Audioreactive Dancers Evolved
Il flusso di lavoro Audioreactive Dancers Evolved trasforma i soggetti video in animazioni affascinanti sincronizzate con i ritmi musicali, su sfondi dinamici, geometrici e psichedelici. Progettato per la flessibilità, consente agli utenti di controllare i fotogrammi video, il mascheramento, la reattività audio e i dettagli dei motivi. Con caratteristiche come maschere di dilatazione, ControlNet e animazione del rumore sincronizzata con il ritmo, questo flusso di lavoro ComfyUI consente ai creativi di fondere arte, suono e movimento, creando esperienze visive immersive e ritmiche con visualizzazioni audioreattive.ComfyUI Audioreactive Dancers Evolved Flusso di lavoro

- Workflow completamente operativi
- Nessun nodo o modello mancante
- Nessuna configurazione manuale richiesta
- Presenta visuali mozzafiato
ComfyUI Audioreactive Dancers Evolved Esempi
ComfyUI Audioreactive Dancers Evolved Descrizione
Crea animazioni video mozzafiato trasformando il tuo soggetto (ballerino) e donagli uno sfondo dinamico audioreattivo composto da varie geometrie complesse e motivi psichedelici. Puoi usare questo flusso di lavoro con un singolo soggetto o più soggetti. Con questo flusso di lavoro, puoi produrre effetti visivi audioreattivi affascinanti che si sincronizzano perfettamente con il ritmo della musica, offrendo un'esperienza immersiva. Il flusso di lavoro ti consente di usarlo con un singolo soggetto o più soggetti, tutti arricchiti con elementi audioreattivi.
Come utilizzare il flusso di lavoro Audioreactive Dancers Evolved:
- Carica un video del soggetto nella sezione Input
- Seleziona la larghezza e l'altezza desiderate del video finale, insieme a quanti fotogrammi del video di input devono essere saltati con "every_nth". Puoi anche limitare il numero totale di fotogrammi da renderizzare con "frame_load_cap".
- Compila il prompt positivo e negativo. Imposta i tempi di batch frame per corrispondere al momento in cui desideri che avvengano le transizioni di scena.
- Carica immagini per ciascuno dei colori della maschera del soggetto IP Adapter predefiniti:
- Rosso, Verde, Blu = soggetto(i)
- Nero = Sfondo
- Bianco = Maschera di dilatazione audioreattiva bianca
- Giallo, Magenta = Motivi della maschera del rumore di fondo
- Carica un buon checkpoint LCM (io uso ParadigmLCM di Machine Delusions) nella sezione "Models".
- Aggiungi eventuali loras usando lo stacker Lora sotto il caricatore del modello
- Premi Queue Prompt
Guida Video
Colore dei Nodi e dei Gruppi
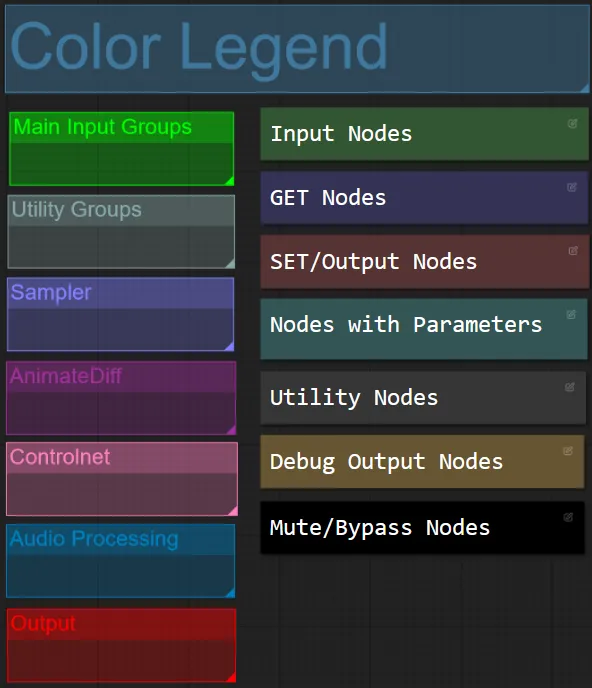
- Per questo flusso di lavoro ho coordinato i colori dei nodi in base alla loro funzionalità all'interno di ciascun gruppo.
- I titoli delle sezioni di gruppo sono coordinati per colore per una più facile differenziazione.
Input
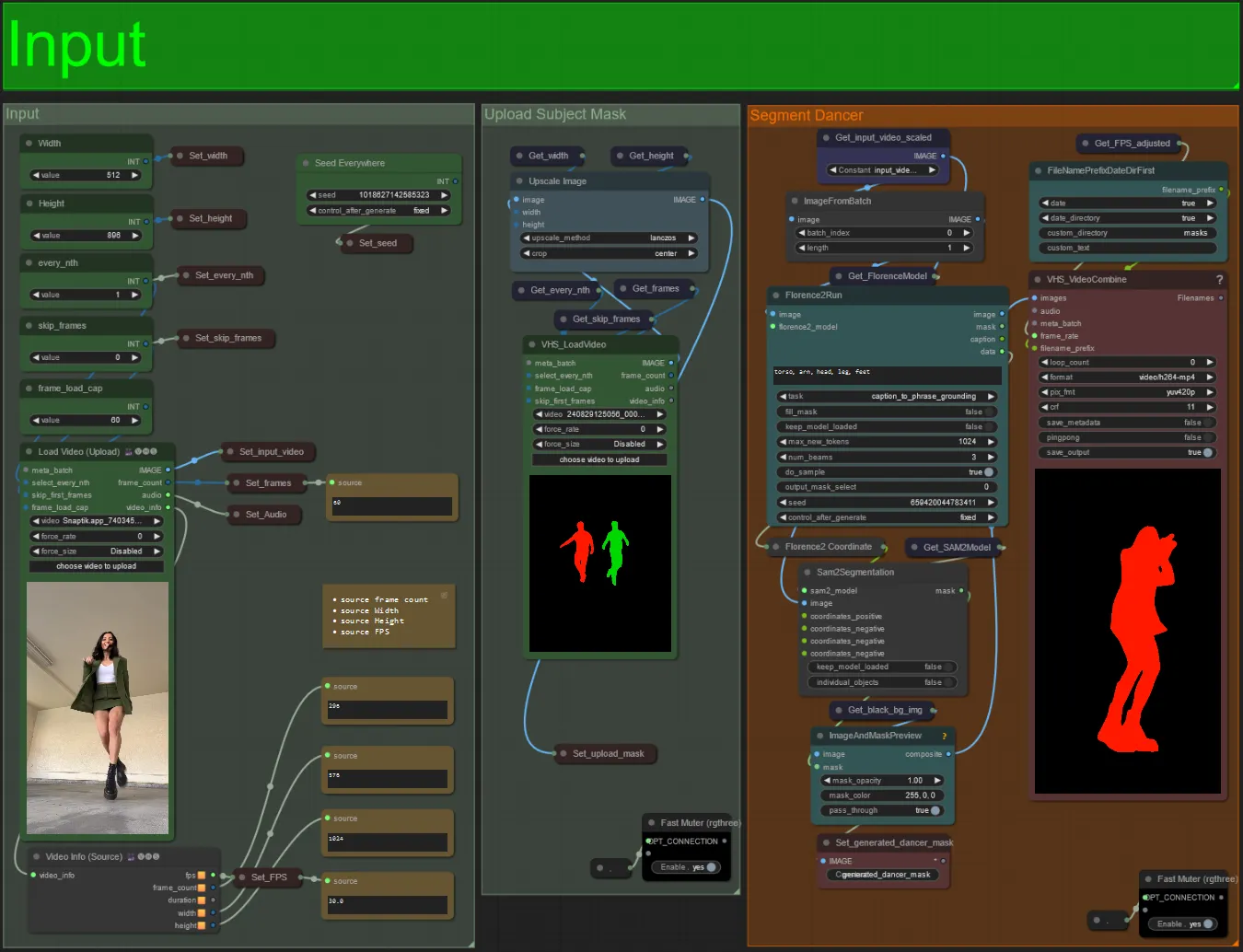
- Carica il video del soggetto desiderato nel nodo Load Video (Upload).
