Transferência de Estilo Consistente com Unsampling
Este fluxo de trabalho explora o Unsampling como um método para transferência de estilo consistente em Stable Diffusion. Ao controlar o ruído latente, o Unsampling garante que o movimento e a composição do vídeo sejam preservados, tornando as transições de estilo mais suaves e consistentes!ComfyUI Unsampling Fluxo de Trabalho
- Fluxos de trabalho totalmente operacionais
- Sem nós ou modelos ausentes
- Nenhuma configuração manual necessária
- Apresenta visuais impressionantes
ComfyUI Unsampling Exemplos
ComfyUI Unsampling Descrição
Este guia de Unsampling, escrito por Inner-Reflections, contribui significativamente para explorar o método de Unsampling para alcançar uma transferência de estilo de vídeo dramaticamente consistente.
1. Introdução: Controle de Ruído Latente com Unsampling
O Ruído Latente é a base de tudo o que fazemos com Stable Diffusion. É incrível dar um passo atrás e pensar no que somos capazes de realizar com isso. No entanto, de modo geral, somos forçados a usar um número aleatório para gerar o ruído. E se pudéssemos controlá-lo?
Eu não sou o primeiro a usar Unsampling. Ele existe há muito tempo e tem sido usado de várias maneiras diferentes. Até agora, no entanto, geralmente não fiquei satisfeito com os resultados. Passei vários meses encontrando as melhores configurações e espero que você aproveite este guia.
Ao usar o processo de amostragem com AnimateDiff/Hotshot, podemos encontrar ruído que representa nosso vídeo original e, portanto, facilita qualquer tipo de transferência de estilo. É especialmente útil manter o Hotshot consistente, dada sua janela de contexto de 8 quadros.
Este processo de unsampling essencialmente converte nosso vídeo de entrada em ruído latente que mantém o movimento e a composição do original. Podemos então usar esse ruído representacional como ponto de partida para o processo de difusão, em vez de ruído aleatório. Isso permite que a IA aplique o estilo alvo enquanto mantém as coisas temporalmente consistentes.
Este guia assume que você instalou o AnimateDiff e/ou o Hotshot. Se você ainda não o fez, os guias estão disponíveis aqui:
AnimateDiff: https://civitai.com/articles/2379
Hotshot XL guide: https://civitai.com/articles/2601/
Link para o recurso - Se você quiser postar vídeos no Civitai usando este fluxo de trabalho. https://civitai.com/models/544534
2. Requisitos do Sistema para este Fluxo de Trabalho
Recomenda-se um computador Windows com uma placa gráfica NVIDIA que tenha pelo menos 12GB de VRAM. Na plataforma RunComfy, use uma máquina Medium (16GB de VRAM) ou de nível superior. Este processo não requer mais VRAM do que os fluxos de trabalho padrão do AnimateDiff ou Hotshot, mas leva quase o dobro do tempo, pois essencialmente executa o processo de difusão duas vezes - uma para upsampling e outra para resampling com o estilo alvo.
