

FLUX LoRA 在AI社区中获得了极大的欢迎,尤其是在那些希望使用自己的数据集微调AI模型的人群中。这种方法允许您轻松地将现有的FLUX模型适应于您的独特数据集,使其高度可定制且高效,适用于各种创意项目。如果您已经熟悉ComfyUI,使用ComfyUI FLUX LoRA训练工作流程来训练您的FLUX LoRA模型将会非常轻松。工作流程和相关节点由Kijai创建,感谢他所做的贡献!有关更多信息,请查看 Kijai's GitHub。
ComfyUI FLUX LoRA 训练工作流程是一个强大的过程,旨在训练FLUX LoRA模型。使用ComfyUI进行训练具有多种优势,尤其适合那些已经熟悉其界面的用户。通过FLUX LoRA训练,您可以使用用于推理的相同模型,确保在相同Python环境中工作时没有兼容性问题。此外,您可以构建工作流程来比较不同的设置,从而增强您的训练过程。本教程将指导您如何在ComfyUI中设置和使用FLUX LoRA训练。
我们将涵盖:
在为FLUX LoRA训练准备训练数据时,确保目标主体的高质量图像是至关重要的。
在本例中,我们正在训练一个FLUX LoRA模型来生成特定网红的图像。为此,您需要一组高质量的网红图像,展示其在不同姿势和环境中的样子。使用 ComfyUI Consistent Character workflow 是收集这些图像的便捷方式,该工作流程使您可以轻松生成展示同一角色在不同姿势中保持外观一致的图像集合。对于我们的训练数据集,我们选择了五张高质量的网红图像,展示了其在不同姿势和环境中的样子,确保数据集足够强大,以便FLUX LoRA训练学习产生一致和准确输出所需的复杂细节。

