
1. 关于CogVideoX-5B#
CogVideoX-5B是由清华大学的Zhipu AI开发的最先进的文本到视频扩散模型。作为CogVideoX系列的一部分,该模型使用3D变分自编码器(VAE)和专家Transformer等先进AI技术直接从文本提示创建视频。CogVideoX-5B生成高质量、时间上连贯的结果,捕捉复杂的运动和详细的语义。
使用CogVideoX-5B,您可以获得卓越的清晰度和流畅性。该模型确保无缝流动,以非凡的准确性捕捉复杂的细节和动态元素。利用CogVideoX-5B可以减少不一致性和伪影,从而呈现出抛光且引人入胜的展示。CogVideoX-5B的高保真输出可以从文本提示创建丰富详细且连贯的场景,使其成为顶级质量和视觉影响的必备工具。
2. CogVideoX-5B的技术#
2.1 CogVideoX-5B的3D因果变分自编码器(VAE)#
3D因果VAE是CogVideoX-5B的关键组件,通过在空间和时间上压缩视频数据,实现高效的视频生成。与传统模型使用2D VAE逐帧处理的方式不同,CogVideoX-5B使用3D卷积同时捕捉空间和时间信息。这种方法确保帧间的平滑和连贯过渡。
3D因果VAE的架构包括编码器、解码器和潜在空间正则化器。编码器将视频数据压缩成潜在表示,解码器则使用该表示重建视频。Kullback-Leibler(KL)正则化器约束潜在空间,确保编码视频保持在高斯分布内。这有助于在重建过程中保持高视频质量。
3D因果VAE的关键特性
- 空间和时间压缩:VAE在时间维度上压缩视频数据4倍,在空间维度上压缩8x8倍,总压缩比达到4x8x8。这减少了计算需求,使模型能够以更少的资源处理更长的视频。
- 因果卷积:为了保持视频帧的顺序,模型使用时间因果卷积。这确保未来帧不会影响当前或过去帧的预测,在生成过程中保持序列的完整性。
- 上下文并行性:为了管理处理长视频的高计算负荷,模型在时间维度上使用上下文并行性,将工作负载分布在多个设备上。这优化了训练过程并减少了内存使用。
2.2 CogVideoX-5B的专家Transformer架构#
CogVideoX-5B的专家Transformer架构旨在有效处理文本和视频数据之间的复杂交互。它使用自适应LayerNorm技术处理文本和视频的不同特征空间。
专家Transformer的关键特性
