AnimateDiff + ControlNet + IPAdapter V1 | Estilo de Desenho Animado
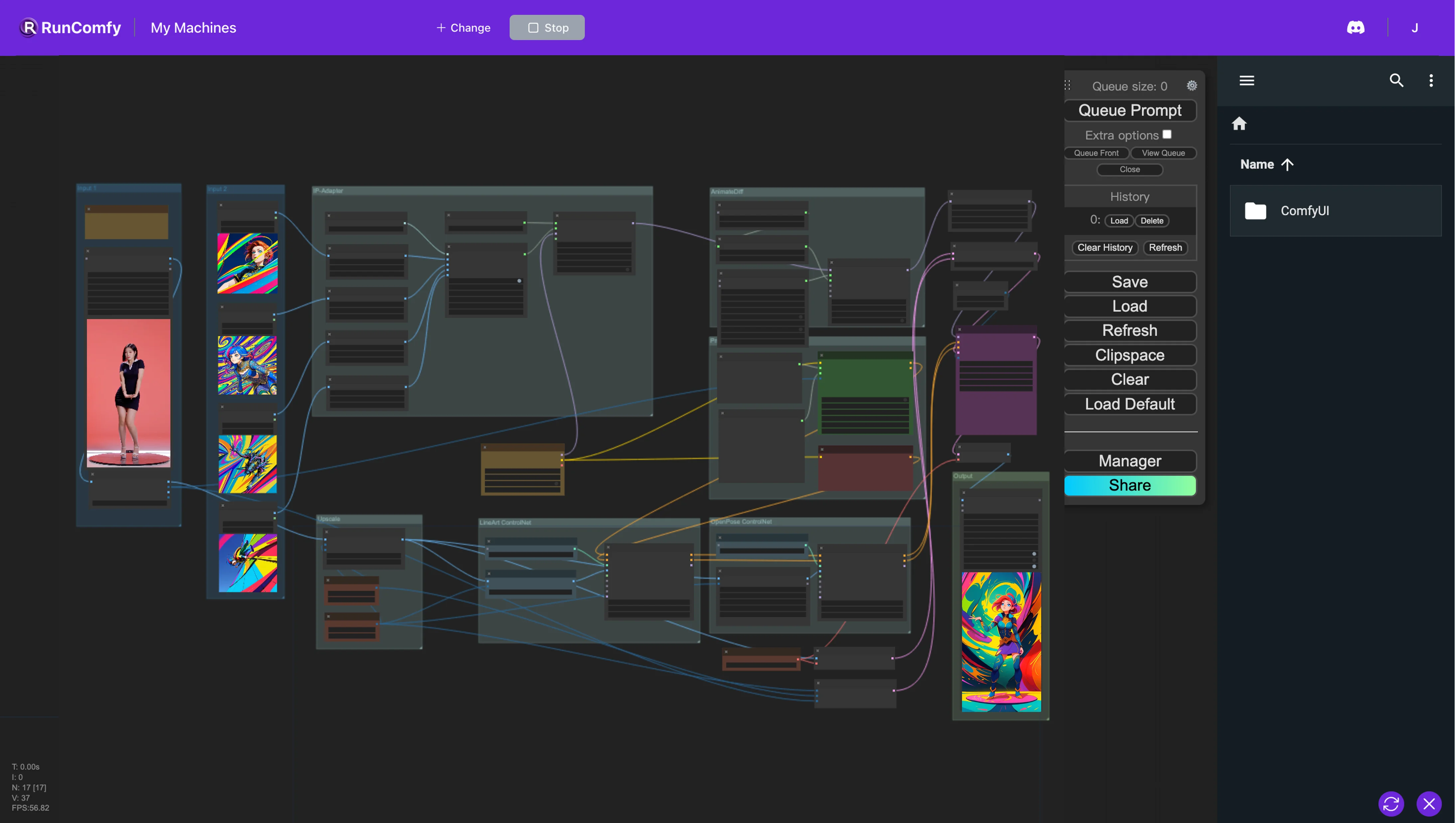
No Fluxo de Trabalho ComfyUI, integramos vários nós, incluindo Animatediff, ControlNet (com LineArt e OpenPose), IP-Adapter e FreeU. Essa integração facilita a conversão do vídeo original na animação desejada usando apenas algumas imagens para definir o estilo preferido. No entanto, os modelos de checkpoint também afetam o estilo. Encorajamos a experimentação com uma variedade de imagens e modelos de checkpoint para obter os melhores resultados!ComfyUI Vid2Vid (Cartoon Style) Fluxo de Trabalho
- Fluxos de trabalho totalmente operacionais
- Sem nós ou modelos ausentes
- Nenhuma configuração manual necessária
- Apresenta visuais impressionantes
ComfyUI Vid2Vid (Cartoon Style) Exemplos
ComfyUI Vid2Vid (Cartoon Style) Descrição
1. Fluxo de Trabalho ComfyUI AnimateDiff, ControlNet, IP-Adapter e FreeU
O fluxo de trabalho ComfyUI implementa uma metodologia para estilização de vídeo que integra vários componentes—AnimateDiff, ControlNet, IP-Adapter e FreeU—para aprimorar as capacidades de edição de vídeo.
