Stable Diffusion 3 (SD3) | Texto para Imagem
O Stable Diffusion 3 (SD3) medium está agora disponível na Versão Beta do RunComfy, tornando-o facilmente acessível para seus projetos. Você pode usar o Stable Diffusion 3 medium diretamente neste fluxo de trabalho ou integrá-lo em seus fluxos de trabalho existentes.ComfyUI Stable Diffusion 3 (SD3) Playground
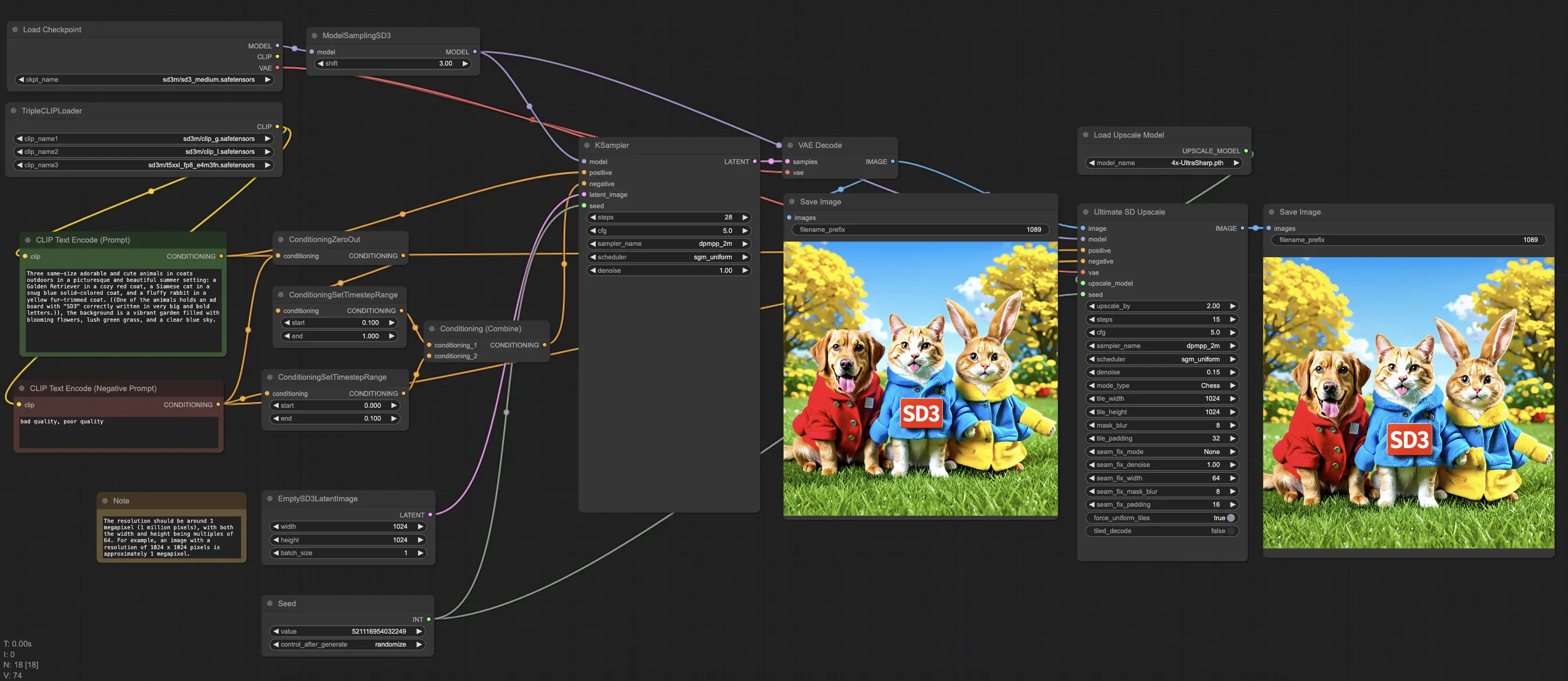
ComfyUI Stable Diffusion 3 (SD3) Fluxo de Trabalho
- Fluxos de trabalho totalmente operacionais
- Sem nós ou modelos ausentes
- Nenhuma configuração manual necessária
- Apresenta visuais impressionantes
ComfyUI Stable Diffusion 3 (SD3) Exemplos



ComfyUI Stable Diffusion 3 (SD3) Descrição
1. Impulsionando Seu Processo Criativo com ComfyUI Stable Diffusion 3
🌟🌟🌟**O modelo Stable Diffusion 3 Medium e seus nós relacionados agora estão pré-carregados na Versão Beta do ComfyUI da RunComfy (Versão 24.06.13.0)!!!**🌟🌟🌟 Você pode usar o Stable Diffusion 3 Medium diretamente neste fluxo de trabalho do ComfyUI ou integrá-lo perfeitamente em seus fluxos de trabalho ComfyUI existentes.