- Patchification:在3D因果VAE编码视频数据后,它在空间维度上被分成更小的片段。这一过程称为Patchification,将视频转换为更小段的序列,使Transformer更容易处理并与相应的文本数据对齐。
- 3D旋转位置嵌入(RoPE):为了捕捉视频中的空间和时间关系,CogVideoX-5B将传统的2D RoPE扩展到3D。这种嵌入技术将位置编码应用于视频的x、y和t维度,帮助Transformer有效建模长视频序列并保持帧间的一致性。
- 专家自适应LayerNorm(AdaLN):Transformer使用专家自适应LayerNorm分别处理文本和视频嵌入。这允许模型对齐文本和视频的不同特征空间,实现这两种模态的平滑融合。
2.3 CogVideoX-5B的渐进训练技术#
CogVideoX-5B使用多种渐进训练技术来提高其在视频生成过程中的性能和稳定性。
关键渐进训练策略
- 混合时长训练:模型在同一批次中训练不同长度的视频。这种技术增强了模型的泛化能力,使其能够生成不同时长的视频,同时保持一致的质量。
- 分辨率渐进训练:模型首先在低分辨率视频上进行训练,然后逐渐在高分辨率视频上进行微调。这种方法允许模型在高分辨率下精细理解之前学习视频的基本结构和内容。
- 显式均匀采样:为了稳定训练过程,CogVideoX-5B使用显式均匀采样,为每个数据并行等级设置不同的时间步长采样间隔。这种方法加速了收敛,确保模型在整个视频序列中有效学习。
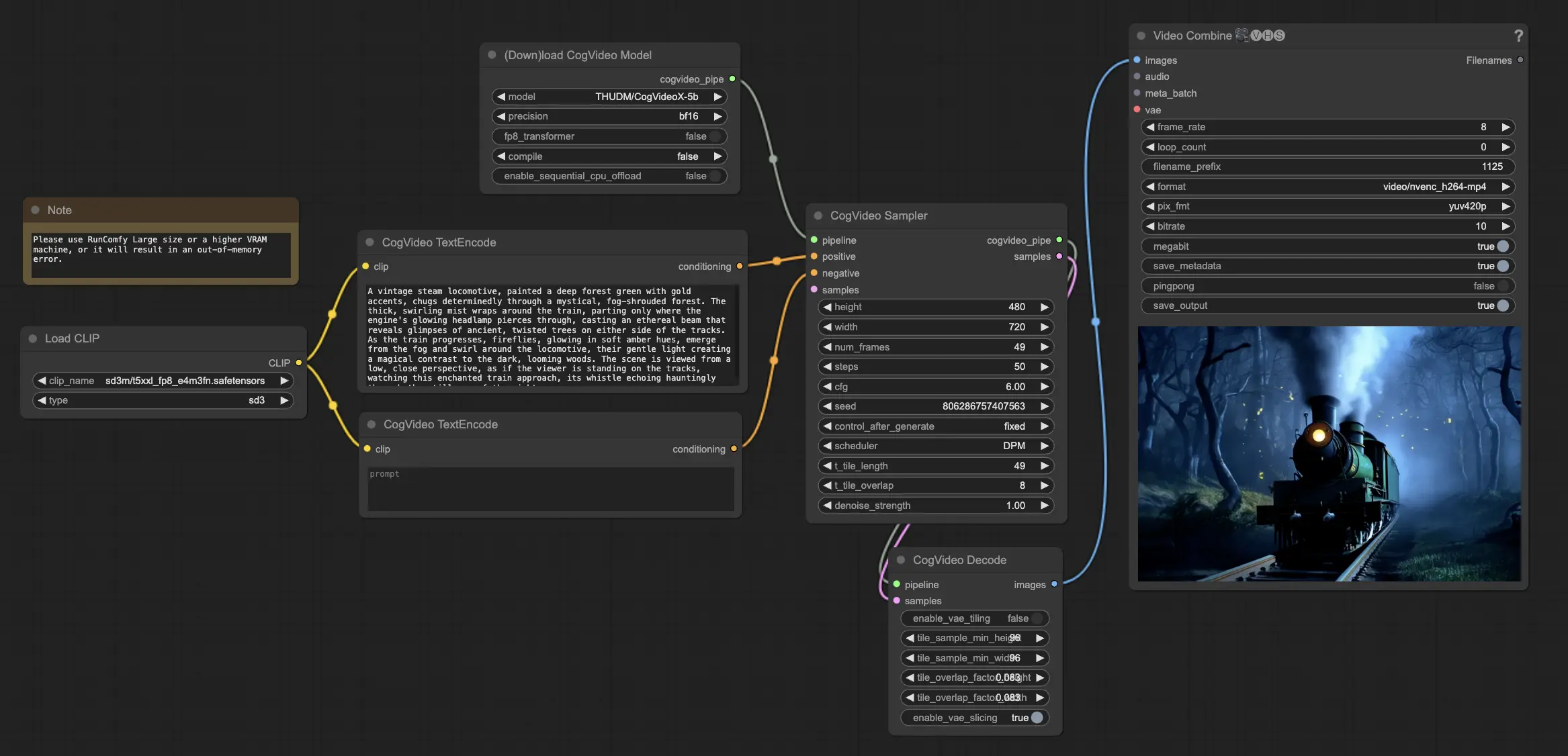
3. 如何使用ComfyUI的CogVideoX-5B工作流#
第一步:加载CogVideoX-5B模型#
首先将CogVideoX-5B模型加载到ComfyUI工作流中。CogVideoX-5B模型已预加载在RunComfy的平台上。
第二步:输入您的文本提示#
在指定节点中输入您想要的文本提示,以引导CogVideoX-5B视频生成过程。CogVideoX-5B擅长解释和转换文本提示为动态视频内容。
4. 许可协议#
CogVideoX模型的代码根据 Apache 2.0 License 发布。
CogVideoX-2B模型(包括其对应的Transformers模块和VAE模块)根据 Apache 2.0 License 发布。
CogVideoX-5B模型(Transformers模块)根据 CogVideoX LICENSE 发布。