EchoMimic | Анимации портретов, управляемые аудио
EchoMimic — это инструмент, который позволяет создавать реалистичные говорящие головы и жесты тела, которые идеально синхронизируются с предоставленным аудио. Используя передовые техники ИИ, EchoMimic анализирует аудио-вход и генерирует реалистичные выражения лица, движения губ и язык тела, которые идеально соответствуют произнесённым словам и эмоциям. С EchoMimic вы можете оживить ваших персонажей и создавать анимационный контент, который захватывает вашу аудиторию.ComfyUI EchoMimic Рабочий процесс
- Полностью функциональные рабочие процессы
- Нет недостающих узлов или моделей
- Не требуется ручная настройка
- Отличается потрясающей визуализацией
ComfyUI EchoMimic Примеры
ComfyUI EchoMimic Описание
EchoMimic — это инструмент для генерации реалистичных анимаций портретов, управляемых аудио. Он использует методы глубокого обучения для анализа входного аудио и генерирования соответствующих выражений лица, движений губ и жестов головы, которые точно соответствуют эмоциональному и фонетическому содержанию речи.
EchoMimic V2 был разработан исследовательской группой из отдела Terminal Technology компании Alipay, Ant Group, в которую входят Ранг Мэн, Синью Чжан, Юмин Ли и Ченгуан Ма. Для получения подробной информации, пожалуйста, посетите /. Узел ComfyUI_EchoMimic был разработан /. Вся заслуга принадлежит их значительному вкладу.
EchoMimic V1 и V2
- EchoMimic V1: Реалистичные анимации портретов, управляемые аудио, с возможностью настройки контрольных точек
- EchoMimic V2: Упрощенные, выразительные и полу-телесные анимации человека
Ключевое различие заключается в том, что EchoMimic V2 стремится достичь впечатляющей анимации половины тела человека, упрощая ненужные условия контроля по сравнению с EchoMimic V1. EchoMimic V2 использует новую стратегию Audio-Pose Dynamic Harmonization для улучшения выражений лица и жестов тела.
Преимущества и недостатки EchoMimic V2
Преимущества:
- EchoMimic V2 генерирует крайне реалистичные и выразительные анимации портретов, управляемые аудио
- EchoMimic V2 расширяет анимацию на верхнюю часть тела, а не только на область головы
- EchoMimic V2 снижает сложность условий, сохраняя качество анимации по сравнению с EchoMimic V1
- EchoMimic V2 бесшовно включает данные headshot для улучшения выражений лица
Недостатки:
- EchoMimic V2 требует аудио источника, соответствующего портрету, для достижения наилучших результатов
- EchoMimic V2 в настоящее время не имеет кода синхронизации поз, используя файл позы по умолчанию
- Генерация более длительных высококачественных анимаций с EchoMimic V2 может быть вычислительно затратной
- EchoMimic V2 лучше всего работает с обрезанными изображениями портретов, а не с полными телесными снимками
Как использовать рабочий процесс ComfyUI EchoMimic
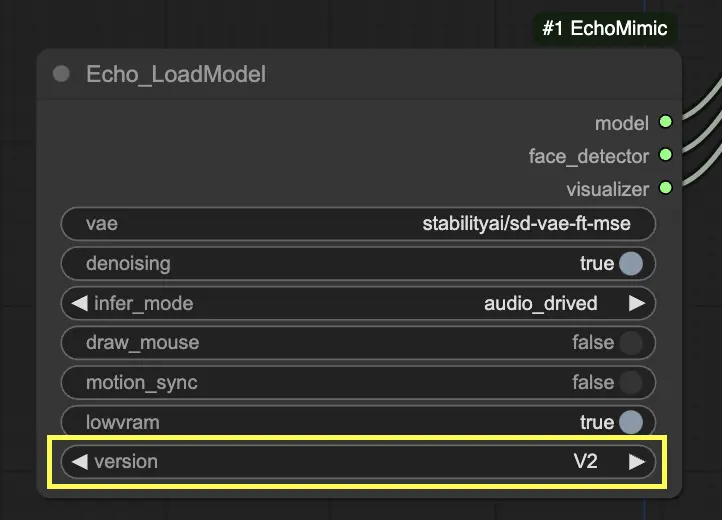
В узле "Echo_LoadModel" у вас есть возможность выбрать между EchoMimic v1 и EchoMimic v2:
- EchoMimic v1: Эта версия сосредоточена на генерации реалистичных анимаций портретов, управляемых аудио, с возможностью настройки контрольных точек. Она хорошо подходит для создания реалистичных анимаций лица, которые точно соответствуют входному аудио.
