Audioreactive Mask Dilation | Animazioni Straordinarie
Questo flusso di lavoro Audioreactive Mask Dilation di ComfyUI ti consente di trasformare creativamente i soggetti dei tuoi video. Ti permette di avvolgere i tuoi soggetti, sia che si tratti di un individuo o di un gruppo di performer, con un'aura dinamica e reattiva che si espande e si contrae in perfetta sincronizzazione con il ritmo della musica. Questo effetto aggiunge una dimensione visiva affascinante ai tuoi video, migliorandone l'impatto complessivo e il coinvolgimento.ComfyUI Audioreactive Mask Dilation Flusso di lavoro

Vuoi eseguire questo workflow?
- Workflow completamente operativi
- Nessun nodo o modello mancante
- Nessuna configurazione manuale richiesta
- Presenta visuali mozzafiato
ComfyUI Audioreactive Mask Dilation Esempi
ComfyUI Audioreactive Mask Dilation Descrizione
Crea animazioni video straordinarie trasformando il tuo soggetto (ad esempio, un ballerino) con un'aura dinamica che si espande e si contrae ritmicamente in sincronizzazione con il battito. Usa questo flusso di lavoro con soggetti singoli o multipli come mostrato negli esempi.
Come usare il flusso di lavoro Audioreactive Mask Dilation:
- Carica un video del soggetto nella sezione Input
- Seleziona la larghezza e l'altezza desiderate per il video finale, insieme a quanti fotogrammi del video di input devono essere saltati con 'every_nth'. Puoi anche limitare il numero totale di fotogrammi da rendere con 'frame_load_cap'.
- Compila il prompt positivo e negativo. Imposta i tempi dei batch frame per corrispondere a quando desideri che avvengano le transizioni di scena.
- Carica immagini per ciascuno dei colori della maschera del soggetto IP Adapter predefiniti:
- Rosso = soggetto (ballerino)
- Nero = Sfondo
