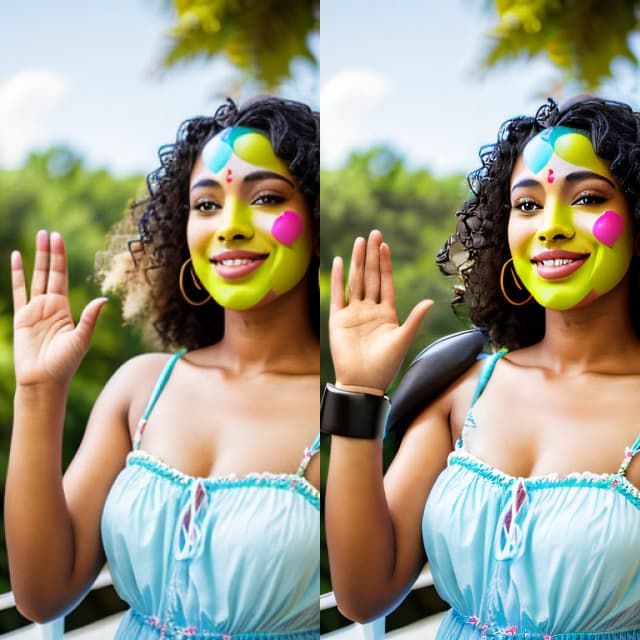Audioreactive Dancers Evolved
Der Audioreactive Dancers Evolved Workflow verwandelt Videomotive in fesselnde Animationen, die mit musikalischen Beats synchronisiert sind und vor dynamischen, geometrischen und psychedelischen Hintergründen spielen. Entwickelt für Flexibilität, ermöglicht es Benutzern, Videoframes, Maskierung, Audio-Reaktionsfähigkeit und Musterdetails zu steuern. Mit Funktionen wie Dilationsmasken, ControlNet und beat-synchronisierter Rauschanimation befähigt dieser ComfyUI-Workflow Kreative, Kunst, Klang und Bewegung zu verschmelzen und visuell immersive, rhythmische Erlebnisse mit audioreaktiven Visuals zu schaffen.ComfyUI Audioreactive Dancers Evolved Arbeitsablauf

- Voll funktionsfähige Workflows
- Keine fehlenden Nodes oder Modelle
- Keine manuelle Einrichtung erforderlich
- Beeindruckende Visualisierungen
ComfyUI Audioreactive Dancers Evolved Beispiele
ComfyUI Audioreactive Dancers Evolved Beschreibung
Erstellen Sie atemberaubende Videoanimationen, indem Sie Ihr Motiv (Tänzer) transformieren und ihm einen dynamischen audioreaktiven Hintergrund aus verschiedenen komplexen Geometrien und psychedelischen Mustern geben. Sie können diesen Workflow mit einem oder mehreren Motiven verwenden. Mit diesem Workflow können Sie faszinierende audioreaktive visuelle Effekte erzeugen, die perfekt mit dem Rhythmus der Musik synchronisiert sind und ein immersives Erlebnis bieten. Der Workflow ermöglicht es Ihnen, ihn mit einem einzelnen oder mehreren Motiven zu verwenden, die alle mit audioreaktiven Elementen verbessert werden.
So verwenden Sie den Audioreactive Dancers Evolved Workflow:
- Laden Sie ein Motivvideo im Eingabebereich hoch
- Wählen Sie die gewünschte Breite und Höhe des endgültigen Videos sowie die Anzahl der zu überspringenden Frames des Eingabevideos mit "every_nth". Sie können auch die Gesamtanzahl der zu rendernden Frames mit "frame_load_cap" begrenzen.
- Füllen Sie den positiven und negativen Prompt aus. Stellen Sie die Batch-Frame-Zeiten so ein, dass sie den gewünschten Szenenübergängen entsprechen.
- Laden Sie Bilder für jede der Standard-IP-Adapter-Motivmaskenfarben hoch:
- Rot, Grün, Blau = Motiv(e)
- Schwarz = Hintergrund
- Weiß = Weiße audioreaktive Dilationsmaske
- Gelb, Magenta = Hintergrundrauschmaskenmuster
- Laden Sie einen guten LCM-Checkpoint (ich verwende ParadigmLCM von Machine Delusions) im Abschnitt "Models".
- Fügen Sie alle Loras mit dem Lora-Stacker unter dem Modell-Loader hinzu
- Drücken Sie Queue Prompt
Videoanleitung
Knoten- und Gruppierungsfarbe
- Für diesen Workflow habe ich Knoten basierend auf ihrer Funktion innerhalb jeder Gruppe farblich koordiniert.
- Gruppensektionstitel sind farblich koordiniert, um eine einfachere Differenzierung zu ermöglichen.
Eingabe
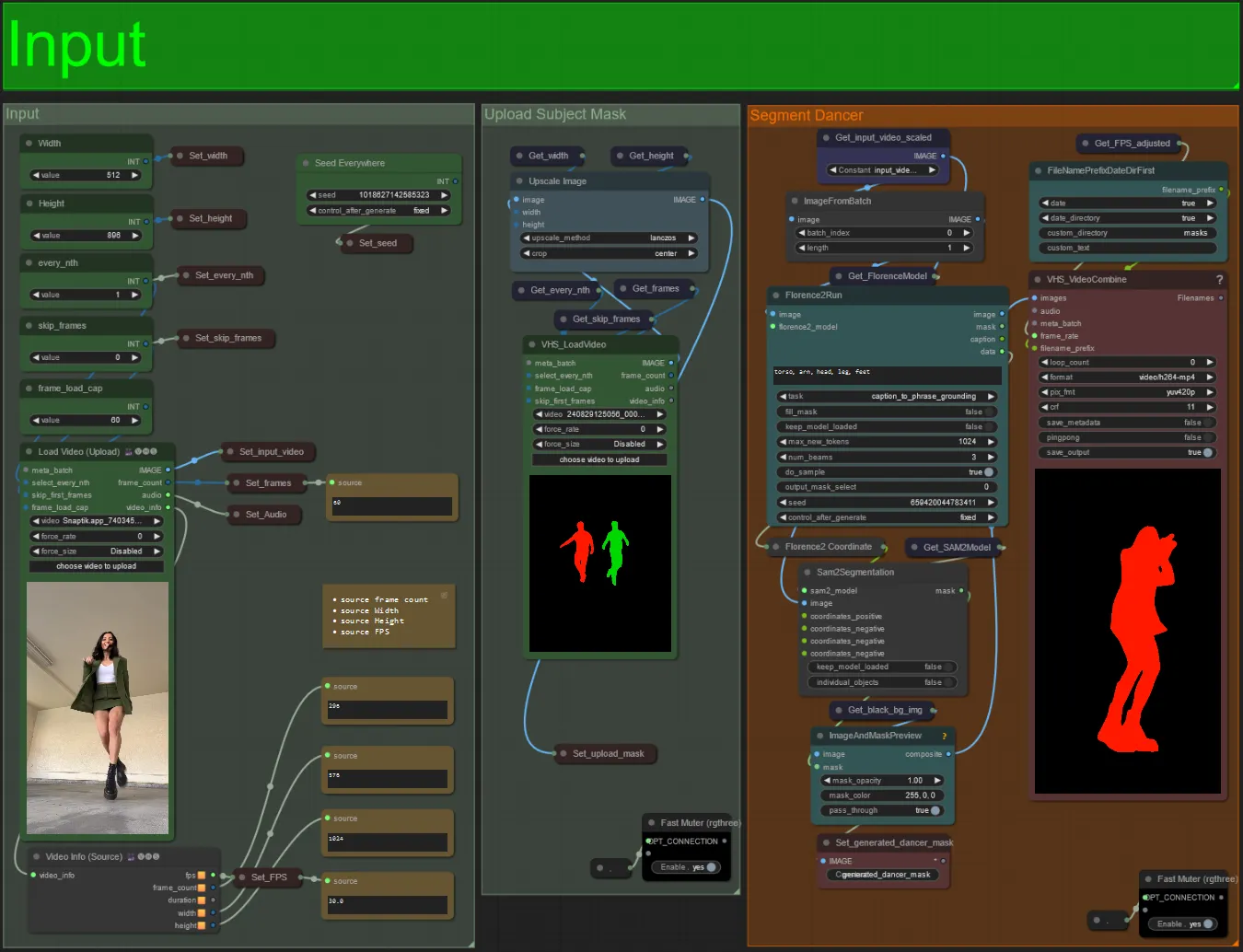
- Laden Sie Ihr gewünschtes Motivvideo in den Knoten Load Video (Upload) hoch.