- EchoMimic v2: Эта версия стремится упростить процесс анимации, обеспечивая при этом выразительные и полу-телесные анимации человека. Она расширяет анимацию за пределы только лицевой области, включая движения верхней части тела. Однако, пожалуйста, обратите внимание, что функция синхронизации поз для v2 еще не реализована в текущей версии рабочего процесса ComfyUI. Если вы выберете 'None' для пути позы, вместо этого будет использоваться файл позы по умолчанию.
Вот пошаговое руководство по использованию предоставленного рабочего процесса ComfyUI:
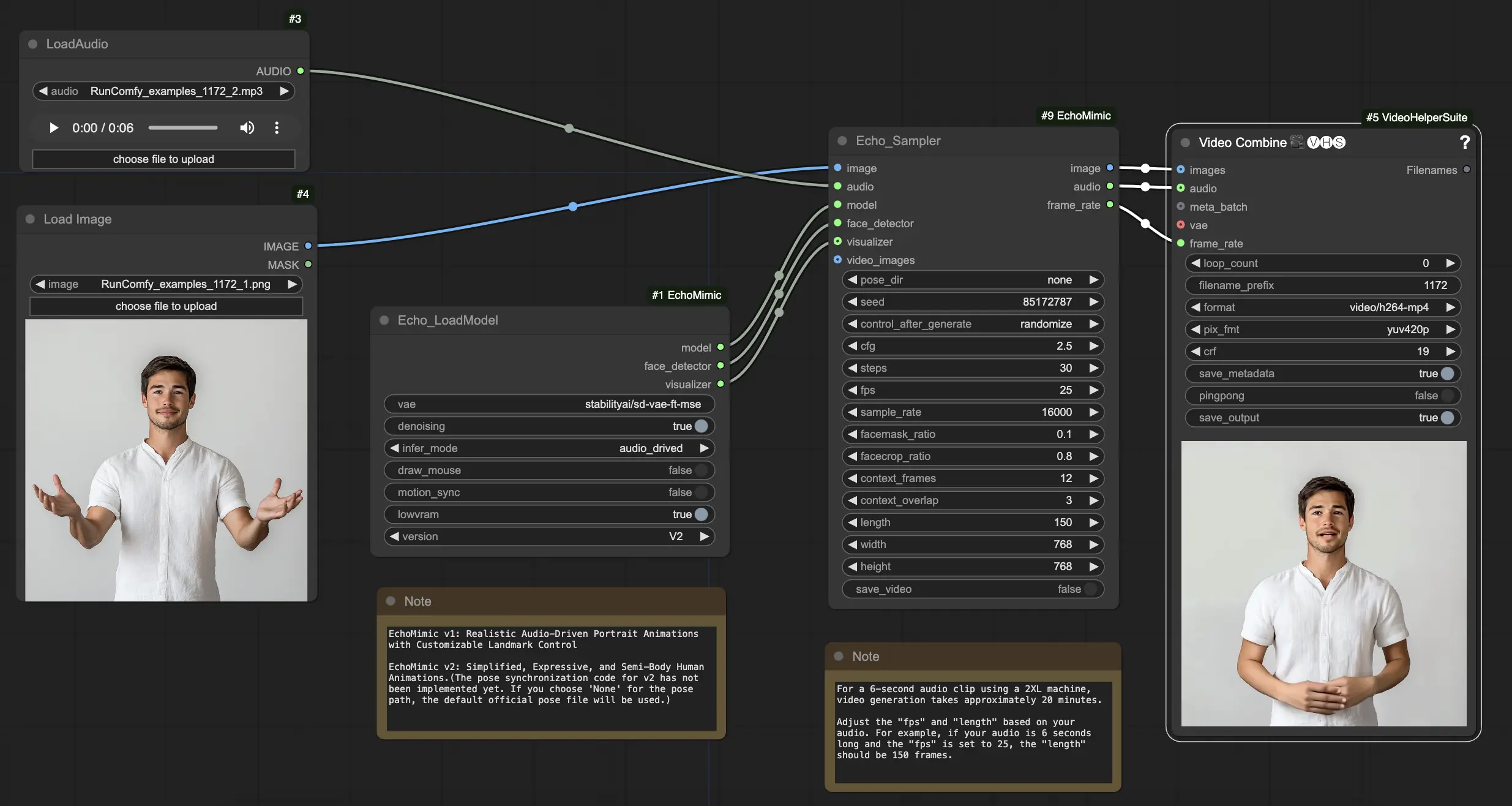
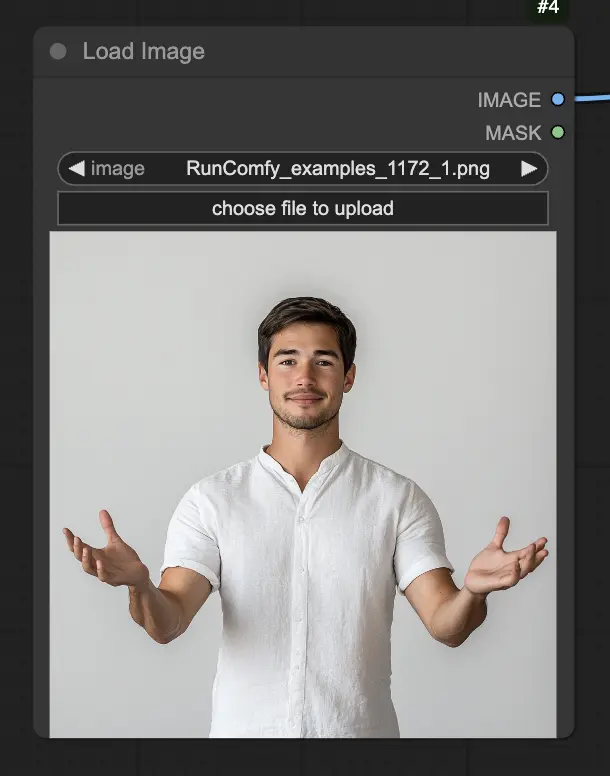
Шаг 1. Загрузите изображение портрета с помощью узла LoadImage. Это должен быть крупный план головы и плеч субъекта.
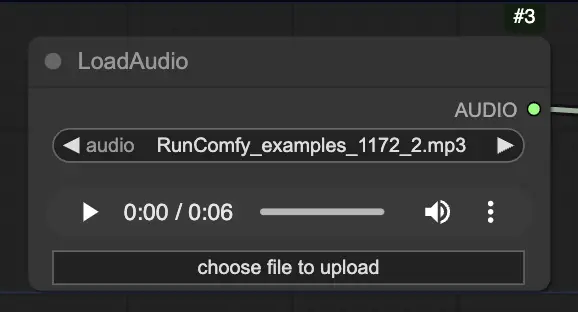
Шаг 2. Загрузите аудио файл с помощью узла LoadAudio. Речь в аудио должна соответствовать идентичности субъекта портрета.
Шаг 3. Используйте узел Echo_LoadModel для загрузки модели EchoMimic. Ключевые настройки:
- Выберите версию (V1 или V2).
- Выберите режим вывода, например, режим, управляемый аудио.