- Bianco = Maschera di dilatazione audioreattiva bianca
- Carica un buon checkpoint LCM (io uso ParadigmLCM di Machine Delusions) nella sezione 'Models'.
- Aggiungi eventuali loras utilizzando lo stacker Lora sotto il caricatore del modello
- Premi Queue Prompt
Input
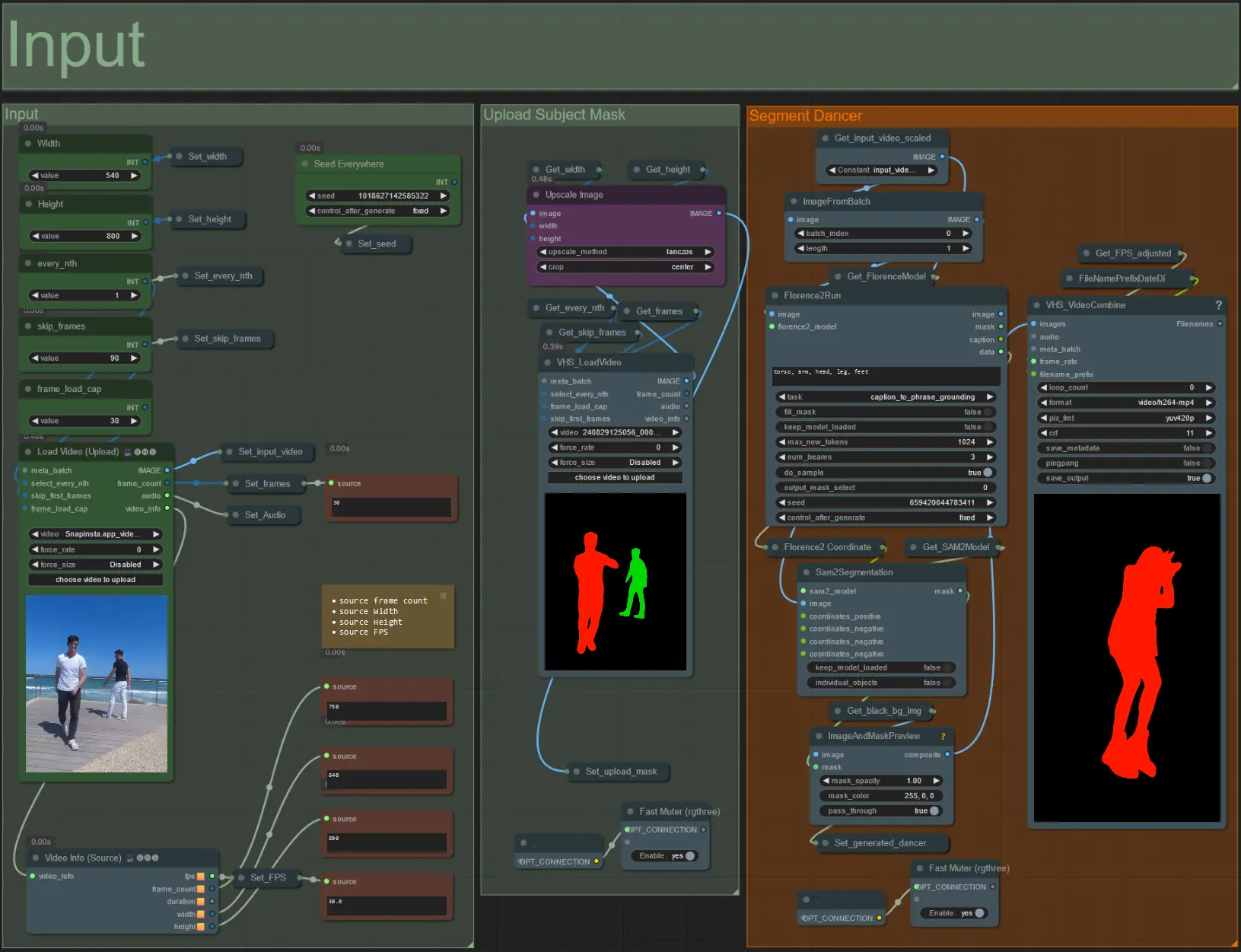
- Carica il video del soggetto desiderato nel nodo Load Video (Upload).
- Regola la larghezza e l'altezza di output utilizzando i due input in alto a sinistra.
- every_nth imposta se utilizzare ogni altro fotogramma, ogni terzo fotogramma e così via (2 = ogni altro fotogramma). Lasciato a 1 per impostazione predefinita.
- skip_frames viene utilizzato per saltare i fotogrammi all'inizio del video. (100 = salta i primi 100 fotogrammi del video di input). Lasciato a 0 per impostazione predefinita.
- frame_load_cap viene utilizzato per specificare quanti fotogrammi totali del video di input devono essere caricati. Meglio tenere basso quando si testano le impostazioni (30 - 60 ad esempio) e poi aumentare o impostare a 0 (nessun limite di fotogrammi) quando si rende il video finale.
- I campi numerici in basso a destra mostrano informazioni sul video di input caricato: fotogrammi totali, larghezza, altezza e FPS dall'alto verso il basso.
- Se hai già un video maschera del soggetto generato, disattiva la sezione 'Upload Subject Mask' e carica il video maschera. Facoltativamente disattiva la sezione 'Segment Dancer' per risparmiare tempo di elaborazione.
- A volte il soggetto segmentato non sarà perfetto, quindi controlla la qualità della maschera utilizzando la casella di anteprima in basso a destra vista sopra. Se è così, puoi giocare con il prompt nel nodo 'Florence2Run' per mirare a diverse parti del corpo come 'testa', 'petto', 'gambe', ecc. e vedere se ottieni un risultato migliore.
