
1. Sobre o CogVideoX-5B#
CogVideoX-5B é um modelo de difusão de texto-para-vídeo de ponta desenvolvido pela Zhipu AI na Universidade de Tsinghua. Como parte da série CogVideoX, este modelo cria vídeos diretamente a partir de prompts de texto usando técnicas avançadas de IA, como um 3D Variational Autoencoder (VAE) e um Expert Transformer. O CogVideoX-5B gera resultados de alta qualidade e temporalmente consistentes que capturam movimentos complexos e semântica detalhada.
Com o CogVideoX-5B, você alcança clareza e fluidez excepcionais. O modelo garante um fluxo contínuo, capturando detalhes intrincados e elementos dinâmicos com precisão extraordinária. Utilizar o CogVideoX-5B reduz inconsistências e artefatos, resultando em uma apresentação polida e envolvente. As saídas de alta fidelidade do CogVideoX-5B facilitam a criação de cenas ricamente detalhadas e coerentes a partir de prompts de texto, tornando-o uma ferramenta essencial para qualidade de primeira linha e impacto visual.
2. A Técnica do CogVideoX-5B#
2.1 3D Causal Variational Autoencoder (VAE) do CogVideoX-5B#
O 3D Causal VAE é um componente chave do CogVideoX-5B, permitindo a geração eficiente de vídeos ao comprimir dados de vídeo tanto espacialmente quanto temporalmente. Ao contrário dos modelos tradicionais que usam VAEs 2D para processar cada frame individualmente—frequentemente resultando em cintilação entre os frames—o CogVideoX-5B usa convoluções 3D para capturar informações espaciais e temporais de uma vez. Essa abordagem garante transições suaves e coerentes entre os frames.
A arquitetura do 3D Causal VAE inclui um codificador, um decodificador e um regulador de espaço latente. O codificador comprime os dados de vídeo em uma representação latente, que o decodificador usa para reconstruir o vídeo. Um regulador de Kullback-Leibler (KL) restringe o espaço latente, garantindo que o vídeo codificado permaneça dentro de uma distribuição Gaussiana. Isso ajuda a manter a alta qualidade do vídeo durante a reconstrução.
Características Chave do 3D Causal VAE
- Compressão Espacial e Temporal: O VAE comprime os dados de vídeo por um fator de 4x na dimensão temporal e 8x8 nas dimensões espaciais, alcançando uma razão total de compressão de 4x8x8. Isso reduz as demandas computacionais, permitindo que o modelo processe vídeos mais longos com menos recursos.
- Convolução Causal: Para preservar a ordem dos frames em um vídeo, o modelo usa convoluções temporais causais. Isso garante que frames futuros não influenciem a previsão de frames atuais ou passados, mantendo a integridade da sequência durante a geração.
- Paralelismo de Contexto: Para gerenciar a alta carga computacional do processamento de vídeos longos, o modelo usa paralelismo de contexto na dimensão temporal, distribuindo a carga de trabalho entre múltiplos dispositivos. Isso otimiza o processo de treinamento e reduz o uso de memória.
2.2 Arquitetura Expert Transformer do CogVideoX-5B#
A arquitetura expert transformer do CogVideoX-5B foi projetada para lidar de forma eficaz com a interação complexa entre dados de texto e vídeo. Ela usa uma técnica adaptativa de LayerNorm para processar os espaços de características distintos de texto e vídeo.
Características Chave do Expert Transformer
- Patchificação: Após o 3D Causal VAE codificar os dados de vídeo, eles são divididos em menores "patches" ao longo das dimensões espaciais. Esse processo, chamado de patchificação, converte o vídeo em uma sequência de segmentos menores, facilitando o processamento pelo transformer e o alinhamento com os dados de texto correspondentes.
- 3D Rotary Positional Embedding (RoPE): Para capturar relações espaciais e temporais dentro do vídeo, o CogVideoX-5B estende o tradicional RoPE 2D para 3D. Essa técnica de embedding aplica codificação posicional às dimensões x, y e t do vídeo, ajudando o transformer a modelar efetivamente sequências longas de vídeo e a manter a consistência entre os frames.
- Expert Adaptive LayerNorm (AdaLN): O transformer usa um LayerNorm adaptativo especializado para processar as embeddings de texto e vídeo separadamente. Isso permite que o modelo alinhe os diferentes espaços de características de texto e vídeo, possibilitando uma fusão suave dessas duas modalidades.
2.3 Técnicas de Treinamento Progressivo do CogVideoX-5B#
O CogVideoX-5B usa várias técnicas de treinamento progressivo para melhorar seu desempenho e estabilidade durante a geração de vídeos.
Principais Estratégias de Treinamento Progressivo
- Treinamento de Duração Mista: O modelo é treinado em vídeos de várias durações dentro do mesmo lote. Essa técnica melhora a capacidade de generalização do modelo, permitindo que ele gere vídeos de diferentes durações enquanto mantém a qualidade consistente.
- Treinamento Progressivo de Resolução: O modelo é inicialmente treinado em vídeos de baixa resolução e, em seguida, ajustado gradualmente em vídeos de alta resolução. Essa abordagem permite que o modelo aprenda a estrutura básica e o conteúdo dos vídeos antes de refinar seu entendimento em resoluções mais altas.
