EchoMimic | Audio-driven Portrait Animations
EchoMimic is a tool that enables you to create realistic talking heads and body gestures that seamlessly sync with the provided audio. By leveraging advanced AI techniques, EchoMimic analyzes the audio input and generates lifelike facial expressions, lip movements, and body language that perfectly match the spoken words and emotions. With EchoMimic, you can bring your characters to life and create animated content that captivates your audience.ComfyUI EchoMimic Workflow
- Fully operational workflows
- No missing nodes or models
- No manual setups required
- Features stunning visuals
ComfyUI EchoMimic Examples
ComfyUI EchoMimic Description
EchoMimic is a tool for generating lifelike audio-driven portrait animations. It utilizes deep learning techniques to analyze input audio and generate corresponding facial expressions, lip movements, and head gestures that closely match the emotional and phonetic content of the speech.
EchoMimic V2 was developed by a team of researchers from the Terminal Technology Department at Alipay, Ant Group, including Rang Meng, Xingyu Zhang, Yuming Li, and Chenguang Ma. For detailed information, please visit /. The ComfyUI_EchoMimic node was developed by /. All credit goes to their significant contribution.
EchoMimic V1 and V2
- EchoMimic V1: Realistic Audio-Driven Portrait Animations with Customizable Landmark Control
- EchoMimic V2: Simplified, Expressive, and Semi-Body Human Animations
The key difference is that EchoMimic V2 aims to achieve striking half-body human animation while simplifying unnecessary control conditions compared to EchoMimic V1. EchoMimic V2 uses a novel Audio-Pose Dynamic Harmonization strategy to enhance facial expressions and body gestures.
Strengths and Weaknesses of EchoMimic V2
Strengths:
- EchoMimic V2 generates highly realistic and expressive portrait animations driven by audio
- EchoMimic V2 extends animation to the upper body, not just the head region
- EchoMimic V2 reduces condition complexity while maintaining animation quality compared to EchoMimic V1
- EchoMimic V2 seamlessly incorporates headshot data to enhance facial expressions
Weaknesses:
- EchoMimic V2 requires an audio source matched to the portrait for best results
- EchoMimic V2 currently lacks pose synchronization code, using a default pose file
- Generating longer high-quality animations with EchoMimic V2 can be computationally intensive
- EchoMimic V2 works best on cropped portrait images rather than full-body shots
How to Use the ComfyUI EchoMimic Workflow
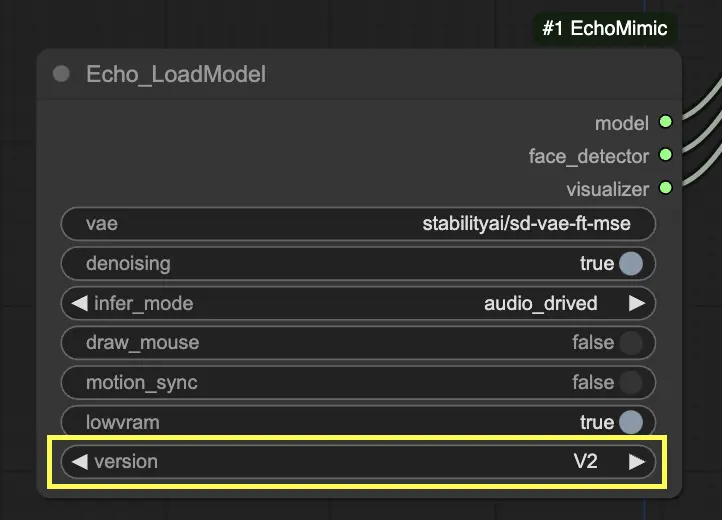
In the "Echo_LoadModel" node, you have the option to select between EchoMimic v1 and EchoMimic v2:
- EchoMimic v1: This version focuses on generating realistic audio-driven portrait animations with the ability to customize landmark control. It is well-suited for creating lifelike facial animations that closely match the input audio.
- EchoMimic v2: This version aims to simplify the animation process while delivering expressive and semi-body human animations. It extends the animation beyond just the facial region to include upper body movements. However, please note that the pose synchronization feature for v2 is not yet implemented in the current version of the ComfyUI workflow. If you select 'None' for the pose path, the default official pose file will be used instead.