- Puoi regolare la larghezza e l'altezza dell'output utilizzando i due input in alto a sinistra.
- every_nth imposta se utilizzare ogni altro fotogramma, ogni terzo fotogramma e così via (2 = ogni altro fotogramma). Lasciato a 1 per impostazione predefinita.
- skip_frames è usato per saltare fotogrammi all'inizio del video. (100 = salta i primi 100 fotogrammi del video di input). Lasciato a 0 per impostazione predefinita.
- frame_load_cap è usato per specificare quanti fotogrammi totali del video di input devono essere caricati. Meglio tenere basso quando si testano le impostazioni (30 - 60 per esempio) e poi aumentare o impostare a 0 (nessun limite di fotogrammi) quando si rende il video finale.
- I campi numerici in basso a destra mostrano informazioni sul video di input caricato: fotogrammi totali, larghezza, altezza e FPS dall'alto verso il basso.
- Se hai già un video maschera del soggetto generato, puoi disattivare la sezione "Upload Subject Mask" e caricare il video della maschera. Facoltativamente puoi disattivare la sezione "Segment Dancer" per risparmiare un po' di tempo di elaborazione.
- A volte il soggetto segmentato non sarà perfetto, puoi controllare la qualità della maschera usando la casella di anteprima in basso a destra vista sopra. In tal caso puoi giocare con il prompt nel nodo "Florence2Run" per mirare a diverse parti del corpo come "testa", "petto", "gambe", ecc. e vedere se ottieni un risultato migliore.
Prompt
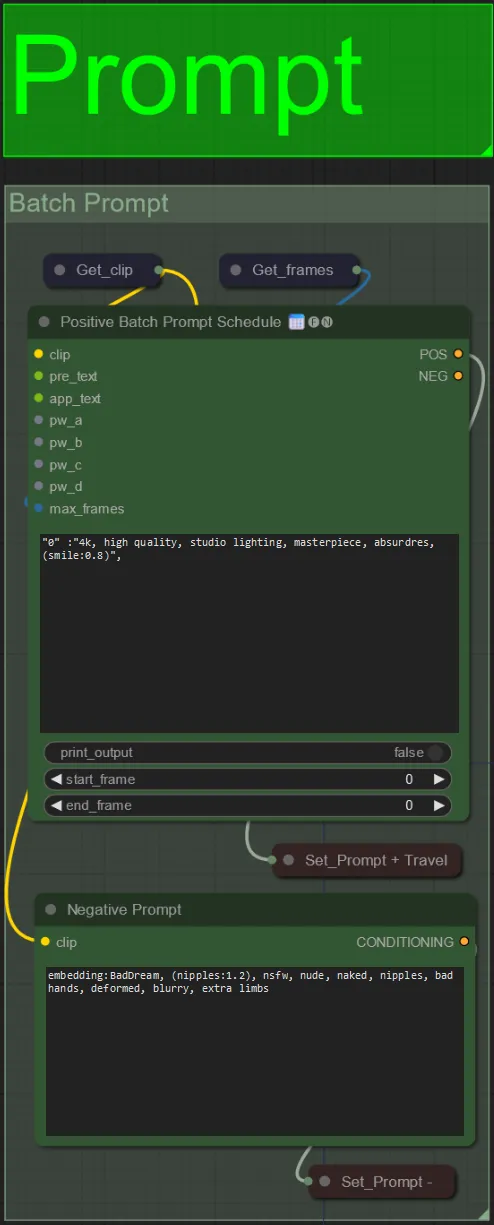
- Imposta il prompt positivo utilizzando la formattazione batch:
- es. "0": "4k, capolavoro, 1 ragazza in piedi sulla spiaggia, absurdres", "25": "HDR, scena del tramonto, 1 ragazza con capelli neri e una giacca bianca, absurdres", …
- Il prompt negativo è in formato normale, puoi aggiungere embeddings se desiderato.
Elaborazione Audio
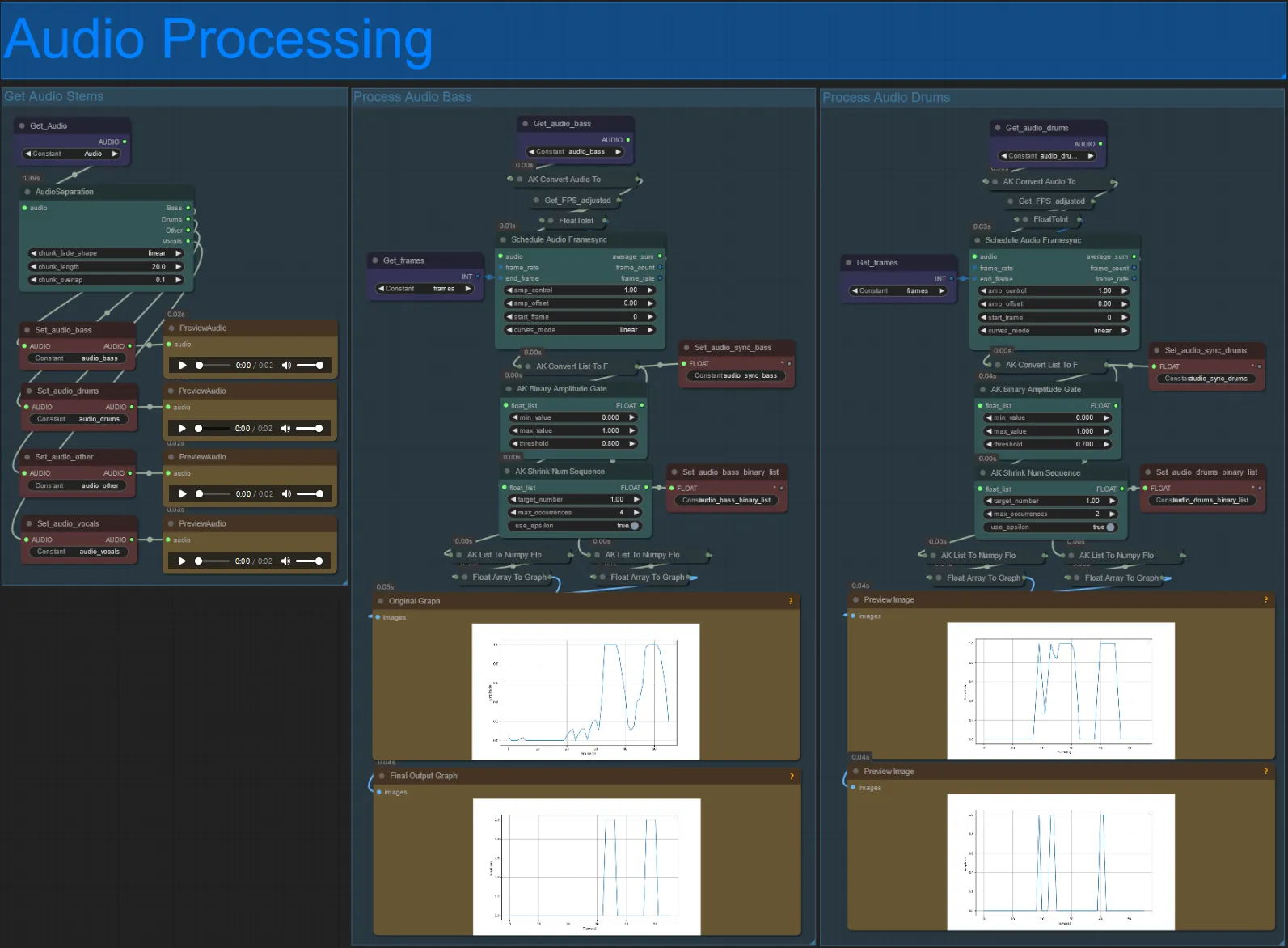
- Questa sezione prende l'audio dal video di input, estrae gli steli (basso, batteria, voci, ecc.) e poi lo converte in un'ampiezza normalizzata sincronizzata con i fotogrammi del video di input, per creare visualizzazioni audioreattive.
- amp_control = gamma totale che l'ampiezza può percorrere.
