Bailarines Audioreactivos Evolucionados
El Flujo de Trabajo de Bailarines Audioreactivos Evolucionados transforma sujetos de video en animaciones cautivadoras sincronizadas con ritmos musicales, sobre fondos dinámicos, geométricos y psicodélicos. Diseñado para la flexibilidad, permite a los usuarios controlar cuadros de video, enmascaramiento, respuesta al audio y detalles de patrones. Con características como máscaras de dilatación, ControlNet y animación de ruido sincronizada con el ritmo, este flujo de trabajo de ComfyUI empodera a los creativos para mezclar arte, sonido y movimiento, creando experiencias visuales inmersivas y rítmicas con visuales audioreactivos.ComfyUI Audioreactive Dancers Evolved Flujo de trabajo

- Flujos de trabajo completamente operativos
- Sin nodos ni modelos faltantes
- No se requiere configuración manual
- Presenta visuales impresionantes
ComfyUI Audioreactive Dancers Evolved Ejemplos
ComfyUI Audioreactive Dancers Evolved Descripción
Crea impresionantes animaciones de video transformando a tu sujeto (bailarín) y dales un fondo dinámico audioreactivo compuesto por varias geometrías intrincadas y patrones psicodélicos. Puedes utilizar este flujo de trabajo con uno o varios sujetos. Con este flujo de trabajo, puedes producir efectos visuales audioreactivos hipnotizantes que se sincronizan perfectamente con el ritmo de la música, ofreciendo una experiencia inmersiva. El flujo de trabajo te permite usarlo con un sujeto único o múltiples sujetos, todos mejorados con elementos audioreactivos.
Cómo usar el Flujo de Trabajo de Bailarines Audioreactivos Evolucionados:
- Sube un video de sujeto en la sección de Entrada
- Selecciona el ancho y alto deseados del video final, junto con cuántos cuadros del video de entrada deben omitirse con "every_nth". También puedes limitar el número total de cuadros a renderizar con "frame_load_cap".
- Completa el aviso positivo y negativo. Establece los tiempos de cuadro por lotes para coincidir con cuándo deseas que ocurran las transiciones de escena.
- Sube imágenes para cada uno de los colores de máscara de sujeto predeterminados del Adaptador IP:
- Rojo, Verde, Azul = sujeto(s)
- Negro = Fondo
- Blanco = Máscara de dilatación audioreactiva blanca
- Amarillo, Magenta = Patrones de máscara de ruido de fondo
- Carga un buen punto de control LCM (uso ParadigmLCM de Machine Delusions) en la sección "Models".
- Agrega cualquier lora usando el apilador de Lora debajo del cargador de modelos
- Presiona Cola de Aviso
Guía de Video
Color de Nodo y Grupo
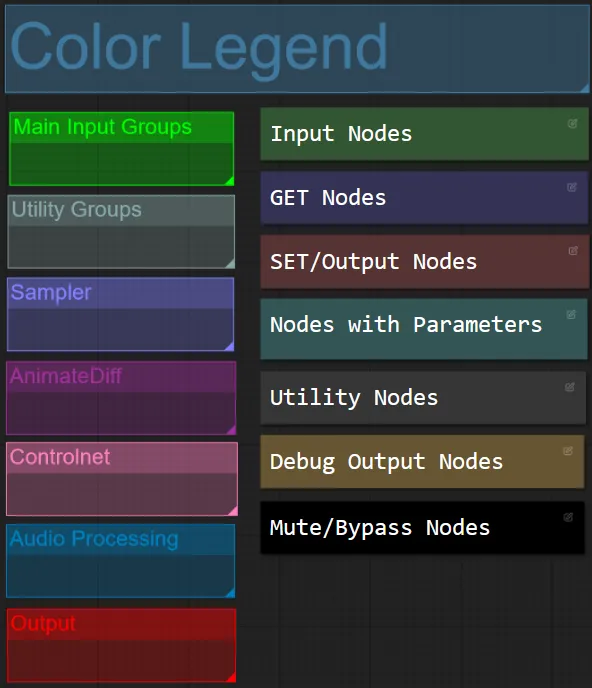
- Para este flujo de trabajo he coordinado el color de los nodos según su funcionalidad dentro de cada grupo.
- Los títulos de las secciones de grupo están coordinados por color para facilitar la diferenciación.
Entrada
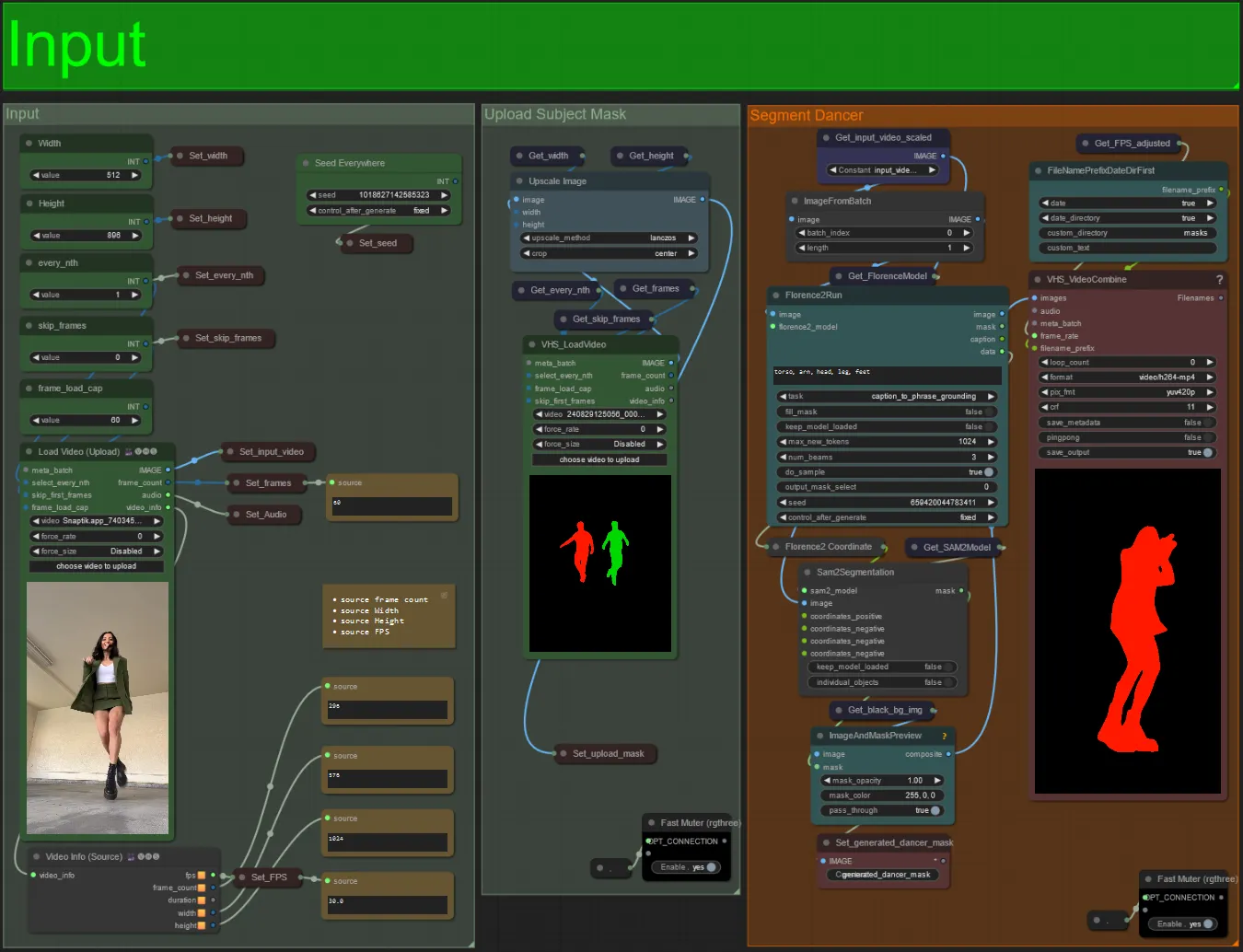
- Sube tu video de sujeto deseado al nodo de Cargar Video (Subir).
