Stable Diffusion 3.5
Stable Diffusion 3.5 (SD3.5) é um novo modelo de código aberto que gera imagens diversificadas e de alta qualidade a partir de prompts de texto. O SD3.5 se destaca na criação de vários estilos e na aderência aos prompts. Apesar de algumas limitações em anatomia e resolução, o SD3.5 é uma ferramenta poderosa para criação visual. Explore o SD3.5 no ComfyUI para criar visuais impressionantes com facilidade.ComfyUI Stable Diffusion 3.5 Fluxo de Trabalho
- Fluxos de trabalho totalmente operacionais
- Sem nós ou modelos ausentes
- Nenhuma configuração manual necessária
- Apresenta visuais impressionantes
ComfyUI Stable Diffusion 3.5 Exemplos




ComfyUI Stable Diffusion 3.5 Descrição
A Stability AI lançou , um modelo de IA generativa multimodal de código aberto que inclui várias variantes, como Stable Diffusion 3.5 (SD3.5) Large, Stable Diffusion 3.5 (SD3.5) Large Turbo e Stable Diffusion 3.5 (SD3.5) Medium. Esses modelos são altamente personalizáveis, capazes de rodar em hardware de consumo. Os modelos SD3.5 Large e Large Turbo estão disponíveis imediatamente, enquanto a versão Medium será lançada em 29 de outubro de 2024.
1. Como Funciona o Stable Diffusion 3.5 (SD3.5)
Em um nível técnico, o Stable Diffusion 3.5 (SD3.5) recebe um prompt de texto como entrada, codifica-o em um espaço latente usando codificadores de texto baseados em transformers e então decodifica essa representação latente em uma imagem de saída usando um decodificador baseado em difusão. Os codificadores de texto transformer, como o modelo CLIP (Contrastive Language-Image Pre-training), mapeiam o prompt de entrada em uma representação comprimida semanticamente significativa no espaço latente. Este código latente é então iterativamente desruídido pelo decodificador de difusão em vários passos de tempo para gerar a imagem final de saída. O processo de difusão envolve a remoção gradual de ruído de uma representação latente inicialmente ruidosa, condicionada pela incorporação de texto, até que uma imagem limpa emerja.
Os diferentes tamanhos de modelo no Stable Diffusion 3.5 (SD3.5) (Large, Medium) referem-se ao número de parâmetros treináveis - 8 bilhões para o modelo Large e 2,5 bilhões para o Medium. Mais parâmetros geralmente permitem que o modelo capture mais conhecimento e nuances de seus dados de treinamento. Os modelos Turbo são versões destiladas que sacrificam alguma qualidade por velocidades de inferência muito mais rápidas. A destilação envolve treinar um modelo "aluno" menor para imitar as saídas de um modelo "professor" maior, visando reter a maior parte da capacidade em uma arquitetura mais eficiente.
2. Pontos Fortes dos Modelos Stable Diffusion 3.5 (SD3.5)
2.1. Personalização
Os modelos Stable Diffusion 3.5 (SD3.5) foram projetados para serem facilmente ajustáveis e desenvolvidos para aplicações específicas. A Normalização Consulta-Chave foi integrada nos blocos de transformers para estabilizar o treinamento e simplificar o desenvolvimento adicional. Essa técnica normaliza os scores de atenção nas camadas de transformers, o que pode tornar o modelo mais robusto e fácil de adaptar a novos conjuntos de dados via aprendizado de transferência.
2.2. Diversidade de Saídas
Stable Diffusion 3.5 (SD3.5) visa gerar imagens representativas da diversidade mundial sem a necessidade de prompts extensivos. Ele pode representar pessoas com diferentes tons de pele, características e estéticas. Isso provavelmente se deve ao modelo ser treinado em um grande e diversificado conjunto de dados de imagens de toda a internet.