您还可以根据自己的具体需求收集数据集——FLUX LoRA训练灵活适用于各种类型的数据。
FLUX LoRA训练工作流程由多个关键节点组成,这些节点协同工作以训练和验证您的模型。以下是主要节点的详细概述,分为三个部分:数据集、设置和初始化、以及训练。
数据集部分由两个基本节点组成,帮助您配置和自定义训练数据:TrainDatasetGeneralConfig 和 TrainDatasetAdd。
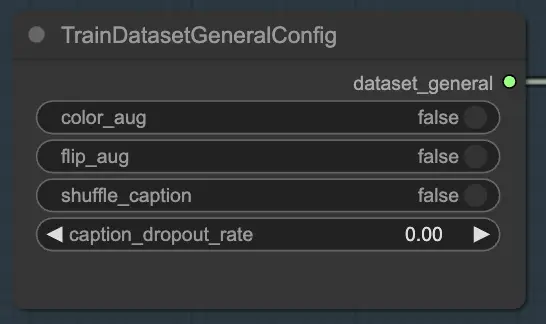
TrainDatasetGeneralConfig 节点是您定义FLUX LoRA训练中训练数据集整体设置的地方。此节点让您可以控制数据增强和预处理的各个方面。例如,您可以选择启用或禁用 颜色增强,这可以帮助提高模型在不同颜色变化中的泛化能力。类似地,您可以切换 翻转增强 来随机水平翻转图像,提供更多样化的训练样本。此外,您可以选择 打乱每个图像关联的标题,引入随机性并减少过拟合。标题丢弃率 允许您在训练期间随机丢弃标题,这可以帮助模型更好地应对缺失或不完整的标题。
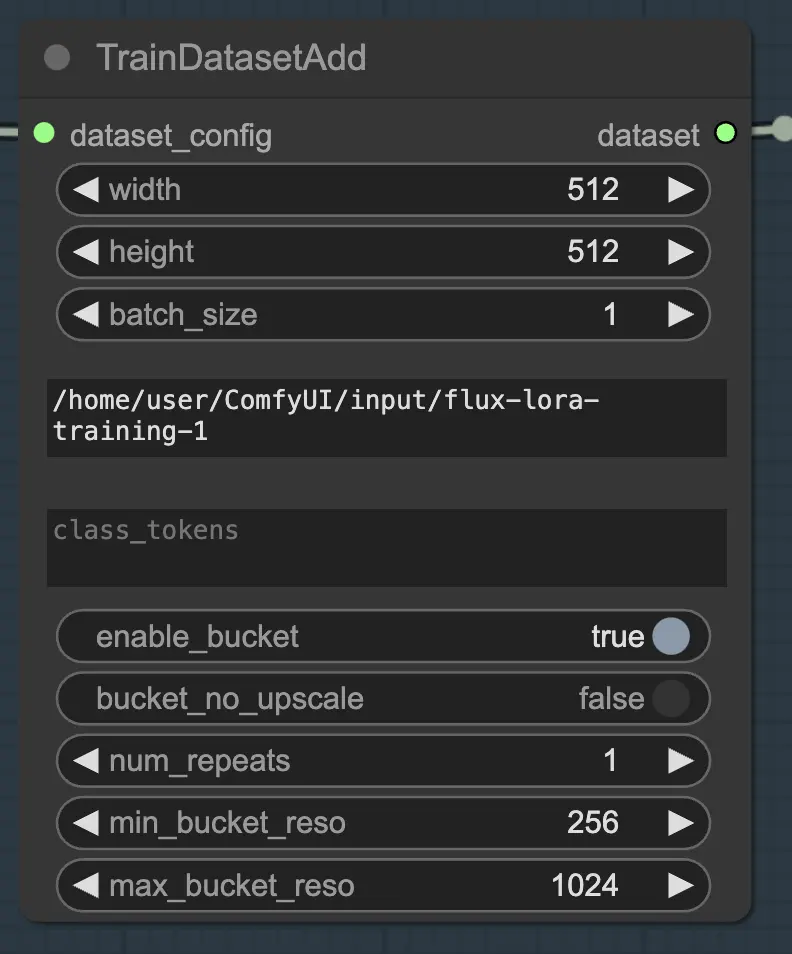
TrainDatasetAdd 节点是您指定要包含在FLUX LoRA训练中的每个独立数据集的详细信息的地方。
为了充分利用此节点,正确组织您的训练数据是很重要的。使用RunComfy的文件浏览器时,将训练数据放在 /home/user/ComfyUI/input/{file-name} 目录中,其中 {file-name} 是您为数据集分配的有意义的名称。