- Puedes ajustar el ancho y alto de salida usando las dos entradas superiores izquierdas.
- every_nth establece si se usa cada otro cuadro, cada tercer cuadro, etc. (2 = cada otro cuadro). Se deja en 1 por defecto.
- skip_frames se usa para omitir cuadros al comienzo del video. (100 = omitir los primeros 100 cuadros del video de entrada). Se deja en 0 por defecto.
- frame_load_cap se usa para especificar cuántos cuadros totales del video de entrada deben cargarse. Lo mejor es mantenerlo bajo al probar configuraciones (30 - 60 por ejemplo) y luego aumentar o establecer en 0 (sin límite de cuadros) al renderizar el video final.
- Los campos de número en la parte inferior derecha muestran información sobre el video de entrada subido: cuadros totales, ancho, alto y FPS de arriba a abajo.
- Si ya tienes un video de máscara de sujeto generado, puedes desactivar el silencio de la sección "Subir Máscara de Sujeto" y subir el video de máscara. Opcionalmente, puedes silenciar la sección "Segmentar Bailarín" para ahorrar algo de tiempo de procesamiento.
- A veces, el sujeto segmentado no será perfecto, puedes verificar la calidad de la máscara utilizando el cuadro de vista previa en la parte inferior derecha que se ve arriba. Si ese es el caso, puedes experimentar con el aviso en el nodo "Florence2Run" para apuntar a diferentes partes del cuerpo como "cabeza", "pecho", "piernas", etc. y ver si obtienes un mejor resultado.
Aviso
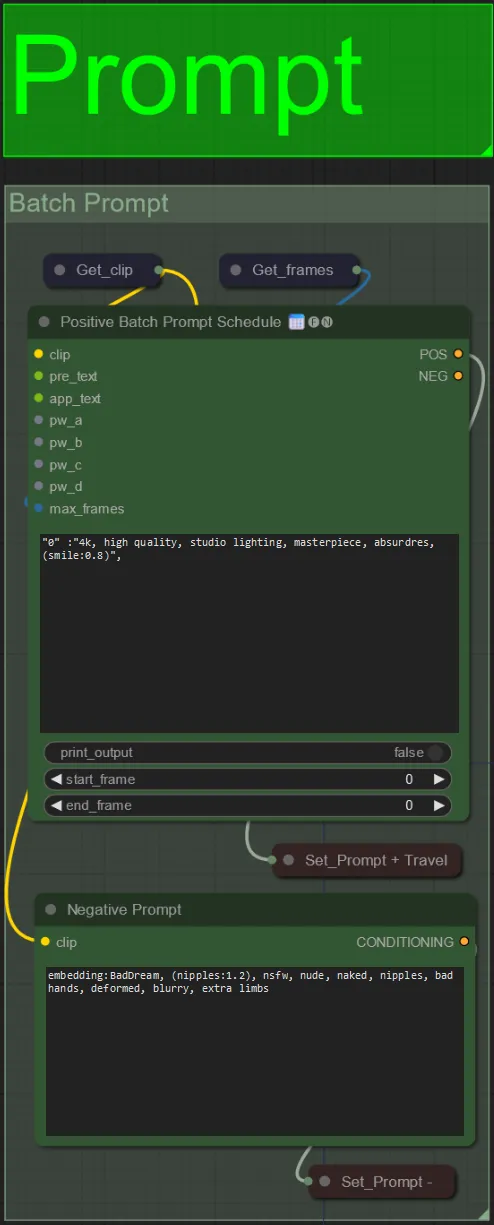
- Establece el aviso positivo usando el formato por lotes:
- por ejemplo, "0": "4k, obra maestra, 1 chica de pie en la playa, absurdo", "25": "HDR, escena de atardecer, 1 chica con cabello negro y una chaqueta blanca, absurdo", …
- El aviso negativo es de formato normal, puedes agregar incrustaciones si lo deseas.
Procesamiento de Audio
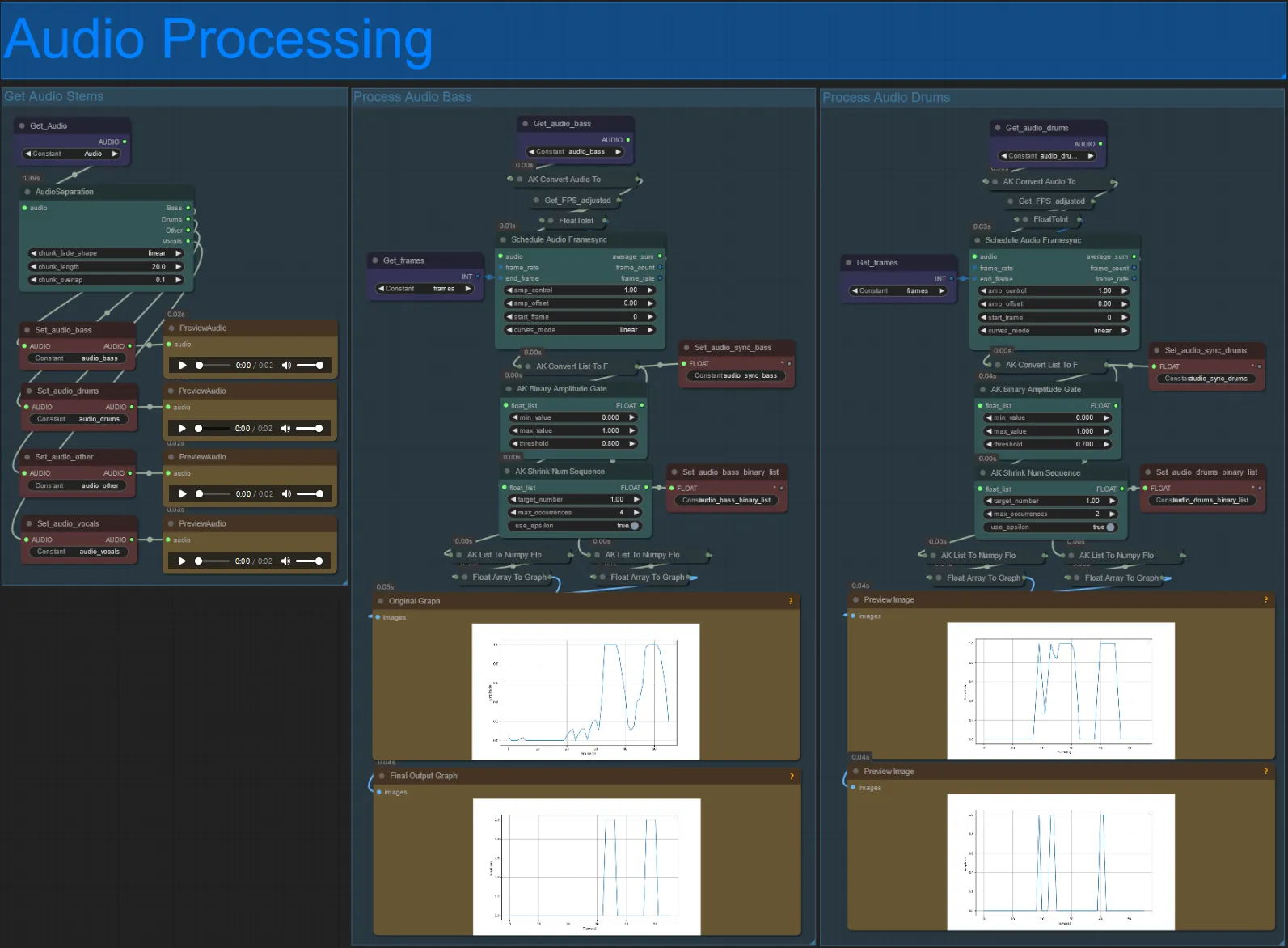
- Esta sección toma el audio del video de entrada, extrae los elementos (bajo, batería, voces, etc.) y luego lo convierte en una amplitud normalizada sincronizada con los cuadros del video de entrada, para crear visuales audioreactivos.
- amp_control = rango total que la amplitud puede recorrer.
- amp_offset = el valor mínimo que la amplitud puede tomar.