Here is a step-by-step guide on using the provided ComfyUI workflow:
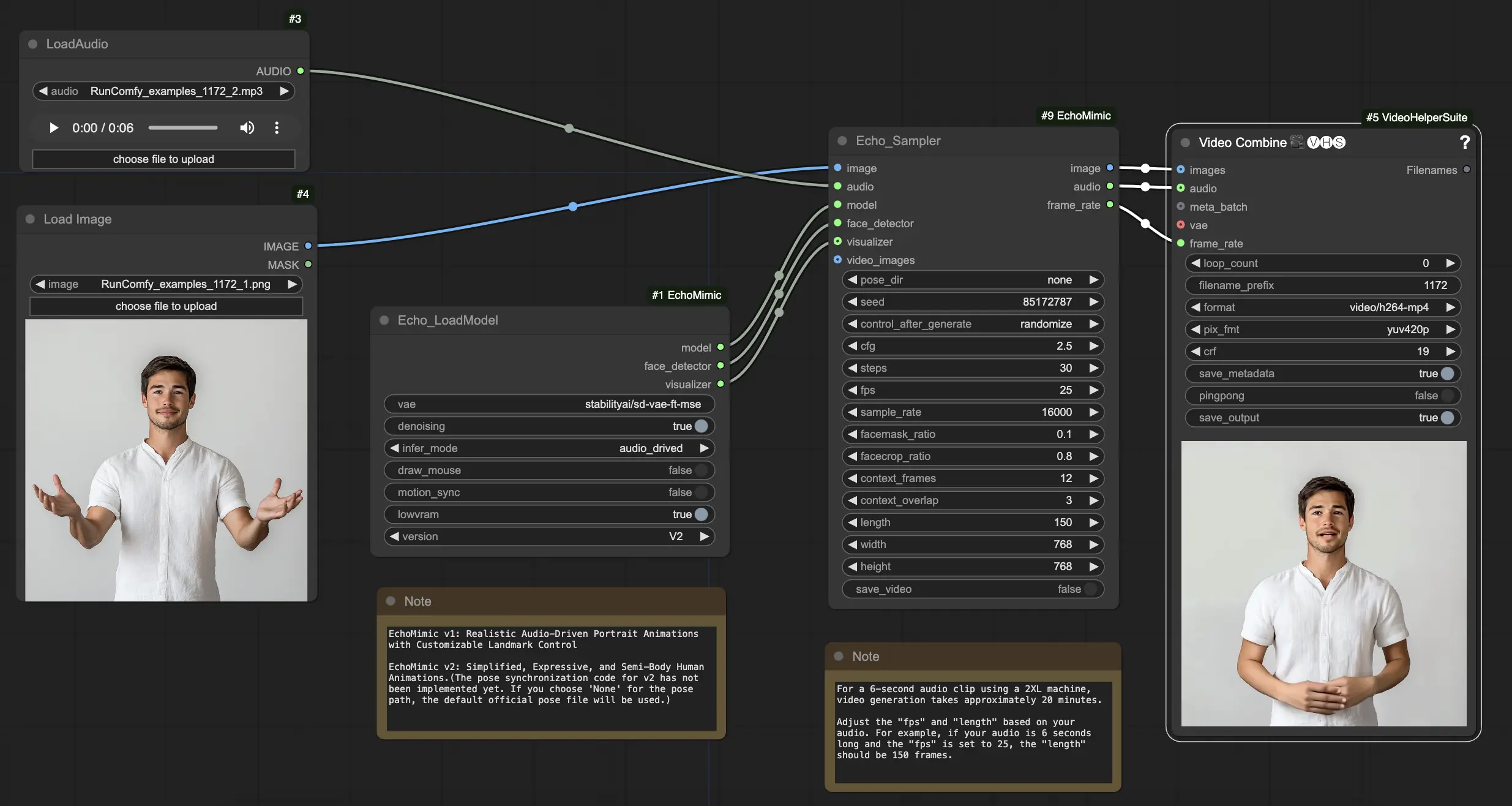
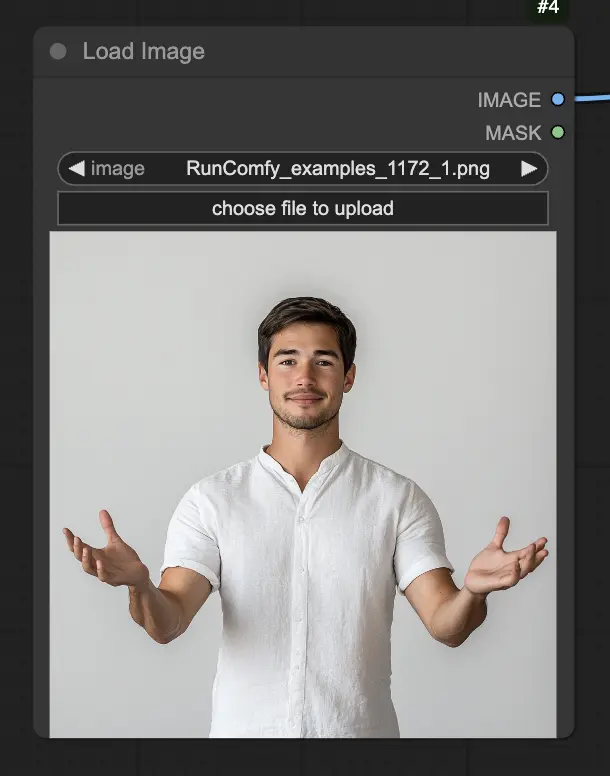
Step 1. Load your portrait image using the LoadImage node. This should be a close-up shot of the subject's head and shoulders.
