
Esta guía de Unsampling, escrita por Inner-Reflections, contribuye en gran medida a explorar el método de Unsampling para lograr una transferencia de estilo de video dramáticamente consistente.
1. Introducción: Control de Ruido Latente con Unsampling
El Ruido Latente es la base de todo lo que hacemos con Stable Diffusion. Es increíble dar un paso atrás y pensar en lo que somos capaces de lograr con esto. Sin embargo, generalmente hablando estamos obligados a usar un número aleatorio para generar el ruido. ¿Qué pasaría si pudiéramos controlarlo?
No soy el primero en usar Unsampling. Ha existido durante mucho tiempo y se ha utilizado de varias maneras diferentes. Sin embargo, hasta ahora generalmente no he estado satisfecho con los resultados. He pasado varios meses encontrando las mejores configuraciones y espero que disfrutes esta guía.
Al usar el proceso de muestreo con AnimateDiff/Hotshot podemos encontrar ruido que represente nuestro video original y, por lo tanto, facilite cualquier tipo de transferencia de estilo. Es especialmente útil para mantener Hotshot consistente dado su ventana de contexto de 8 cuadros.
Este proceso de unsampling esencialmente convierte nuestro video de entrada en ruido latente que mantiene el movimiento y la composición del original. Luego podemos usar este ruido representacional como punto de partida para el proceso de difusión en lugar de ruido aleatorio. Esto permite que la IA aplique el estilo objetivo mientras mantiene las cosas temporalmente consistentes.
Esta guía asume que has instalado AnimateDiff y/o Hotshot. Si aún no lo has hecho, las guías están disponibles aquí:
AnimateDiff: https://civitai.com/articles/2379
Guía de Hotshot XL: https://civitai.com/articles/2601/
Enlace al recurso - Si quieres publicar videos en Civitai usando este flujo de trabajo. https://civitai.com/models/544534
2. Requisitos del Sistema para este Flujo de Trabajo
Se recomienda una computadora con Windows y una tarjeta gráfica NVIDIA que tenga al menos 12GB de VRAM. En la plataforma RunComfy, usa una máquina de nivel Medio (16GB de VRAM) o superior. Este proceso no requiere más VRAM que los flujos de trabajo estándar de AnimateDiff o Hotshot, pero lleva casi el doble de tiempo, ya que básicamente ejecuta el proceso de difusión dos veces, una para upsampling y otra para resampling con el estilo objetivo.
3. Explicaciones de Nodos y Guía de Configuraciones
Nodo: Custom Sampler
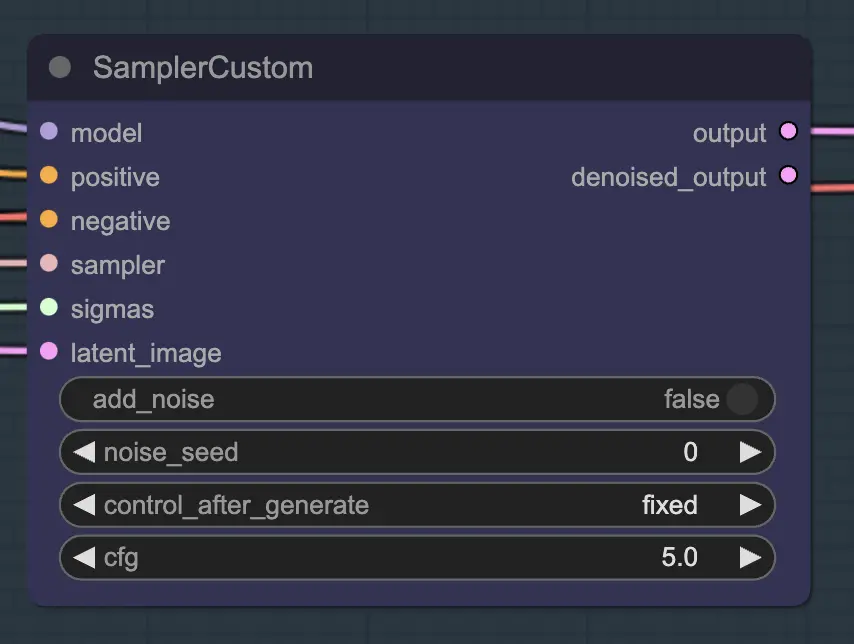
La parte principal de esto es usar el Custom Sampler que divide todas las configuraciones que normalmente ves en el KSampler regular en piezas:
Este es el nodo principal de KSampler - para unsampling agregar ruido/semilla no tiene ningún efecto (que yo sepa). CFG importa - generalmente hablando cuanto más alto sea el CFG en este paso, más se parecerá el video a tu original. Un CFG más alto obliga al unsampler a igualar más de cerca la entrada.