- Ejemplo: amp_control = 0.8 y amp_offset = 0.2 significa que la señal viajará entre 0.2 y 1.0.
- A veces el elemento de Batería tendrá las notas reales del Bajo de la canción, previsualiza cada uno para ver cuál usar para tus máscaras audioreactivas.
- Usa los gráficos para obtener una buena comprensión de cómo cambia la señal para ese elemento a lo largo del video
Generadores de Voronoi
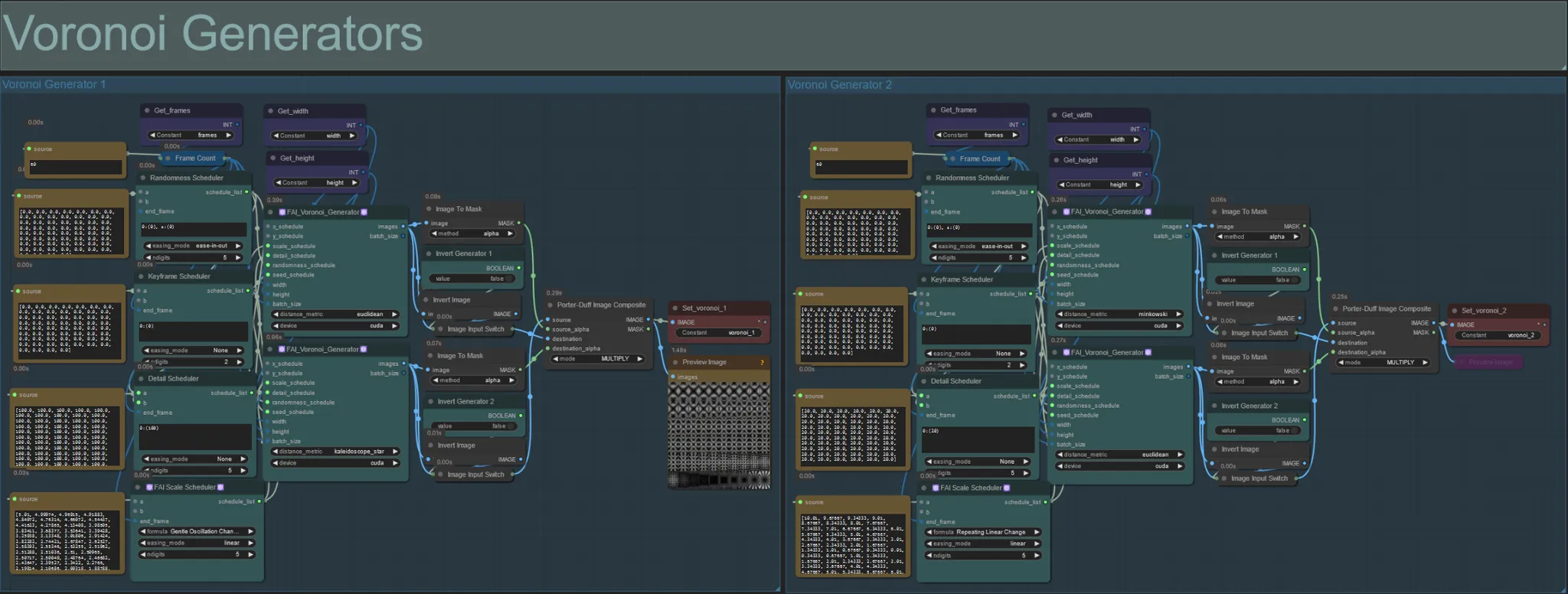
- Esta sección genera patrones de ruido Voronoi utilizando dos nodos personalizados FAI_Voronoi_Generator por grupo que se componen juntos usando un Multiplicar.
- Puedes aumentar los valores del Programador de Aleatoriedad en el paréntesis de 0 para romper patrones simétricos en el resultado final.
- Aumenta el valor del Programador de Detalle en el paréntesis para aumentar el conteo de detalles en los patrones de ruido de salida. Valores más bajos resultan en menor diferenciación de ruido.
- Cambia los parámetros "formula" en el nodo Programador de Escala FAI para tener un gran impacto en el movimiento final del patrón de ruido.
- También puedes cambiar la función "distance_metric" en los nodos FAI_Voronoi_Generator para afectar en gran medida los patrones y formas generados del ruido resultante.
Máscaras de Audio
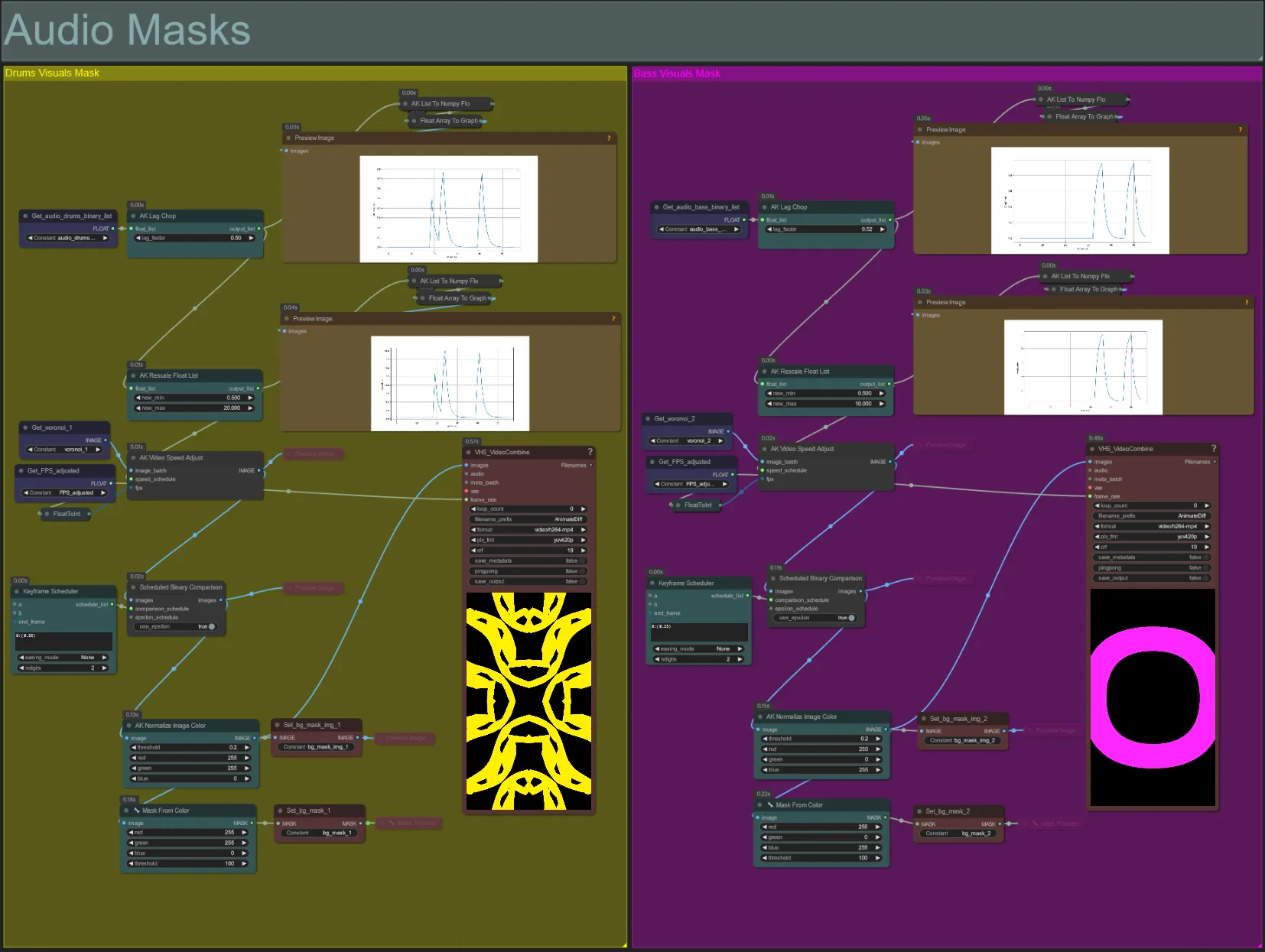
- Esta sección se utiliza para convertir los lotes de imágenes de ruido voronoi en máscaras coloreadas para ser compuestas con el sujeto, así como para sincronizar sus movimientos con el ritmo de los elementos de audio de bajo o batería. Estas máscaras son esenciales para crear efectos audioreactivos.