- Amostragem Uniforme Explícita: Para estabilizar o processo de treinamento, o CogVideoX-5B usa amostragem uniforme explícita, definindo diferentes intervalos de amostragem de tempo para cada rank paralelo de dados. Esse método acelera a convergência e garante que o modelo aprenda de forma eficaz ao longo de toda a sequência de vídeo.
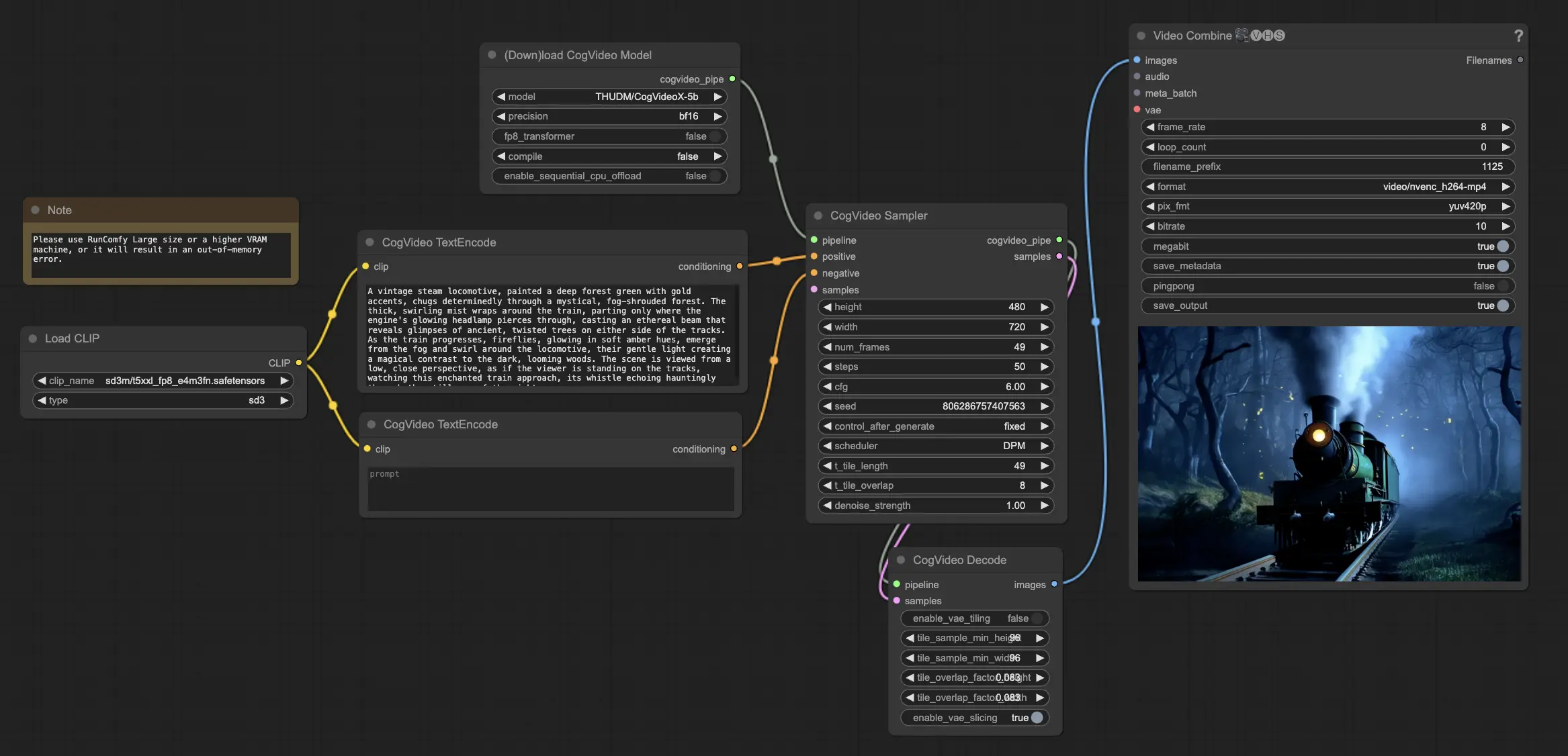
3. Como Usar o Workflow CogVideoX-5B no ComfyUI#
Passo 1: Carregar o Modelo CogVideoX-5B#
Comece carregando o modelo CogVideoX-5B no workflow do ComfyUI. Os modelos CogVideoX-5B foram pré-carregados na plataforma RunComfy.
Passo 2: Insira Seu Prompt de Texto#
Insira seu prompt de texto desejado no nó designado para guiar o processo de geração de vídeo do CogVideoX-5B. O CogVideoX-5B se destaca em interpretar e transformar prompts de texto em conteúdo de vídeo dinâmico.
4. Acordo de Licença#
O código dos modelos CogVideoX é lançado sob a Licença Apache 2.0.
O modelo CogVideoX-2B (incluindo seu módulo Transformers correspondente e módulo VAE) é lançado sob a Licença Apache 2.0.
O modelo CogVideoX-5B (módulo Transformers) é lançado sob a Licença CogVideoX.