- Sie können die Ausgabe-Breite und -Höhe mit den beiden Eingaben oben links anpassen.
- every_nth legt fest, ob jedes zweite Frame, jedes dritte Frame usw. verwendet werden soll (2 = jedes zweite Frame). Standardmäßig auf 1 belassen.
- skip_frames wird verwendet, um Frames am Anfang des Videos zu überspringen. (100 = die ersten 100 Frames des Eingabevideos überspringen). Standardmäßig auf 0 belassen.
- frame_load_cap wird verwendet, um anzugeben, wie viele Gesamtframes des Eingabevideos geladen werden sollen. Am besten niedrig halten, wenn Sie die Einstellungen testen (z. B. 30 - 60) und dann erhöhen oder auf 0 setzen (keine Frame-Obergrenze), wenn Sie das endgültige Video rendern.
- Die Zahlenfelder unten rechts zeigen Informationen über das hochgeladene Eingabevideo an: Gesamtframes, Breite, Höhe und FPS von oben nach unten.
- Wenn Sie bereits ein Maskenvideo des Motivs haben, können Sie den Abschnitt "Upload Subject Mask" un-stummschalten und das Maskenvideo hochladen. Optional können Sie den Abschnitt "Segment Dancer" stummschalten, um etwas Verarbeitungszeit zu sparen.
- Manchmal wird das segmentierte Motiv nicht perfekt sein, Sie können die Maskenqualität mit dem Vorschaubild im unteren rechten Bereich überprüfen. Wenn dies der Fall ist, können Sie mit dem Prompt im "Florence2Run"-Knoten herumspielen, um verschiedene Körperteile wie "Kopf", "Brust", "Beine" usw. anzusprechen und zu sehen, ob Sie ein besseres Ergebnis erzielen.
Prompt
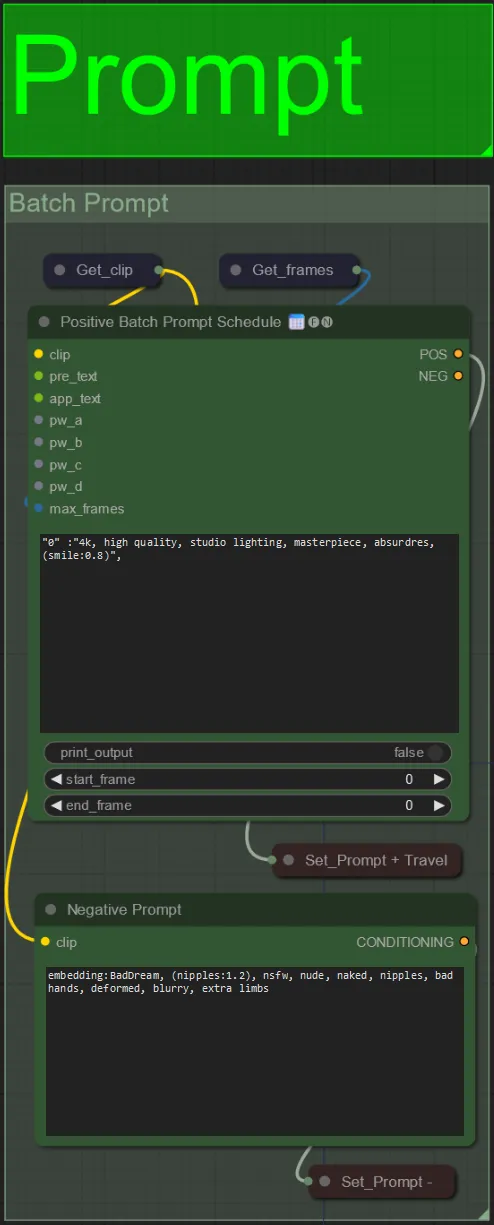
- Legen Sie den positiven Prompt mit Batch-Formatierung fest:
- z. B. "0": "4k, Meisterwerk, 1 Mädchen am Strand stehend, absurdres", "25": "HDR, Sonnenuntergangsszene, 1 Mädchen mit schwarzen Haaren und einer weißen Jacke, absurdres", …
- Der negative Prompt hat ein normales Format, Sie können Einbettungen hinzufügen, wenn gewünscht.
Audioverarbeitung
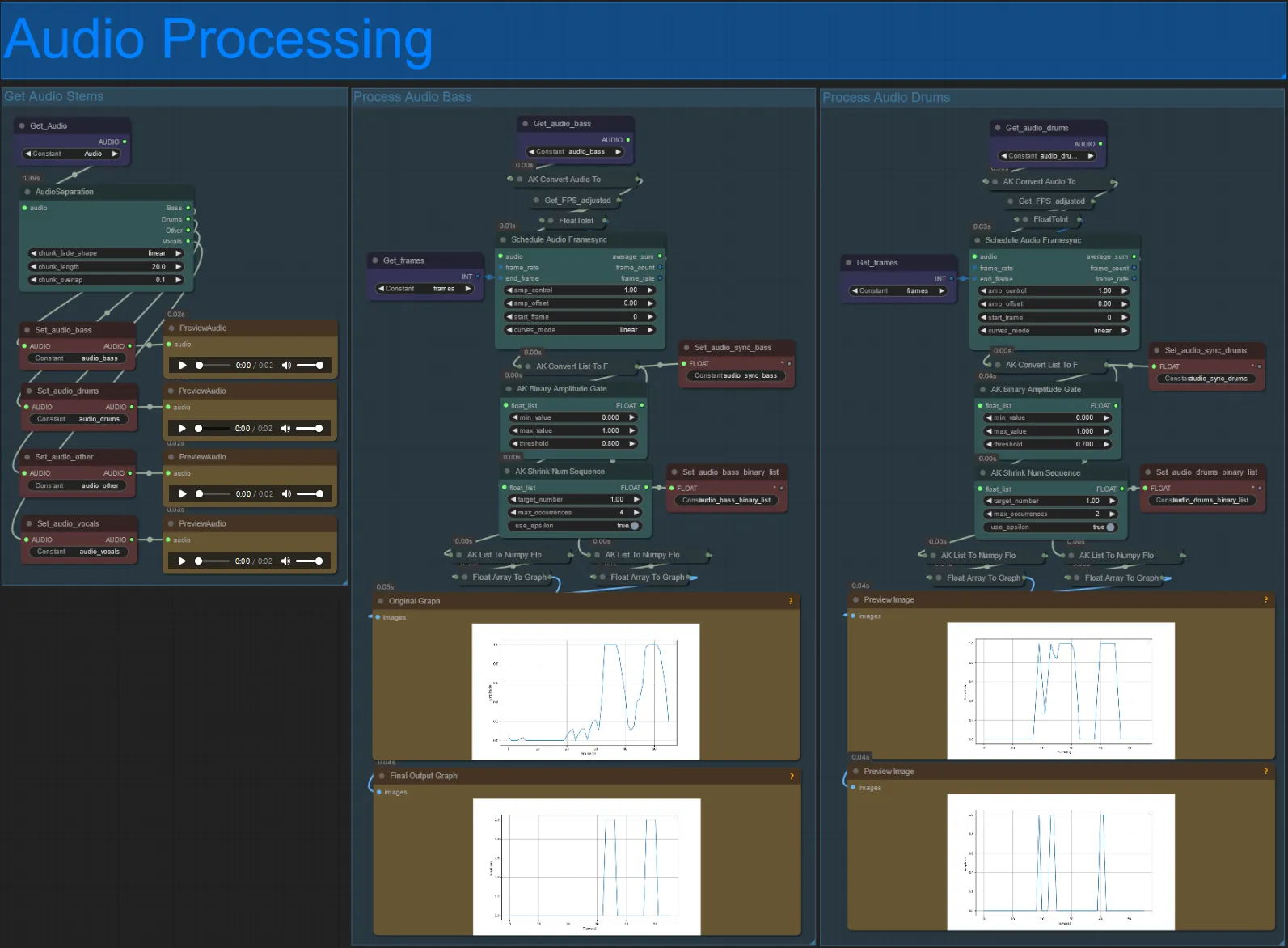
- Dieser Abschnitt nimmt Audio aus dem Eingabevideo auf, extrahiert die Stems (Bass, Drums, Vocals usw.) und konvertiert es dann in eine normalisierte Amplitude, die mit den Eingabevideoframes synchronisiert ist, um audioreaktive Visuals zu erstellen.
