LTX Vidéo | Image+Texte vers Vidéo
Lightricks a développé LTX Vidéo, un modèle de génération de vidéos utilisant des techniques basées sur la diffusion. Le modèle peut générer des vidéos à partir de prompts textuels ou d'une combinaison de prompts image et texte. LTX Vidéo produit des vidéos à une résolution de 768x512 et un taux de 24 FPS. Le modèle LTX a été entraîné sur un ensemble de données diversifié pour générer du contenu vidéo varié. Découvrez les techniques derrière le modèle LTX et utilisez-le avec ComfyUI.Flux de travail ComfyUI LTX Video
- Workflows entièrement opérationnels
- Aucun nœud ou modèle manquant
- Aucune configuration manuelle requise
- Propose des visuels époustouflants
Exemples ComfyUI LTX Video
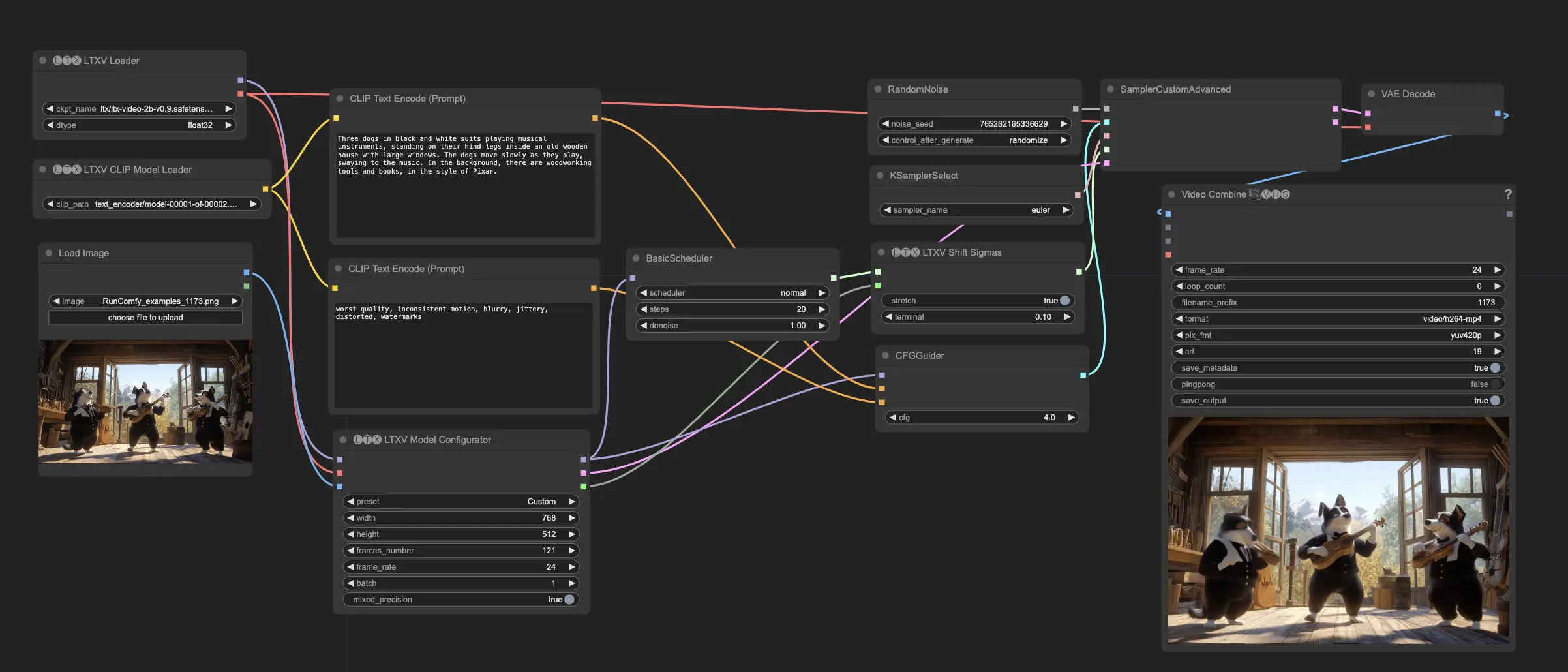
Description ComfyUI LTX Video
LTX Vidéo est un modèle de génération de vidéos basé sur la diffusion développé par Lightricks. Il est capable de générer des vidéos à partir de prompts textuels (texte-vers-vidéo) ou d'une combinaison de prompts image et texte (image+texte-vers-vidéo). LTX Vidéo produit des vidéos de 24 images par seconde (FPS) à une résolution de 768x512 plus rapidement qu'elles ne peuvent être regardées. Le modèle a été entraîné sur un vaste ensemble de données contenant des vidéos diversifiées, lui permettant de générer du contenu vidéo réaliste et varié à haute résolution.