一旦您将训练数据放置在适当的目录中,您需要在 TrainDatasetAdd 节点的 image_dir 参数中提供该目录的路径。这会告诉节点在哪里找到您的训练图像。
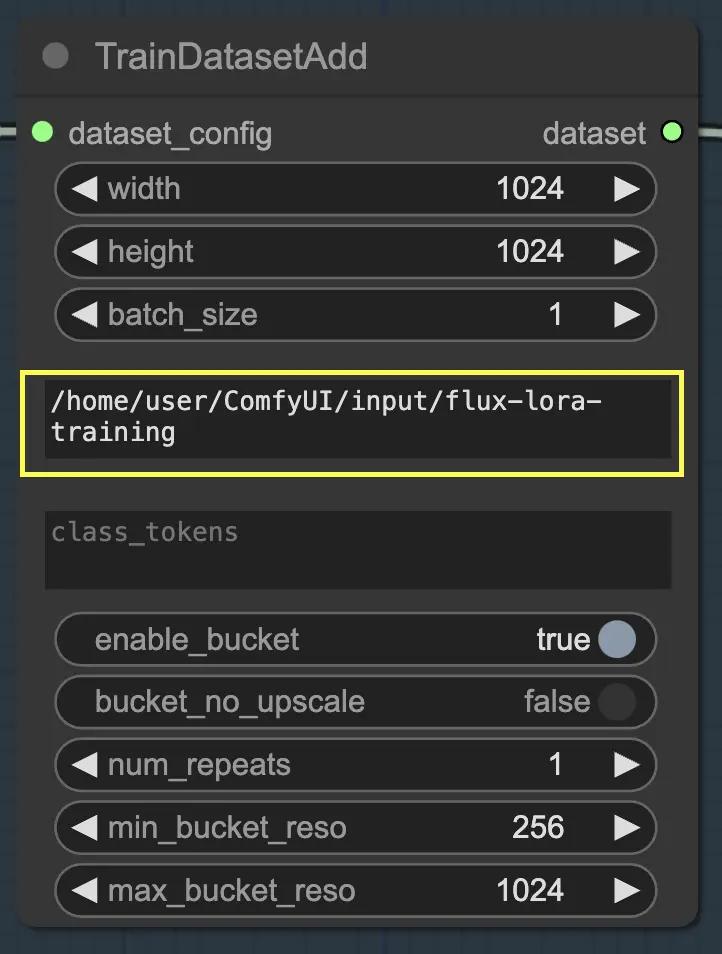
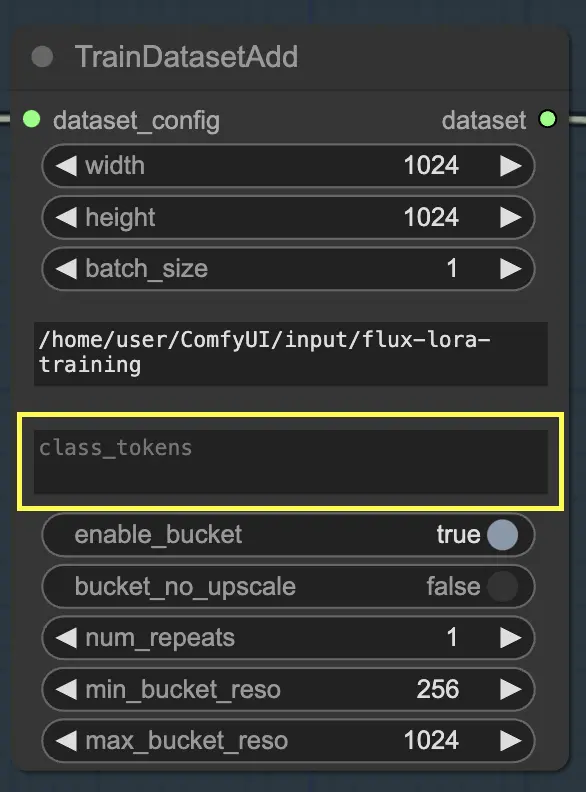
如果您的数据集受益于使用特定的类别标记或触发词,您可以在 class_tokens 参数中输入它们。类别标记是附加到每个标题之前的特殊词语或短语,帮助指导模型的生成过程。例如,如果您正在训练包含各种动物物种的数据集,您可以使用诸如 "dog"、"cat" 或 "bird" 等类别标记来指示生成图像中所需的动物。当您稍后在提示中使用这些类别标记时,您可以控制希望模型生成的具体方面。
除了 image_dir 和 class_tokens 参数外,TrainDatasetAdd 节点还提供了其他几个选项来微调数据集。您可以设置图像的分辨率(宽度和高度)、指定训练的批量大小,并确定数据集在每个周期中应重复的次数。
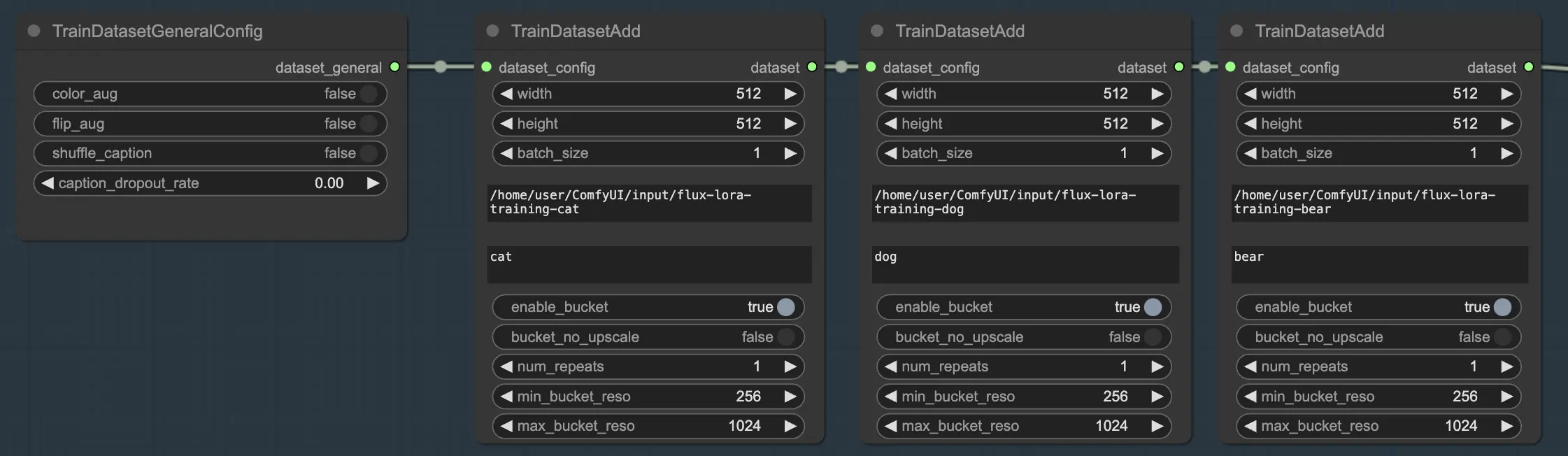
FLUX LoRA训练的一个强大功能是能够无缝结合多个数据集。在FLUX LoRA训练工作流程中,有三个依次连接的 TrainDatasetAdd 节点。每个节点代表一个具有其独特设置的独立数据集。通过将这些节点连接在一起,您可以创建一个丰富而多样的训练集,结合来自不同来源的图像和标题。