- amp_control = Gesamtreichweite, die die Amplitude erreichen kann.
- amp_offset = Der Mindestwert, den die Amplitude annehmen kann.
- Beispiel: amp_control = 0.8 und amp_offset = 0.2 bedeutet, dass das Signal zwischen 0.2 und 1.0 wandert.
- Manchmal hat der Drum-Stem die tatsächlichen Bassnoten des Songs, hören Sie sich jeden an, um zu sehen, welchen Sie für Ihre audioreaktiven Masken verwenden möchten.
- Verwenden Sie die Diagramme, um ein gutes Verständnis dafür zu bekommen, wie sich das Signal für diesen Stem über die Länge des Videos ändert.
Voronoi-Generatoren
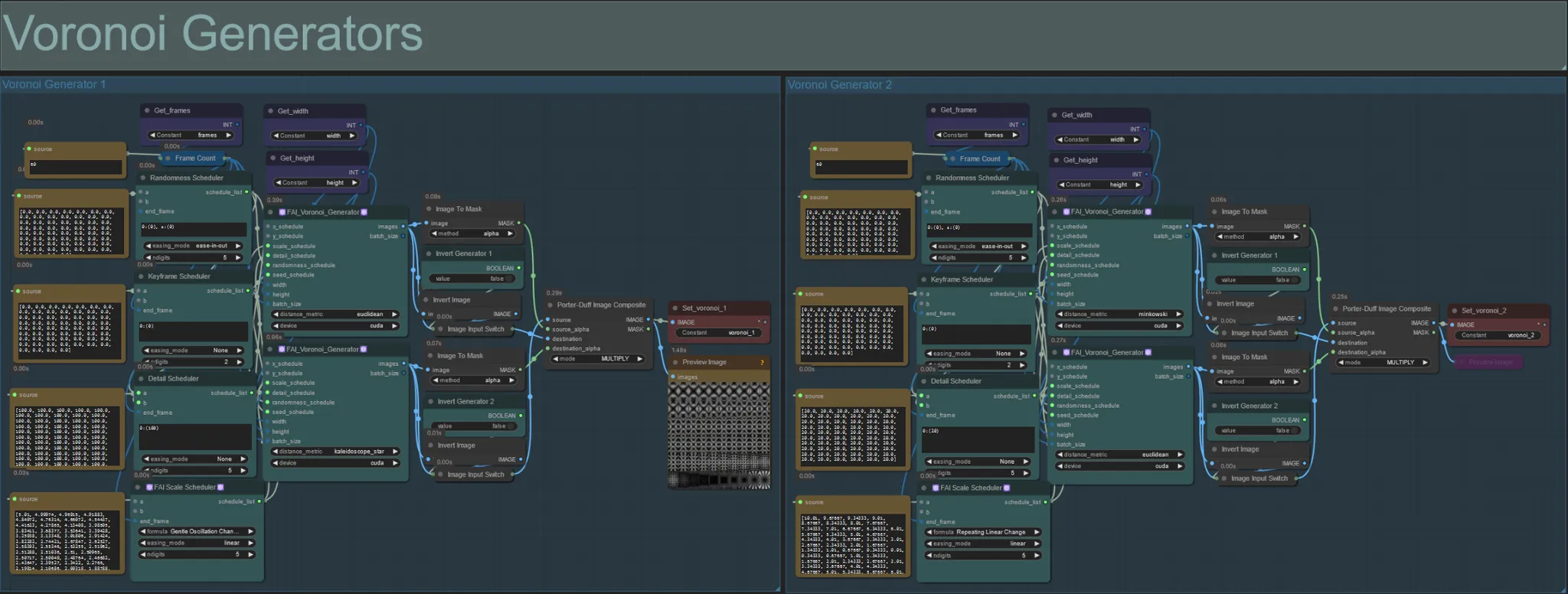
- Dieser Abschnitt erzeugt Voronoi-Rauschmuster mit zwei FAI_Voronoi_Generator-Benutzerdefinierten Knoten pro Gruppe, die mit einem Multiply zusammengesetzt werden.
- Sie können die Werte des Randomness Scheduler in den Klammern von 0 erhöhen, um symmetrische Muster im endgültigen Output zu durchbrechen.
- Erhöhen Sie den Wert des Detail Scheduler in den Klammern, um die Detailanzahl in den Ausgaberauschmustern zu erhöhen. Niedrigere Werte führen zu einer geringeren Rauschdifferenzierung.
- Ändern Sie die "Formula"-Parameter im FAI Scale Scheduler-Knoten, um einen großen Einfluss auf die endgültige Rauschmusterbewegung zu haben.
- Sie können auch die "distance_metric"-Funktion in den FAI_Voronoi_Generator-Knoten selbst ändern, um die generierten Muster und Formen des resultierenden Rauschens stark zu beeinflussen.
Audio-Masken
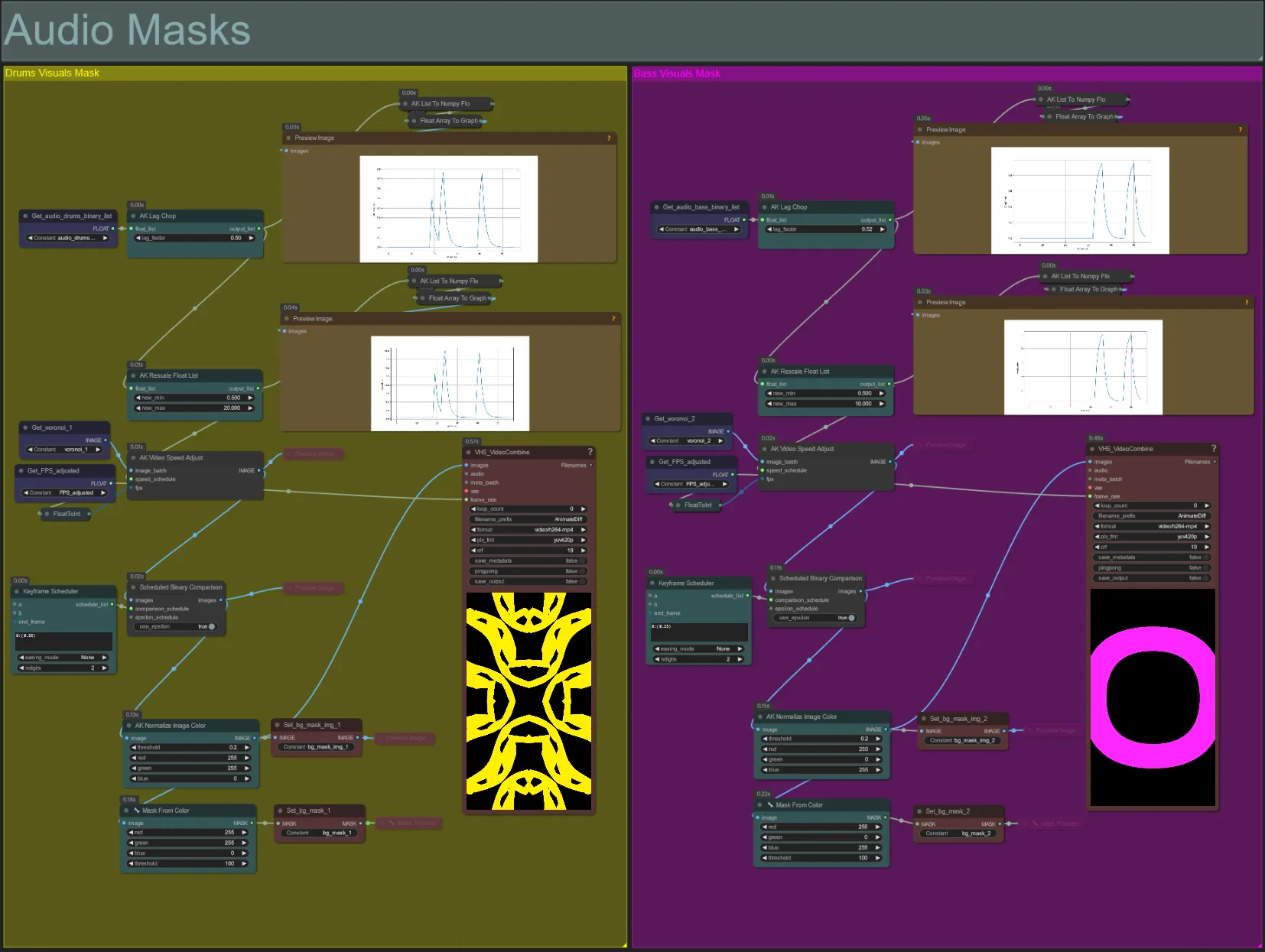
- Dieser Abschnitt wird verwendet, um die Voronoi-Rauschbild-Batches in farbige Masken umzuwandeln, die mit dem Motiv zusammengesetzt werden, sowie ihre Bewegungen mit dem Beat entweder der Bass- oder Drums-Audiostems zu synchronisieren. Diese Masken sind entscheidend für die Erstellung audioreaktiver Effekte.