AnimateDiff: Este componente emprega modelos de diferença temporal para criar animações suaves a partir de imagens estáticas ao longo do tempo. Ele opera identificando as diferenças entre quadros consecutivos e aplicando incrementalmente essas variações para reduzir mudanças abruptas, preservando assim a coerência do movimento.
ControlNet: O ControlNet aproveita sinais de controle, como aqueles derivados de ferramentas de estimativa de pose como o OpenPose, para guiar o movimento e o fluxo da animação. Esses sinais de controle são em camadas e processados por modelos semelhantes a redes de controle, que por sua vez moldam a saída animada final.
IP-Adapter: O IP-Adapter é projetado para adaptar imagens de entrada para que elas se alinhem mais estreitamente com os estilos ou recursos de saída desejados. Ele realiza processos como colorização e transferência de estilo, alterando os atributos da imagem de forma não supervisionada.
FreeU: Como uma ferramenta de aprimoramento econômica, o FreeU refina modelos de difusão ajustando as arquiteturas U-Net existentes. Isso resulta em um aumento substancial na qualidade da geração de imagens e vídeos, exigindo apenas modificações mínimas.
Juntos, esses componentes se sinergizam dentro deste fluxo de trabalho ComfyUI para transformar entradas em animações estilizadas por meio de um processo de difusão sofisticado e em várias etapas.
2. Visão Geral do AnimateDiff
Confira os detalhes em
3. Visão Geral do ControlNet
Confira os detalhes em
4. Visão Geral do IP-Adapter
Confira os detalhes na
5. Visão Geral do FreeU
5.1. Introdução ao FreeU
O FreeU é um aprimoramento de ponta para modelos de difusão que eleva a qualidade da amostra sem sobrecarga adicional. Ele funciona dentro do sistema existente, não exigindo treinamento adicional, parâmetros extras e mantendo o tempo atual de memória e processamento. O FreeU utiliza os mecanismos existentes da arquitetura U-Net de difusão para melhorar instantaneamente a qualidade da geração.
A inovação do FreeU está em sua capacidade de aproveitar a arquitetura U-Net de difusão de forma mais eficaz. Ele refina o equilíbrio entre o backbone de denoising da U-Net e suas conexões de salto de adição de recursos de alta frequência, otimizando a qualidade das imagens e vídeos gerados sem comprometer a integridade semântica.
O FreeU é projetado para fácil integração com modelos populares de difusão, exigindo ajustes mínimos e o ajuste de apenas dois fatores de escala durante a inferência para fornecer melhorias marcantes na qualidade de saída. Isso torna o FreeU uma opção atraente para aqueles que buscam aprimorar seus fluxos de trabalho generativos de forma eficiente.
Parâmetros para o Desempenho Ideal do FreeU
Sinta-se à vontade para ajustar esses parâmetros com base em seus modelos, estilo de imagem/vídeo ou tarefas. Os seguintes parâmetros são apenas para referência.
SD1.4: (será atualizado em breve)
b1: 1.3, b2: 1.4, s1: 0.9, s2: 0.2
SD1.5: (será atualizado em breve)
b1: 1.5, b2: 1.6, s1: 0.9, s2: 0.2
SD2.1
b1: 1.4, b2: 1.6, s1: 0.9, s2: 0.2
SDXL
b1: 1.3, b2: 1.4, s1: 0.9, s2: 0.2
Alcance para Mais Parâmetros
Ao tentar parâmetros adicionais, considere os seguintes intervalos:
- b1: 1 ≤ b1 ≤ 1.2
- b2: 1.2 ≤ b2 ≤ 1.6
- s1: s1 ≤ 1
- s2: s2 ≤ 1
Para mais informações, confira no