- amp_offset = il valore minimo che l'ampiezza può assumere.
- Esempio: amp_control = 0.8 e amp_offset = 0.2 significa che il segnale percorrerà tra 0.2 e 1.0.
- A volte lo stelo della Batteria avrà le note di Basso effettive della canzone, visualizza in anteprima ciascuno per vedere quale usare per le tue maschere audioreattive.
- Usa i grafici per ottenere una buona comprensione di come il segnale per quello stelo cambia nel corso del video
Generatori Voronoi
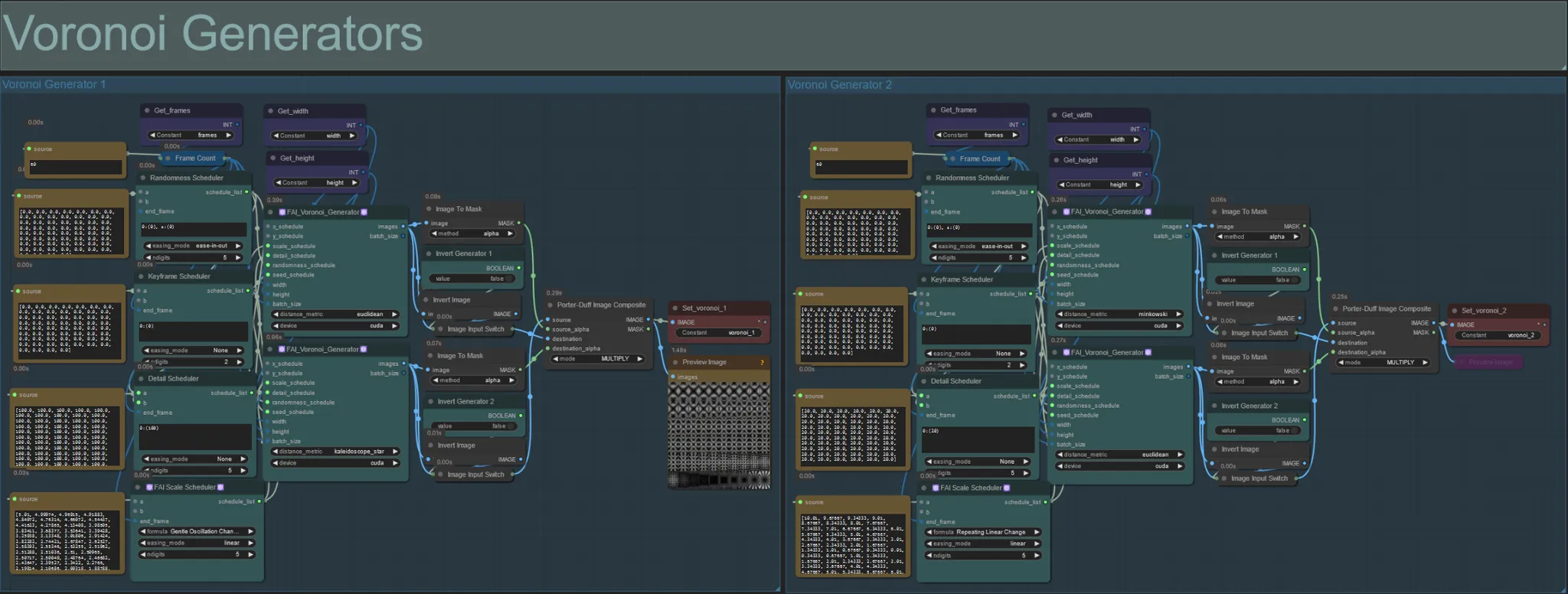
- Questa sezione genera motivi di rumore Voronoi usando due nodi personalizzati FAI_Voronoi_Generator per gruppo che sono composti insieme usando un Multiply.
- Puoi aumentare i valori del Randomness Scheduler tra parentesi da 0 per rompere i motivi simmetrici nell'output finale.
- Aumenta il valore del Detail Scheduler tra parentesi per aumentare il conteggio dei dettagli nei motivi di rumore di output. Valori inferiori risultano in una minore differenziazione del rumore.
- Cambia i parametri "formula" nel nodo FAI Scale Scheduler per avere un grande impatto sul movimento del motivo di rumore finale.
- Puoi anche cambiare la funzione "distance_metric" sui nodi FAI_Voronoi_Generator stessi per influenzare notevolmente i motivi e le forme generate del rumore risultante.
Maschere Audio
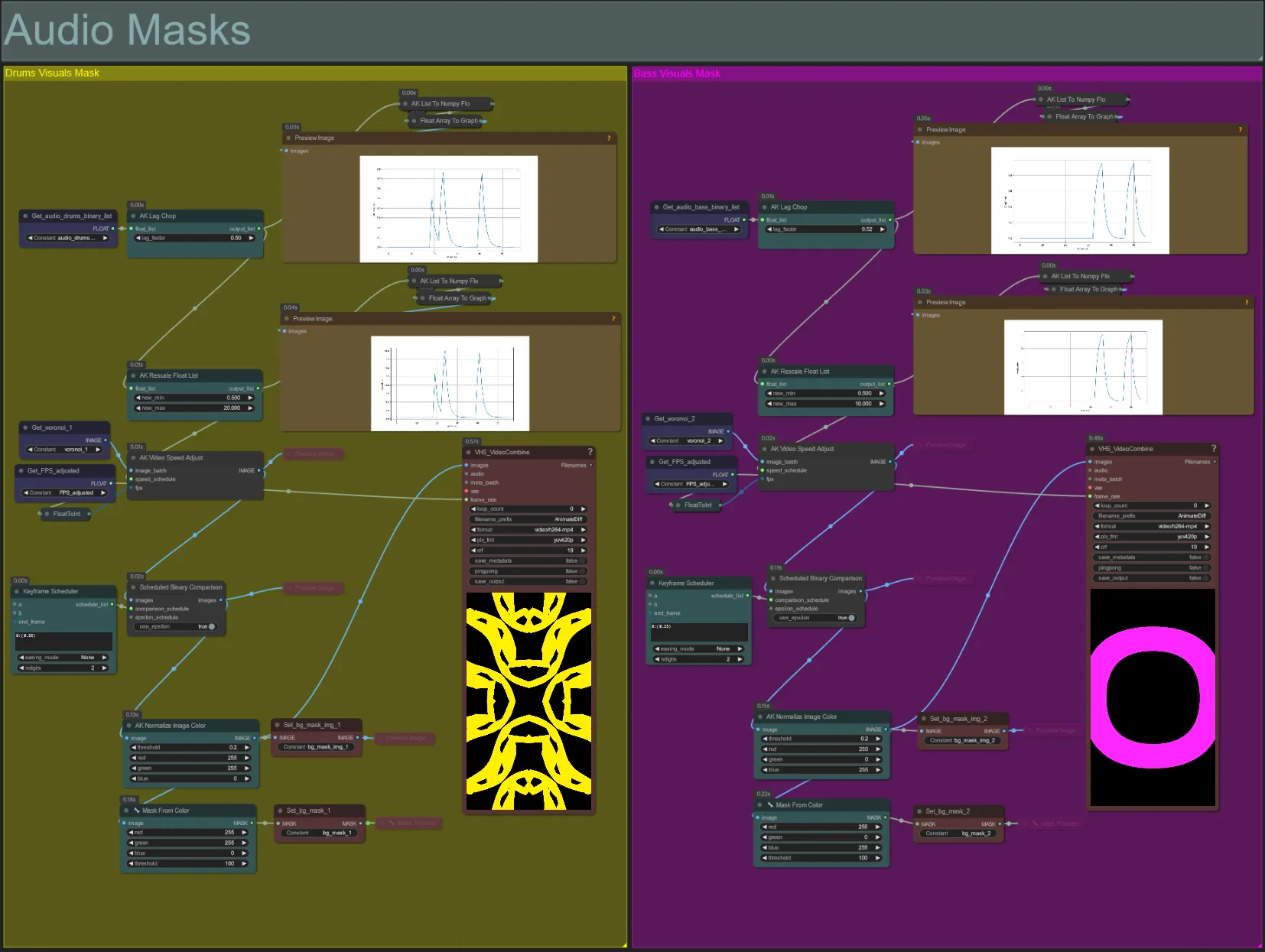
- Questa sezione è usata per convertire i batch di immagini di rumore voronoi in maschere colorate da comporre con il soggetto, oltre a sincronizzare i loro movimenti con il ritmo di uno dei due steli audio bassi o batteria. Queste maschere sono essenziali per creare effetti audioreattivi.
