Hallo2 | Портретная анимация синхронизации губ
Hallo2 — это продвинутая модель AI, которая генерирует высококачественные портретные анимации с синхронизацией губ, управляемые аудио-входом. Применяя такие техники, как диффузионные модели, кодирование аудио и обнаружение лиц, Hallo2 создаёт анимации в 4K с точно синхронизированными движениями рта и выражениями. Бесшовно интегрированная в платформу ComfyUI, Hallo2 позволяет пользователям создавать реалистичные портретные анимации с синхронизацией губ.ComfyUI Hallo2 Lip-Sync Рабочий процесс
- Полностью функциональные рабочие процессы
- Нет недостающих узлов или моделей
- Не требуется ручная настройка
- Отличается потрясающей визуализацией
ComfyUI Hallo2 Lip-Sync Примеры
ComfyUI Hallo2 Lip-Sync Описание
Техника Hallo2 была разработана Цзяхао Цуй, Хуй Ли, Яо Яо, Хао Чжу, Ханлин Шан, Кайхуэй Чэн, Ханг Чжоу, Сию Чжу и Цзиндон Ван из Фуданьского университета и Baidu Inc. Для более подробной информации посетите . Узлы и рабочий процесс ComfyUI_Hallo2 были разработаны smthemex. Для получения более подробной информации посетите . Все заслуги их вкладу.
1. О Hallo2
Hallo2 — это передовая модель для генерации высококачественных, продолжительных, 4K разрешения аудио-управляемых портретных анимационных видео. Она основывается на оригинальной модели Hallo с несколькими ключевыми улучшениями:
- Поддерживает генерацию гораздо более длинных видео, до десятков минут или даже часов
- Генерирует видео в разрешении 4K
- Позволяет контролировать выражение и позу с помощью текстовых подсказок в дополнение к аудио
Hallo2 достигает этого, используя передовые техники, такие как увеличение данных для поддержания согласованности на протяжении долгих периодов, векторное квантование латентных кодов для разрешения 4K и улучшенный процесс удаления шума, управляемый как аудио, так и текстом.
2. Технические особенности Hallo2
Hallo2 сочетает несколько передовых AI моделей и техник для создания своих высококачественных портретных видео:
- Диффузионная модель: Это основное "движок", который генерирует кадры видео. Он начинается с случайного шума и постепенно уточняет его, чтобы соответствовать желаемому результату, управляемый аудио и текстовыми подсказками.
- 3D U-Net: Это тип нейронной сети, который действует как "скульптор" в процессе диффузии. Он смотрит на текущий шумный кадр, аудио и текстовые инструкции и предлагает, как изменить шум, чтобы он больше походил на окончательный портрет.
- Аудио кодировщик: Hallo2 использует модель под названием Wav2Vec2 в качестве своих "ушей" для понимания аудио, преобразуя сырой звуковой сигнал в компактное представление, которое захватывает тон, скорость и содержание речи.
- Обнаружение лиц: Чтобы помочь сосредоточиться на анимации лица, Hallo2 использует модель обнаружения лиц для автоматического нахождения лица портрета в референсном изображении. Затем он знает, где применять движения губ и выражения.
- Компрессор изображений: Для эффективной работы с изображениями высокого разрешения 4K, Hallo2 использует специальный тип модели автоэнкодера (VQ-VAE) для сжатия их в меньшее "латентное" представление, а затем декодирует их обратно в 4K в конце. Это похоже на то, как JPEG сжимает размеры файлов изображений, сохраняя качество.
- Увеличение данных: Чтобы поддерживать качество в течение долгих видео, Hallo2 применяет некоторые умные "увеличения данных" к ранее сгенерированным кадрам перед их использованием для влияния на следующий кадр. Эти включают в себя случайное удаление случайных участков или добавление лёгкого шума. Это помогает предотвратить накопление ошибок, которые в противном случае могли бы накапливаться и портить согласованность со временем.
Итак, в итоге - Hallo2 принимает аудио и портретное изображение, имеет AI "агента", который создаёт видео кадры, чтобы они соответствовали им, оставаясь верными оригинальному портрету, и использует некоторые дополнительные трюки, чтобы всё оставалось синхронизированным и согласованным даже в длинных видео. Все эти части работают вместе в многоступенчатом конвейере для достижения впечатляющих результатов, которые вы видите.