- Aumenta el "lag_factor" en el nodo AK Lag Chop para aumentar cuán "puntiagudos" serán los gráficos de amplitud finales. Esto hará que el movimiento del ruido de salida se acelere y desacelere más repentinamente, mientras que un lag_factor más bajo resultará en una desaceleración más gradual del movimiento después de cada ritmo. Esto se usa para evitar que la animación de la máscara de ruido parezca demasiado "brusca" y rígida.
- El AK Rescale Float List se utiliza para volver a mapear los valores de amplitud normalizada de 0-1 a new_min y new_max. Un valor de 1.0 representa una velocidad de reproducción de 30FPS de la animación de ruido, mientras que 0.5 representa 15FPS, 2.0 representa 60FPS, etc. Ajusta este valor para cambiar cuán lento se anima el patrón de ruido audioreactivo fuera del ritmo (amplitud 0.0), y cuán rápido se mueve en el ritmo (amplitud 1.0).
- El Programador de Fotogramas Clave tiene un gran efecto en la apariencia de la máscara. Crea una lista de valores flotantes para especificar el umbral de valores de brillo de píxeles a usar para las imágenes de entrada de ruido que resultarán en parte del ruido siendo recortado y convertido en la máscara final. Baja este valor para retener más del ruido de entrada, y aumenta para retener menos del ruido.
Dilatar Máscaras
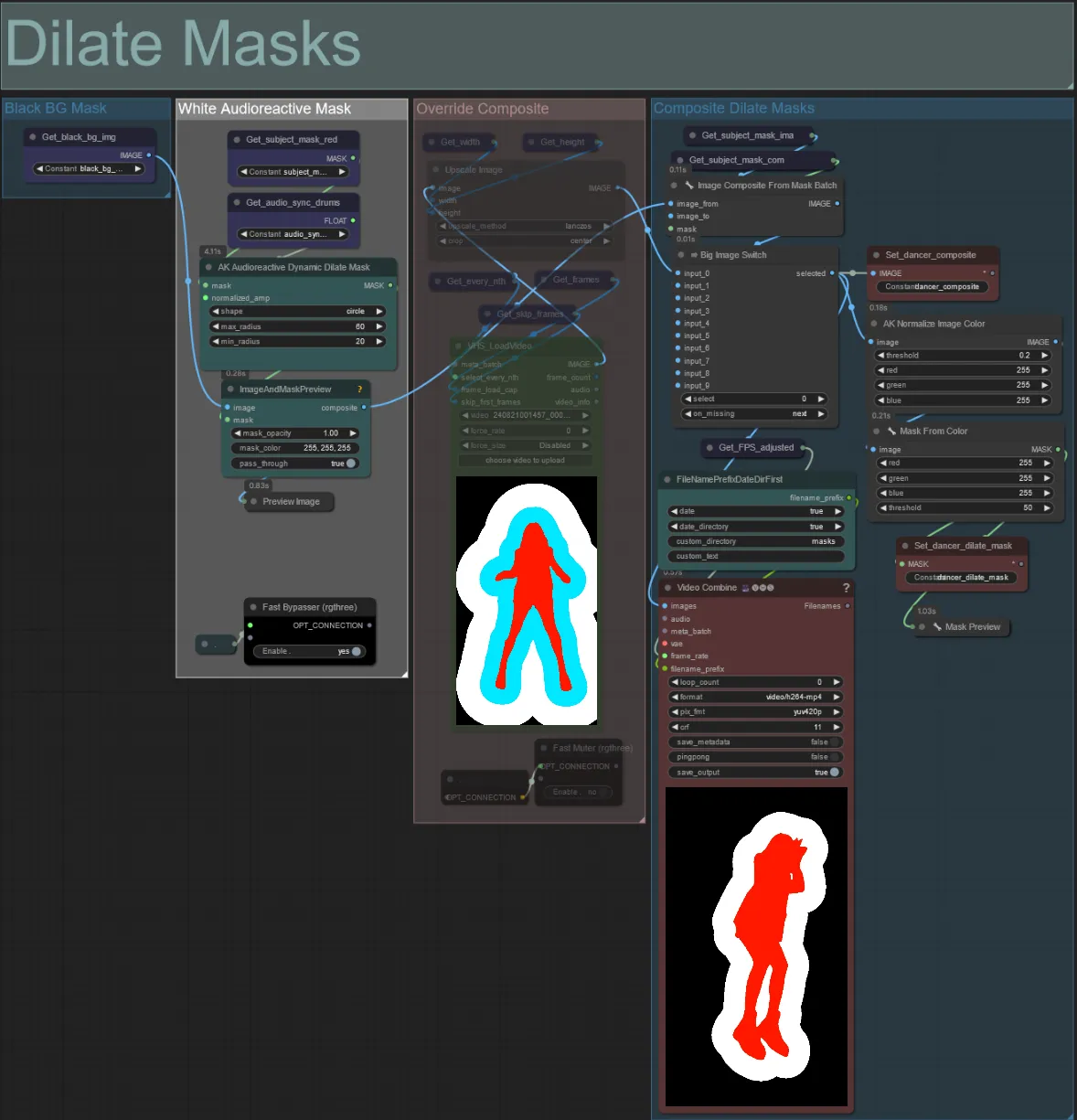
- Cada grupo coloreado corresponde al color de la máscara de dilatación que será generada por él.
- Puedes establecer el radio mínimo y máximo de la máscara de dilatación, así como la forma usando el siguiente nodo:
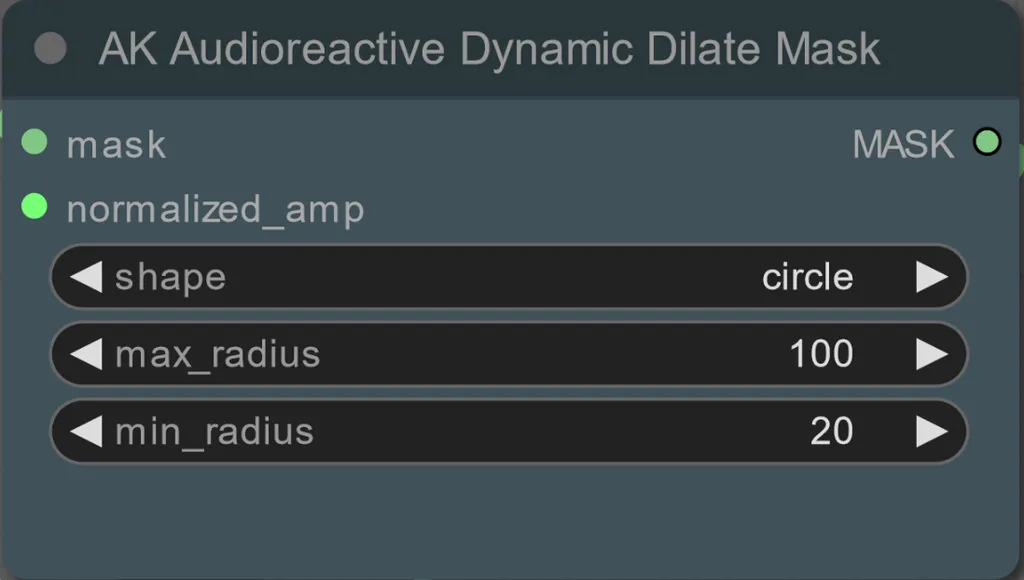
- forma: "círculo" es el más preciso pero tarda más en generarse. Establece esto cuando estés listo para realizar la renderización final. "cuadrado" es rápido de calcular pero menos preciso, lo mejor para probar el flujo de trabajo y decidir sobre las imágenes del adaptador IP.
- max_radius: El radio de la máscara en píxeles cuando el valor de amplitud es máximo (1.0).