- Erhöhen Sie den "lag_factor" im AK Lag Chop-Knoten, um zu erhöhen, wie "spiky" die endgültigen Amplitudendiagramme sein werden. Dies wird dazu führen, dass die Ausgabe-Rauschbewegung schneller und langsamer wird, während ein niedrigerer lag_factor zu einer allmählicheren Verlangsamung der Bewegung nach jedem Beat führt. Dies wird verwendet, um zu verhindern, dass die Rauschmaskenanimation zu "sprunghaft" und starr erscheint.
- Der AK Rescale Float List wird verwendet, um die normalisierten Amplitudenwerte von 0-1 auf new_min und new_max neu zuzuordnen. Ein Wert von 1.0 entspricht 30FPS Wiedergabegeschwindigkeit der Rauschanimation, während 0.5 15FPS entspricht, 2.0 60FPS usw. Passen Sie diesen Wert an, um zu ändern, wie langsam das audioreaktive Rauschmuster außerhalb des Beats (Amplitude 0.0) animiert und wie schnell es sich auf dem Beat (Amplitude 1.0) bewegt.
- Der Keyframe Scheduler hat einen großen Einfluss auf das Erscheinungsbild der Maske. Er erstellt eine Liste von Float-Werten, um die Schwelle der Pixelhelligkeitswerte zu bestimmen, die für die Rauscheingangsbilder verwendet werden, was dazu führt, dass ein Teil des Rauschens abgeschnitten und in die endgültige Maske umgewandelt wird. Senken Sie diesen Wert, um mehr vom Eingaberauschen zu behalten, und erhöhen Sie ihn, um weniger vom Rauschen zu behalten.
Dilate-Masken
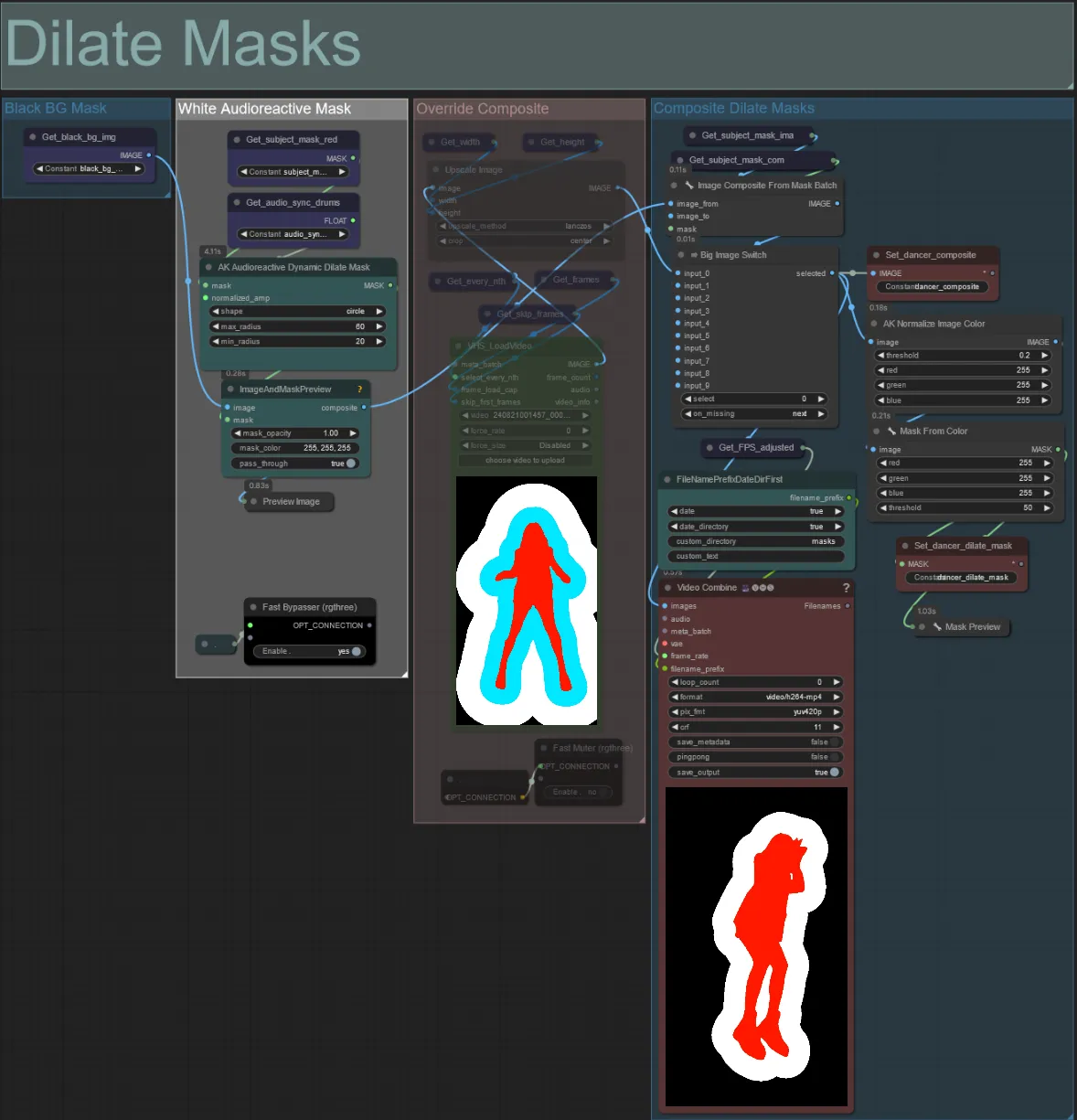
- Jede farbige Gruppe entspricht der Farbe der Dilationsmaske, die von ihr erzeugt wird.
- Sie können den Mindest- und Maximalradius der Dilationsmaske sowie die Form mit dem folgenden Knoten einstellen:
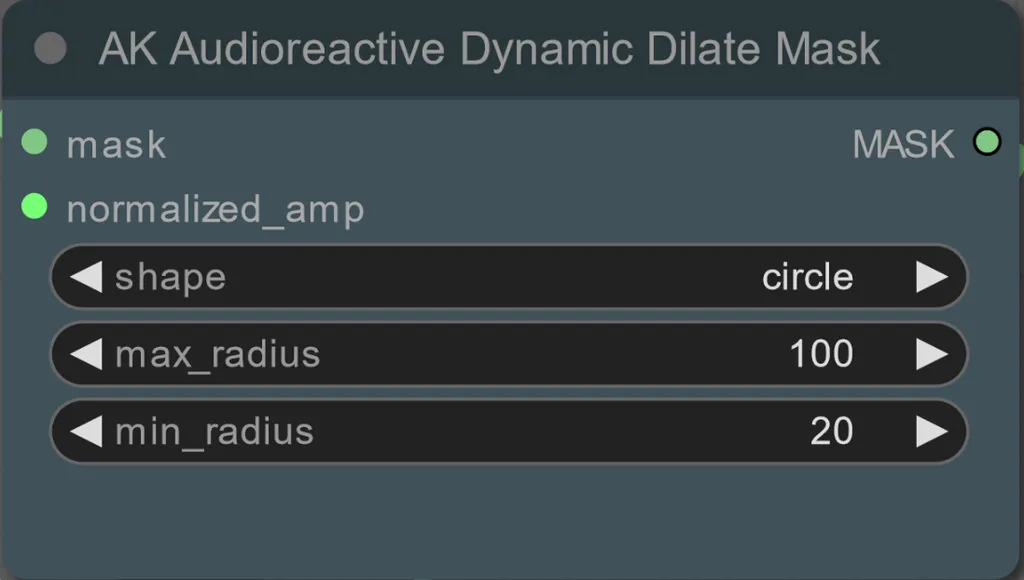
- Form: "Kreis" ist am genauesten, benötigt aber länger zur Erstellung. Stellen Sie dies ein, wenn Sie bereit sind, das endgültige Rendering durchzuführen. "Quadrat" ist schnell zu berechnen, aber weniger genau, am besten geeignet, um den Workflow zu testen und IP-Adapterbilder zu entscheiden.