- Aumenta il "lag_factor" nel nodo AK Lag Chop per aumentare quanto saranno "spigolosi" i grafici di ampiezza finali. Ciò farà sì che il movimento del rumore di output acceleri e rallenti più bruscamente, mentre un lag_factor inferiore risulterà in una decelerazione più graduale del movimento dopo ogni battito. Questo è usato per evitare che l'animazione della maschera di rumore appaia troppo "scattante" e rigida.
- L'AK Rescale Float List è usata per rimappare i valori di ampiezza normalizzati da 0-1 a new_min e new_max. Un valore di 1.0 rappresenta una velocità di riproduzione del rumore di animazione di 30FPS, mentre 0.5 rappresenta 15FPS, 2.0 rappresenta 60FPS, ecc. Regola questo valore per cambiare quanto lentamente il motivo di rumore audioreattivo si anima fuori dal ritmo (ampiezza 0.0), e quanto velocemente si muove sul ritmo (ampiezza 1.0).
- Il Keyframe Scheduler ha un grande effetto sull'aspetto della maschera. Crea un elenco di valori in virgola mobile per specificare la soglia dei valori di luminosità dei pixel da usare per le immagini di input di rumore che risulteranno in una parte del rumore che viene ritagliata e trasformata nella maschera finale. Abbassa questo valore per mantenere più del rumore di input, e aumenta per mantenere meno del rumore.
Maschere di Dilatazione
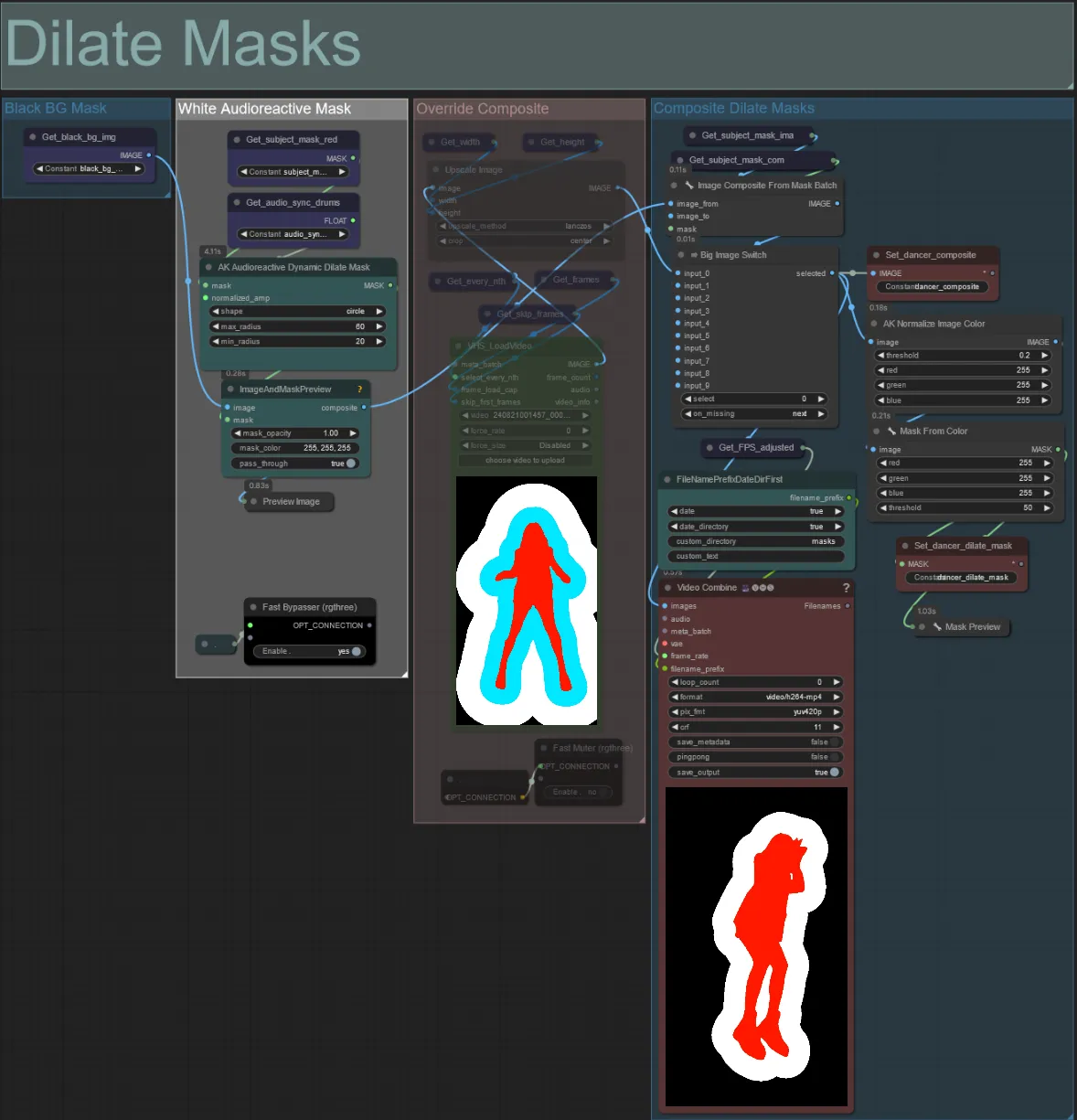
- Ogni gruppo colorato corrisponde al colore della maschera di dilatazione che verrà generata da esso.
- Puoi impostare il raggio minimo e massimo della maschera di dilatazione, così come la forma usando il seguente nodo:
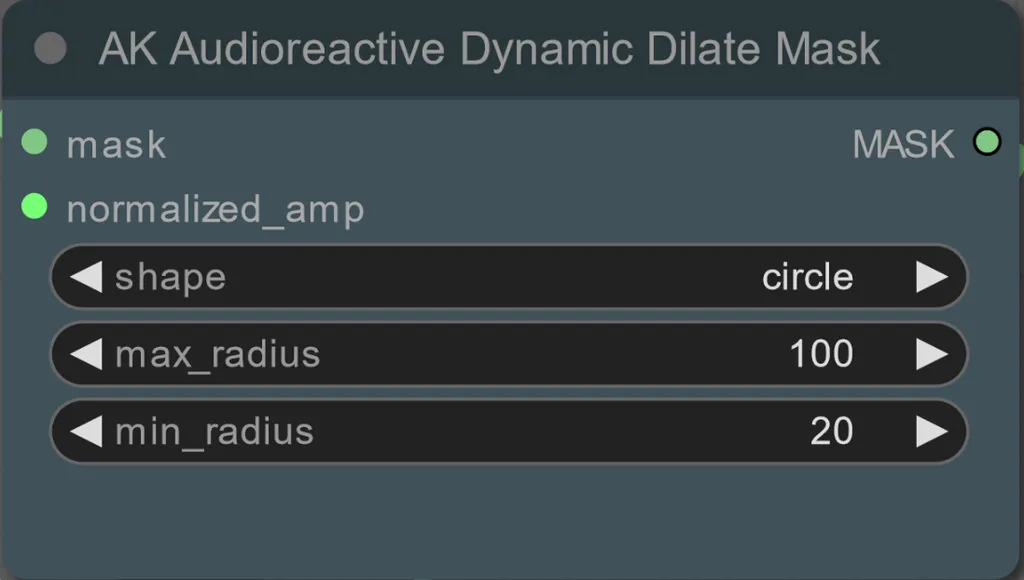
- forma: "circle" è la più accurata ma richiede più tempo per essere generata. Imposta questo quando sei pronto a eseguire il rendering finale. "square" è veloce da calcolare ma meno accurato, migliore per testare il flusso di lavoro e decidere sulle immagini IP adapter.