- min_radius: El radio de la máscara en píxeles cuando el valor de amplitud es mínimo (0.0).
- Si ya tienes un video de máscara compuesto generado, puedes desactivar el silencio del grupo "Anular Máscara Compuesta" y subirlo. Se recomienda omitir los grupos de máscaras de dilatación si se anula para ahorrar tiempo de procesamiento.
Máscara de Ruido Latente
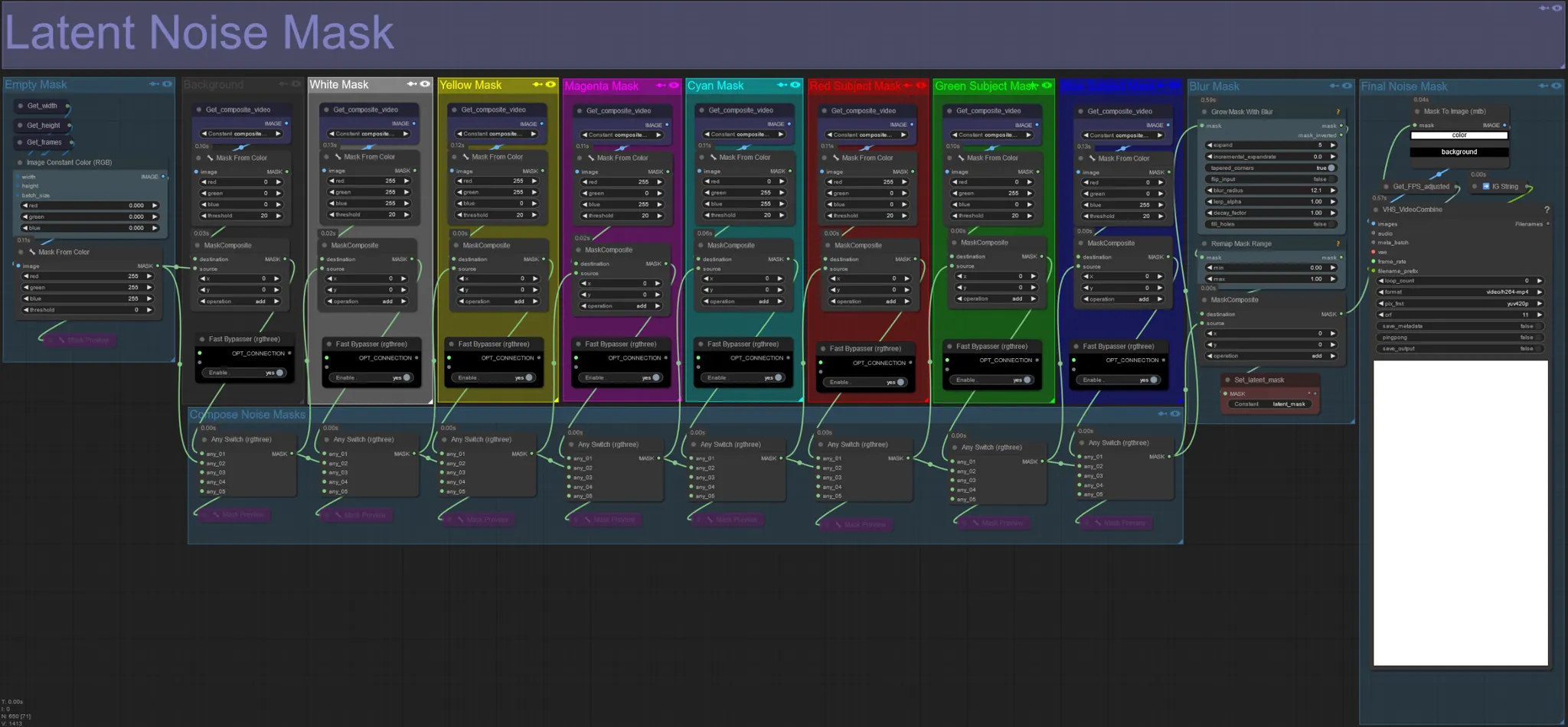
- Usa máscaras de ruido latente para controlar qué máscaras se difunden (soñadas) realmente por el ksampler. Omite el grupo correspondiente a la máscara coloreada que no deseas difundir (es decir, quieres que aparezcan elementos del video original).
- Dejar todos los grupos de máscaras habilitados resulta en una máscara final de ruido blanca (todo se difundirá).
- Ejemplo: Omite el grupo de Máscara de Sujeto Roja haciendo clic en el nodo Desviador Rápido para que tu bailarín o sujeto aparezca en el resultado final.
Video de Entrada Original:

Omisión de Grupos de Máscaras Roja y Amarilla:

Máscara Compuesta
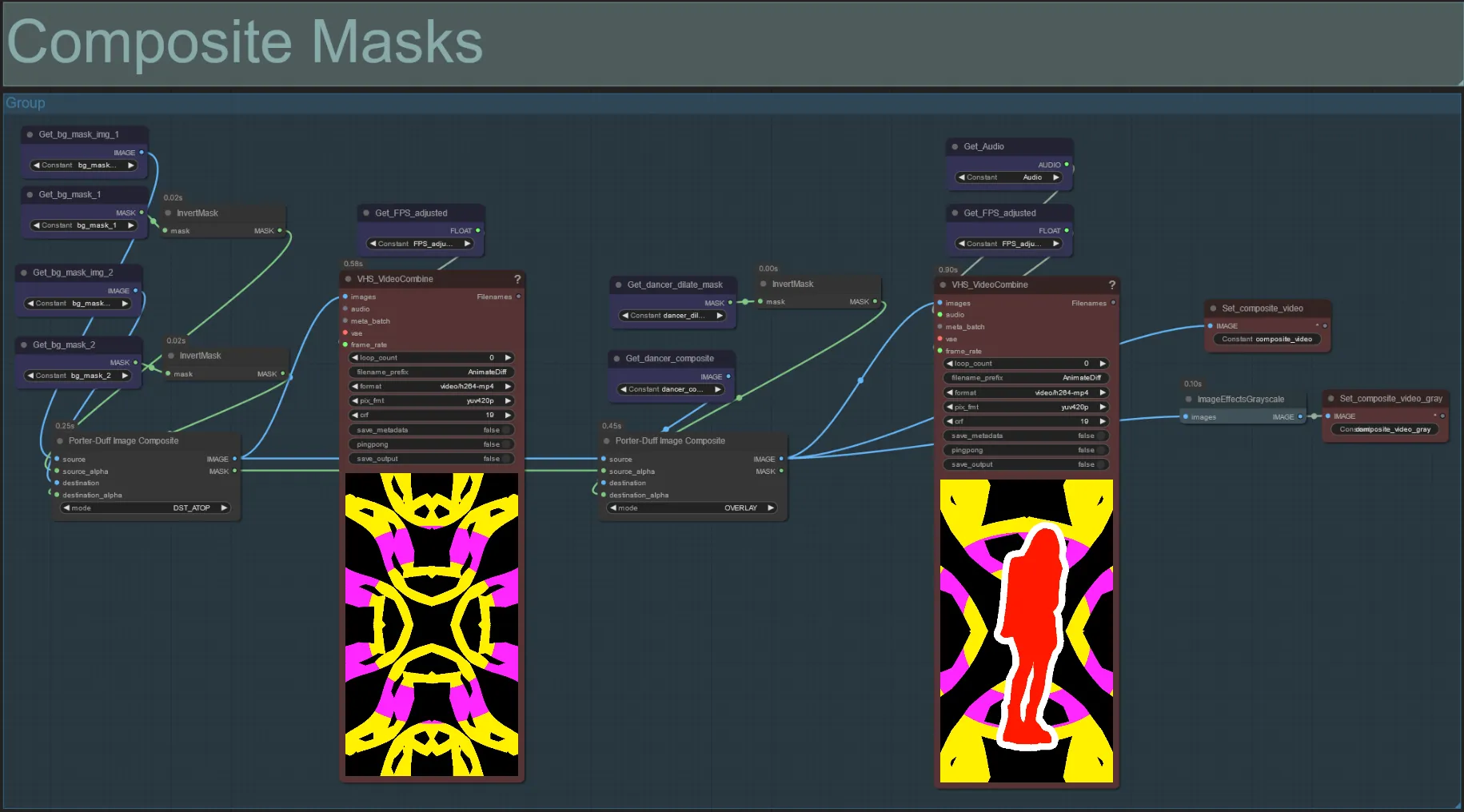
- Esta sección crea la composición final de las máscaras de ruido voronoi con la máscara de sujeto (y máscara de dilatación audioreactiva si está habilitada).