- max_radius: Der Radius der Maske in Pixeln, wenn der Amplitudenwert maximal ist (1.0).
- min_radius: Der Radius der Maske in Pixeln, wenn der Amplitudenwert minimal ist (0.0).
- Wenn Sie bereits ein zusammengesetztes Maskenvideo erzeugt haben, können Sie die Gruppe "Override Composite Mask" un-stummschalten und es hochladen. Es wird empfohlen, die Dilationsmaskengruppen zu umgehen, wenn überschrieben wird, um Verarbeitungszeit zu sparen.
Latent Noise Mask
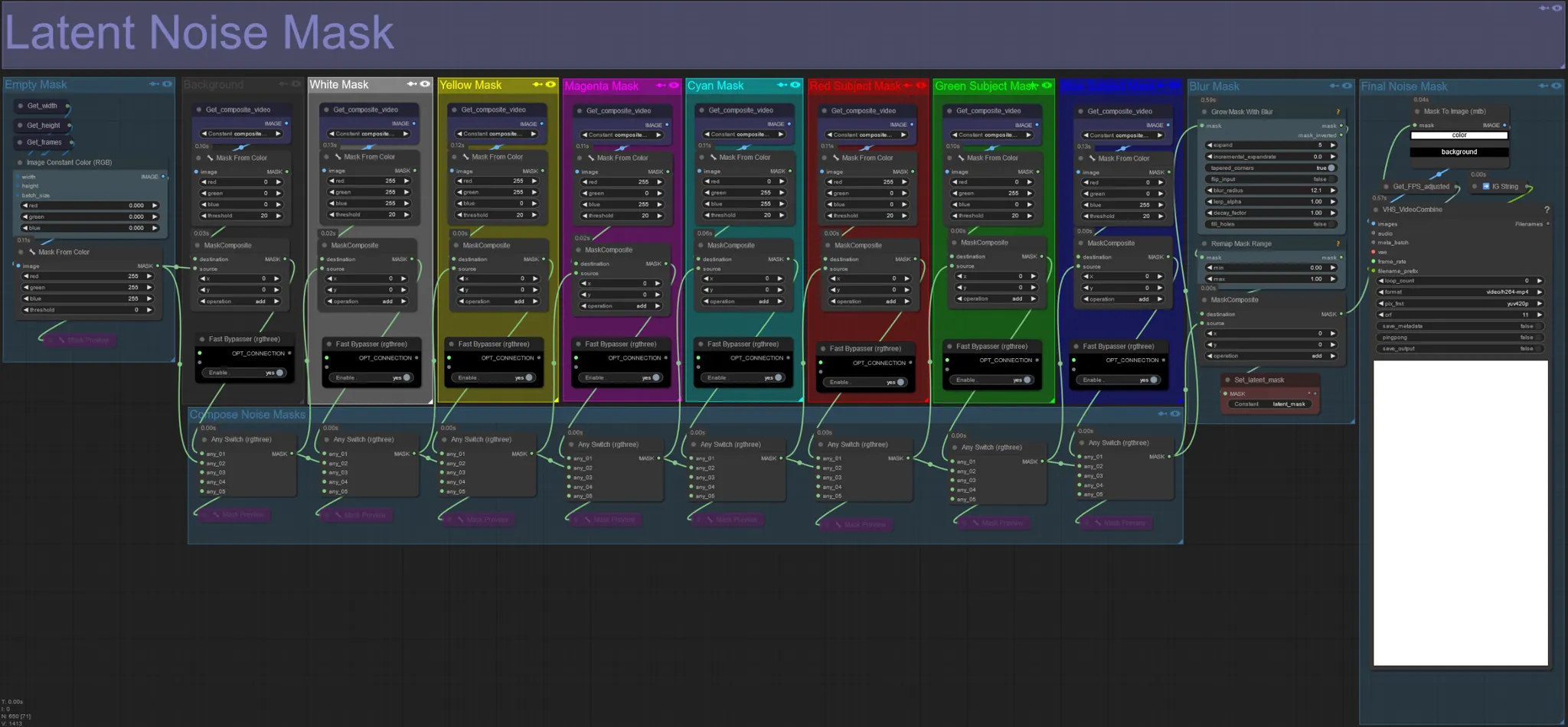
- Verwenden Sie latente Rauschmasken, um zu steuern, welche Masken tatsächlich vom ksampler diffundiert (übergangen) werden. Umgehen Sie die Gruppe, die der farbigen Maske entspricht, die Sie nicht diffundiert haben möchten (d. h. auf der Elemente aus dem Originalvideo erscheinen sollen).
- Wenn alle Maskengruppen aktiviert bleiben, ergibt dies eine weiße endgültige Rauschmaske (alles wird diffundiert).
- Beispiel: Umgehen Sie die Gruppe der roten Motivmaske, indem Sie auf den Fast Bypasser-Knoten klicken, um Ihren Tänzer oder das Motiv im endgültigen Ergebnis erscheinen zu lassen.
Originales Eingabevideo:

Umgehen der roten und gelben Maskengruppen:

Composite Mask
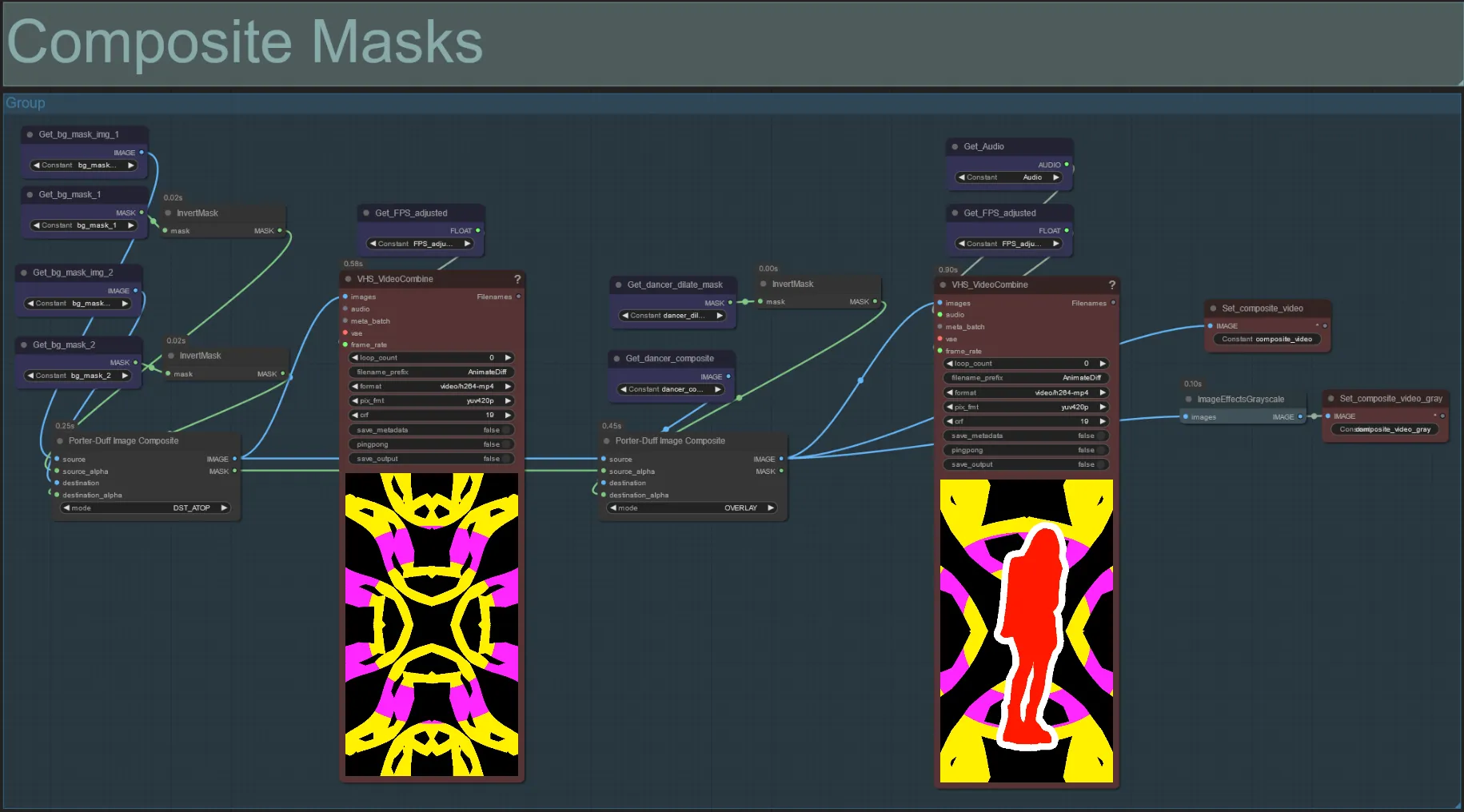
- Dieser Abschnitt erstellt das endgültige Komposit der Voronoi-Rauschmasken mit der Motivmaske (und der audioreaktiven Dilationsmaske, wenn aktiviert).