- max_radius: Il raggio della maschera in pixel quando il valore di ampiezza è massimo (1.0).
- min_radius: Il raggio della maschera in pixel quando il valore di ampiezza è minimo (0.0).
- Se hai già un video maschera composito generato puoi disattivare il gruppo "Override Composite Mask" e caricarlo. È consigliato bypassare i gruppi di maschere di dilatazione se si sovrascrive per risparmiare tempo di elaborazione.
Maschera di Rumore Latente
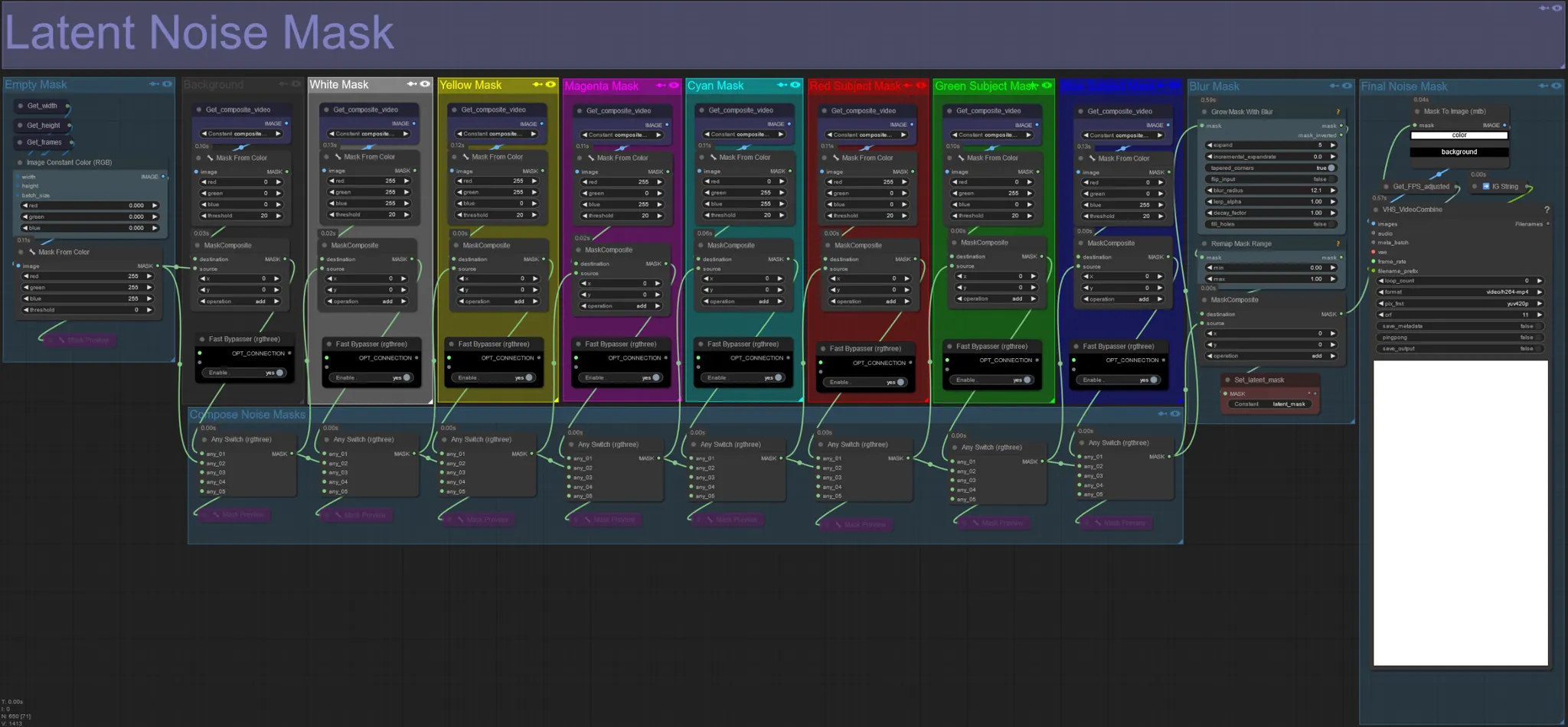
- Usa maschere di rumore latente per controllare quali maschere vengono effettivamente diffuse (sognate) dal ksampler. Bypassa il gruppo corrispondente alla maschera colorata che non vuoi diffondere (cioè vuoi far apparire elementi dal video originale).
- Lasciando abilitati tutti i gruppi di maschere si ottiene una maschera di rumore finale bianca (tutto sarà diffuso).
- Esempio: Bypassa il gruppo Red Subject Mask cliccando sul nodo Fast Bypasser per far apparire il tuo ballerino o soggetto nel risultato finale.
Video di Input Originale:

Bypassando i Gruppi di Maschere Rosso e Giallo:

Maschera Composita
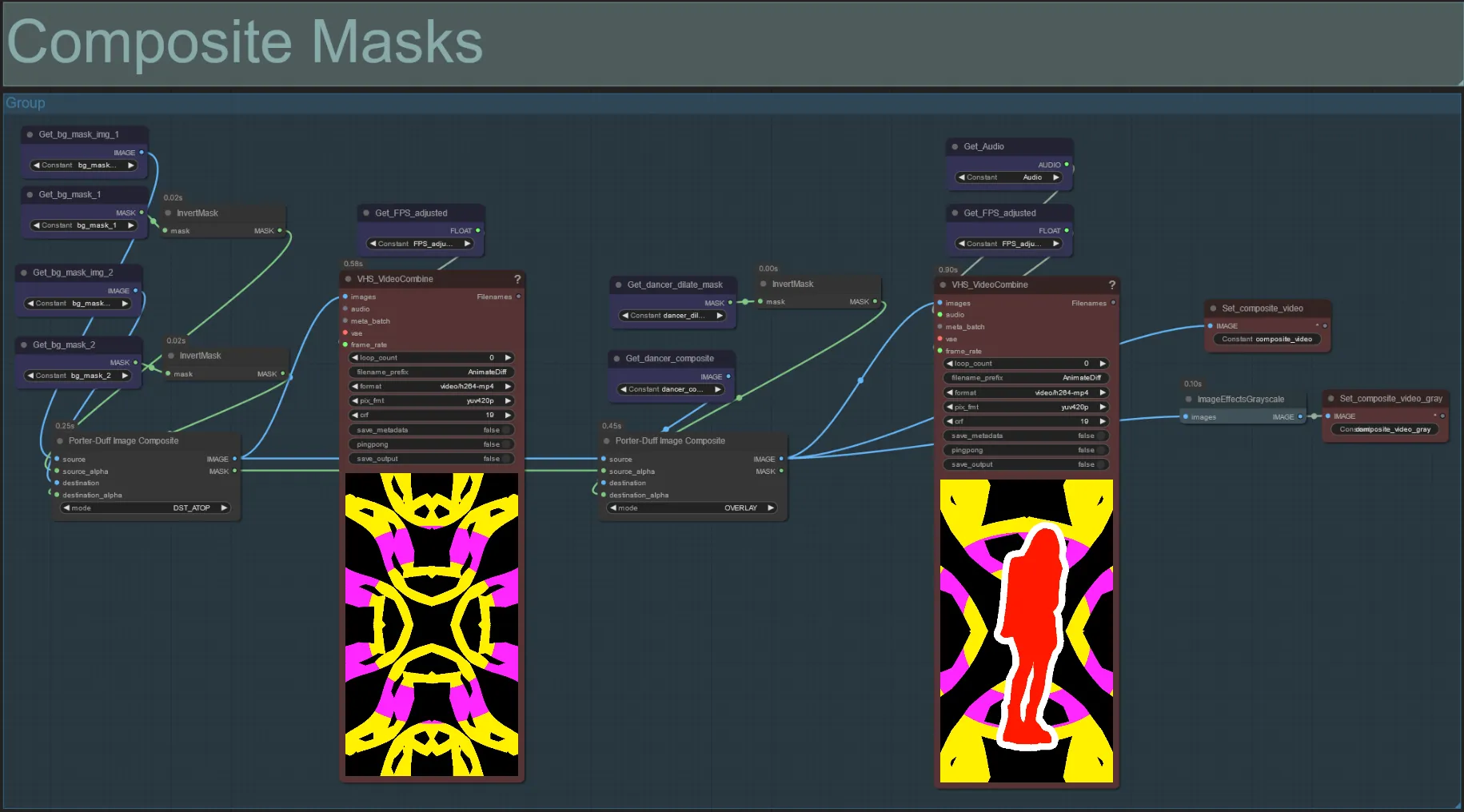
- Questa sezione crea il composito finale delle maschere di rumore voronoi con la maschera del soggetto (e maschera di dilatazione audioreattiva se abilitata).