Modelos
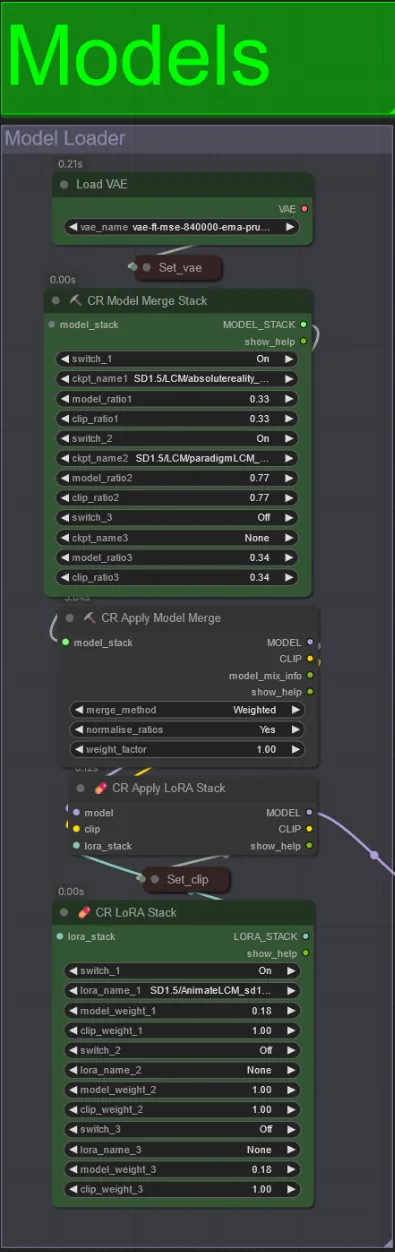
- Usa un buen modelo LCM para el punto de control. Recomiendo ParadigmLCM de Machine Delusions.
- Puedes fusionar varios modelos juntos usando el Apilador de Fusión de Modelos para obtener varios efectos interesantes. Asegúrate de que los pesos sumen 1.0 para los modelos habilitados.
- Opcionalmente, puedes especificar el AnimateLCM_sd15_t2v_lora.safetensors con un peso bajo de 0.18 para mejorar aún más el resultado final.
- Agrega cualquier Lora adicional al modelo usando el apilador de Lora debajo del cargador de modelos.
AnimateDiff

- Puedes establecer un Lora de Movimiento diferente al que usé (LiquidAF-0-1.safetensors)
- Aumenta/disminuye los flotadores de Escala y Efecto para aumentar/disminuir la cantidad de movimiento en la salida.
Adaptadores IP
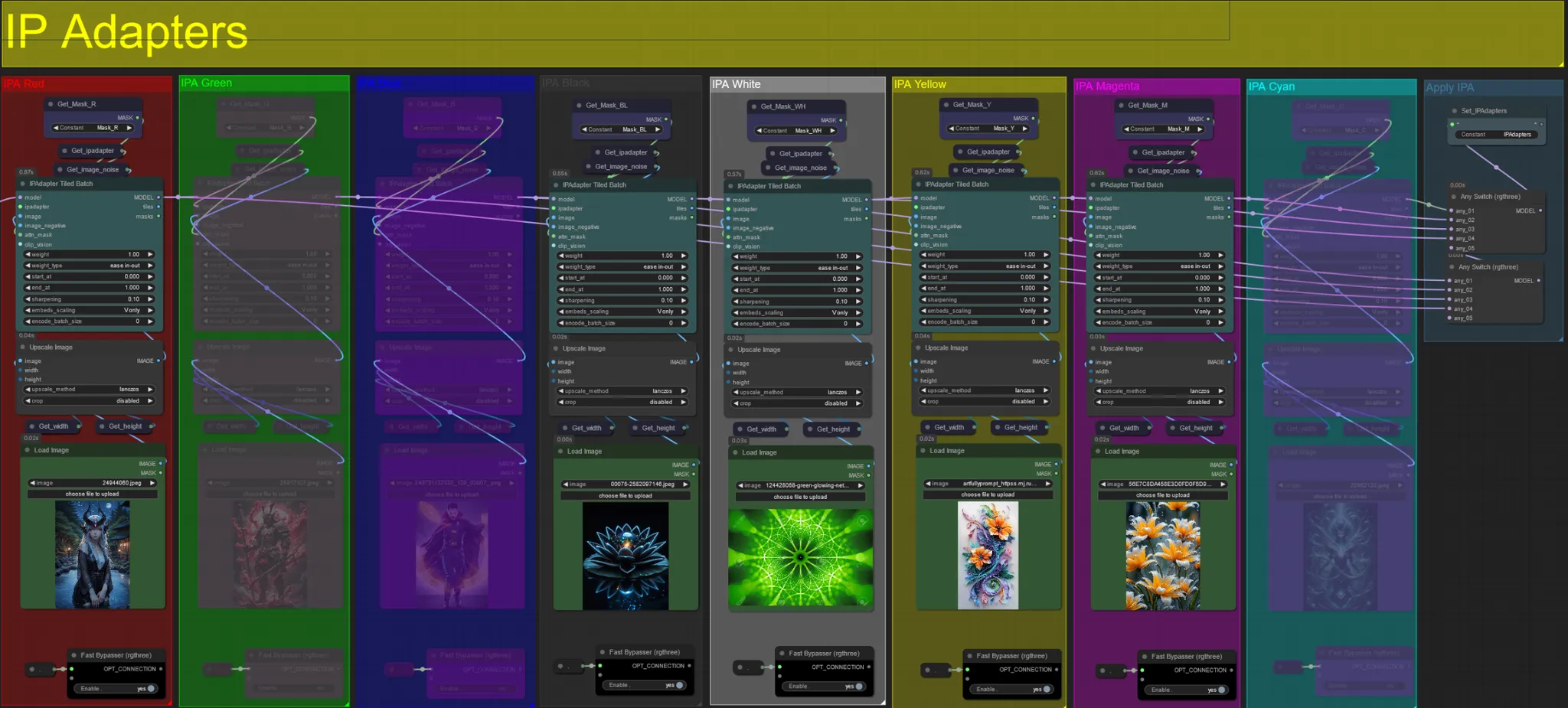
- Aquí puedes especificar las imágenes de referencia que se utilizarán para renderizar los fondos de cada una de las máscaras de dilatación, así como tu(s) sujeto(s) de video.
- El color de cada grupo representa la máscara a la que apunta:
Rojo, Verde, Azul:
- Imágenes de referencia de máscara de sujeto.
Negro:
- Imagen de máscara de fondo, sube una imagen de referencia para el fondo.
Blanco:
- Imágenes de referencia de máscara de dilatación, sube una imagen de referencia para cada máscara de dilatación de color en uso.
Amarillo, Magenta
- Imágenes de referencia de máscara de ruido voronoi.