为了说明这一点,让我们考虑一个场景,您有三个独立的数据集:一个是猫,一个是狗,另一个是熊。您可以设置三个TrainDatasetAdd节点,每个节点专用于其中一个数据集。在第一个节点中,您将在 image_dir 参数中指定 "cats" 数据集的路径,将 class token 设置为 "cat",并根据需要调整其他参数,如分辨率和批量大小。同样,您可以配置第二个和第三个节点用于 "dogs" 和 "bears" 数据集。
这种方法允许FLUX LoRA训练过程利用多种图像,提高模型在不同类别中的泛化能力。
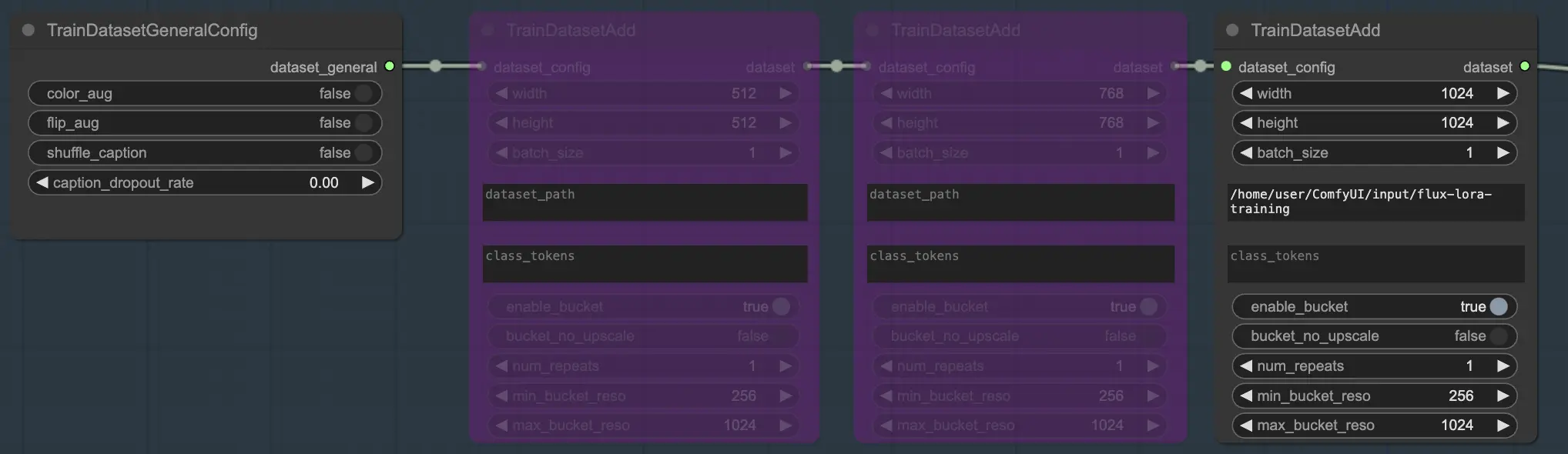
在我们的示例中,我们仅使用一个数据集来训练模型,因此我们启用了一个 TrainDatasetAdd 节点,并绕过了其他两个。您可以这样设置:
设置和初始化部分是您配置FLUX LoRA训练的关键组件和参数的地方。此部分包括几个必不可少的节点,这些节点共同设置您的训练环境。
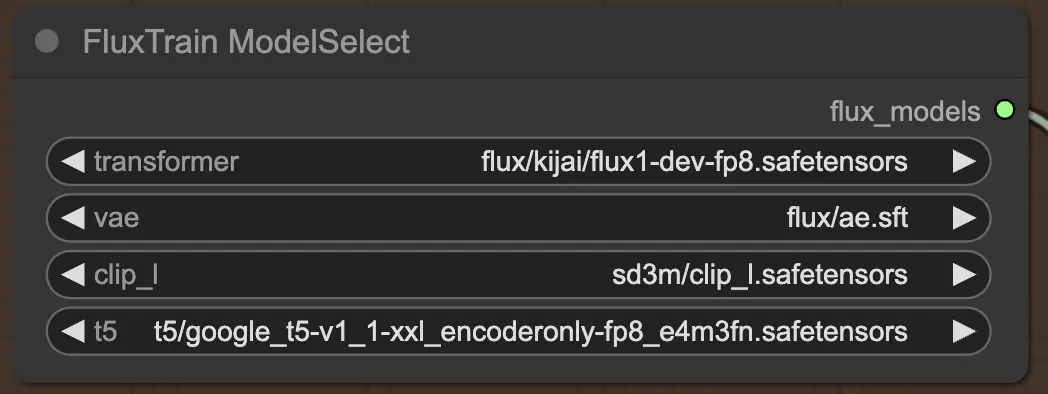
首先,您有 FluxTrainModelSelect 节点,负责选择将在FLUX LoRA训练中使用的FLUX模型。此节点允许您指定四个关键模型的路径:transformer、VAE(变分自编码器)、CLIP_L(对比语言-图像预训练)和T5(文本到文本转换器)。这些模型构成了FLUX训练过程的骨干,并已在RunComfy平台上设置。
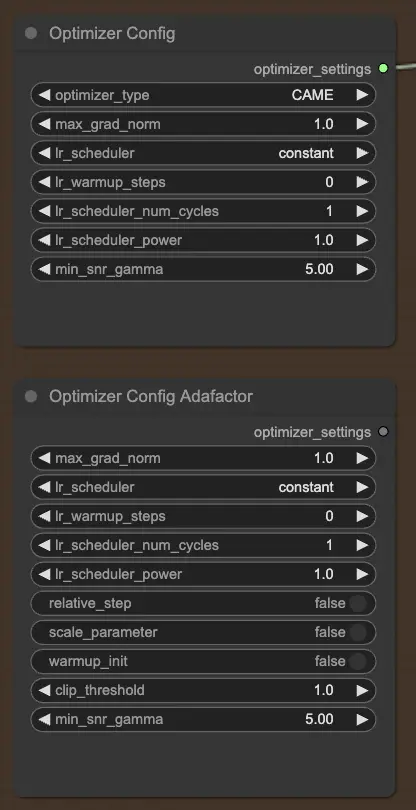