2.3. Ampla Gama de Estilos
Os modelos Stable Diffusion 3.5 (SD3.5) são capazes de gerar imagens em uma ampla variedade de estilos, incluindo renderizações 3D, fotorrealismo, pinturas, arte linear, anime e mais. Essa versatilidade os torna adequados para muitos casos de uso. A diversidade de estilos emerge da capacidade do modelo de difusão de capturar muitos padrões visuais e estéticos diferentes em seu espaço latente.
2.4. Forte Aderência ao Prompt
Especialmente para o modelo Stable Diffusion 3.5 (SD3.5) Large, o SD3.5 se sai bem em gerar imagens que se alinham com o significado semântico dos prompts de texto de entrada. Ele se classifica altamente em comparação com outros modelos em métricas de correspondência de prompt. Essa capacidade de traduzir texto em imagens com precisão é impulsionada pelas capacidades de compreensão de linguagem do codificador de texto transformer.
3. Limitações e Desvantagens dos Modelos Stable Diffusion 3.5 (SD3.5)
3.1. Dificuldades com Anatomia e Interações de Objetos
Como a maioria dos modelos de texto para imagem, o Stable Diffusion 3.5 (SD3.5) ainda tem dificuldade em renderizar anatomia humana realista, especialmente mãos, pés e rostos em poses complexas. As interações entre objetos e mãos costumam ser distorcidas. Isso provavelmente se deve ao desafio de aprender todas as nuances de relações espaciais 3D e física a partir de imagens 2D sozinhas.
3.2. Resolução Limitada
O modelo Stable Diffusion 3.5 (SD3.5) Large é ideal para imagens de 1 megapixel (1024x1024), enquanto o Medium atinge no máximo cerca de 2 megapixels. Gerar imagens coerentes em resoluções mais altas é desafiador para o SD3.5. Essa limitação decorre das restrições computacionais e de memória da arquitetura de difusão.
3.3. Falhas e Alucinações Ocasionalmente
Devido aos modelos Stable Diffusion 3.5 (SD3.5) permitirem uma ampla diversidade de saídas a partir do mesmo prompt com diferentes sementes aleatórias, pode haver alguma imprevisibilidade. Prompts sem especificidade podem levar a elementos falhos ou inesperados aparecendo. Esta é uma propriedade inerente do processo de amostragem de difusão, que envolve aleatoriedade.
3.4. Fica Aquém do Absolutamente Mais Avançado
De acordo com alguns testes iniciais, em termos de qualidade e coerência de imagem, o Stable Diffusion 3.5 (SD3.5) atualmente não corresponde ao desempenho de modelos de texto para imagem de última geração, como Midjourney. E comparações iniciais entre Stable Diffusion 3.5 (SD3.5) e FLUX.1 revelam que cada modelo se destaca em diferentes áreas. Enquanto o FLUX.1 parece ter vantagem em produzir imagens fotorrealistas, o SD3.5 Large tem maior proficiência em gerar arte no estilo anime sem exigir ajuste fino ou modificações adicionais.