Modelle
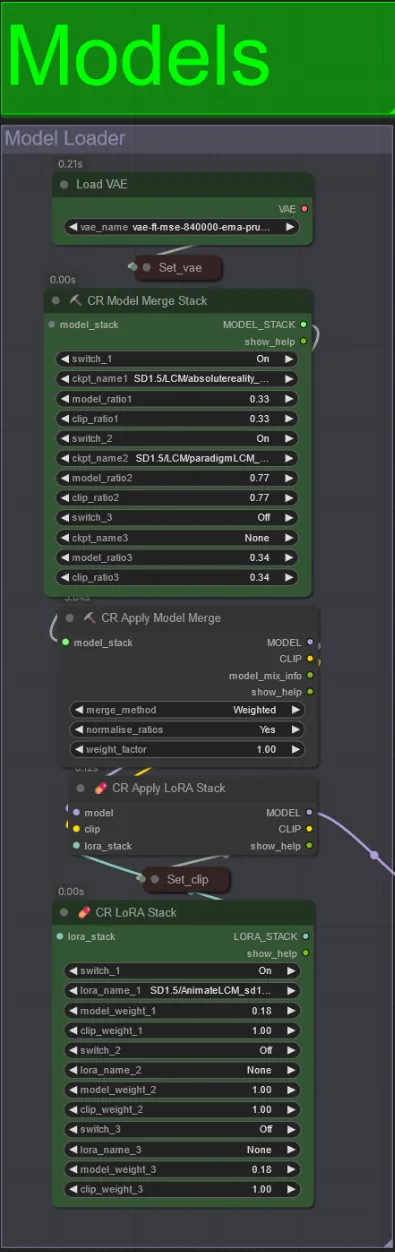
- Verwenden Sie ein gutes LCM-Modell für den Checkpoint. Ich empfehle ParadigmLCM von Machine Delusions.
- Sie können mehrere Modelle zusammenführen, um verschiedene interessante Effekte zu erzielen. Stellen Sie sicher, dass die Gewichte für die aktivierten Modelle 1.0 ergeben.
- Sie können optional das AnimateLCM_sd15_t2v_lora.safetensors mit einem niedrigen Gewicht von 0.18 angeben, um das endgültige Ergebnis weiter zu verbessern.
- Fügen Sie alle zusätzlichen Loras mit dem Lora-Stacker unter dem Modell-Loader hinzu.
AnimateDiff

- Sie können ein anderes Motion Lora anstelle des von mir verwendeten (LiquidAF-0-1.safetensors) festlegen
- Erhöhen/Verkleinern Sie die Scale- und Effect-Floats, um die Menge an Bewegung im Output zu erhöhen/verringern.
IP-Adapter
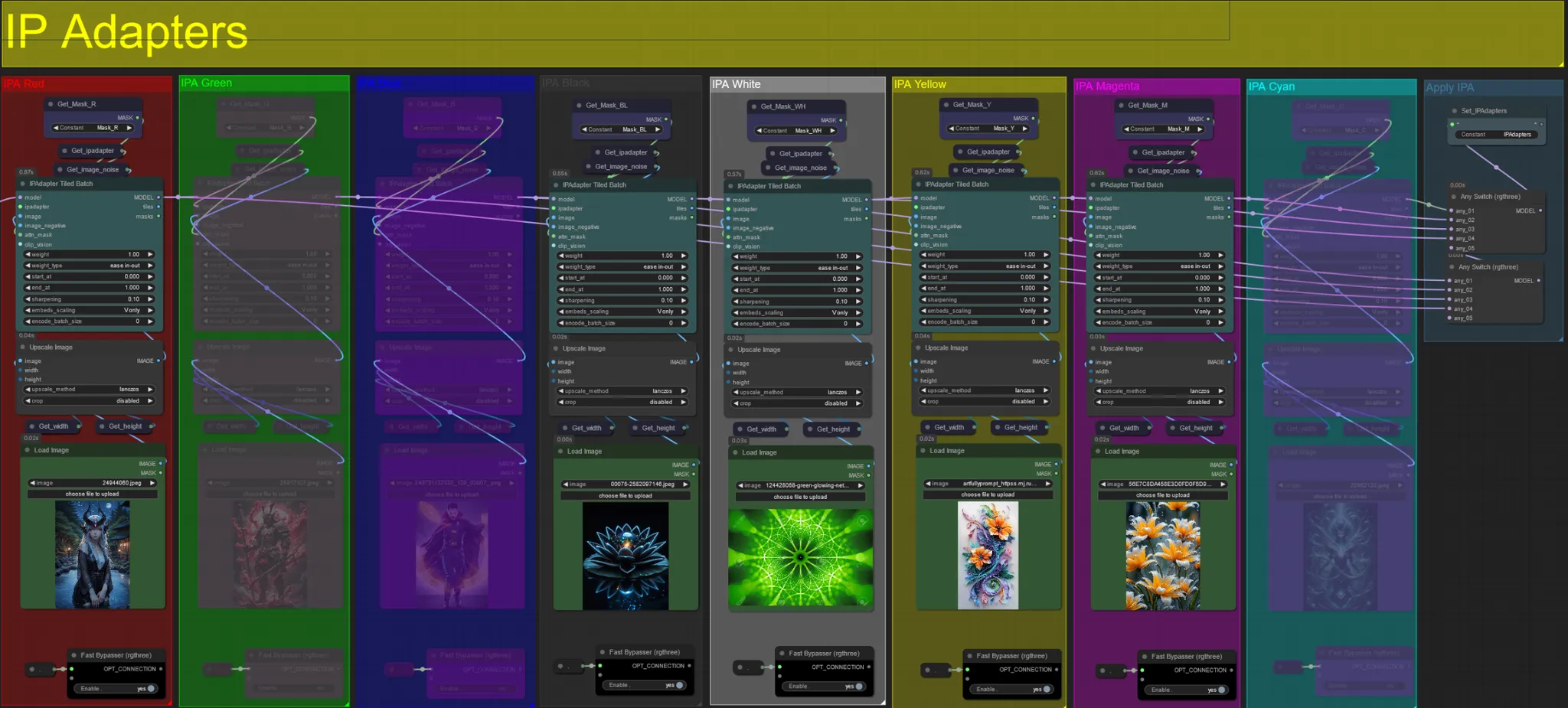
- Hier können Sie die Referenzbilder angeben, die verwendet werden, um die Hintergründe für jede der Dilationsmasken sowie Ihr(e) Videomotiv(e) zu rendern.
- Die Farbe jeder Gruppe repräsentiert die Maske, auf die sie abzielt:
Rot, Grün, Blau:
- Motivmasken-Referenzbilder.
Schwarz:
- Hintergrundmaskenbild, laden Sie ein Referenzbild für den Hintergrund hoch.
Weiß:
- Dilationsmasken-Referenzbilder, laden Sie ein Referenzbild für jede verwendete Farbdilationsmaske hoch.
Gelb, Magenta
- Voronoi-Rauschmasken-Referenzbilder.