Nodo: KSampler Select
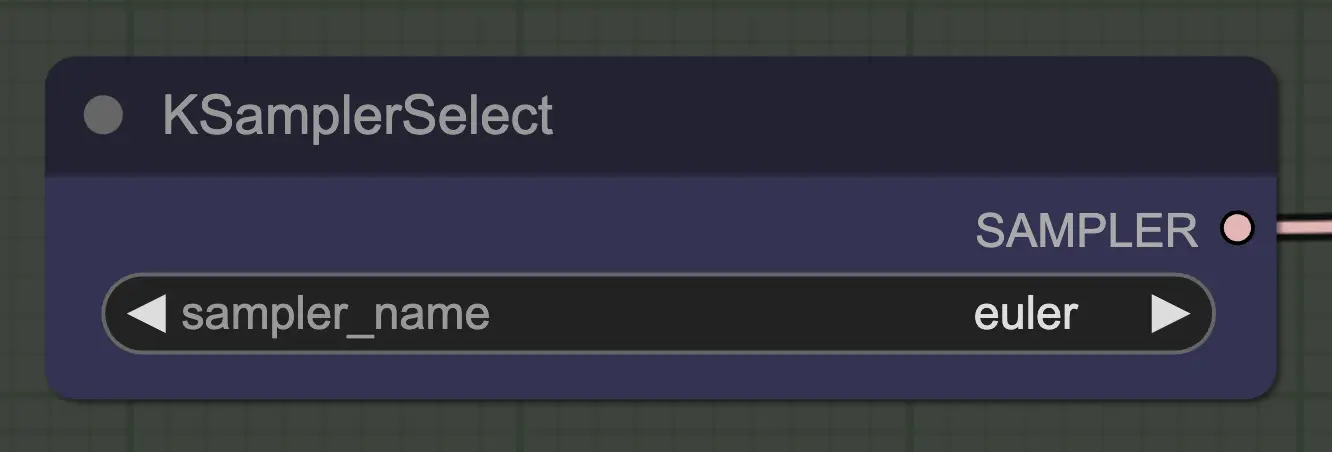
Lo más importante es usar un sampler que converja! Por eso usamos euler en lugar de euler a, ya que este último resulta en más aleatoriedad/inestabilidad. Los samplers ancestrales que agregan ruido en cada paso impiden que el unsampling converja limpiamente. Si quieres leer más sobre esto, siempre he encontrado útil this article. @spacepxl en reddit sugiere que DPM++ 2M Karras es quizás el sampler más preciso dependiendo del caso de uso.