Prompt
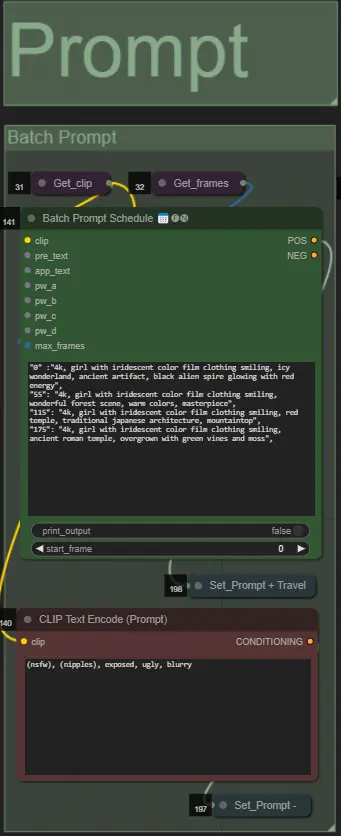
- Imposta il prompt positivo utilizzando la formattazione batch:
- es. '0': '4k, masterpiece, 1girl standing on the beach, absurdres', '25': 'HDR, sunset scene, 1girl with black hair and a white jacket, absurdres', …
- Il prompt negativo è in formato normale, aggiungi embeddings se desiderato.
Elaborazione Audio
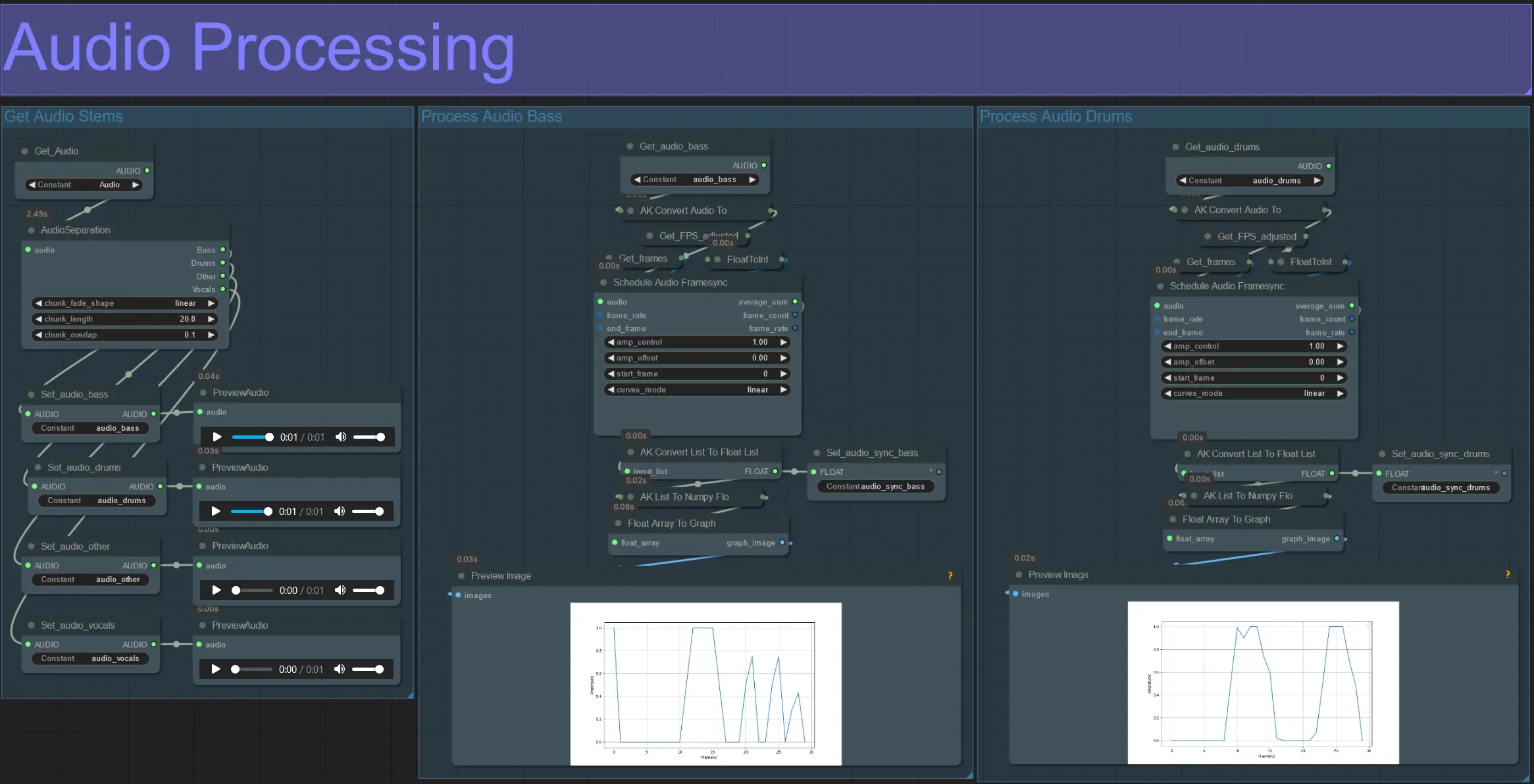
- Questa sezione prende l'audio dal video di input, estrae gli steli (basso, batteria, voce, ecc.) e poi lo converte in un'ampiezza normalizzata sincronizzata con i fotogrammi del video di input.