ControlNet
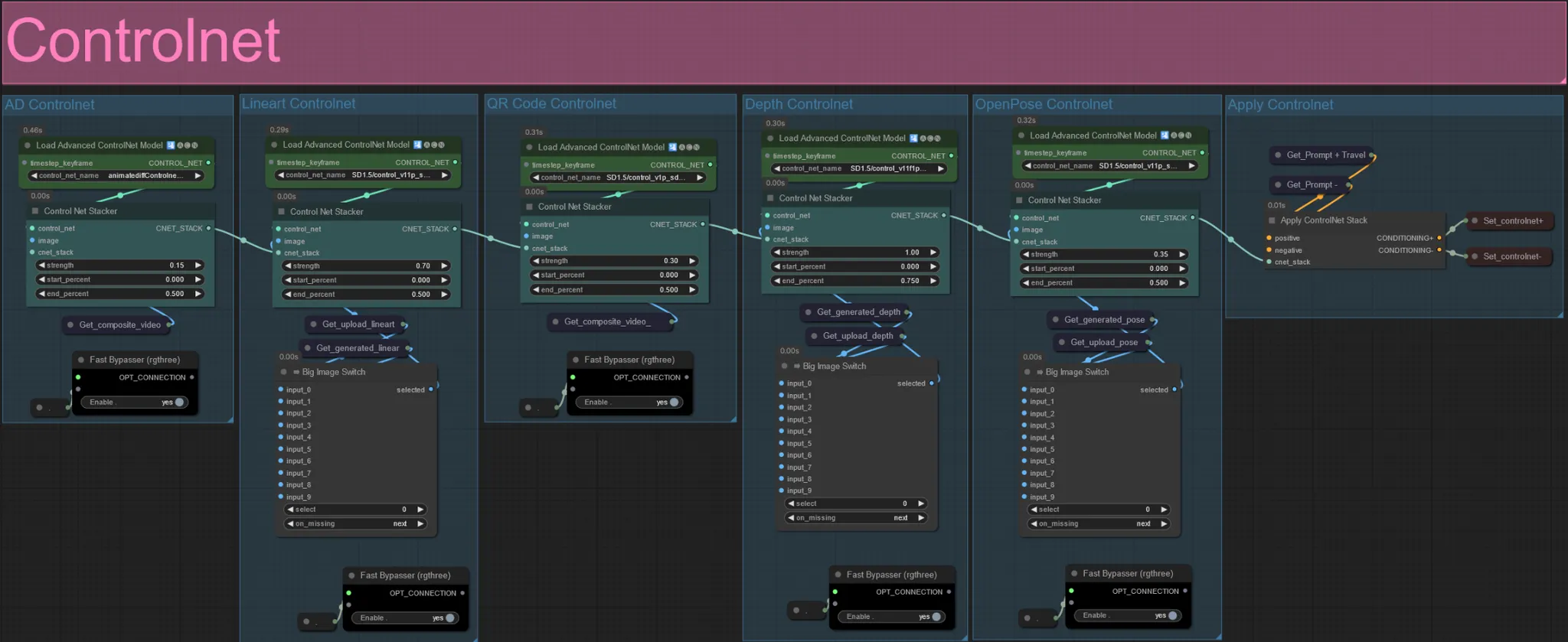
- Dieser Workflow verwendet 5 verschiedene Controlnets, darunter AD, Lineart, QR Code, Depth und OpenPose.
- Alle Eingaben zu den Controlnets werden automatisch generiert
- Sie können das Eingabevideo für die Lineart-, Depth- und Openpose-Controlnets überschreiben, wenn gewünscht, indem Sie die Gruppen "Override " un-stummschalten, wie unten zu sehen:
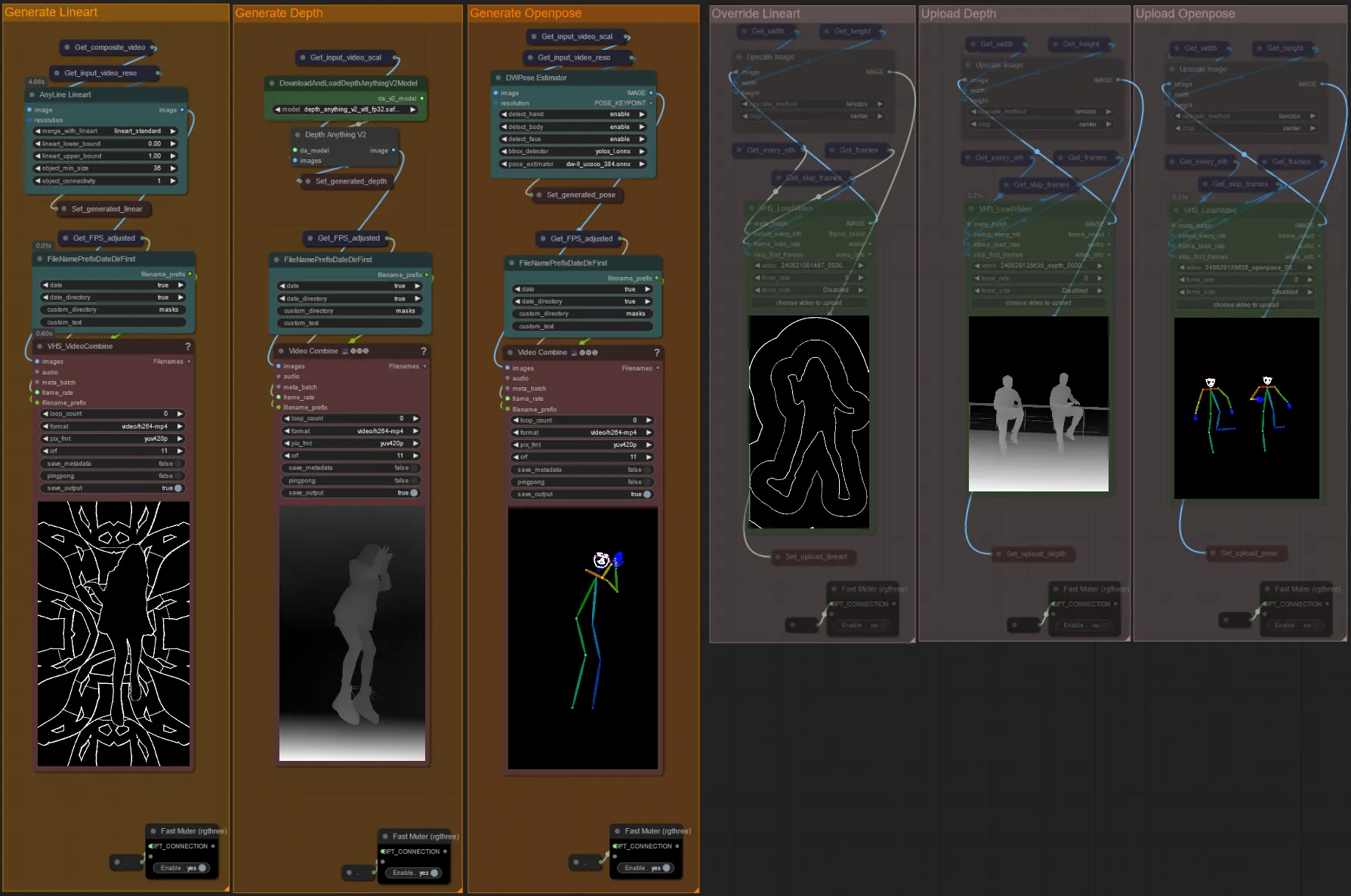
- Es wird empfohlen, auch die "Generate"-Gruppen zu stummschalten, wenn überschrieben wird, um Verarbeitungszeit zu sparen.
Tipp:
- Umgehen Sie den Ksampler und beginnen Sie mit einem Render mit Ihrem vollständigen Eingabevideo. Sobald alle Vorverarbeitungsvideos generiert sind, speichern Sie sie und laden Sie sie in die jeweiligen Überschreibungen hoch. Von nun an müssen Sie beim Testen des Workflows nicht mehr auf die individuelle Generierung jedes Vorverarbeitungsvideos warten.