Nodo: Align Your Step Scheduler
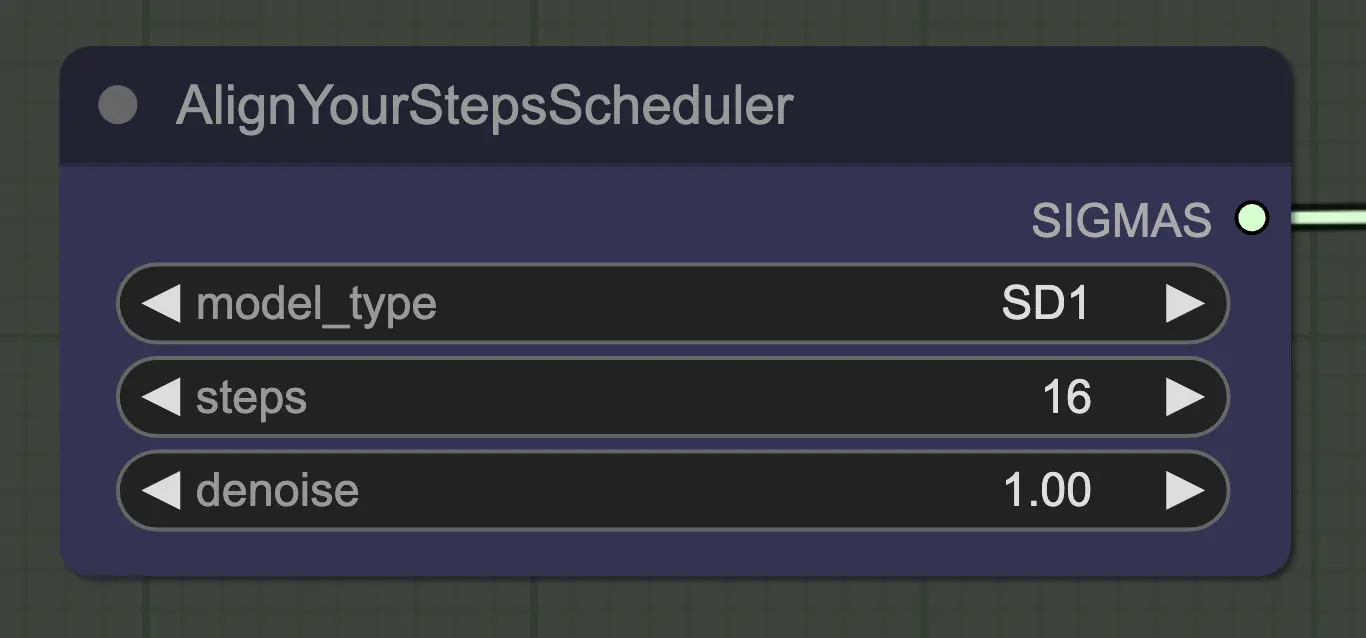
Cualquier scheduler funcionará bien aquí - Align Your Steps (AYS) sin embargo obtiene buenos resultados con 16 pasos, por lo que he optado por usarlo para reducir el tiempo de computación. Más pasos convergerán más completamente pero con rendimientos decrecientes.
Nodo: Flip Sigma
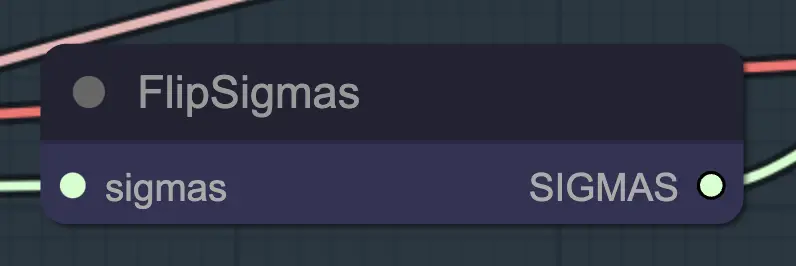
Flip Sigma es el nodo mágico que hace que el unsampling ocurra! Al voltear el schedule de sigma, invertimos el proceso de difusión para pasar de una imagen de entrada limpia a ruido representativo.
