Segment Anything V2 (SAM2) | Segmentation Vidéo
Segment Anything V2 (SAM2), développé par Meta AI, est un modèle d'IA révolutionnaire qui simplifie la segmentation d'objets dans les images et les vidéos. Ses capacités de segmentation intelligente, combinées à divers modes d'entrée, simplifient le flux de travail pour les artistes de l'IA. La segmentation vidéo améliorée de SAM2, le temps d'interaction réduit et les vitesses d'inférence rapides en font un outil puissant pour repousser les limites de la création artistique pilotée par l'IA. Le nœud ComfyUI-LivePortraitKJ est créé par Kijai, et ce flux de travail est entièrement développé par lui.Flux de travail ComfyUI Segment Anything V2 (SAM2)
- Workflows entièrement opérationnels
- Aucun nœud ou modèle manquant
- Aucune configuration manuelle requise
- Propose des visuels époustouflants
Exemples ComfyUI Segment Anything V2 (SAM2)
Description ComfyUI Segment Anything V2 (SAM2)
Segment Anything V2, également connu sous le nom de SAM2, est un modèle d'IA révolutionnaire développé par Meta AI qui révolutionne la segmentation d'objets dans les images et les vidéos.
Qu'est-ce que Segment Anything V2 (SAM2) ?
Segment Anything V2 est un modèle d'IA de pointe qui permet la segmentation transparente des objets dans les images et les vidéos. C'est le premier modèle unifié capable de gérer les tâches de segmentation d'images et de vidéos avec une précision et une efficacité exceptionnelles. Segment Anything V2 (SAM2) s'appuie sur le succès de son prédécesseur, le Segment Anything Model (SAM), en étendant ses capacités de promptable au domaine de la vidéo.
Avec Segment Anything V2 (SAM2), les utilisateurs peuvent sélectionner un objet dans une image ou une image vidéo en utilisant diverses méthodes d'entrée, telles qu'un clic, une boîte englobante ou un masque. Le modèle segmente ensuite intelligemment l'objet sélectionné, permettant une extraction et une manipulation précises des éléments spécifiques du contenu visuel.
Points forts de Segment Anything V2 (SAM2)
- Performance de pointe : SAM2 surpasse les modèles existants dans le domaine de la segmentation d'objets pour les images et les vidéos. Il établit une nouvelle référence en matière de précision et de précision, surpassant les performances de son prédécesseur, SAM, dans les tâches de segmentation d'images.
- Modèle unifié pour les images et les vidéos : SAM2 est le premier modèle à offrir une solution unifiée pour segmenter les objets dans les images et les vidéos. Cette intégration simplifie le flux de travail pour les artistes de l'IA, car ils peuvent utiliser un seul modèle pour diverses tâches de segmentation.
- Capacités de segmentation vidéo améliorées : SAM2 excelle dans la segmentation d'objets vidéo, en particulier dans le suivi des parties d'objets. Il surpasse les modèles de segmentation vidéo existants, offrant une précision et une cohérence améliorées dans la segmentation des objets à travers les images.
- Points forts de Segment A. Temps d'interaction réduit : Par rapport aux méthodes de segmentation vidéo interactives existantes, SAM2 nécessite moins de temps d'interaction de la part des utilisateurs. Cette efficacité permet aux artistes de l'IA de se concentrer davantage sur leur vision créative et de passer moins de temps sur les tâches de segmentation manuelle.
- Conception simple et inférence rapide : Malgré ses capacités avancées, SAM2 maintient une conception architecturale simple et offre des vitesses d'inférence rapides. Cela garantit que les artistes de l'IA peuvent intégrer SAM2 dans leurs flux de travail sans compromettre la performance ou l'efficacité.
Comment fonctionne Segment Anything V2 (SAM2)
SAM2 étend les capacités de promptable de SAM aux vidéos en introduisant un module de mémoire par session qui capture les informations sur l'objet cible, permettant le suivi des objets à travers les images, même avec des disparitions temporaires. L'architecture de streaming traite les images vidéo une à la fois, se comportant comme SAM pour les images lorsque le module de mémoire est vide. Cela permet un traitement vidéo en temps réel et une généralisation naturelle des capacités de SAM. SAM2 prend également en charge les corrections de prédiction de masque interactif basées sur les invites des utilisateurs. Le modèle utilise une architecture de transformateur avec une mémoire en streaming et est formé sur le jeu de données SA-V, le plus grand ensemble de données de segmentation vidéo collecté à l'aide d'un moteur de données en boucle fermée qui améliore à la fois le modèle et les données grâce à l'interaction utilisateur.