Modelli
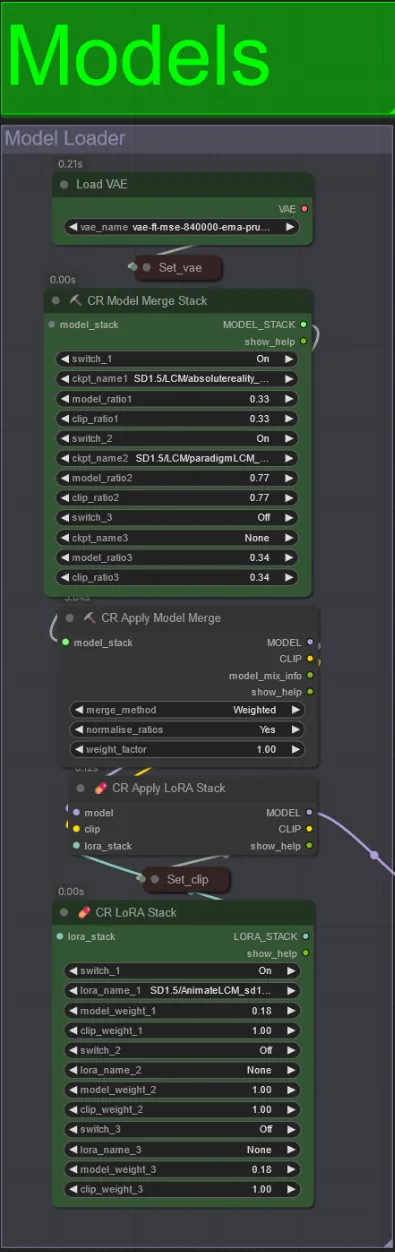
- Usa un buon modello LCM per il checkpoint. Raccomando ParadigmLCM di Machine Delusions.
- Puoi unire più modelli insieme usando lo stack di Merge Model per ottenere vari effetti interessanti. Assicurati che i pesi aggiungano fino a 1.0 per i modelli abilitati.
- Puoi opzionalmente specificare l'AnimateLCM_sd15_t2v_lora.safetensors con un peso basso di 0.18 per migliorare ulteriormente il risultato finale.
- Aggiungi eventuali Loras aggiuntivi al modello usando lo stacker Lora sotto il caricatore del modello.
AnimateDiff

- Puoi impostare un diverso Motion Lora invece di quello che ho usato (LiquidAF-0-1.safetensors)
- Aumenta/diminuisci i float di Scale ed Effect per aumentare/diminuire la quantità di movimento nell'output.
IP Adapters
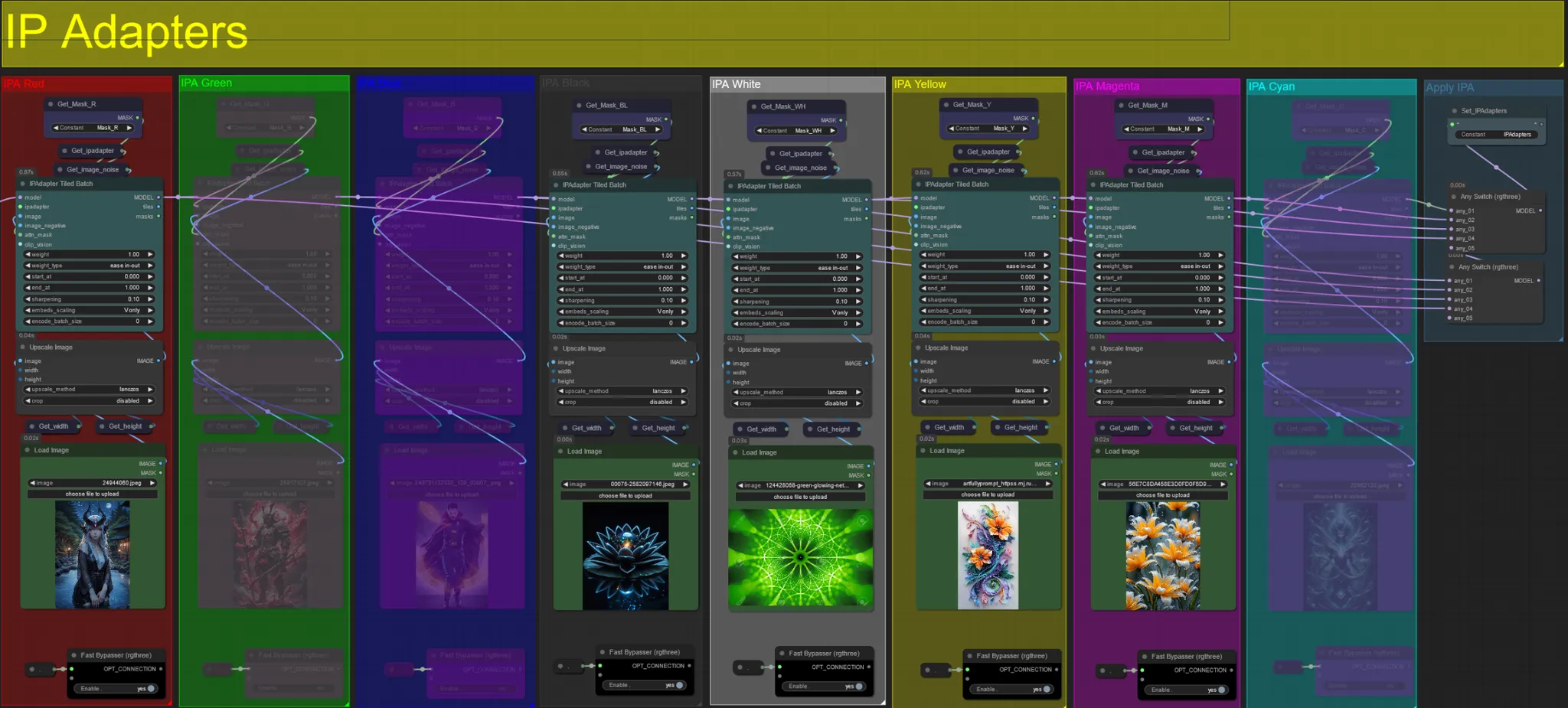
- Qui puoi specificare le immagini di riferimento che verranno utilizzate per rendere gli sfondi di ciascuna delle maschere di dilatazione, così come il tuo soggetto video.
- Il colore di ciascun gruppo rappresenta la maschera che mira:
Rosso, Verde, Blu:
- Immagini di riferimento della maschera del soggetto.
Nero:
- Immagine della maschera di sfondo, carica un'immagine di riferimento per lo sfondo.
Bianco:
- Immagini di riferimento della maschera di dilatazione, carica un'immagine di riferimento per ciascuna maschera di dilatazione di colore in uso.
Giallo, Magenta
- Immagini di riferimento della maschera di rumore voronoi.