Nodo: Prompt
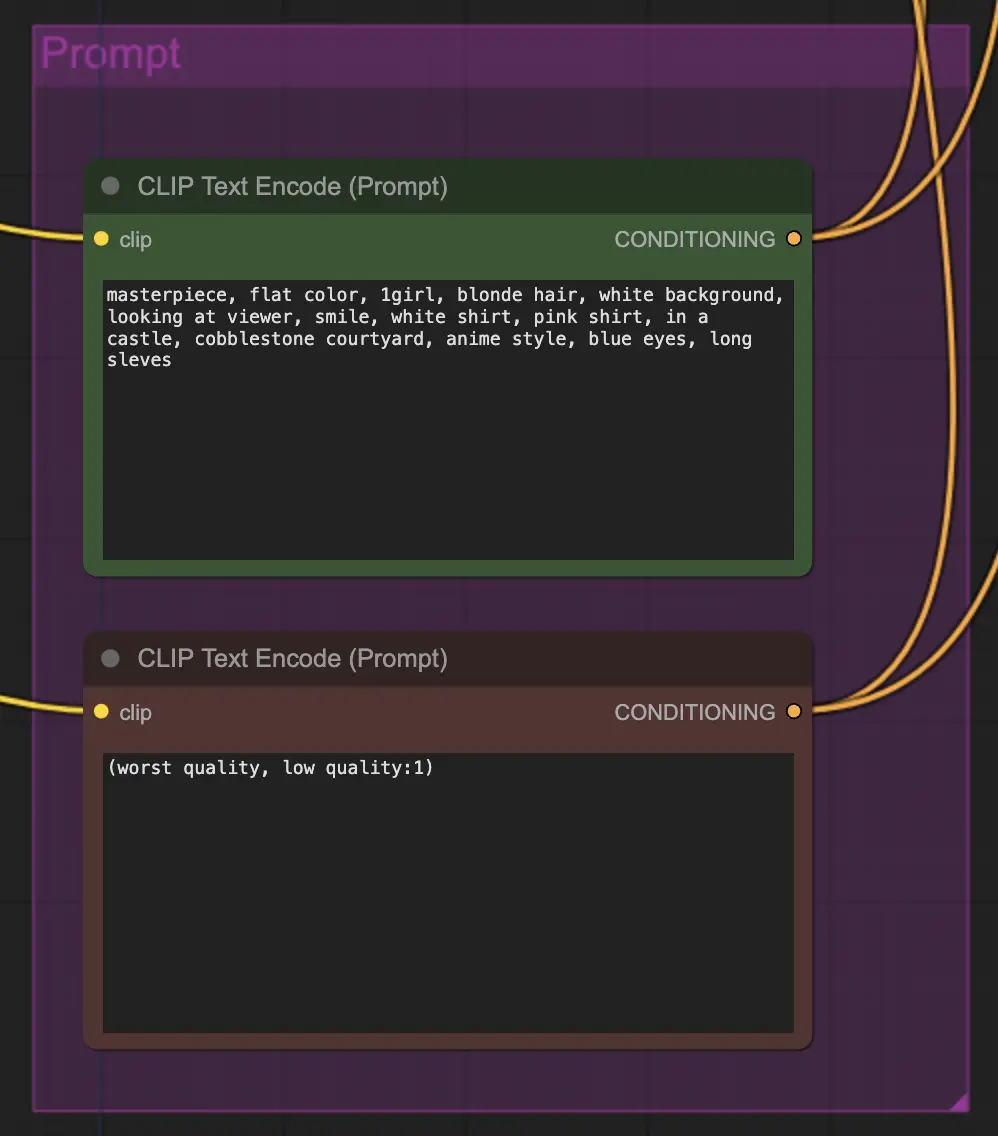
El prompting importa bastante en este método por alguna razón. Un buen prompt puede realmente mejorar la coherencia del video, especialmente cuanto más quieras impulsar la transformación. Para este ejemplo, he alimentado la misma condición tanto al unsampler como al resampler. Parece funcionar bien generalmente - sin embargo, nada te impide poner una condición en blanco en el unsampler - encuentro que ayuda a mejorar la transferencia de estilo, quizás con una pequeña pérdida de consistencia.