Le Modèle LTX Vidéo et les Nœuds ComfyUI-LTXVideo ont été développés par Lightricks. Tout le crédit revient à leur travail dans la création de LTX Vidéo. Pour plus d'informations sur LTX Vidéo et les projets de Lightricks, veuillez visiter leur dépôt GitHub à l'adresse https://github.com/Lightricks/LTX-Video ou leur site Web à l'adresse https://www.lightricks.com/ltxv.
Techniques derrière le Modèle LTX
LTX Vidéo utilise une approche basée sur la diffusion pour générer des vidéos. Les modèles de diffusion fonctionnent en réduisant progressivement le bruit d'une entrée bruyante sur plusieurs étapes pour générer le résultat final. Dans le cas de LTX Vidéo, le modèle prend une représentation latente bruyante en entrée et la débruite itérativement pour produire une séquence d'images vidéo. Le processus de débruitage est guidé par les prompts textuels ou image+texte fournis, qui contrôlent le contenu et le style de la vidéo générée.
Les techniques clés employées par LTX Vidéo incluent :
- Génération de vidéos basée sur la diffusion : En exploitant les modèles de diffusion, LTX Vidéo peut générer des vidéos de haute qualité avec un mouvement réaliste et une cohérence entre les images.
- Synthèse texte-vers-vidéo : LTX Vidéo peut générer des vidéos uniquement basées sur des descriptions textuelles, permettant aux utilisateurs de créer des vidéos personnalisées à partir de zéro en utilisant des prompts en langage naturel.
- Synthèse image+texte-vers-vidéo : LTX Vidéo prend également en charge la génération de vidéos en combinant une image initiale avec un prompt textuel. Cela permet aux utilisateurs de fournir un point de départ pour la vidéo et de guider son contenu et son style à l'aide de texte.
Comment Utiliser le Workflow LTX Vidéo dans ComfyUI
- Préparez l'Entrée :
- Le workflow par défaut est la génération image + texte-vers-vidéo. Fournissez une image initiale avec un prompt textuel. L'image sert de point de départ, et le modèle générera une vidéo basée à la fois sur l'image et le texte accompagnant. Notez que ce modèle nécessite des prompts longs et descriptifs ; si le prompt est trop court, la qualité en souffrira grandement.
- Configurez les Paramètres du Modèle :
- Définissez la résolution et le nombre d'images souhaités pour le contenu généré. La résolution doit être divisible par 32, et le nombre d'images doit être divisible par 8 + 1 (par exemple, 257 images). LTX fonctionne mieux avec des résolutions inférieures à 720x1280 pixels et moins de 257 images.
- Ajustez d'autres paramètres tels que les étapes de diffusion, le calendrier de bruit et l'échelle de guidage selon vos besoins. Ces paramètres contrôlent la qualité et la diversité du résultat généré.
- Générez le Contenu :
- Le résultat aura la résolution et le nombre d'images spécifiés, et il s'alignera avec le prompt d'entrée fourni.
Limitations du Modèle LTX
- LTX Vidéo n'est pas destiné à fournir des informations factuelles.
- En tant que modèle statistique, LTX Vidéo pourrait amplifier les biais sociétaux existants présents dans les données d'entraînement.
- Les vidéos générées peuvent ne pas correspondre parfaitement aux prompts fournis.
- La qualité de l'adhésion aux prompts dépend fortement du style de prompting utilisé.
Licence
Veuillez utiliser le modèle à des fins conformes à la