O fluxo de trabalho ComfyUI Stable Diffusion 3 vem com todos os modelos necessários do Stable Diffusion 3 Medium. Basta experimentar diferentes prompts ou parâmetros para experimentá-lo!
1.1. Modelos Stable Diffusion 3 Medium Pré-carregados no ComfyUI
sd3_medium.safetensors: Inclui os pesos MMDiT e VAE, mas não inclui nenhum codificador de texto.sd3_medium_incl_clips_t5xxlfp16.safetensors: Contém todos os pesos necessários, incluindo a versão fp16 do codificador de texto T5XXL.sd3_medium_incl_clips_t5xxlfp8.safetensors: Contém todos os pesos necessários, incluindo a versão fp8 do codificador de texto T5XXL, oferecendo um equilíbrio entre qualidade e requisitos de recursos.sd3_medium_incl_clips.safetensors: Inclui todos os pesos necessários, exceto o codificador de texto T5XXL. Esta versão requer recursos mínimos, mas o desempenho do modelo será diferente sem o codificador de texto T5XXL.- A pasta
text_encoderscontém três codificadores de texto e seus links de cartão de modelo original para conveniência do usuário. Todos os componentes dentro desta pasta (e seus equivalentes embutidos em outros pacotes) estão sujeitos às respectivas licenças originais.
1.2 Qualidade Geral e Fotorrealismo do Stable Diffusion 3 Medium
O Stable Diffusion 3 Medium estabelece um novo padrão de qualidade de imagem na comunidade de arte de IA. Este modelo entrega imagens com detalhes excepcionais, precisão de cores e iluminação realista. Veja o que você pode esperar:
- Detalhe & Resolução: Capacidade aprimorada de renderizar detalhes intrincados, tornando-o perfeito para close-ups e composições complexas.
- Cor & Iluminação: Algoritmos melhorados garantem que as cores sejam vibrantes e fiéis à vida, com efeitos de iluminação dinâmicos que adicionam profundidade e realismo às suas imagens.
- Realismo em Faces e Mãos: Problemas comuns como mãos e rostos distorcidos são significativamente reduzidos, graças a inovações como o Autoencoder Variacional de 16 canais (VAE).
1.3 Compreensão de Prompt do Stable Diffusion 3 Medium
Uma das características de destaque do SD3 Medium é sua compreensão sofisticada de prompts. Este modelo pode interpretar prompts longos e complexos envolvendo raciocínio espacial, elementos composicionais, ações e estilos. Aqui estão alguns destaques:
- Codificadores de Texto: Utiliza três codificadores de texto para equilibrar desempenho e eficiência. Isso permite uma compreensão e execução nuançada de prompts detalhados.
- Consciência Composicional: Capaz de manter relações espaciais e retratar cenas com precisão conforme descrito, tornando-o ideal para contar histórias através de visuais.
1.4 Tipografia do Stable Diffusion 3 Medium
A tipografia sempre foi um desafio na geração de texto-para-imagem. O SD3 Medium aborda isso com sucesso notável:
- Qualidade do Texto: Alcança precisão sem precedentes em ortografia, kerning, formação de letras e espaçamento.
- Arquitetura Diffusion Transformer: Esta arquitetura avançada permite uma renderização mais precisa do texto dentro das imagens, reduzindo erros e melhorando a coerência visual.
1.5 Eficiência de Recursos do Stable Diffusion 3 Medium
Apesar de suas capacidades avançadas, o SD3 Medium é projetado para ser eficiente em termos de recursos:
- Baixo Consumo de VRAM: Pode rodar em GPUs de consumidor padrão sem degradação de desempenho, tornando a arte de IA de alta qualidade acessível a um público mais amplo.
- Otimizado para Eficiência: Equilibra demandas computacionais com qualidade de saída, garantindo operação suave mesmo em hardware menos potente.
1.6 Ajuste Fino do Stable Diffusion 3 Medium
A personalização é um aspecto crítico para artistas de IA, e o SD3 Medium se destaca nesta área:
- Absorvendo Detalhes Nuances: Capaz de ajuste fino com pequenos conjuntos de dados, permitindo que os artistas imprimam seu estilo único ou atendam a requisitos específicos de projeto.
- Versatilidade: Seja você trabalhando em temas específicos, estilos ou detalhes intrincados, o SD3 Medium fornece a flexibilidade necessária para obras de arte personalizadas.