Nodo: Resampling
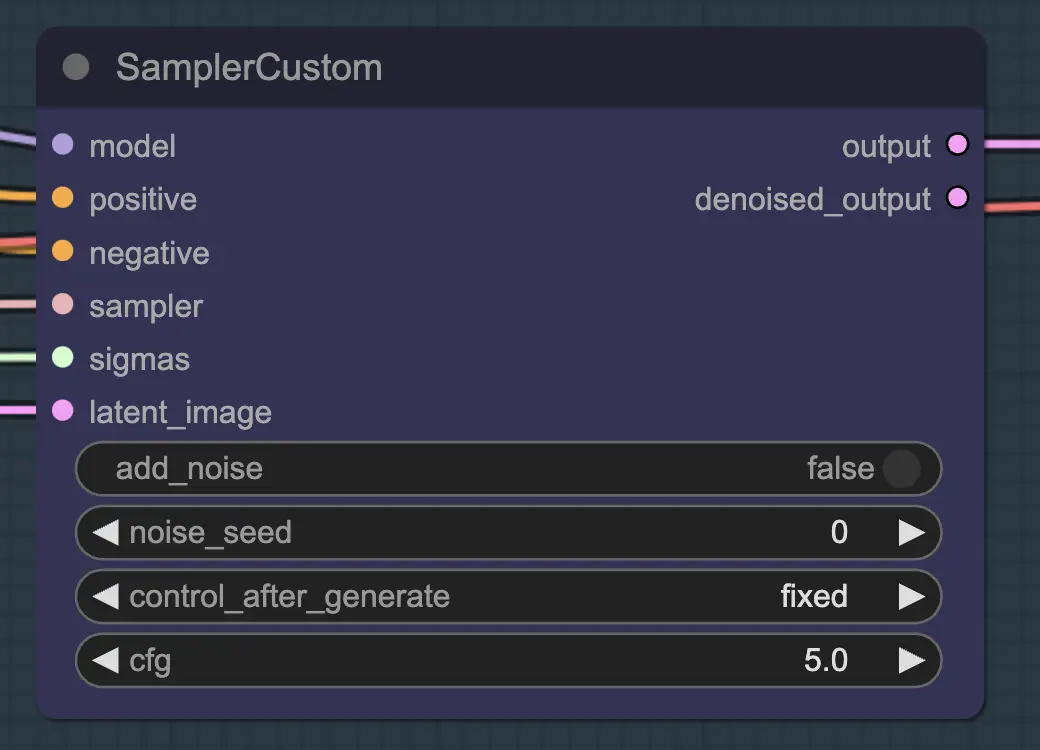
Para el resampling es importante tener el agregado de ruido apagado (aunque tener ruido vacío en las configuraciones de muestra de AnimateDiff tiene el mismo efecto - he hecho ambos para mi flujo de trabajo). Si agregas ruido durante el resampling obtendrás un resultado inconsistente y ruidoso, al menos con configuraciones predeterminadas. De lo contrario, sugiero comenzar con un CFG bastante bajo combinado con configuraciones de ControlNet débiles, ya que eso parece dar los resultados más consistentes mientras aún permite que el prompt influencie el estilo.
Otras Configuraciones
El resto de mis configuraciones son preferencia personal. He simplificado este flujo de trabajo tanto como creo posible mientras aún incluyo los componentes y configuraciones clave.
4. Información del Flujo de Trabajo
El flujo de trabajo predeterminado usa el modelo SD1.5. Sin embargo, puedes cambiar a SDXL simplemente cambiando el checkpoint, VAE, modelo AnimateDiff, modelo ControlNet y modelo de schedule de pasos a SDXL.
5. Notas Importantes/Problemas
- Parpadeo - Si miras los latentes decodificados y previsualizados creados por unsampling en mis flujos de trabajo, notarás algunos con obvias anormalidades de color. La causa exacta no está clara para mí, y generalmente no afectan los resultados finales. Estas anormalidades son especialmente evidentes con SDXL. Sin embargo, a veces pueden causar parpadeo en tu video. La causa principal parece estar relacionada con los ControlNets, por lo que reducir su fuerza puede ayudar. Cambiar el prompt o incluso alterar ligeramente el scheduler también puede hacer una diferencia. Todavía encuentro este problema a veces - si tienes una solución, por favor házmelo saber!
- DPM++ 2M puede a veces mejorar el parpadeo.
6. ¿Dónde Ir Desde Aquí?
Esto se siente como una forma completamente nueva de controlar la consistencia del video, por lo que hay mucho que explorar. Si quieres mis sugerencias:
- Intenta combinar/enmascarar ruido de varios videos fuente.
- Agrega IPAdapter para una transformación de personajes consistente.
Sobre el Autor
Inner-Reflections
- https://x.com/InnerRefle11312
- https://civitai.com/user/Inner_Reflections_AI
