Hunyuan Video | Texto para Vídeo
Hunyuan Video é um modelo de fundação de vídeo de código aberto desenvolvido pela Tencent. Oferece desempenho na geração de vídeos comparável ou superior aos principais modelos de código fechado. Ao alavancar técnicas avançadas como curadoria de dados, treinamento conjunto imagem-vídeo e uma infraestrutura otimizada, o Hunyuan Video possibilita a geração de vídeos de alta qualidade e em larga escala.ComfyUI Hunyuan Video Fluxo de Trabalho
- Fluxos de trabalho totalmente operacionais
- Sem nós ou modelos ausentes
- Nenhuma configuração manual necessária
- Apresenta visuais impressionantes
ComfyUI Hunyuan Video Exemplos
ComfyUI Hunyuan Video Descrição
é um modelo de fundação de vídeo de código aberto inovador que oferece desempenho em geração de vídeo comparável, ou até melhor, do que os principais modelos de código fechado, desenvolvido pela Tencent, uma empresa líder em tecnologia. Hunyuan Video emprega tecnologias de ponta para aprendizado de modelos, como curadoria de dados, treinamento conjunto de modelos imagem-vídeo e uma infraestrutura eficiente para treinamento e inferência de modelos em larga escala. Hunyuan Video possui o maior modelo generativo de vídeo de código aberto com mais de 13 bilhões de parâmetros.
Principais características do Hunyuan Video incluem
- O Hunyuan Video oferece uma arquitetura unificada para gerar tanto imagens quanto vídeos. Ele utiliza um design especial de modelo Transformer chamado "Fluxo-duplo para Fluxo-único." Isso significa que o modelo processa primeiro as informações de vídeo e texto separadamente, e depois as combina para criar o resultado final. Isso ajuda o modelo a entender melhor a relação entre os visuais e a descrição do texto.
- O codificador de texto no Hunyuan Video é baseado em um Modelo de Linguagem Multimodal (MLLM). Comparado a outros codificadores de texto populares como CLIP e T5-XXL, o MLLM é melhor em alinhar o texto com as imagens. Ele também pode fornecer descrições mais detalhadas e raciocínio sobre o conteúdo. Isso ajuda o Hunyuan Video a gerar vídeos que correspondem mais precisamente ao texto de entrada.
- Para lidar eficientemente com vídeos de alta resolução e alta taxa de quadros, o Hunyuan Video usa um Autoencoder Variacional 3D (VAE) com CausalConv3D. Este componente comprime os vídeos e imagens em uma representação menor chamada espaço latente. Trabalhando neste espaço comprimido, o Hunyuan Video pode treinar e gerar vídeos na resolução e taxa de quadros originais sem usar muitos recursos computacionais.
- O Hunyuan Video inclui um modelo de reescrita de prompts que pode adaptar automaticamente o texto de entrada do usuário para melhor atender às preferências do modelo. Existem dois modos disponíveis: Normal e Master. O modo Normal foca em melhorar a compreensão do modelo sobre as instruções do usuário, enquanto o modo Master enfatiza a criação de vídeos com maior qualidade visual. No entanto, o modo Master pode às vezes negligenciar certos detalhes no texto em favor de tornar o vídeo mais atraente visualmente.
Use o Hunyuan Video no ComfyUI
Esses nós e fluxos de trabalho relacionados foram desenvolvidos por Kijai. Damos todo o crédito devido a Kijai por este trabalho inovador. Na plataforma RunComfy, estamos simplesmente apresentando suas contribuições à comunidade.