ControlNet
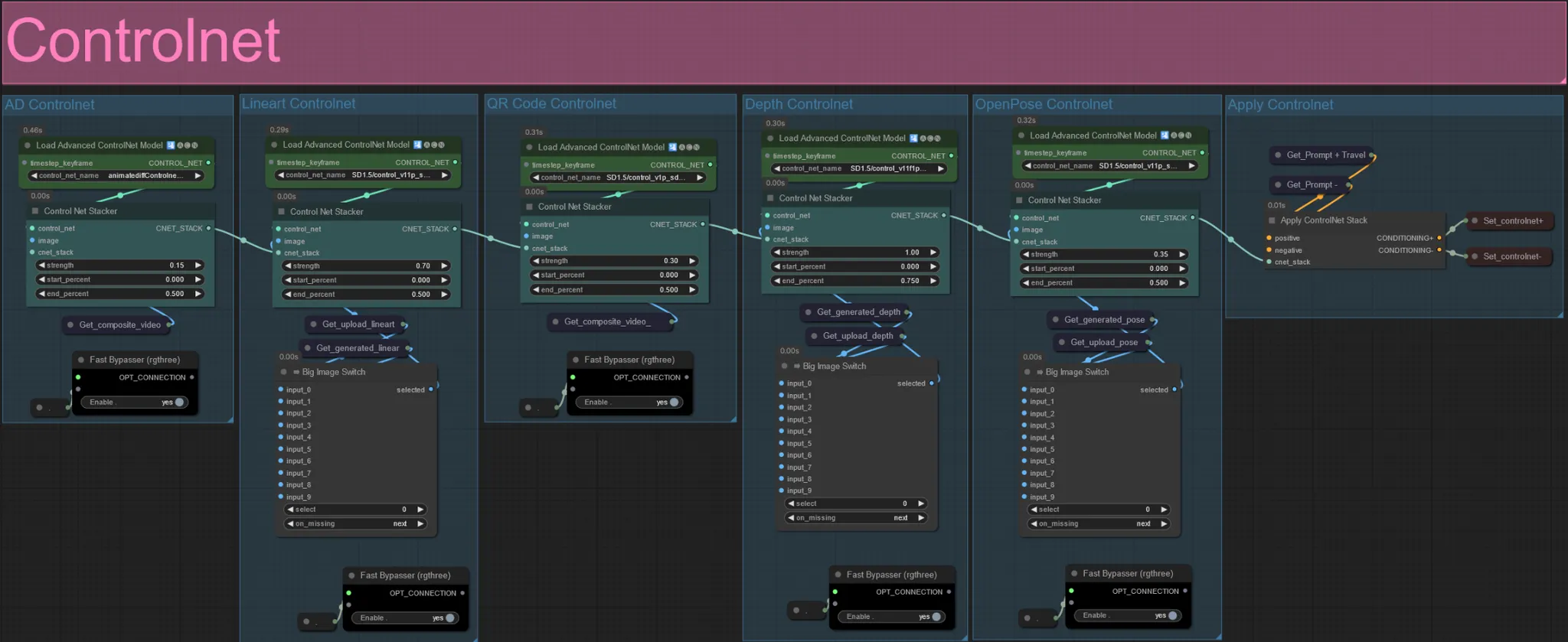
- Questo flusso di lavoro fa uso di 5 diversi controlnet, inclusi AD, Lineart, QR Code, Depth e OpenPose.
- Tutti gli input ai controlnet vengono generati automaticamente
- Puoi scegliere di sovrascrivere il video di input per i controlnet Lineart, Depth e Openpose se desiderato disattivando i gruppi "Override" come visto sotto:
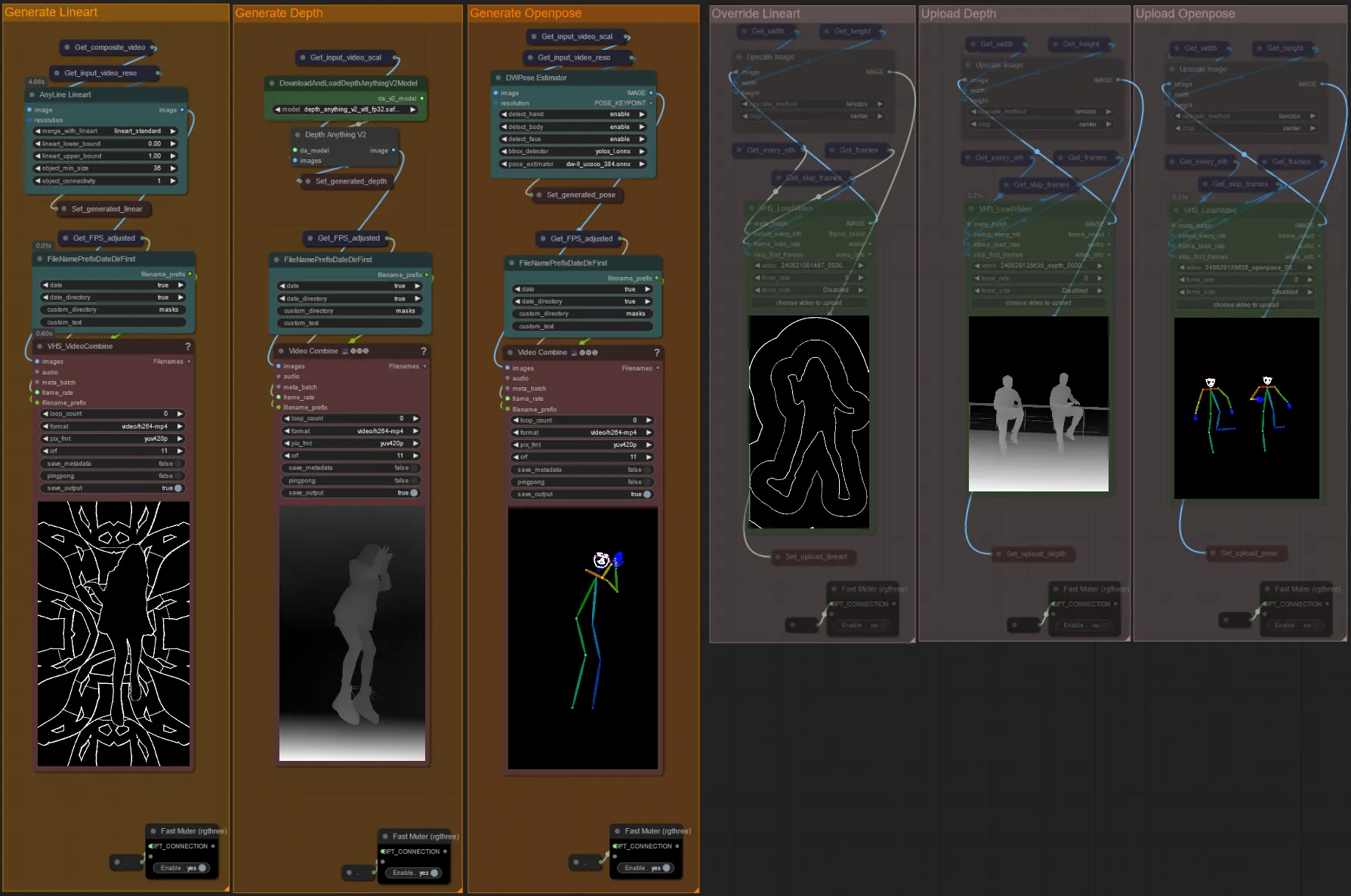
- È consigliato disattivare anche i gruppi "Generate" se si sovrascrive per risparmiare tempo di elaborazione.
Suggerimento:
- Bypassa il Ksampler e inizia un rendering con il tuo video di input completo. Una volta generati tutti i video preprocessor salvali e caricali nelle rispettive sovrascritture. D'ora in poi, quando testi il flusso di lavoro, non dovrai aspettare che ciascun video preprocessor venga generato individualmente.