- amp_control = intervallo totale che l'ampiezza può percorrere.
- amp_offset = il valore minimo che l'ampiezza può assumere.
- Esempio: amp_control = 0.8 e amp_offset = 0.2 significano che il segnale viaggerà tra 0.2 e 1.0.
- A volte lo stelo Drums contiene le note effettive del basso della canzone; anteprima ciascuno per determinare quale è migliore per le tue maschere.
- Usa i grafici per ottenere una chiara comprensione di come il segnale per quello stelo cambia durante la durata del video.
Dilata Maschere
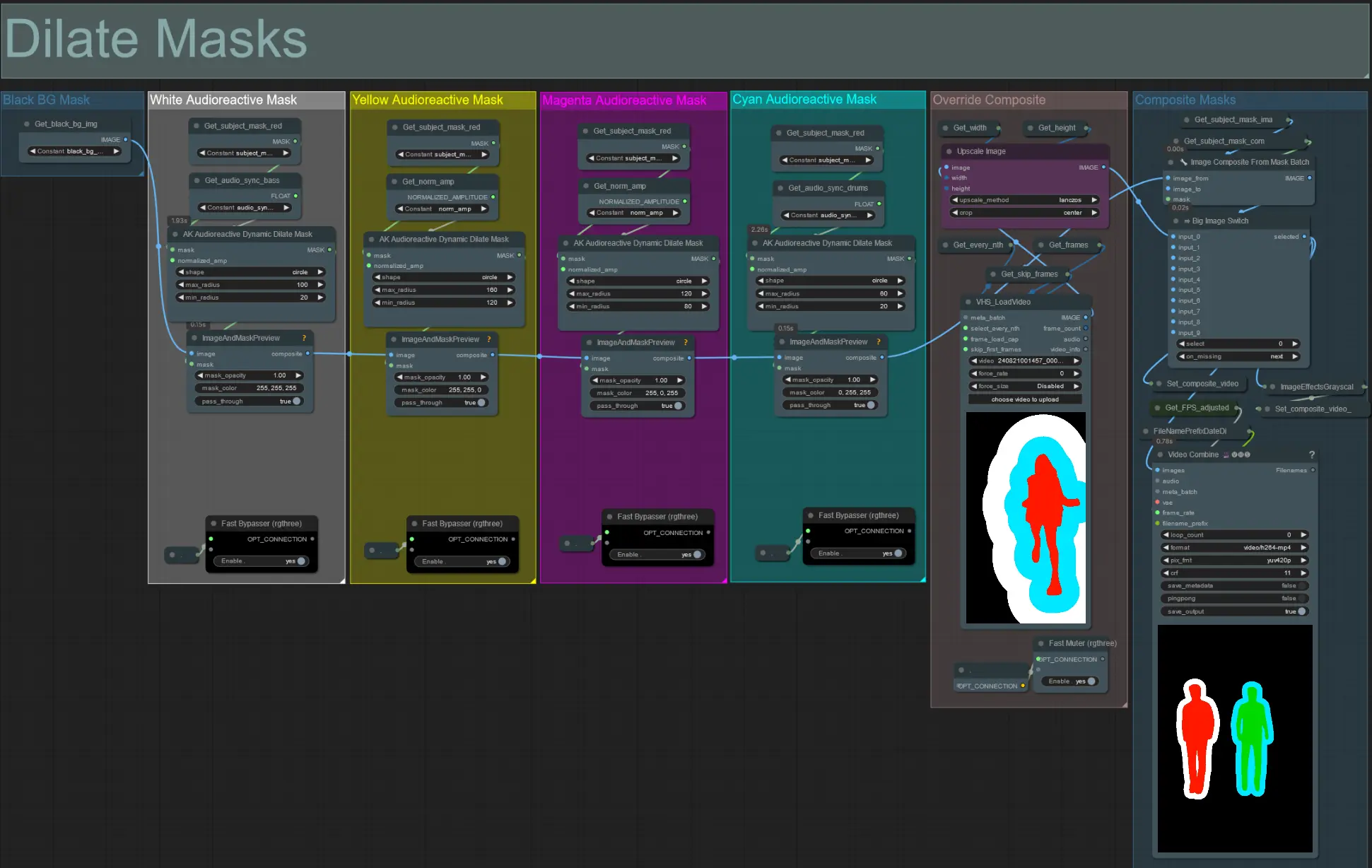