2. O que é o Stable Diffusion 3
O Stable Diffusion 3 é um modelo de IA de ponta projetado especificamente para gerar imagens a partir de prompts. Ele representa a terceira iteração na série Stable Diffusion e visa fornecer melhor precisão, melhor adesão às nuances dos prompts e estética visual superior em comparação com versões anteriores e outros modelos como DALL·E 3, Midjourney v6 e Ideogram v1.
3. Modelos Stable Diffusion 3
O Stable Diffusion 3 oferece três modelos distintos, cada um projetado para atender a diferentes necessidades e capacidades computacionais:
3.1. Stable Diffusion 3 Medium
🌟🌟🌟 Integrado diretamente neste fluxo de trabalho 🌟🌟🌟
- Parâmetros: 2 bilhões
- Características Principais:
- Imagens de alta qualidade, fotorrealistas
- Compreensão avançada de prompts complexos
- Capacidades de tipografia superiores
- Eficiente em termos de recursos, adequado para GPUs de consumidor
- Excelente para ajuste fino com pequenos conjuntos de dados
3.2. Stable Diffusion 3 Large
Disponível via
- Parâmetros: 8 bilhões
- Características Principais:
- Qualidade e detalhe de imagem aprimorados
- Maior capacidade para lidar com prompts e estilos complexos
- Ideal para projetos de nível profissional que exigem alta resolução e fidelidade
3.3. Stable Diffusion 3 Large Turbo
Disponível via
- Parâmetros: 8 bilhões (com tempo de inferência otimizado)
- Características Principais:
- O mesmo alto desempenho do SD3 Large
- Inferência mais rápida, tornando-o adequado para aplicações em tempo real e prototipagem rápida
4. Arquitetura Técnica do Stable Diffusion 3
No núcleo do Stable Diffusion 3 está a arquitetura Multimodal Diffusion Transformer (MMDiT). Esta estrutura inovadora melhora a forma como o modelo processa e integra informações textuais e visuais. Ao contrário de seus predecessores que utilizavam um único conjunto de pesos de rede neural para processamento de imagem e texto, o Stable Diffusion 3 emprega conjuntos de pesos separados para cada modalidade. Esta separação permite um tratamento mais especializado dos dados de texto e imagem, levando a uma melhor compreensão do texto e precisão ortográfica nas imagens geradas.
4.1. Componentes da Arquitetura MMDiT
- Embarcadores de Texto: O Stable Diffusion 3 usa uma combinação de três modelos de incorporação de texto, incluindo dois modelos CLIP e T5, para converter o texto em um formato que a IA possa entender e processar.
- Codificador de Imagem: Um modelo de auto-codificação aprimorado é usado para converter imagens em uma forma adequada para a IA manipular e gerar novo conteúdo visual.
- Abordagem de Transformador Duplo: A arquitetura possui dois transformadores distintos para texto e imagens, que operam independentemente, mas são interconectados para operações de atenção. Esta configuração permite que ambas as modalidades influenciem diretamente uma à outra, melhorando a coerência entre a entrada de texto e a saída de imagem.
5. O que há de Novo e Melhorado no Stable Diffusion 3?
- Adesão aos Prompts: O SD3 se destaca em seguir de perto os detalhes dos prompts do usuário, especialmente aqueles que envolvem cenas complexas ou múltiplos sujeitos. Esta precisão na compreensão e renderização de prompts detalhados permite que ele supere outros modelos líderes, como DALL·E 3, Midjourney v6 e Ideogram v1, tornando-o altamente confiável para projetos que requerem estrita adesão às instruções fornecidas.
- Texto em Imagens: Com sua avançada arquitetura Multimodal Diffusion Transformer (MMDiT), o SD3 melhora significativamente a clareza e legibilidade do texto dentro das imagens. Ao empregar conjuntos de pesos separados para o processamento de dados de imagem e linguagem, o modelo alcança uma compreensão superior do texto e precisão ortográfica. Esta é uma melhoria substancial em relação às versões anteriores do Stable Diffusion, abordando um dos desafios comuns em aplicações de IA de texto-para-imagem.
- Qualidade Visual: O SD3 não apenas iguala, mas em muitos casos supera a qualidade visual das imagens geradas por seus concorrentes. As imagens produzidas são não apenas esteticamente agradáveis, mas também mantêm alta fidelidade aos prompts, graças à capacidade refinada do modelo de interpretar e visualizar descrições textuais. Isso torna o SD3 uma escolha principal para usuários que buscam estética visual excepcional em suas imagens geradas.

Para insights detalhados sobre o modelo, visite o ,