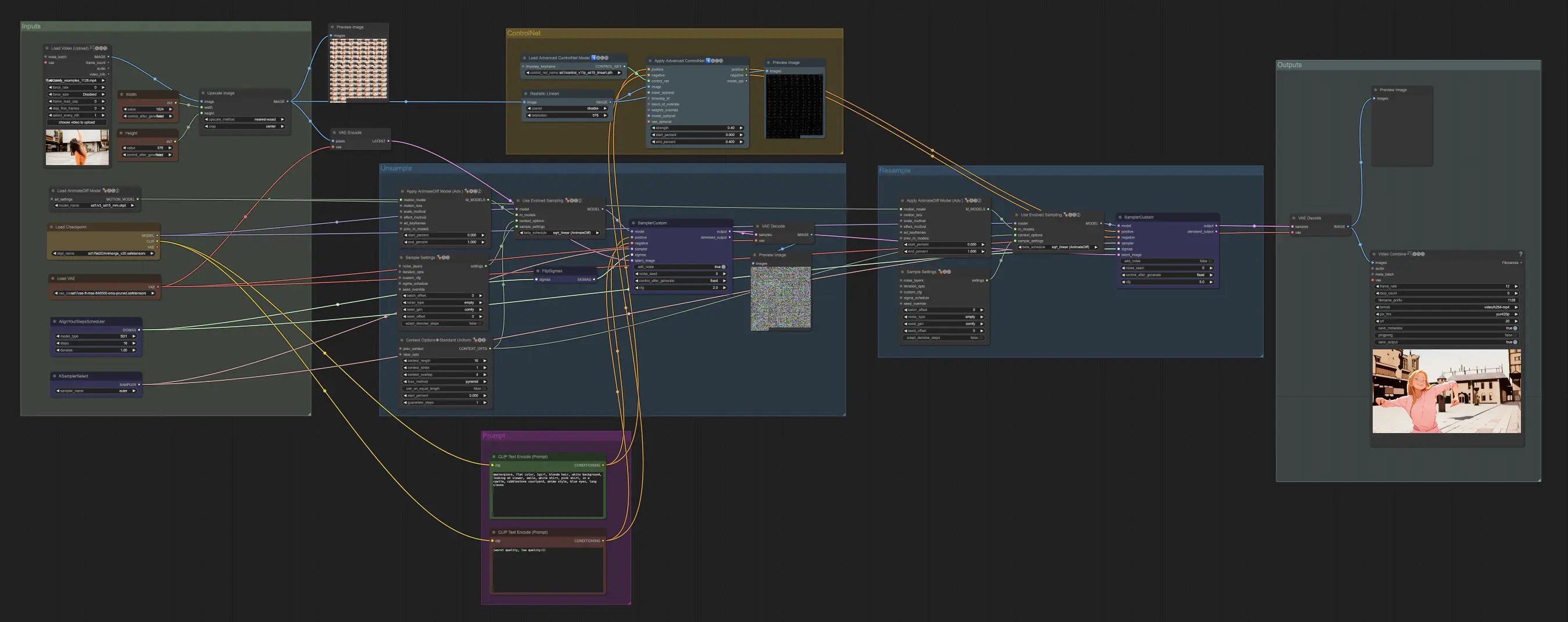
3. Explicações dos Nós e Guia de Configurações
Nó: Custom Sampler
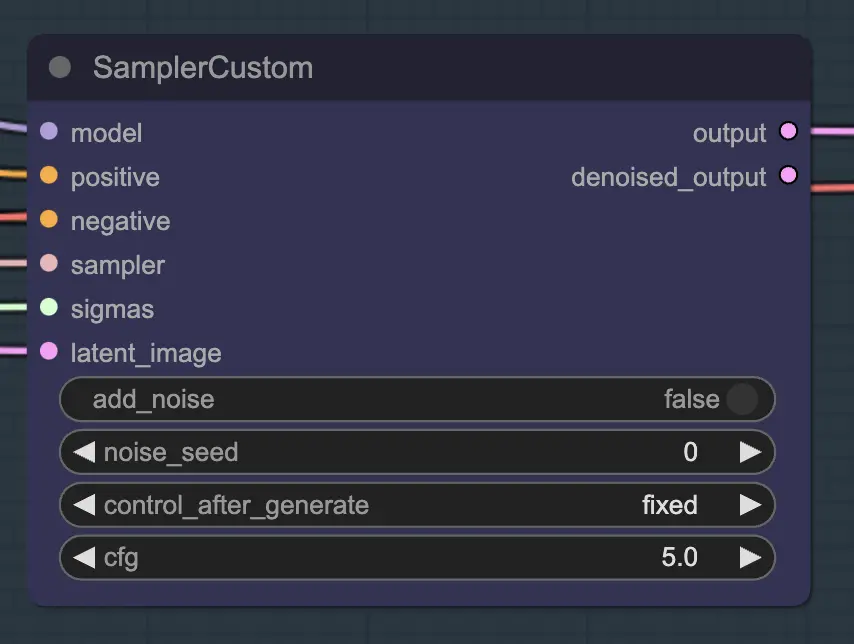
A principal parte disso é usar o Custom Sampler, que divide todas as configurações que você geralmente vê no KSampler regular em partes:
Este é o nó principal do KSampler - para unsampling, adicionar ruído/semente não tem nenhum efeito (que eu saiba). O CFG é importante - de modo geral, quanto maior o CFG nesta etapa, mais o vídeo se parecerá com o seu original. CFG mais alto força o unsampler a corresponder mais de perto à entrada.