OptimizerConfig 节点对于在FLUX LoRA训练中设置优化器至关重要,优化器决定了训练期间模型参数的更新方式。您可以选择优化器类型(例如,AdamW、CAME),设置最大梯度范数以进行梯度裁剪以防止梯度爆炸,并选择学习率调度器(例如,常数、余弦退火)。此外,您可以微调优化器特定的参数,如预热步骤和调度器功率,并提供额外参数以进一步自定义。
如果您更喜欢以内存效率高且能够处理大型模型而闻名的Adafactor优化器,您可以使用 OptimizerConfigAdafactor 节点。
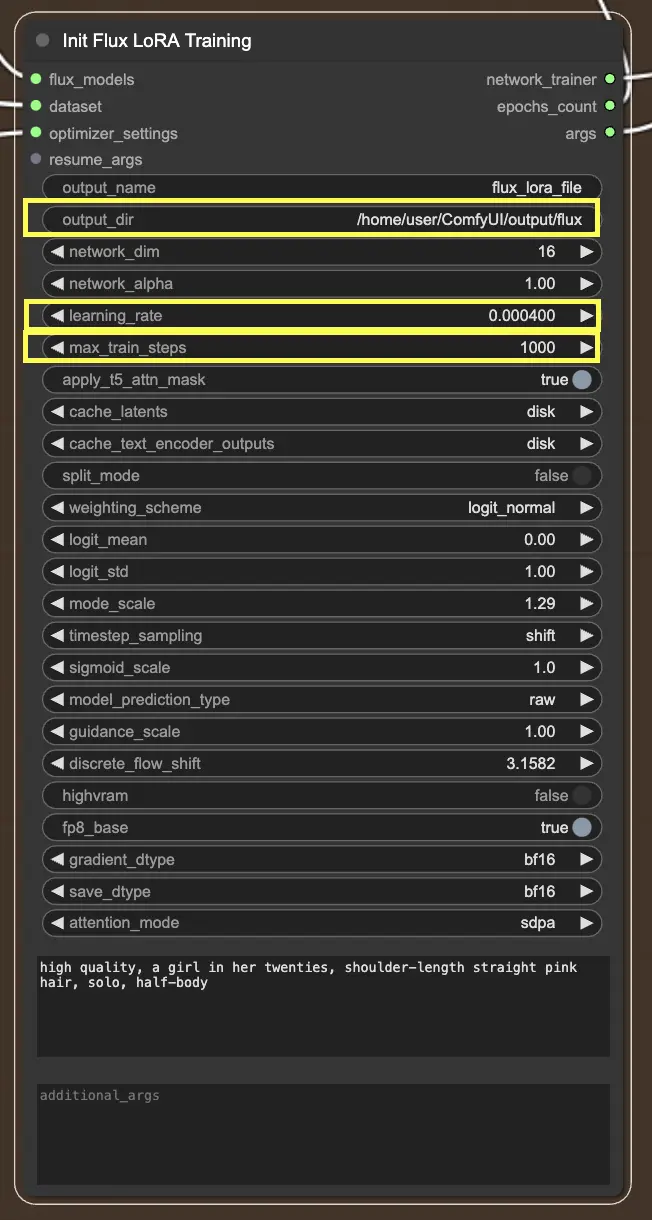
InitFluxLoRATraining 节点是所有关键组件汇聚的中心枢纽,以启动FLUX LoRA训练过程。
在InitFluxLoRATraining节点中需要指定的关键事项之一是输出目录,即保存训练模型的位置。在RunComfy平台上,您可以选择 /home/user/ComfyUI/output/{file_name} 作为输出的位置。完成训练后,您可以在文件浏览器中查看它。
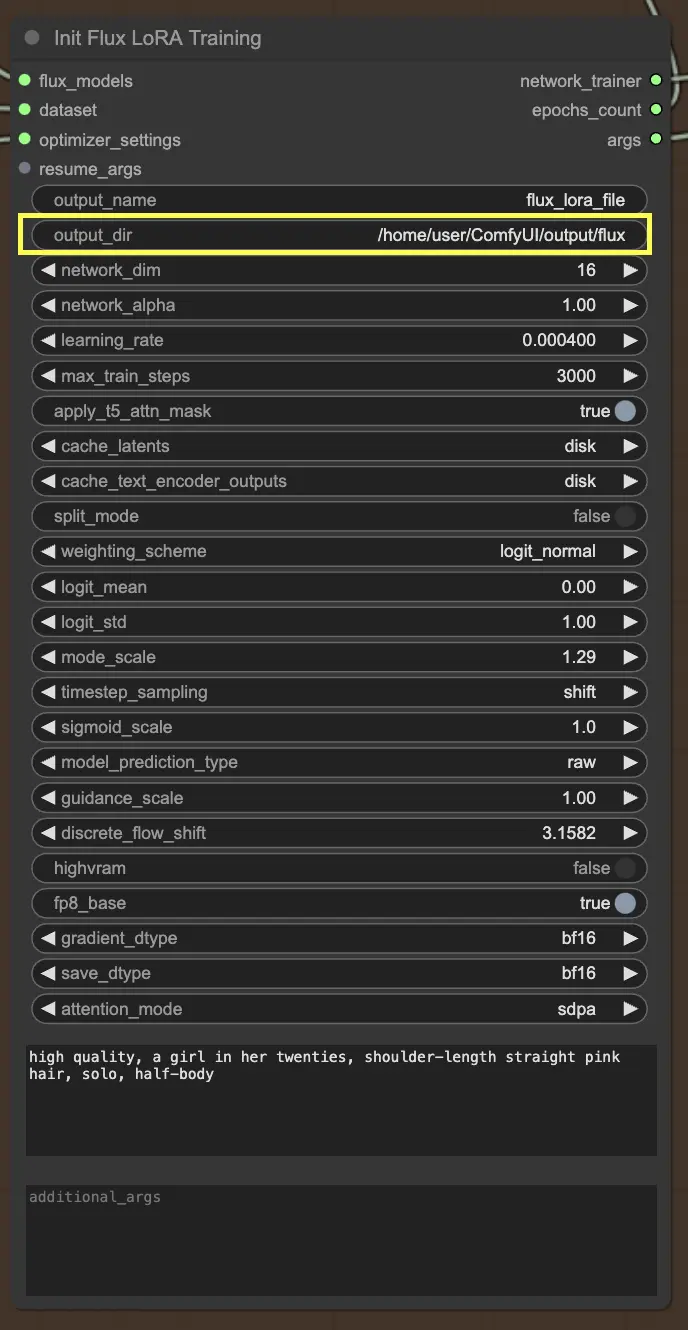
接下来,您需要设置网络尺寸和学习率。网络尺寸决定了LoRA网络的大小和复杂性,而学习率则控制了模型学习和适应的速度。
另一个需要考虑的重要参数是 max_train_steps。它决定了您希望训练过程运行的时间长度,或者换句话说,在模型完全成熟之前您希望模型进行多少步。您可以根据您的具体需求和数据集的大小调整此值。关键在于找到模型学习足够多以产生良好输出的最佳位置!
