Hunyuan Video | 从文本到视频
Hunyuan Video是腾讯开发的开源视频基础模型,其视频生成性能可媲美甚至优于领先的闭源模型。通过利用数据策展、联合图像视频训练和优化的基础设施等先进技术,Hunyuan Video实现了高质量、大规模的视频生成。ComfyUI Hunyuan Video 工作流程
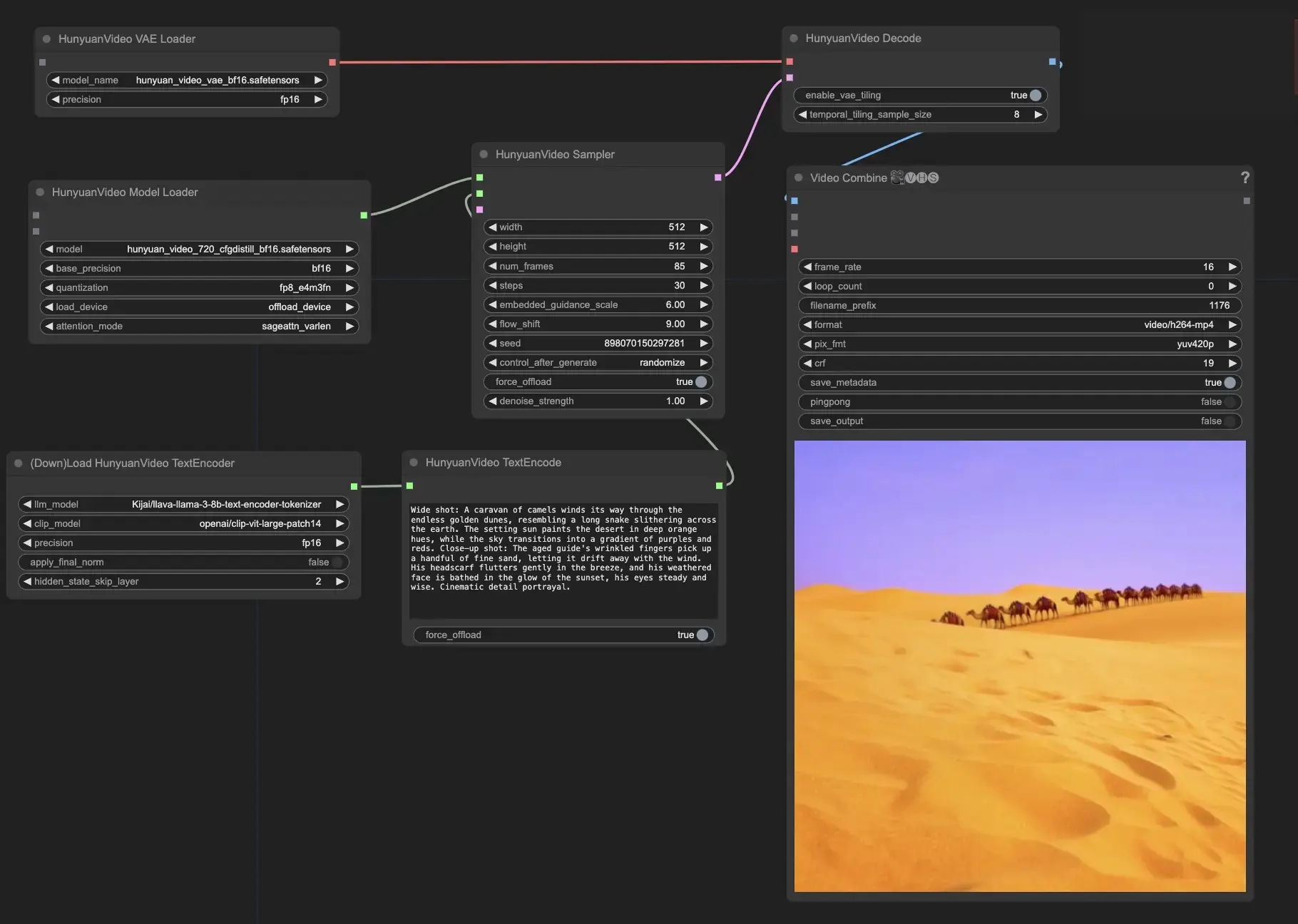
想要运行这个工作流吗?
- 完全可操作的工作流
- 没有缺失的节点或模型
- 无需手动设置
- 具有惊艳的视觉效果
ComfyUI Hunyuan Video 示例
ComfyUI Hunyuan Video 描述
是一个创新的开源视频基础模型,提供与顶级闭源模型相媲美甚至更好的视频生成性能,由领先的科技公司腾讯开发。Hunyuan Video采用前沿技术进行模型学习,如数据策展、图像视频联合模型训练以及用于大规模模型训练和推理的高效基础设施。Hunyuan Video是拥有超过130亿参数的最大开源视频生成模型。
Hunyuan Video的关键特性包括
- Hunyuan Video提供用于生成图像和视频的统一架构。它使用了一种称为"双流到单流"的特殊Transformer模型设计。这意味着模型首先分别处理视频和文本信息,然后将它们结合在一起生成最终输出。这有助于模型更好地理解视觉和文本描述之间的关系。
- Hunyuan Video中的文本编码器基于多模态大语言模型(MLLM)。与其他流行的文本编码器如CLIP和T5-XXL相比,MLLM更擅长将文本与图像对齐。它还可以提供更详细的描述和内容推理。这有助于Hunyuan Video生成更准确匹配输入文本的视频。
- 为了有效处理高分辨率和高帧率视频,Hunyuan Video使用了带有CausalConv3D的3D变分自编码器(VAE)。该组件将视频和图像压缩到称为潜在空间的较小表示中。通过在这个压缩空间中工作,Hunyuan Video可以在不使用过多计算资源的情况下以原始分辨率和帧率训练和生成视频。
- Hunyuan Video包括一个提示重写模型,可以自动调整用户的输入文本以更好地适应模型的偏好。有两种模式可用:普通模式和大师模式。普通模式侧重于提高模型对用户指令的理解,而大师模式则强调创建视觉质量更高的视频。然而,大师模式有时可能会忽略文本中的某些细节,以使视频看起来更好。
在ComfyUI中使用Hunyuan Video
此节点和相关工作流程由Kijai开发。我们对Kijai的创新工作给予应有的赞誉。在RunComfy平台上,我们只是向社区展示他的贡献。
- 提供您的文本提示:在HunyuanVideoTextEncode节点中,在"prompt"字段中输入您想要的文本提示。有一些提示示例供您参考。
- 在HunyuanVideoSampler节点中配置输出视频设置:
- 将"width"和"height"设置为您喜欢的分辨率
- 将"num_frames"设置为所需的视频长度(以帧为单位)
- "steps"控制去噪/采样步骤的数量(默认值:30)
- "embedded_guidance_scale"决定提示指导的强度(默认值:6.0)
- "flow_shift"影响视频长度(值越大视频越短,默认值:9.0)