ControlNet
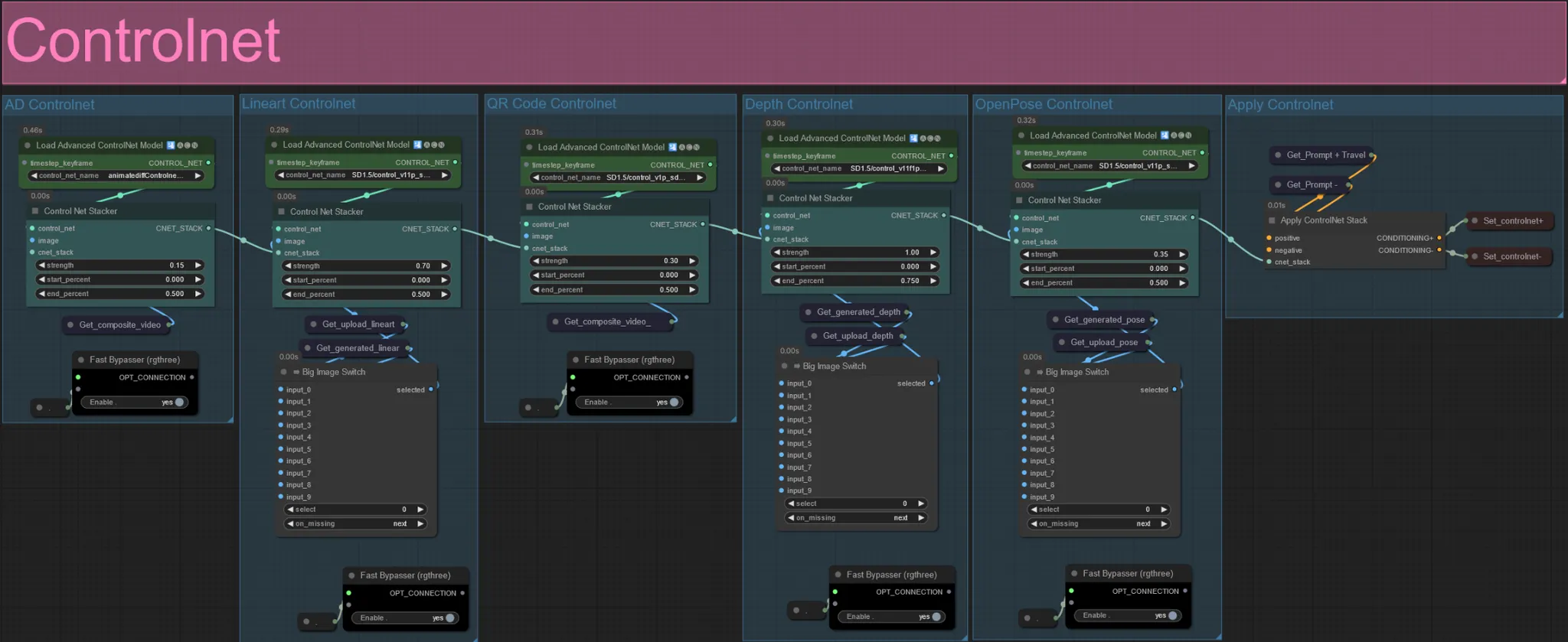
- Este flujo de trabajo hace uso de 5 controlnets diferentes, incluyendo AD, Lineart, QR Code, Depth y OpenPose.
- Todas las entradas a los controlnets se generan automáticamente
- Puedes elegir anular el video de entrada para los controlnets de Lineart, Depth y Openpose si lo deseas desactivando el silencio de los grupos "Anular" como se ve a continuación:
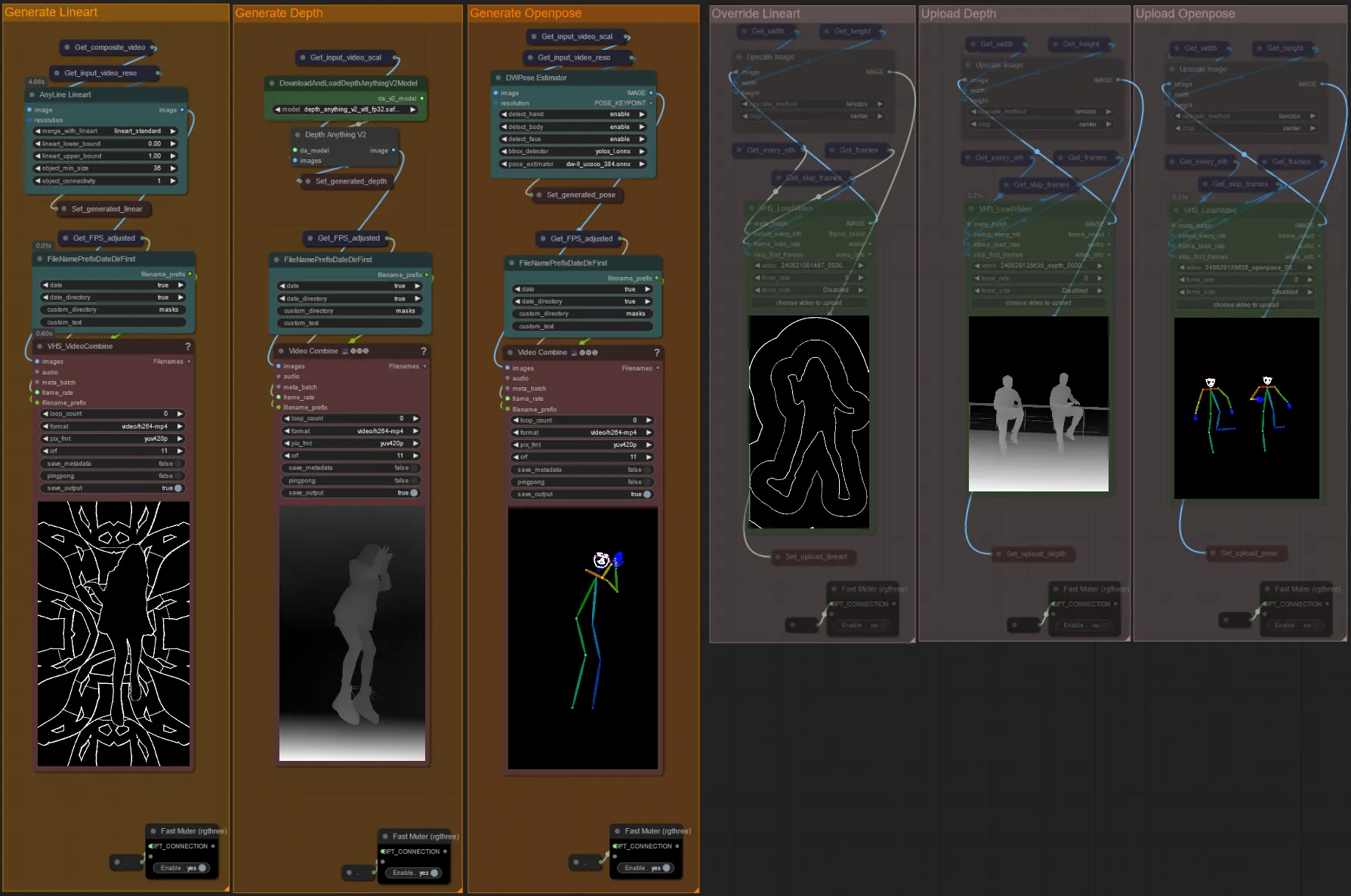
- Se recomienda que también silencies los grupos "Generar" si anulas para ahorrar tiempo de procesamiento.
Consejo:
- Omite el Ksampler y comienza una renderización con tu video de entrada completo. Una vez que se generen todos los videos de preprocesador, guárdalos y súbelos a las anulaciones respectivas. A partir de ahora, al probar el flujo de trabajo, no tendrás que esperar a que se genere cada video de preprocesador individualmente.