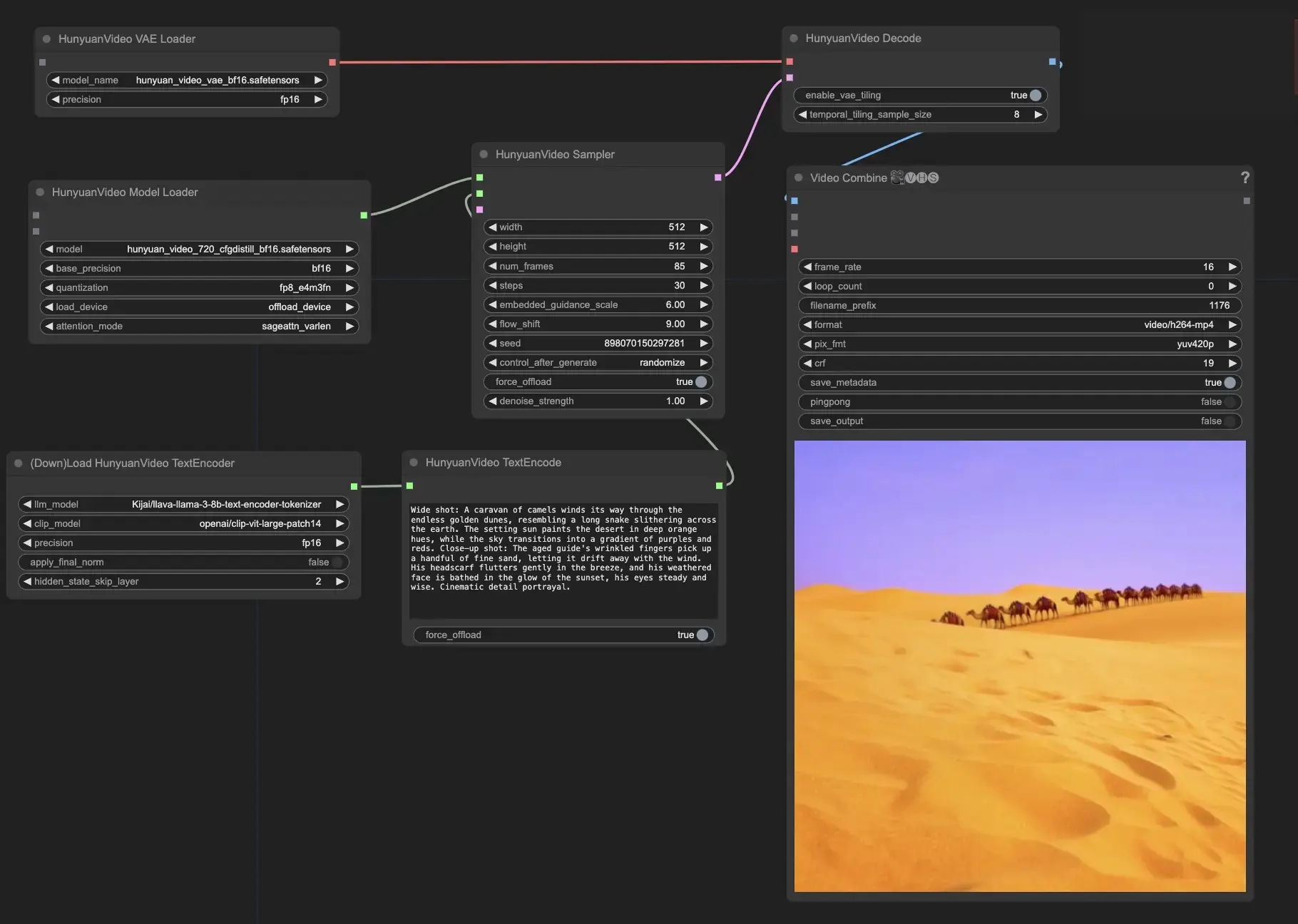
- Forneça seu prompt de texto: No nó HunyuanVideoTextEncode, insira seu prompt de texto desejado no campo "prompt". estão alguns exemplos de prompts para sua referência.
- Configure as configurações de saída de vídeo no nó HunyuanVideoSampler:
- Defina a "width" e "height" para sua resolução preferida
- Defina o "num_frames" para o comprimento do vídeo desejado em quadros
- "steps" controla o número de etapas de remoção de ruído/amostragem (padrão: 30)
- "embedded_guidance_scale" determina a força da orientação do prompt (padrão: 6.0)
- "flow_shift" afeta o comprimento do vídeo (valores maiores resultam em vídeos mais curtos, padrão: 9.0)