4. Stable Diffusion 3.5 no ComfyUI
Na RunComfy, tornamos fácil para você começar a usar os modelos Stable Diffusion 3.5 (SD3.5) pré-carregando-os para sua conveniência. Você pode começar imediatamente e executar inferências usando o fluxo de trabalho de exemplo
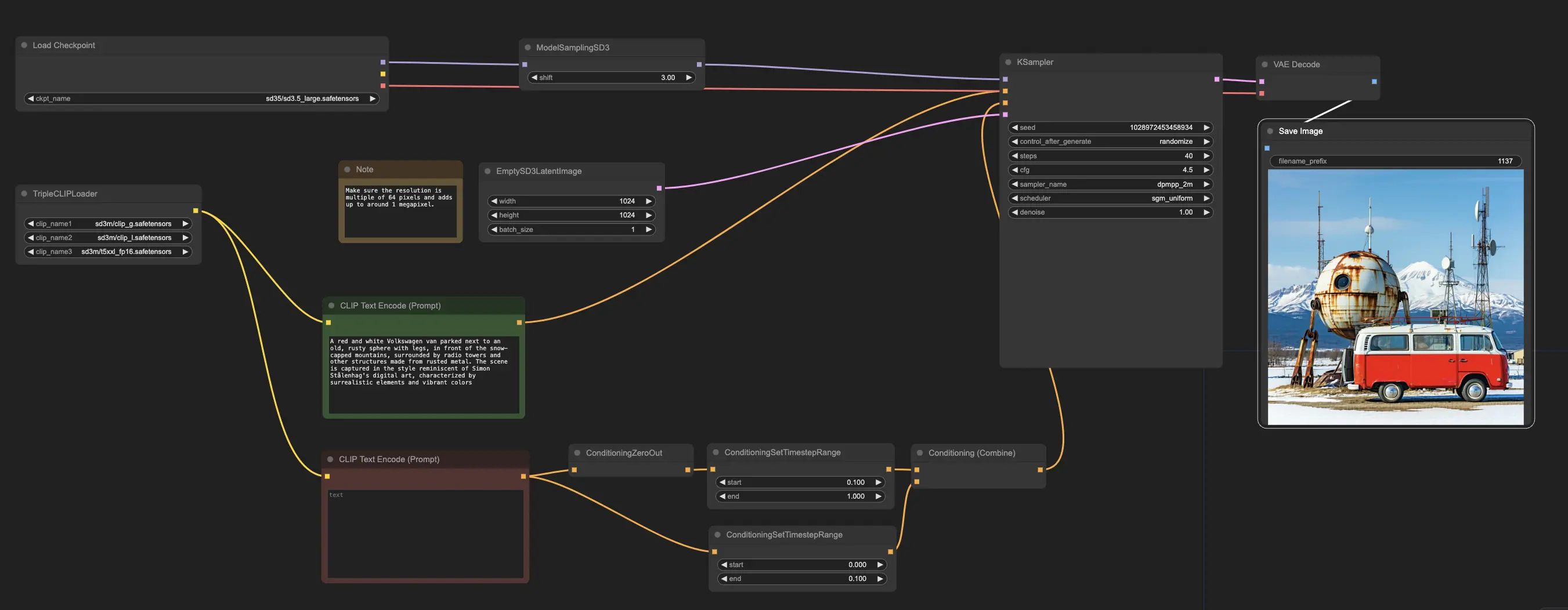
O fluxo de trabalho de exemplo começa com o nó CheckpointLoaderSimple, que carrega o modelo Stable Diffusion 3.5 Large pré-treinado. E para ajudar a traduzir seus prompts de texto em um formato que o modelo possa entender, o nó TripleCLIPLoader é usado para carregar os codificadores correspondentes. Esses codificadores são cruciais para orientar o processo de geração de imagens com base no texto que você fornece.
O nó EmptySD3LatentImage então cria uma tela em branco com as dimensões especificadas, tipicamente 1024x1024 pixels, que serve como ponto de partida para o modelo gerar a imagem. Os nós CLIPTextEncode processam os prompts de texto que você fornece, usando os codificadores carregados para criar um conjunto de instruções para o modelo seguir.
Antes que essas instruções sejam enviadas ao modelo, elas passam por refinamento adicional através dos nós ConditioningCombine, ConditioningZeroOut e ConditioningSetTimestepRange. Esses nós removem a influência de quaisquer prompts negativos, especificam quando os prompts devem ser aplicados durante o processo de geração e combinam as instruções em um conjunto único e coeso.
Finalmente, você pode ajustar o processo de geração de imagens usando o nó ModelSamplingSD3, que permite ajustar várias configurações, como o modo de amostragem, número de etapas e escala de saída do modelo. Finalmente, o nó KSampler dá a você controle sobre o número de etapas, a força da influência das instruções (escala CFG) e o algoritmo específico usado para geração, permitindo que você alcance os resultados desejados.