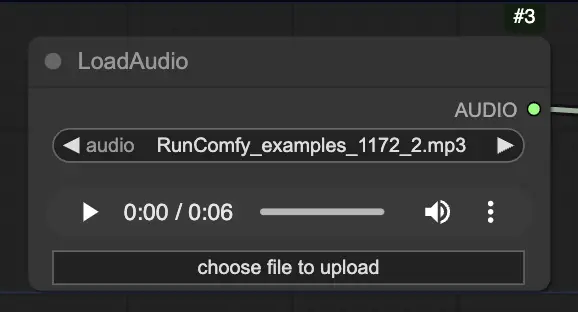
Step 2. Load your audio file using the LoadAudio node. The speech in the audio should match the identity of the portrait subject.
Step 3. Use the Echo_LoadModel node to load the EchoMimic model. Key settings:
- Choose the version (V1 or V2).
- Select the inference mode, e.g. audio-driven mode.
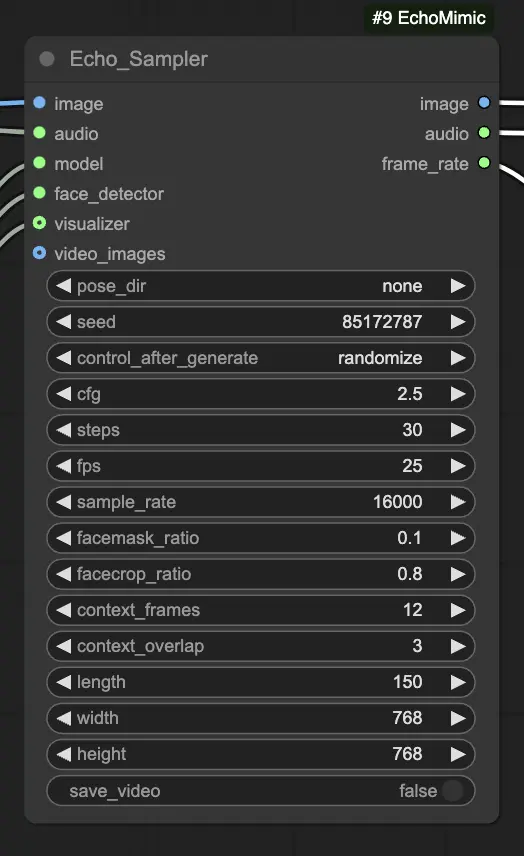
Step 4. Connect the image, audio, and loaded model to the Echo_Sampler node. Key settings:
- pose_dir: The directory path for the pose sequence files used in pose-driven animation modes. If set to "none", no pose sequence will be used.
- seed: The random seed for generating consistent results across runs. It should be an integer between 0 and MAX_SEED.
- cfg: The classifier-free guidance scale, controlling the strength of the audio conditioning. Higher values result in more pronounced audio-driven movements. The default value is 2.5, and it can range from 0.0 to 10.0.
- steps: The number of diffusion steps for generating each frame. Higher values produce smoother animations but take longer to generate. The default is 30, and it can range from 1 to 100.
- fps: The frame rate of the output video in frames per second. The default is 25, and it can range from 5 to 100.
- sample_rate: The sample rate of the input audio in Hz. The default is 16000, and it can range from 8000 to 48000 in increments of 1000.
- facemask_ratio: The ratio of the face mask area to the full image area. It controls the size of the region around the face that is animated. The default is 0.1, and it can range from 0.0 to 1.0.
- facecrop_ratio: The ratio of the face crop area to the full image area. It determines how much of the image is dedicated to the face region. The default is 0.8, and it can range from 0.0 to 1.0.
- context_frames: The number of past and future frames to use as context for generating each frame. The default is 12, and it can range from 0 to 50.
- context_overlap: The number of overlapping frames between adjacent context windows. The default is 3, and it can range from 0 to 10.
- length: The length of the output video in frames. It should be based on the duration of your input audio and the fps setting. For example, if your audio is 6 seconds long and the fps is set to 25, the length should be 150 frames. The length can range from 50 to 5000 frames.
- width: The width of the output video frames in pixels. The default is 512, and it can range from 128 to 1024 in increments of 64.
- height: The height of the output video frames in pixels. The default is 512, and it can range from 128 to 1024 in increments of 64.
Please note that video generation may take some time. For instance, creating a video from a 6-second audio clip using a 2XL machine on RunComfy takes about 20 minutes.