Sampler
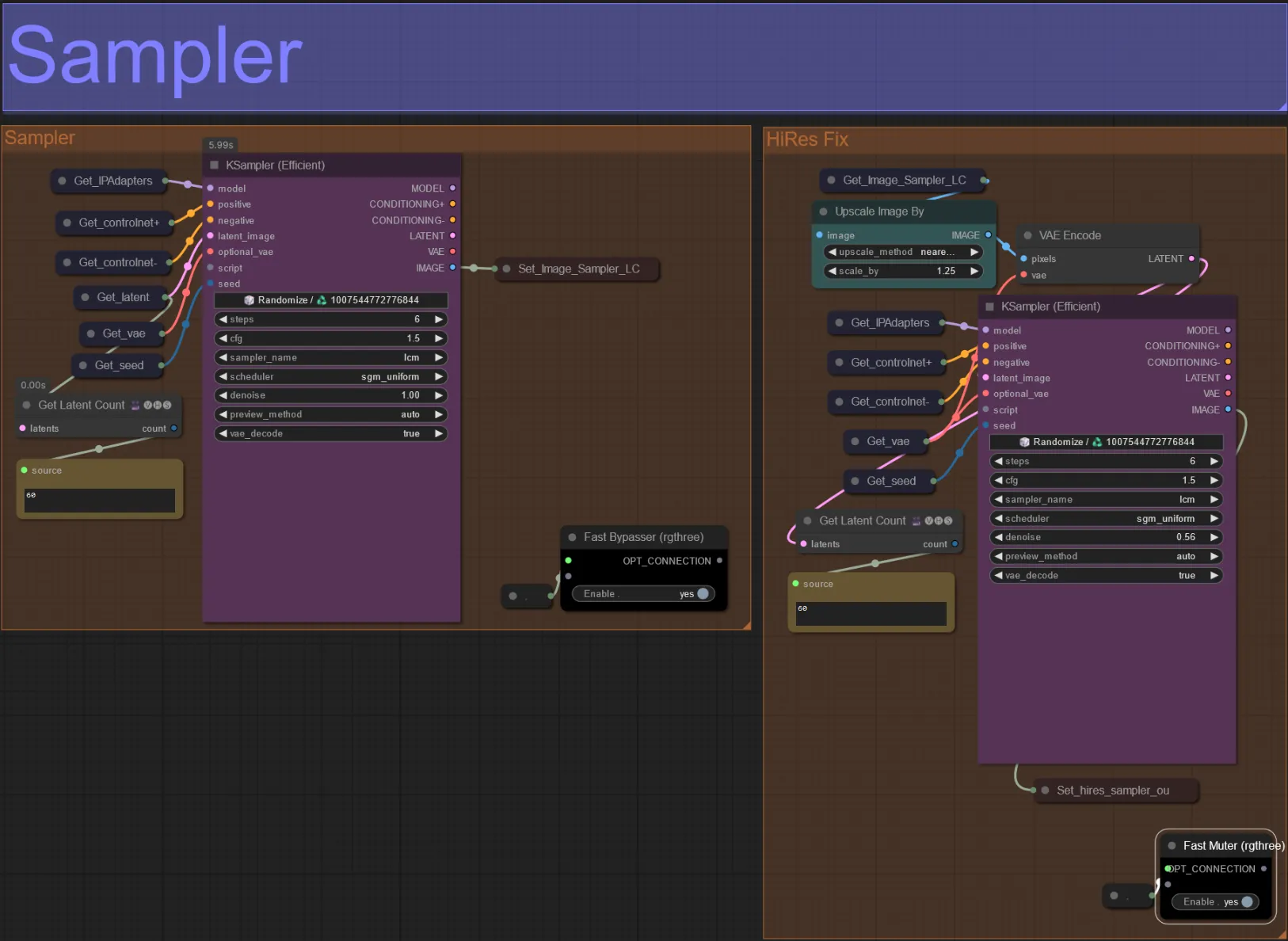
- Standardmäßig wird die HiRes Fix Sampler-Gruppe stummgeschaltet, um Verarbeitungszeit zu sparen, wenn getestet wird
- Ich empfehle, die Sampler-Gruppe ebenfalls zu umgehen, wenn Sie mit den Einstellungen der Dilationsmaske experimentieren, um Zeit zu sparen.
- Bei endgültigen Renderings können Sie die HiRes Fix-Gruppe un-stummschalten, die das endgültige Ergebnis hochskaliert und Details hinzufügt.
Ausgabe
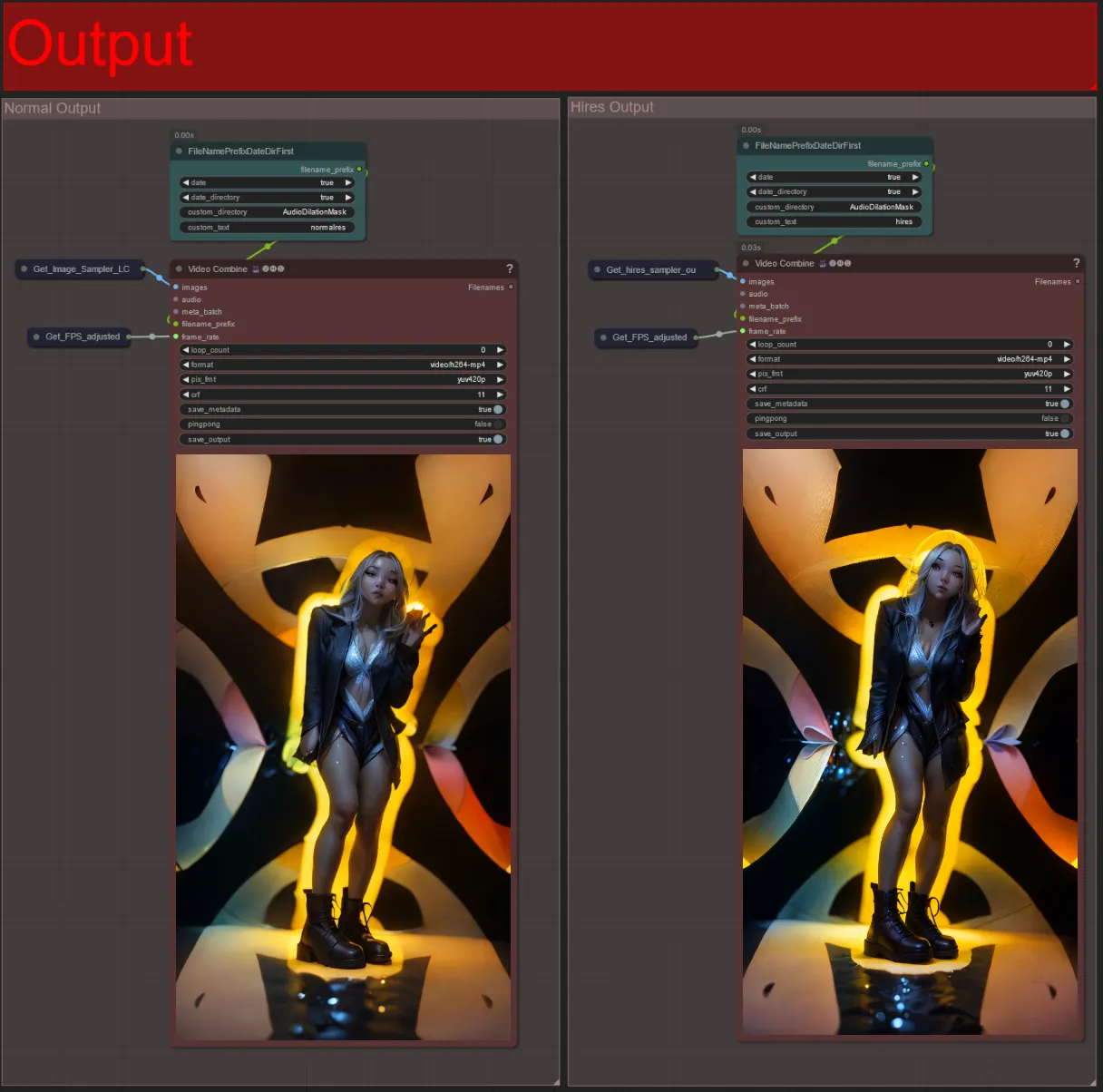
- Es gibt zwei Ausgabegruppen: links für die Standard-Sampler-Ausgabe und rechts für die HiRes Fix Sampler-Ausgabe.
- Sie können ändern, wo Dateien gespeichert werden, indem Sie den "custom_directory"-String in den "FileNamePrefixDateDirFirst"-Knoten ändern. Standardmäßig speichert dieser Knoten Ausgabedateien in einem mit einem Zeitstempel versehenen Verzeichnis im ComfyUI "output"-Verzeichnis
- z. B.
…/ComfyUI/output/240812/<custom_directory>/<my_video>.mp4
- z. B.
Ein audioreaktives Video kann Ihrem Motiv eine immersive, pulsierende Energie verleihen, wobei jedes Frame in Echtzeit auf den Beat reagiert. Tauchen Sie also in die Welt der audioreaktiven Kunst ein und genießenjson die rhythmusgesteuerten Transformationen!
Über den Autor
Akatz AI:
- Website:
Kontakte:
- Email: akatzfey@sendysoftware.com