Nó: KSampler Select
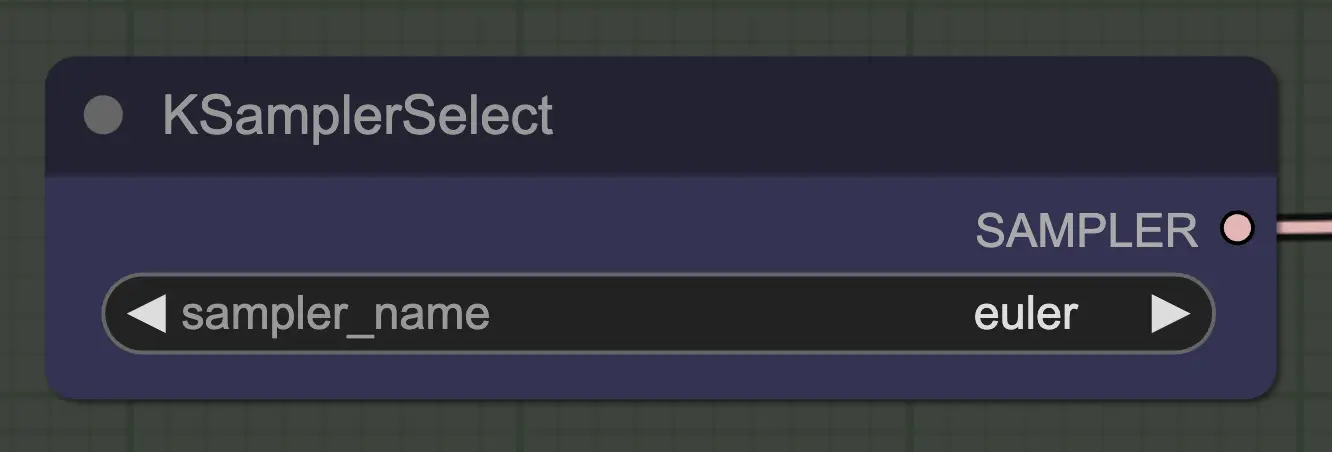
A coisa mais importante é usar um sampler que converja! É por isso que estamos usando euler em vez de euler a, pois este último resulta em mais aleatoriedade/instabilidade. Samplers ancestrais que adicionam ruído a cada etapa impedem que o unsampling converja de forma limpa. Se você quiser ler mais sobre isso, sempre achei útil. @spacepxl no reddit sugere que DPM++ 2M Karras é talvez o sampler mais preciso dependendo do caso de uso.