Sampler
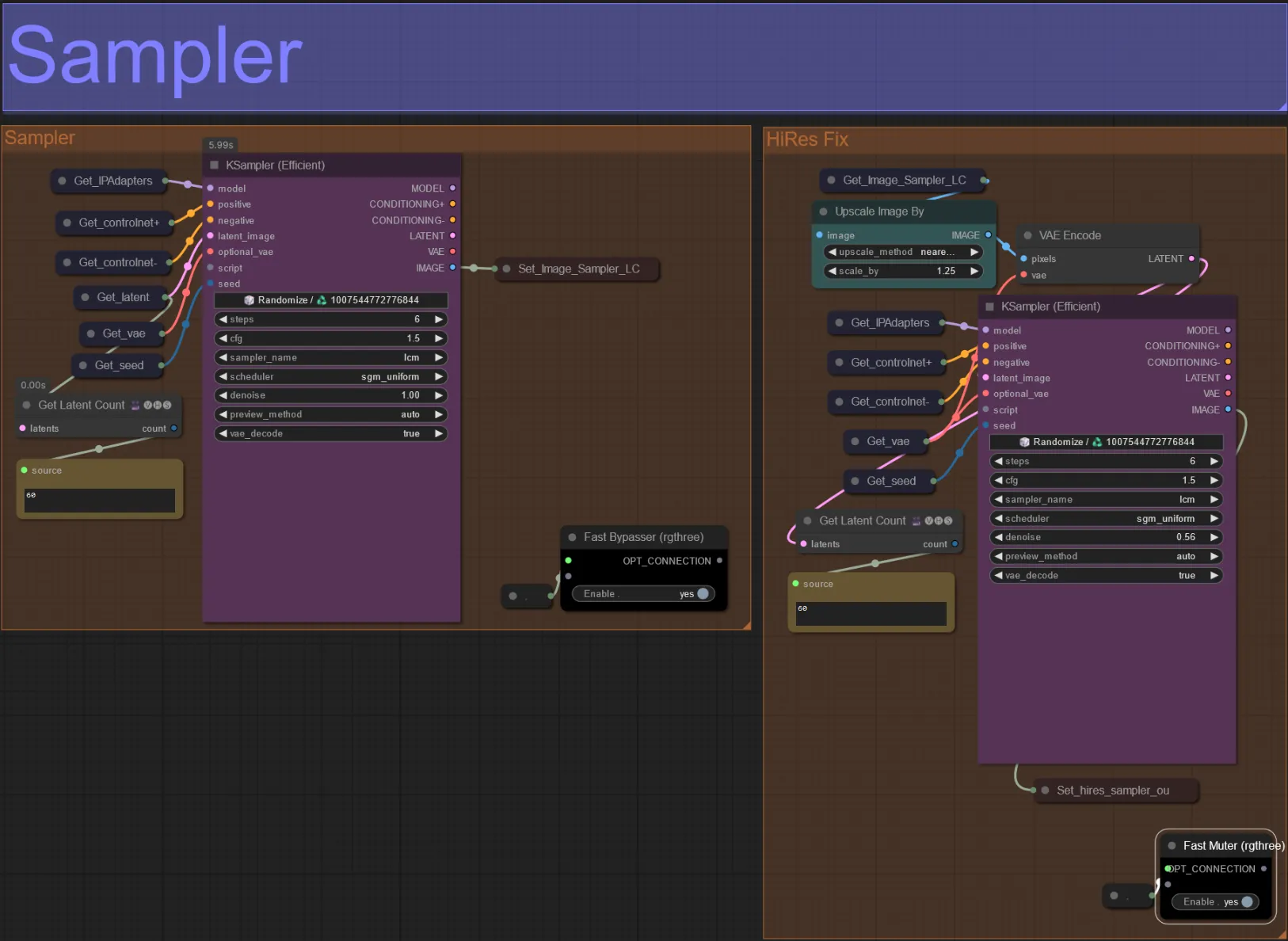
- Per impostazione predefinita il gruppo HiRes Fix sampler sarà disattivato per risparmiare tempo di elaborazione quando si testano
- Consiglio di bypassare anche il gruppo Sampler quando si cerca di sperimentare con le impostazioni della maschera di dilatazione per risparmiare tempo.
- Nei rendering finali puoi disattivare il gruppo HiRes Fix che scalerà e aggiungerà dettagli al risultato finale.
Output
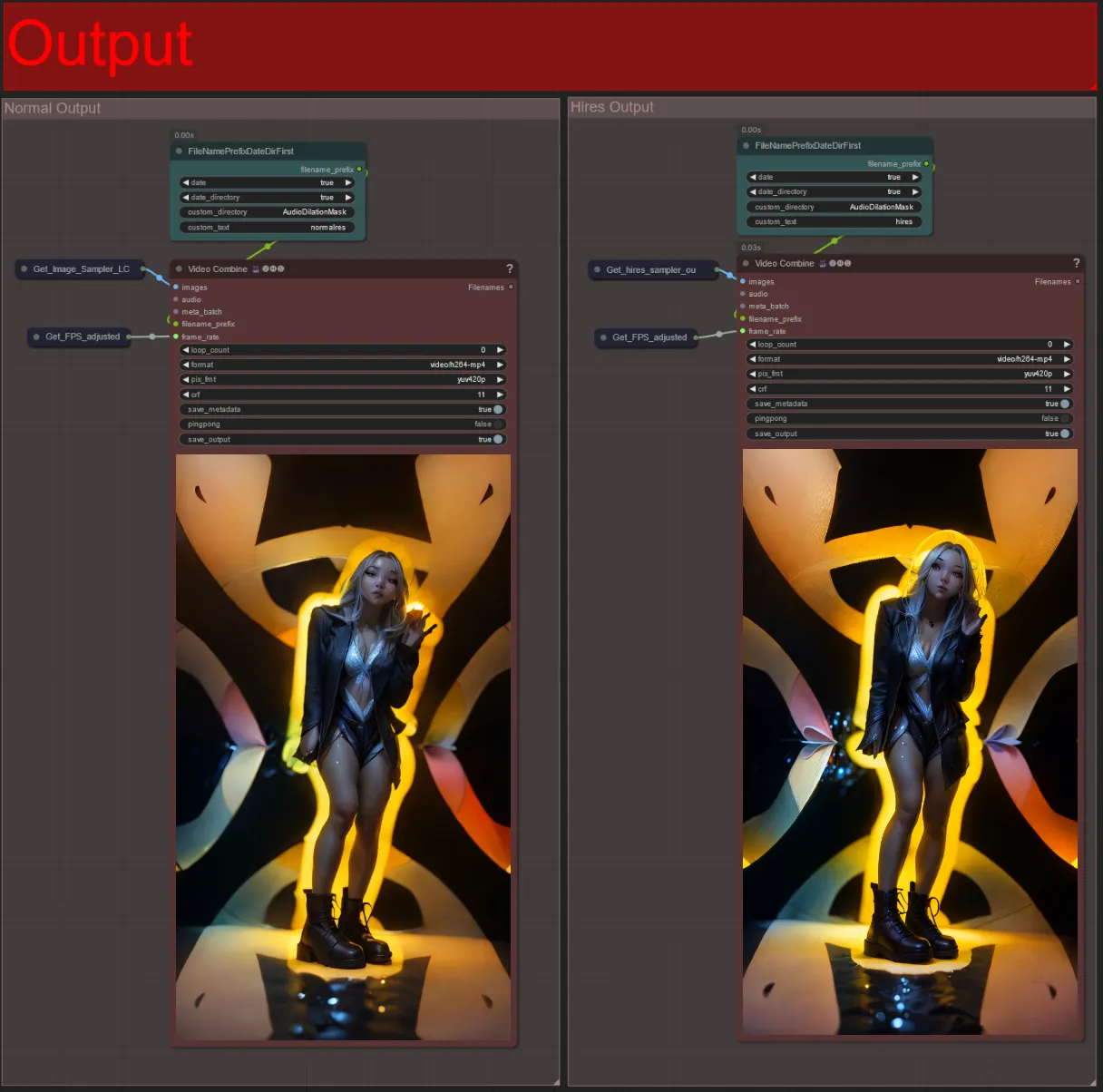
- Ci sono due gruppi di output: a sinistra è per l'output standard del sampler, e a destra è per l'output del HiRes Fix sampler.
- Puoi cambiare dove verranno salvati i file modificando la stringa "custom_directory" nei nodi "FileNamePrefixDateDirFirst". Per impostazione predefinita questo nodo salverà i video di output in una directory con timestamp nella directory "output" di ComfyUI
- es.
…/ComfyUI/output/240812/<custom_directory>/<my_video>.mp4
- es.
Creare un video audioreattivo può aggiungere un'energia pulsante e immersiva al tuo soggetto, con ogni fotogramma che risponde al ritmo in tempo reale. Quindi, immergiti nel mondo dell'arte audioreattiva e goditi le trasformazioni guidate dal ritmo!
Informazioni sull'Autore
Akatz AI:
- Sito web:
Contatti:
- Email: akatzfey@sendysoftware.com