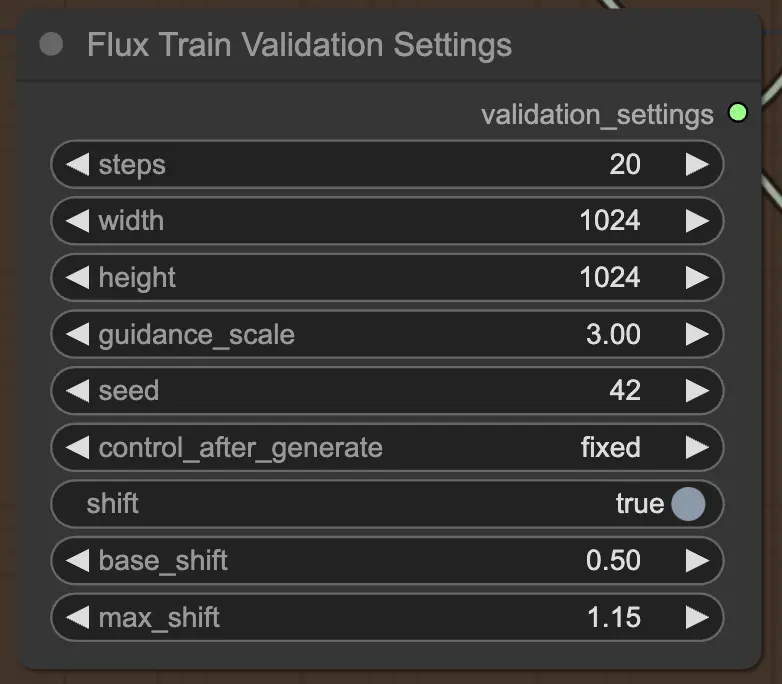
最后,FluxTrainValidationSettings 节点允许您配置用于评估模型在FLUX LoRA训练过程中的性能的验证设置。您可以设置验证步骤的数量、图像大小、指导比例和种子以确保可重复性。此外,您可以选择时间步采样方法,并调整sigmoid比例和偏移参数,以控制时间步调度并提高生成图像的质量。
FLUX LoRA训练的训练部分是魔法发生的地方。它分为四个部分:Train_01、Train_02、Train_03 和 Train_04。每个部分代表FLUX LoRA训练过程中的不同阶段,允许您逐步细化和改进模型。
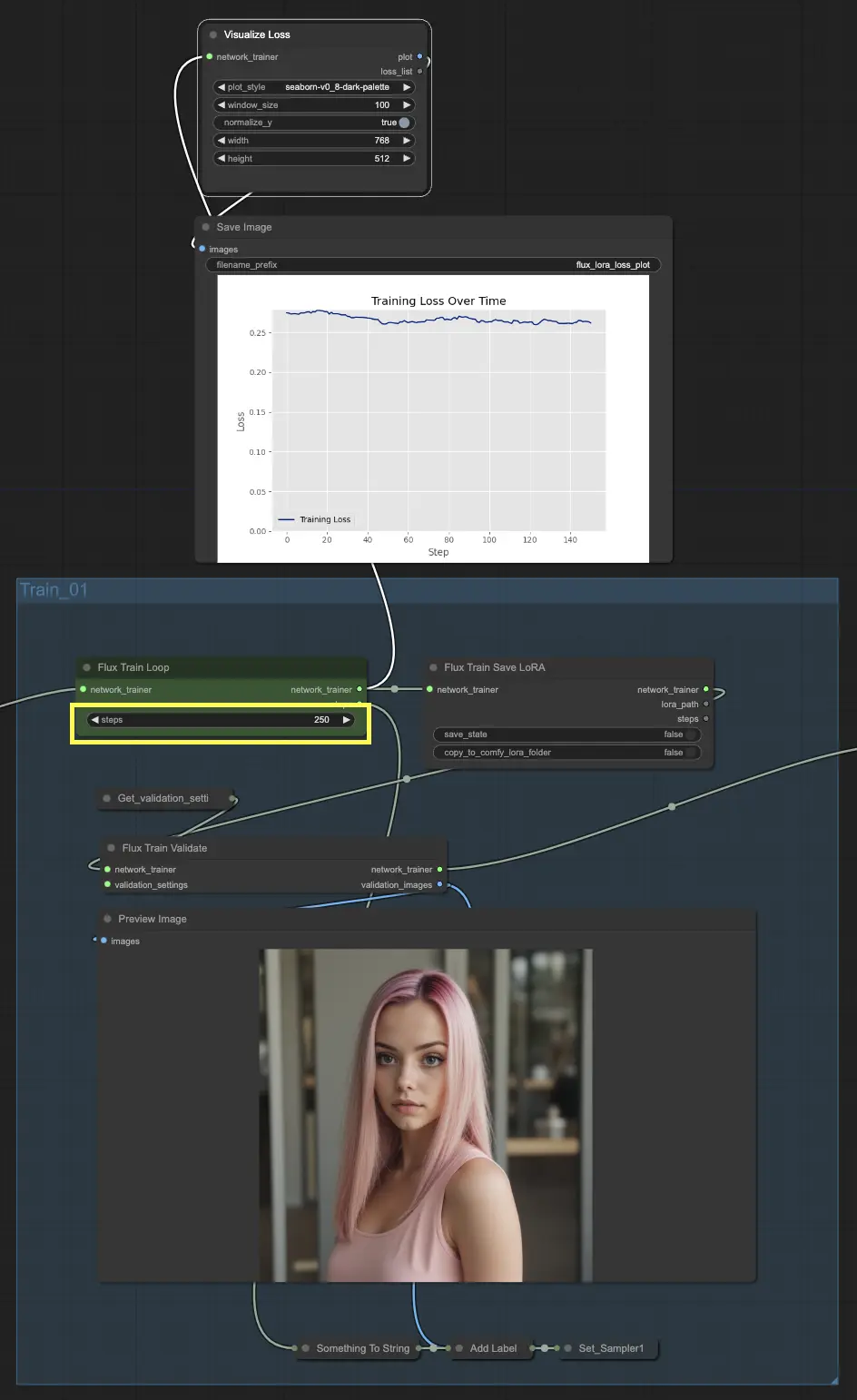
让我们从 Train_01 开始。这是初始训练循环发生的地方。本节的明星是 FluxTrainLoop 节点,负责执行指定步数的训练循环。在这个例子中,我们设置为250步,但您可以根据您的需要调整这个。训练循环完成后,训练好的模型会传递给 FluxTrainSave 节点,该节点会定期保存模型。这可以确保您在训练的不同阶段拥有模型的检查点,这对于跟踪进度和从任何意外中恢复都很有用。