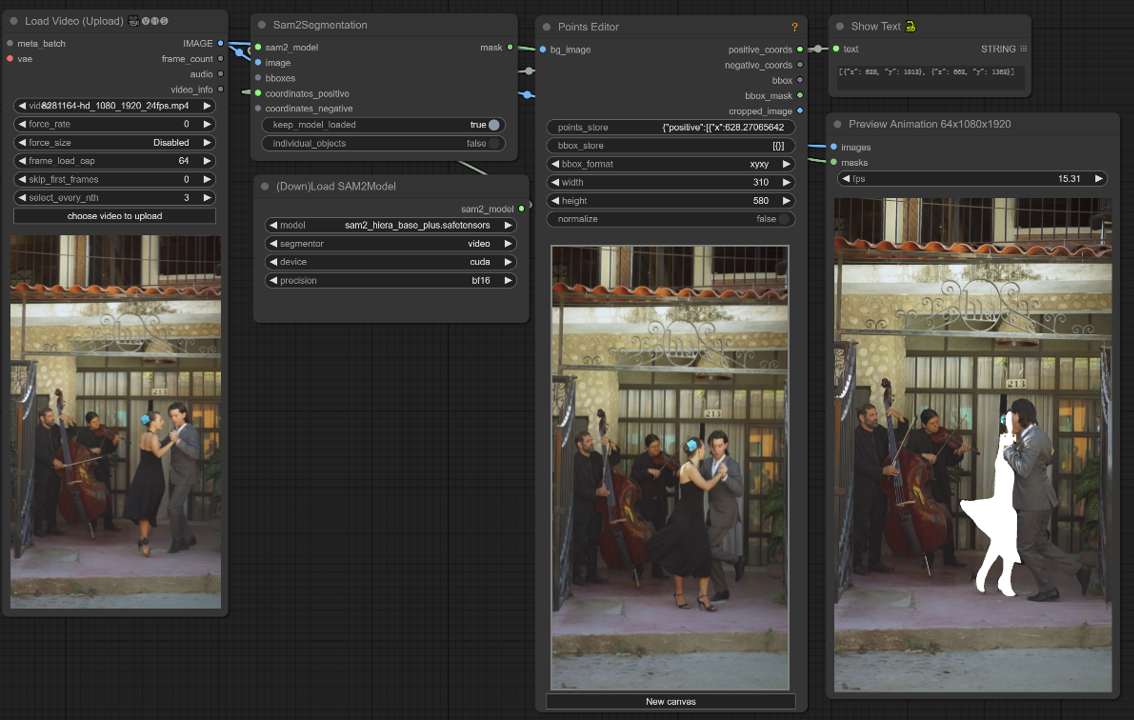
Comment utiliser Segment Anything V2 (SAM2) dans ComfyUI
Ce flux de travail ComfyUI prend en charge la sélection d'un objet dans une image vidéo en utilisant un clic/point.
1. Charger la vidéo (Télécharger)
Chargement de la vidéo : Sélectionnez et téléchargez la vidéo que vous souhaitez traiter.

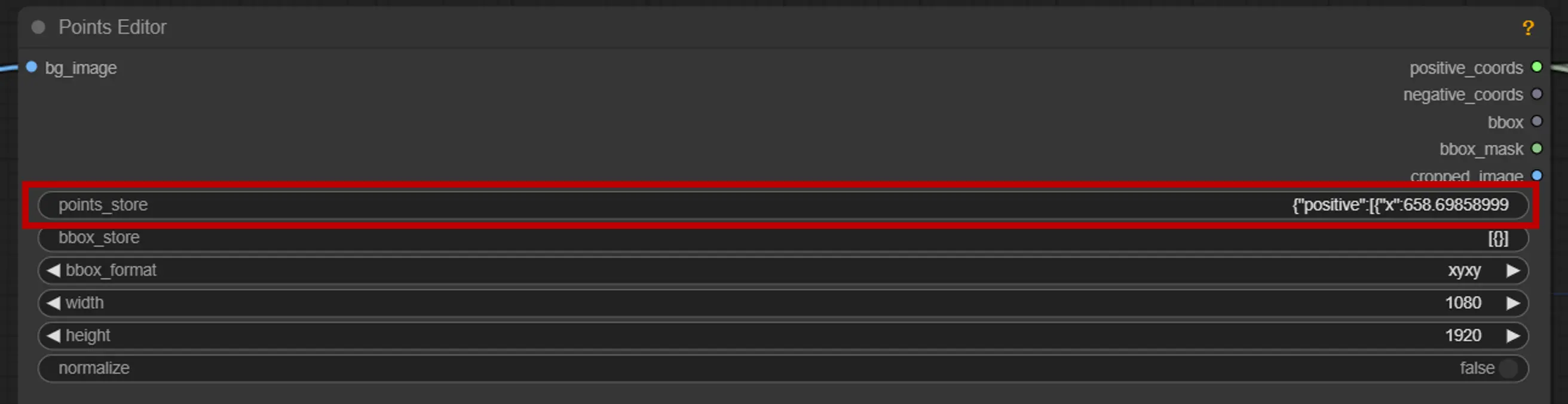
2. Éditeur de points
point clé : Placez trois points clés sur la toile—positive0, positive1, et negative0:
positive0 et positive1 marquent les régions ou objets que vous souhaitez segmenter.
negative0 aide à exclure les zones ou distractions indésirables.

points_store : Vous permet d'ajouter ou de supprimer des points selon les besoins pour affiner le processus de segmentation.
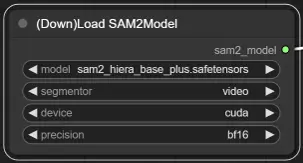
3. Sélection du modèle SAM2
Options de modèle : Choisissez parmi les modèles SAM2 disponibles : tiny, small, large, ou base_plus. Les modèles plus grands fournissent de meilleurs résultats mais nécessitent plus de temps de chargement.
Pour plus d'informations, veuillez visiter .