Segment Anything V2 (SAM2) | 视频分割
由 Meta AI 开发的 Segment Anything V2 (SAM2) 是一个突破性的 AI 模型,它简化了图像和视频中的对象分割。其智能分割能力结合多种输入方法,为 AI 艺术家简化了工作流程。SAM2 增强的视频分割、减少的交互时间和快速的推理速度使其成为推动 AI 驱动艺术创作边界的强大工具。ComfyUI-LivePortraitKJ 节点由 Kijai 创建,此工作流程完全由他开发。ComfyUI Segment Anything V2 (SAM2) 工作流程
- 完全可操作的工作流
- 没有缺失的节点或模型
- 无需手动设置
- 具有惊艳的视觉效果
ComfyUI Segment Anything V2 (SAM2) 示例
ComfyUI Segment Anything V2 (SAM2) 描述
Segment Anything V2,又名 SAM2,是由 Meta AI 开发的突破性 AI 模型,革新了图像和视频中的对象分割。
什么是 Segment Anything V2 (SAM2)?
Segment Anything V2 是一个最先进的 AI 模型,能够无缝分割图像和视频中的对象。这是第一个能够处理图像和视频分割任务的统一模型,具有卓越的准确性和效率。Segment Anything V2 (SAM2) 在其前身 Segment Anything Model (SAM) 的成功基础上,扩展了其在视频领域的提示功能。
使用 Segment Anything V2 (SAM2),用户可以通过点击、边界框或蒙版等多种输入方法选择图像或视频帧中的对象。然后,模型智能地分割所选对象,允许精确提取和操作视觉内容中的特定元素。
Segment Anything V2 (SAM2) 的亮点
- 最先进的性能:SAM2 在图像和视频对象分割领域表现优于现有模型。它在图像分割任务中超越了其前身 SAM,设定了新的准确性和精确性基准。
- 图像和视频的统一模型:SAM2 是第一个为图像和视频对象分割提供统一解决方案的模型。这种集成简化了 AI 艺术家的工作流程,因为他们可以使用单一模型处理各种分割任务。