但训练不仅仅是保存模型。我们还需要验证它的性能,以查看它的表现如何。这就是 FluxTrainValidate 节点的作用。它使用验证数据集测试训练好的模型。这个数据集与训练数据分开,有助于评估模型在未见过的示例上的泛化能力。FluxTrainValidate 节点根据验证数据生成示例图像,给您一个视觉表现此阶段模型输出的方式。
为了跟踪训练进度,我们有 VisualizeLoss 节点。这个方便的节点可视化训练损失随时间的变化,让您看到模型学习的好坏,以及它是否正在收敛到一个好的解决方案。就像有一个个人教练,跟踪您的进度并帮助您保持正轨。
在FLUX LoRA训练的 Train_02 中,继续从 Train_01 开始,输出进一步训练指定的额外步数(例如250步)。Train_03 和 Train_04 遵循类似的模式,更新连接以实现平滑过渡。每个阶段输出一个FLUX LoRA模型,允许您测试和比较性能。
在我们的示例中,我们选择仅使用 Train_01 和 Train_02,每个运行250步。我们暂时绕过了 Train_03 和 Train_04。但请随意根据您的具体需求和资源进行实验和调整训练部分和步骤的数量。
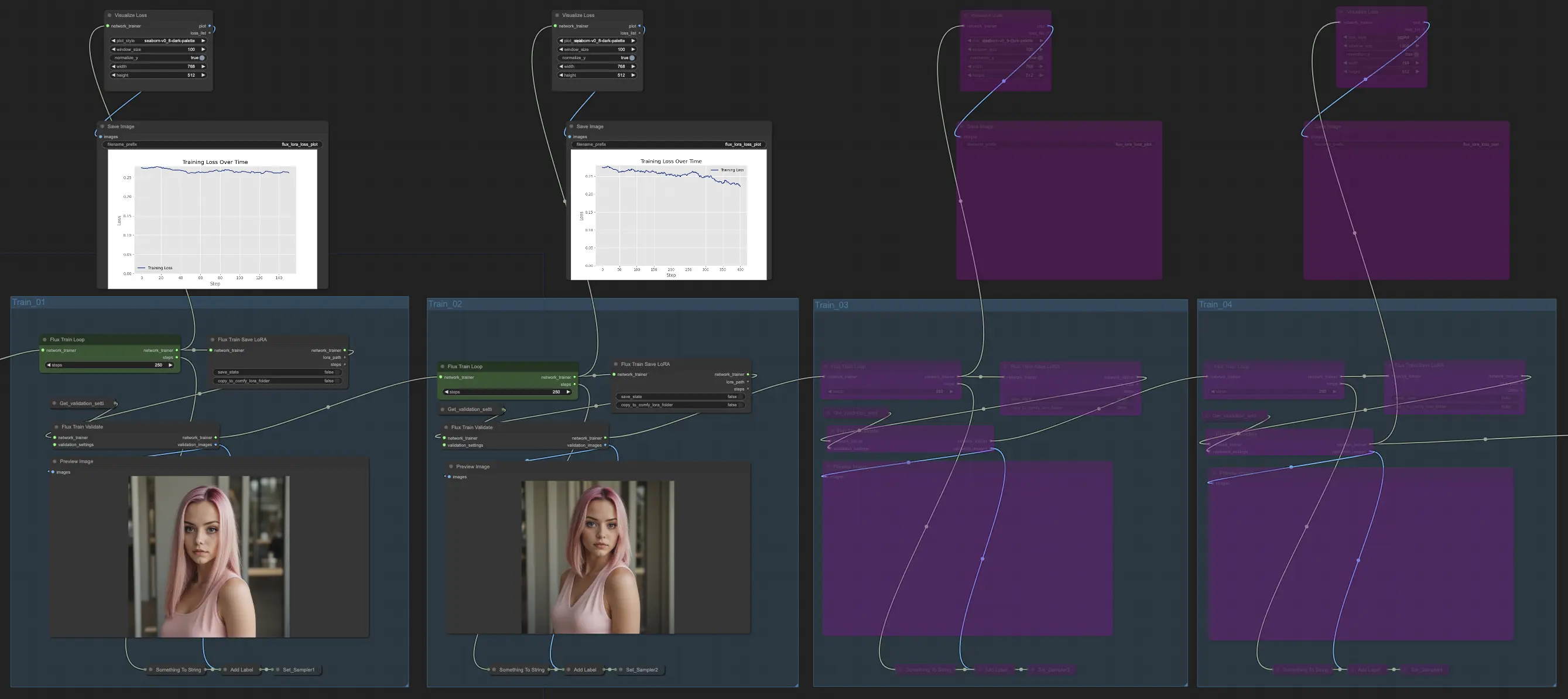