Nó: Align Your Step Scheduler
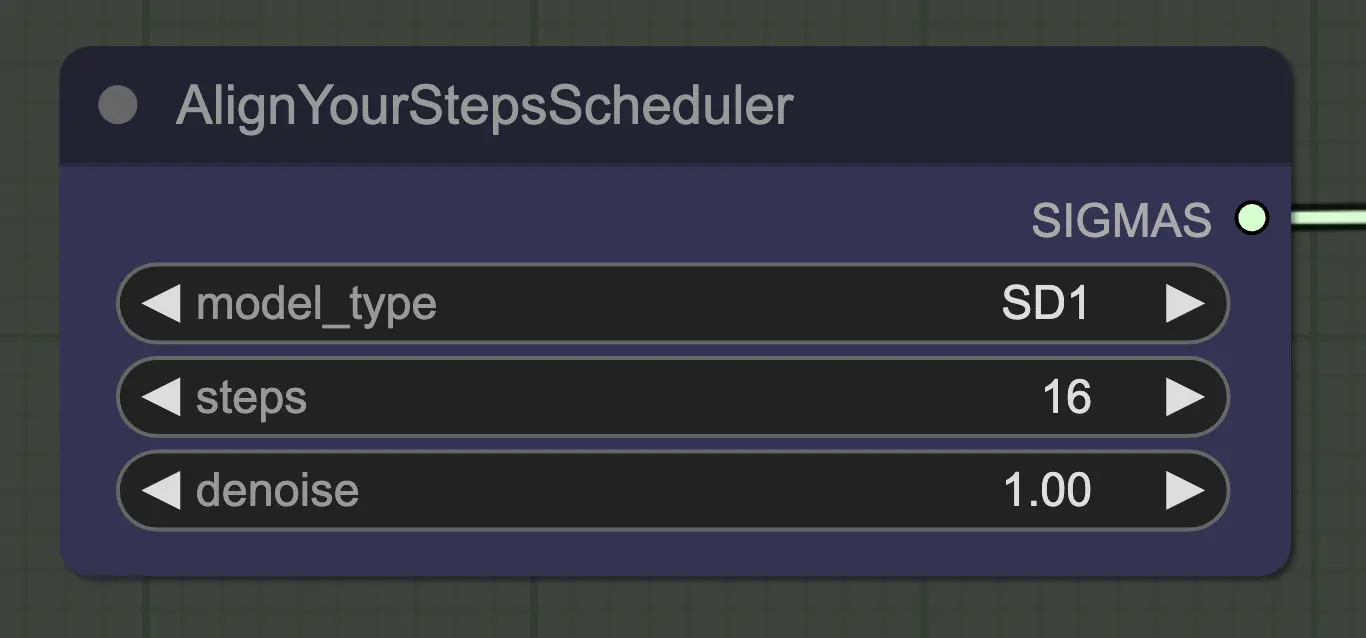
Qualquer scheduler funcionará bem aqui - Align Your Steps (AYS), no entanto, obtém bons resultados com 16 etapas, então optei por usá-lo para reduzir o tempo de computação. Mais etapas convergirão mais completamente, mas com retornos decrescentes.
Nó: Flip Sigma
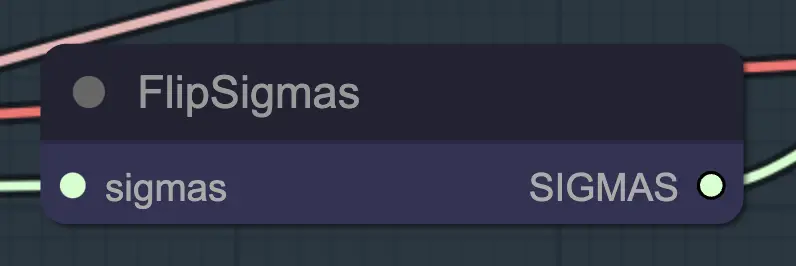
Flip Sigma é o nó mágico que faz o unsampling ocorrer! Ao inverter o cronograma de sigma, revertendo o processo de difusão para ir de uma imagem de entrada limpa para um ruído representacional.