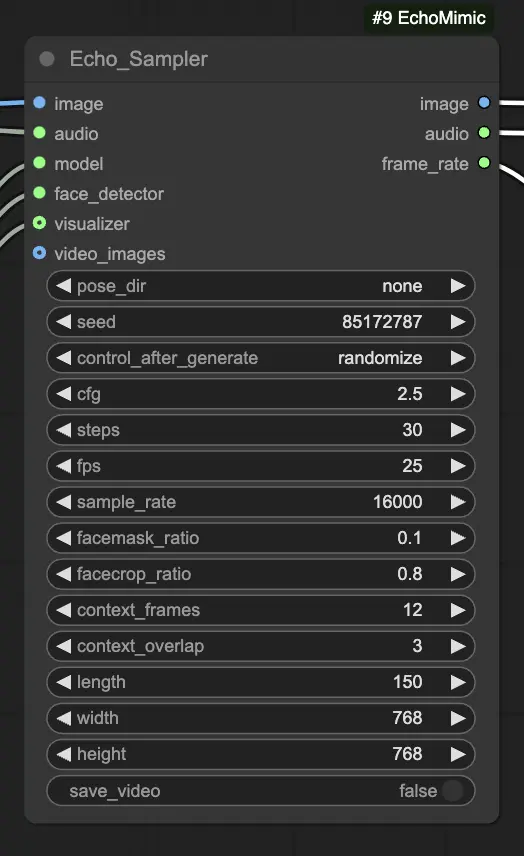
Шаг 4. Подключите изображение, аудио и загруженную модель к узлу Echo_Sampler. Ключевые настройки:
- pose_dir: Директория для файлов последовательности поз, используемых в режимах анимации, управляемых позами. Если установлено "none", последовательность поз не будет использоваться.
- seed: Случайное число для генерации постоянных результатов при повторных запусках. Это должно быть целое число от 0 до MAX_SEED.
- cfg: Масштаб классификатора без руководства, управляющий силой аудио-контроля. Более высокие значения приводят к более выраженным движениям, управляемым аудио. Значение по умолчанию — 2.5, и оно может варьироваться от 0.0 до 10.0.
- steps: Количество шагов диффузии для генерации каждого кадра. Более высокие значения производят более плавные анимации, но требуют больше времени на генерацию. Значение по умолчанию — 30, и оно может варьироваться от 1 до 100.
- fps: Частота кадров выходного видео в кадрах в секунду. Значение по умолчанию — 25, и оно может варьироваться от 5 до 100.
- sample_rate: Частота дискретизации входного аудио в Гц. Значение по умолчанию — 16000, и оно может варьироваться от 8000 до 48000 с шагом 1000.
- facemask_ratio: Отношение площади маски лица к полной площади изображения. Оно управляет размером области вокруг лица, которая анимируется. Значение по умолчанию — 0.1, и оно может варьироваться от 0.0 до 1.0.
- facecrop_ratio: Отношение площади обрезки лица к полной площади изображения. Оно определяет, сколько изображения посвящено области лица. Значение по умолчанию — 0.8, и оно может варьироваться от 0.0 до 1.0.
- context_frames: Количество прошлых и будущих кадров, используемых в качестве контекста для генерации каждого кадра. Значение по умолчанию — 12, и оно может варьироваться от 0 до 50.
- context_overlap: Количество перекрывающихся кадров между смежными окнами контекста. Значение по умолчанию — 3, и оно может варьироваться от 0 до 10.
- length: Длина выходного видео в кадрах. Она должна основываться на продолжительности вашего входного аудио и настройке fps. Например, если ваше аудио длится 6 секунд и fps установлен на 25, длина должна быть 150 кадров. Длина может варьироваться от 50 до 5000 кадров.
- width: Ширина кадров выходного видео в пикселях. Значение по умолчанию — 512, и оно может варьироваться от 128 до 1024 с шагом 64.
- height: Высота кадров выходного видео в пикселях. Значение по умолчанию — 512, и оно может варьироваться от 128 до 1024 с шагом 64.
Пожалуйста, обратите внимание, что генерация видео может занять некоторое время. Например, создание видео из 6-секундного аудио-клипа с использованием машины 2XL на RunComfy занимает около 20 минут.