Sampler
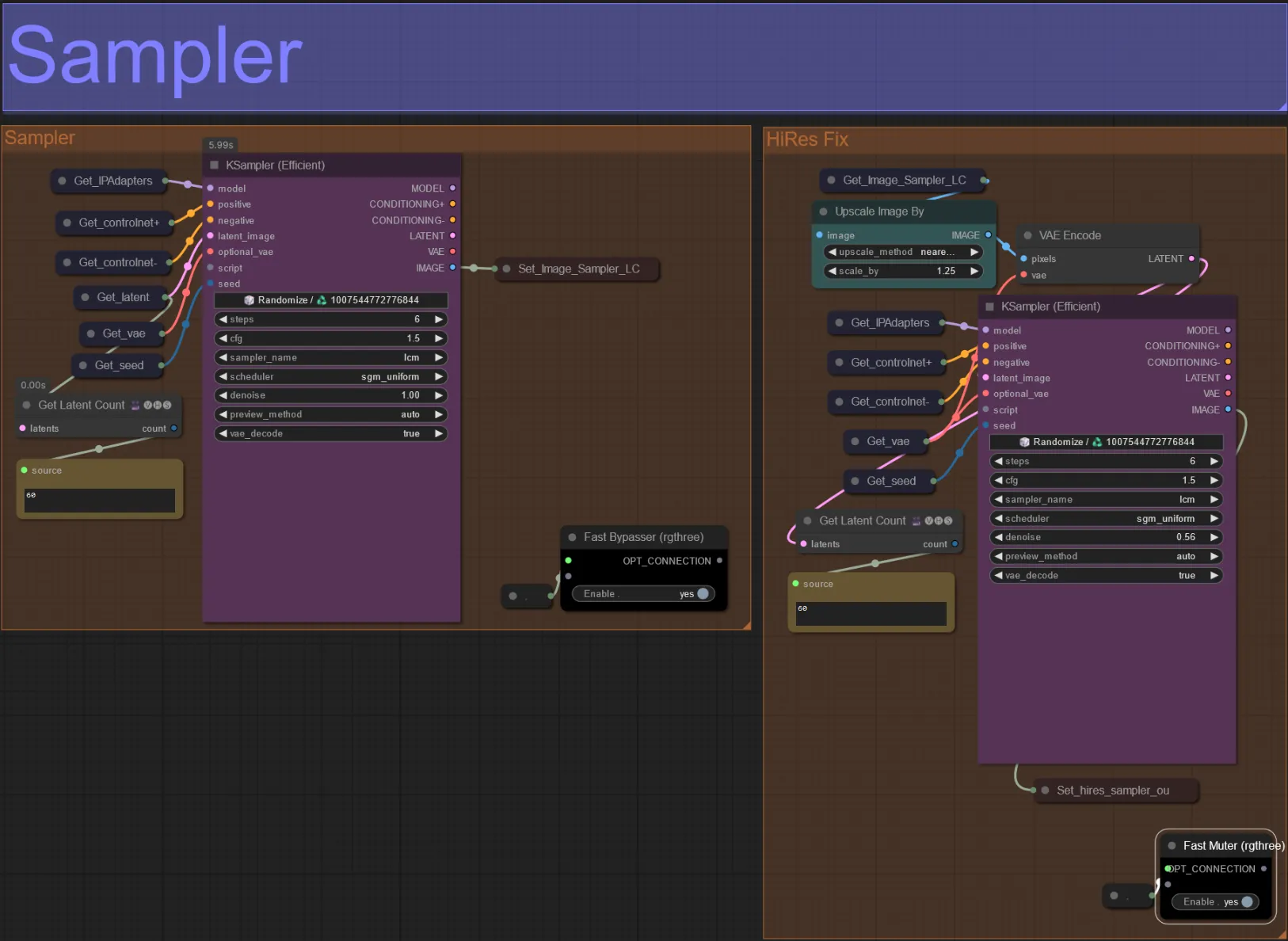
- Por defecto, el grupo de muestreo HiRes Fix estará silenciado para ahorrar tiempo de procesamiento al probar
- Recomiendo omitir el grupo de Sampler también al intentar experimentar con configuraciones de máscara de dilatación para ahorrar tiempo.
- En renderizaciones finales puedes desactivar el silencio del grupo HiRes Fix que mejorará y agregará detalles al resultado final.
Salida
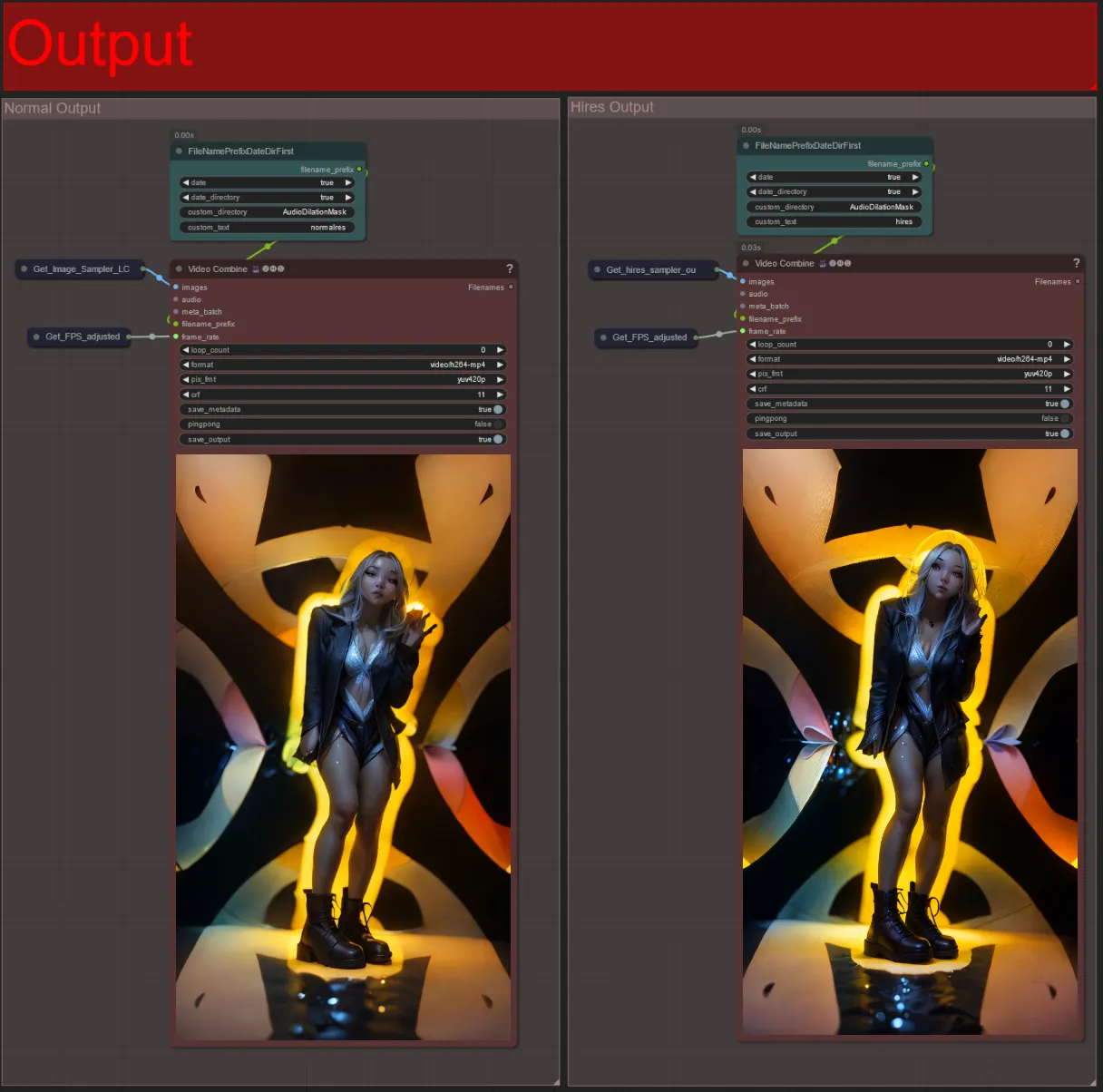
- Hay dos grupos de salida: el de la izquierda es para la salida estándar de muestreo, y el de la derecha es para la salida de muestreo HiRes Fix.
- Puedes cambiar dónde se guardarán los archivos cambiando la cadena "custom_directory" en los nodos "FileNamePrefixDateDirFirst". Por defecto, este nodo guardará los videos de salida en un directorio con fecha y hora en el directorio "output" de ComfyUI
- por ejemplo,
…/ComfyUI/output/240812/<custom_directory>/<my_video>.mp4
- por ejemplo,
Crear un video audioreactivo puede agregar energía inmersiva y pulsante a tu sujeto, con cada cuadro respondiendo al ritmo en tiempo real. Así que, sumérgete en el mundo del arte audioreactivo y disfruta de las transformaciones guiadas por el ritmo.
Acerca del Autor
Akatz AI:
- Sitio web:
Contacts:
- Email: akatzfey@sendysoftware.com