Nó: Prompt
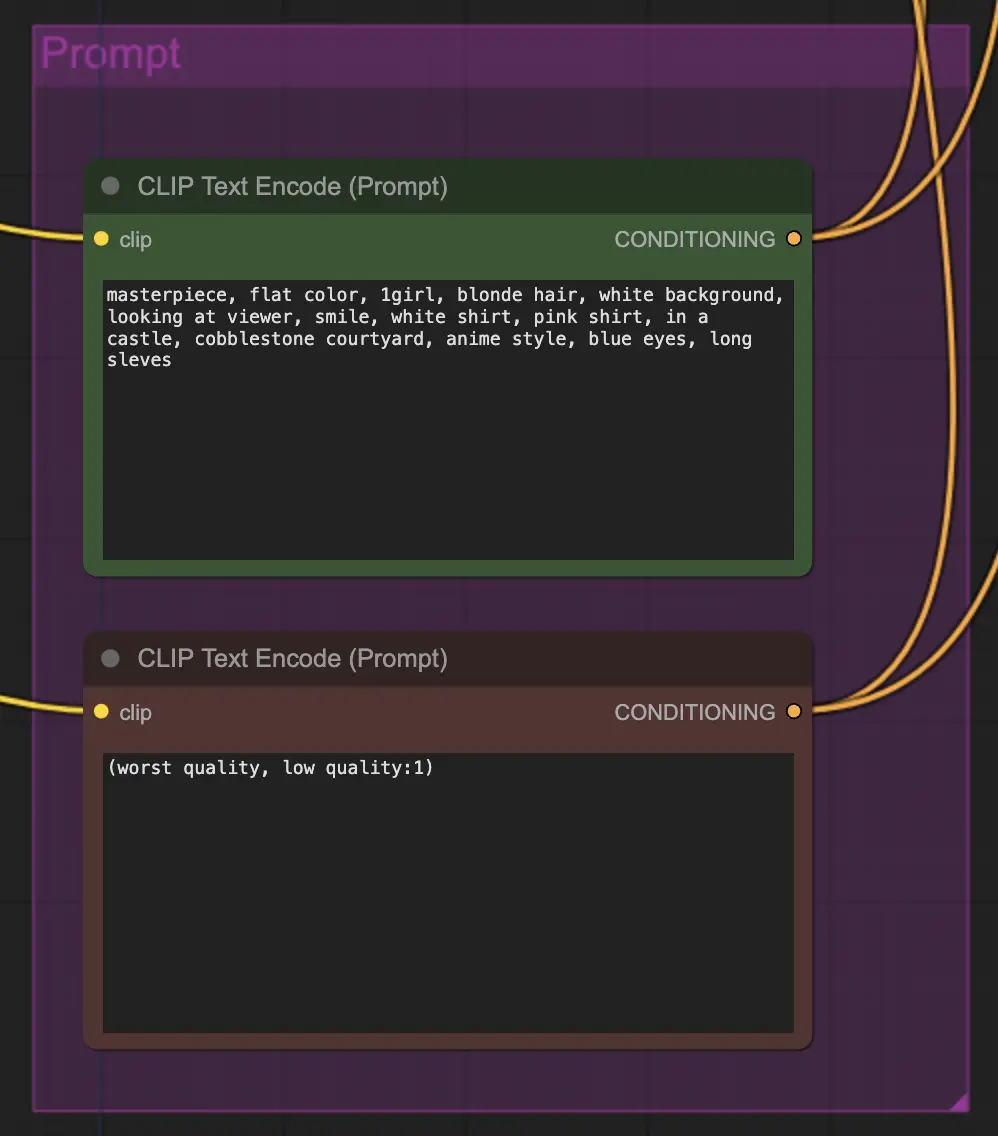
A promptagem importa bastante neste método por algum motivo. Um bom prompt pode realmente melhorar a coerência do vídeo, especialmente quanto mais você quiser forçar a transformação. Para este exemplo, alimentei o mesmo condicionamento para o unsampler e o resampler. Parece funcionar bem geralmente - nada impede você, no entanto, de colocar um condicionamento em branco no unsampler - acho que ajuda a melhorar a transferência de estilo, talvez com um pouco de perda de consistência.