3. Как использовать рабочий процесс ComfyUI Hallo2
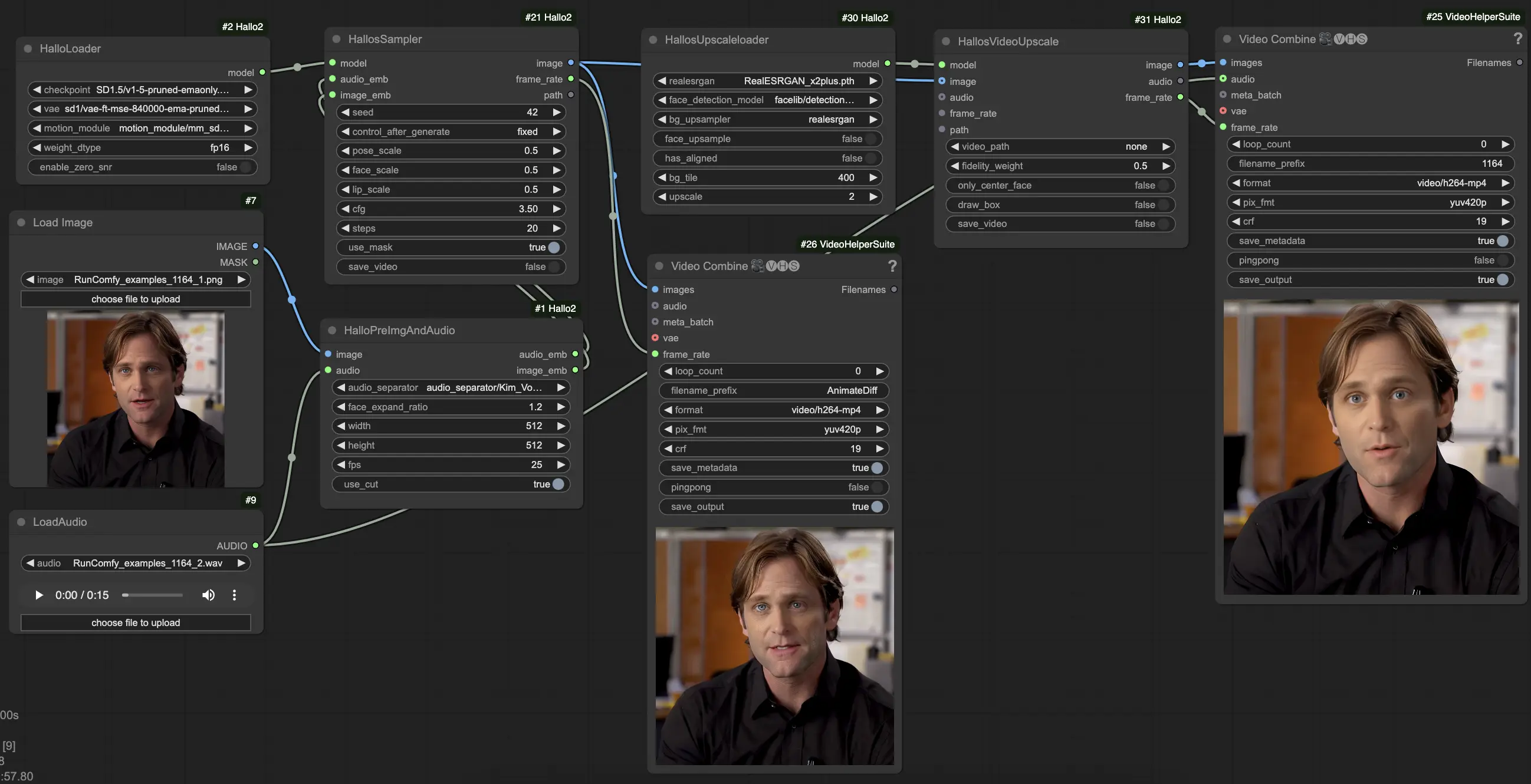
Hallo2 был интегрирован в ComfyUI через пользовательский рабочий процесс с несколькими специализированными узлами. Вот как его использовать:
- Загрузите ваше референсное портретное изображение, используя узел
LoadImage. Это должно быть чёткое изображение лица в анфас. (Советы: Чем лучше оформлен и освещён ваш референсный портрет, тем лучше будут результаты. Избегайте профилей сбоку, перекрытий, загруженных фонов и т.д.) - Загрузите ваше управляющее аудио, используя узел
LoadAudio. Оно должно соответствовать настроению, которое вы хотите, чтобы портрет выражал. - Подключите изображение и аудио к узлу
HalloPreImgAndAudio. Это предварительно обрабатывает изображение и аудио в эмбеддинги. Ключевые параметры:audio_separator: Модель для отделения речи от фонового шума. Обычно оставляйте по умолчанию.face_expand_ratio: Насколько расширять обнаруженную область лица. Более высокие значения включают больше волос/фона.width/height: Разрешение генерации. Более высокие значения медленнее, но более детализированы. 512-1024 квадрат — хороший баланс.fps: Целевой FPS видео. 25 — хороший выбор по умолчанию.
- Загрузите основную модель Hallo2, используя узел
HalloLoader. Укажите на ваш контрольный пункт Hallo2, VAE и файлы модуля движения. - Подключите предварительно обработанные эмбеддинги изображения и аудио вместе с загруженной моделью к узлу
HalloSampler. Это выполняет фактическую генерацию видео. Ключевые параметры:seed: Случайное зерно, которое определяет незначительные детали. Измените его, если вам не понравился первый результат.pose_scale/face_scale/lip_scale: Насколько масштабировать интенсивность позы, выражения лица и движений губ. 1.0 = полная интенсивность, 0.0 = заморожено.cfg: Масштаб руководства без классификатора. Больше = более строго следует условиям, но менее разнообразно.steps: Количество шагов удаления шума. Больше шагов = лучшее качество, но медленнее.
- На этом этапе вы можете просмотреть сгенерированное видео. Чтобы дополнительно улучшить качество с помощью супер-разрешения, добавьте узлы
HallosUpscaleloaderиHallosVideoUpscaleв конец цепочки. Загрузчик увеличения читает предварительно обученную модель увеличения, а узел увеличения фактически выполняет увеличение до 4K.