- 增强的视频分割能力:SAM2 在视频对象分割方面表现出色,特别是在跟踪对象部分方面。它优于现有的视频分割模型,在跨帧分割对象时提供了更高的准确性和一致性。
- 亮点 A. 减少的交互时间:与现有的交互式视频分割方法相比,SAM2 需要更少的用户交互时间。这种效率使 AI 艺术家能够更多地专注于他们的创意愿景,而不是手动分割任务。
- 简单的设计和快速的推理:尽管具有先进功能,SAM2 保持了简单的架构设计,并提供快速的推理速度。这确保了 AI 艺术家可以无缝地将 SAM2 集成到他们的工作流程中,而不牺牲性能或效率。
Segment Anything V2 (SAM2) 的工作原理
SAM2 通过引入会话内存模块,将 SAM 的提示功能扩展到视频中,该模块捕获目标对象信息,实现跨帧的对象跟踪,即使在临时消失的情况下。流式架构一次处理一个视频帧,当内存模块为空时,表现如同处理图像的 SAM。这允许实时视频处理和 SAM 能力的自然泛化。SAM2 还支持基于用户提示的交互式蒙版预测校正。该模型使用具有流式内存的 transformer 架构,并在 SA-V 数据集上进行训练,这是使用模型内循环数据引擎收集的最大的视频分割数据集,通过用户交互改进模型和数据。
如何在 ComfyUI 中使用 Segment Anything V2 (SAM2)
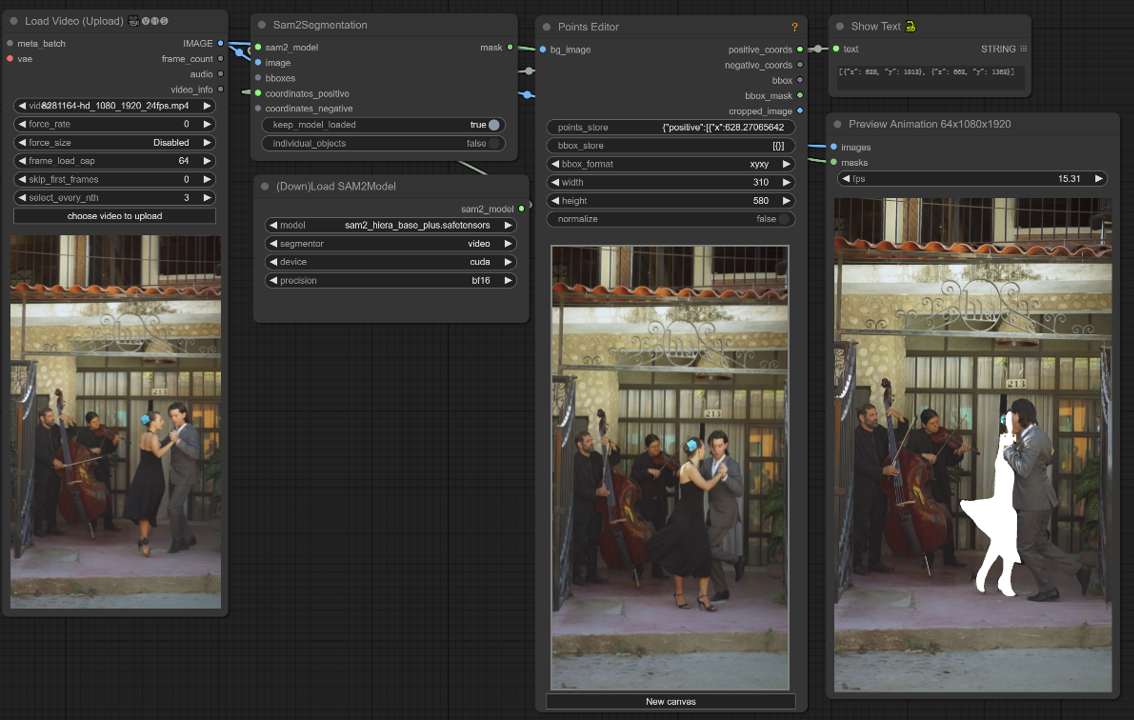
此 ComfyUI 工作流程支持通过点击/点选择视频帧中的对象。
1. 加载视频(上传)
视频加载:选择并上传您希望处理的视频。

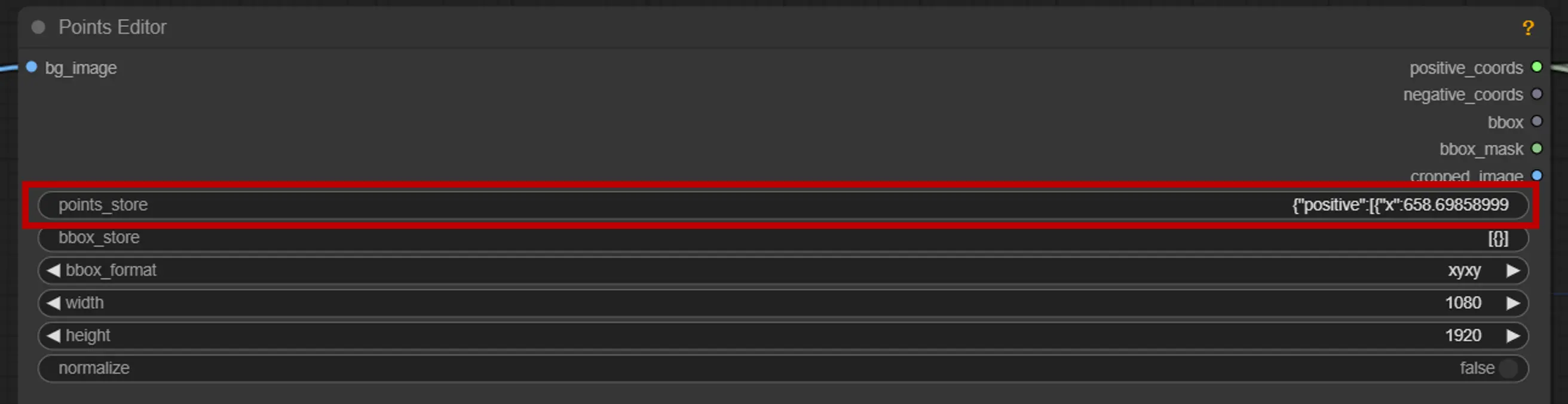
2. 点编辑器
关键点:在画布上放置三个关键点—positive0、positive1 和 negative0:
positive0 和 positive1 标记您要分割的区域或对象。
negative0 有助于排除不需要的区域或干扰。

points_store:允许您根据需要添加或删除点以优化分割过程。
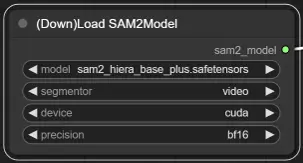
3. SAM2 模型选择
模型选项:从可用的 SAM2 模型中选择:tiny、small、large 或 base_plus。较大的模型提供更好的结果,但需要更多的加载时间。
欲了解更多信息,请访问 。