Nó: Resampling
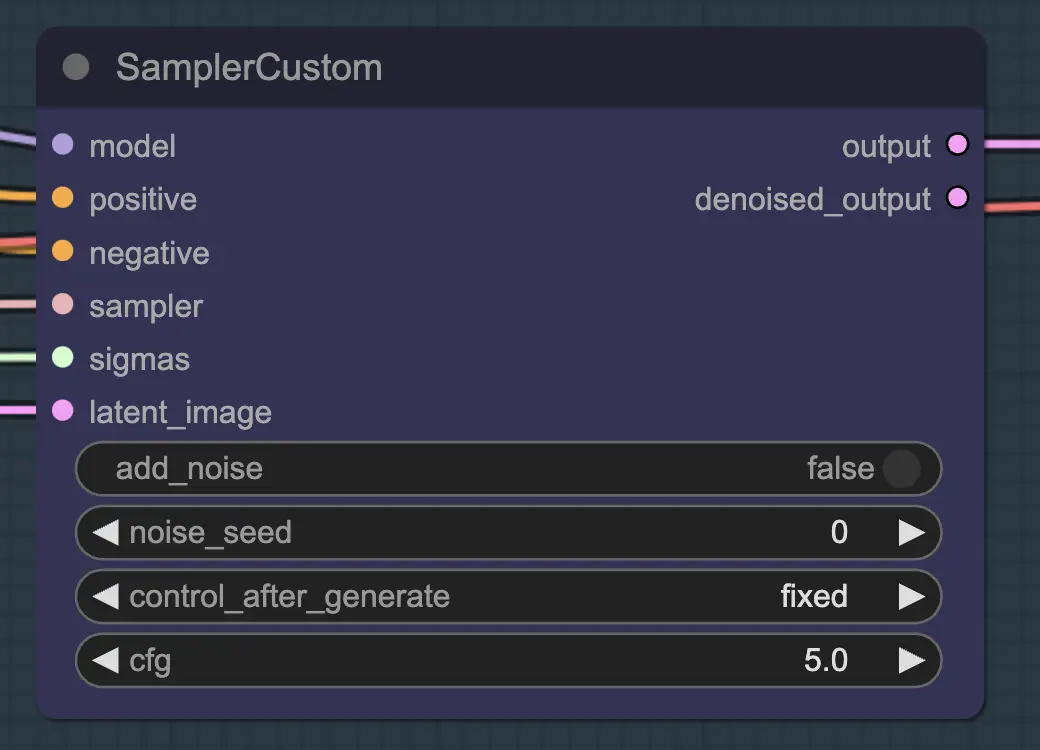
Para o resampling, é importante ter a adição de ruído desativada (embora ter ruído vazio nas configurações de amostras do AnimateDiff tenha o mesmo efeito - fiz ambos para o meu fluxo de trabalho). Se você adicionar ruído durante o resampling, obterá um resultado inconsistente e ruidoso, pelo menos com as configurações padrão. Caso contrário, sugiro começar com um CFG bastante baixo combinado com configurações fracas do ControlNet, pois isso parece dar os resultados mais consistentes enquanto ainda permite que o prompt influencie o estilo.
Outras Configurações
O restante das minhas configurações são preferência pessoal. Simplifiquei este fluxo de trabalho o máximo que penso ser possível, enquanto ainda incluo os componentes e configurações principais.
4. Informações do Fluxo de Trabalho
O fluxo de trabalho padrão usa o modelo SD1.5. No entanto, você pode mudar para SDXL simplesmente alterando o checkpoint, VAE, modelo AnimateDiff, modelo ControlNet e modelo de cronograma de etapas para SDXL.
5. Notas Importantes/Problemas
- Piscar - Se você olhar para os latentes decodificados e previsualizados criados pelo unsampling em meus fluxos de trabalho, notará alguns com anomalias de cor óbvias. A causa exata não está clara para mim, e geralmente, elas não afetam os resultados finais. Essas anomalias são especialmente aparentes com SDXL. No entanto, às vezes podem causar piscadas no seu vídeo. A principal causa parece estar relacionada aos ControlNets - então reduzir sua força pode ajudar. Alterar o prompt ou até mesmo alterar ligeiramente o scheduler também pode fazer a diferença. Ainda encontro esse problema às vezes - se você tiver uma solução, por favor, me avise!
- DPM++ 2M pode às vezes melhorar a piscada.
6. Para Onde Ir a Partir Daqui?
Isso parece uma maneira totalmente nova de controlar a consistência do vídeo, então há muito a explorar. Se você quiser minhas sugestões:
- Tente combinar/mascarar ruído de vários vídeos de origem.
- Adicione IPAdapter para transformação de personagem consistente.
Sobre o Autor
Inner-Reflections
- https://x.com/InnerRefle11312
- https://civitai.com/user/Inner_Reflections_AI