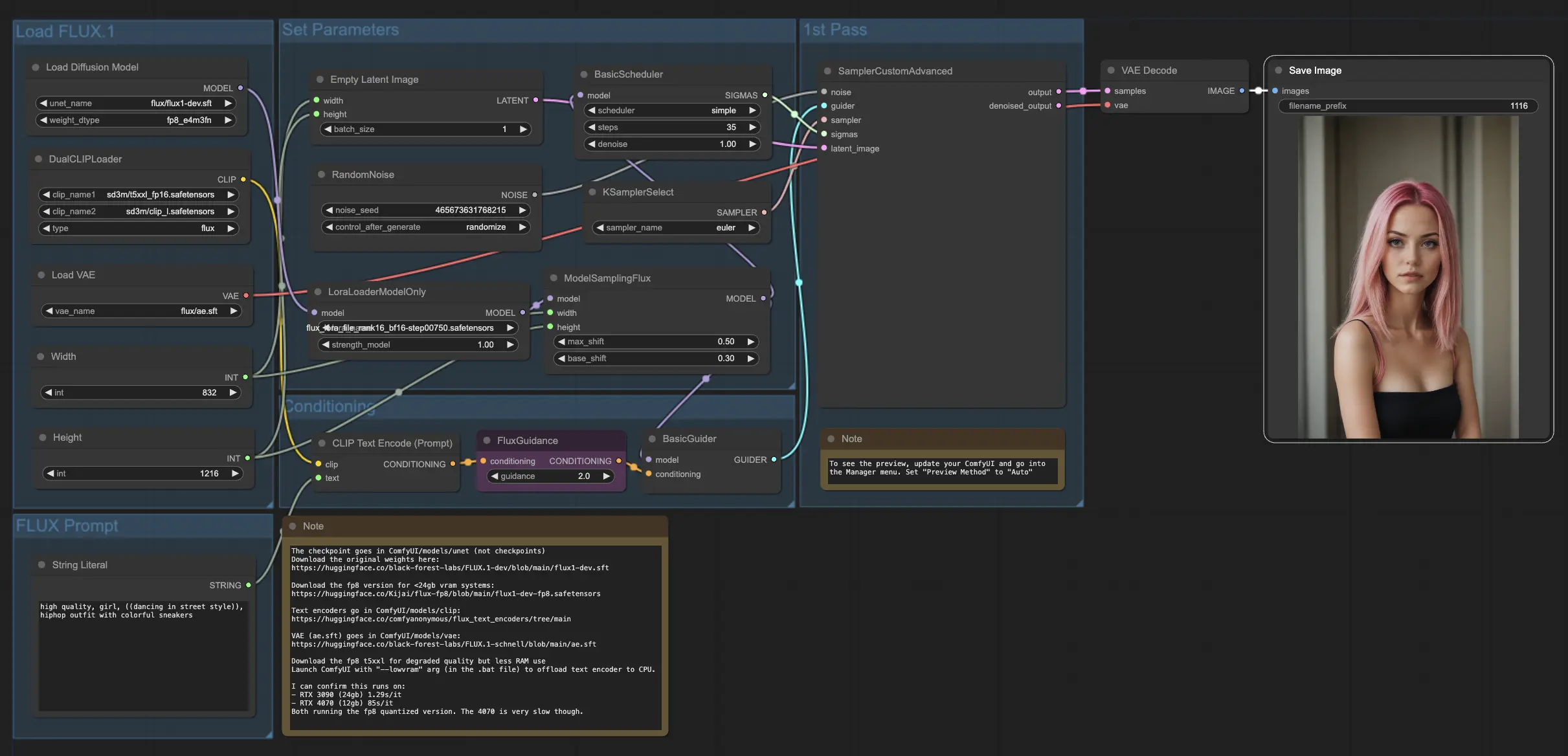
一旦您拥有FLUX LoRA模型,您可以将其整合到 FLUX LoRA workflow 中。用您训练的模型替换现有的LoRA模型,然后测试结果以评估其性能。
在我们的示例中,我们使用FLUX LoRA工作流程通过应用FLUX LoRA模型生成更多网红图像,并观察其性能。
查看许可证文件:
flux/model_licenses/LICENSE-FLUX1-dev
flux/model_licenses/LICENSE-FLUX1-schnell
FLUX.1 [dev]json [dev] 模型由Black Forest Labs. Inc.根据FLUX.1 [dev] 非商业许可证授权。版权所有 Black Forest Labs. Inc.
BLACK FOREST LABS, INC. 在任何情况下均不对因使用此模型而产生的任何索赔、损害或其他责任承担责任,无论是合同、侵权或其他原因。
RunComfy 是首选的 ComfyUI 平台,提供 ComfyUI 在线 环境和服务,以及 ComfyUI 工作流 具有惊艳的视觉效果。 RunComfy还提供 AI Playground, 帮助艺术家利用最新的AI工具创作出令人惊叹的艺术作品。