- Ogni gruppo colorato corrisponde al colore della maschera di dilatazione che verrà generata da esso.
- Imposta il raggio minimo e massimo per la maschera di dilatazione, insieme alla sua forma, utilizzando il seguente nodo:
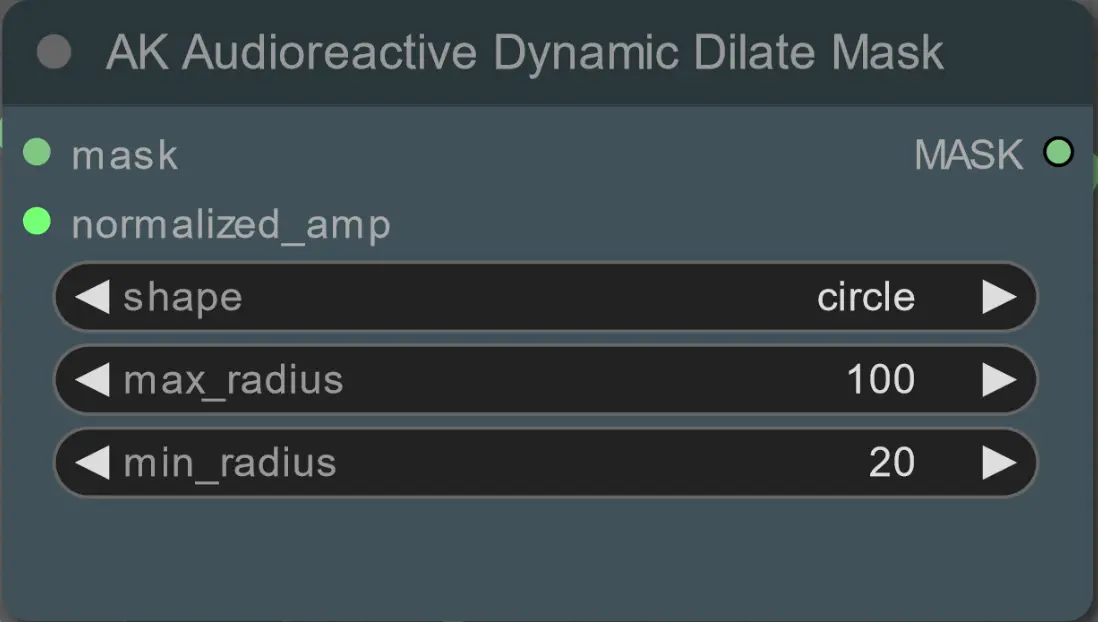
- forma: 'circle' è la più accurata ma richiede più tempo per essere generata. Imposta questa quando sei pronto per eseguire il rendering finale. 'square' è veloce da calcolare ma meno accurata, migliore per testare il flusso di lavoro e decidere sulle immagini IP adapter.
- max_radius: Il raggio della maschera in pixel quando il valore dell'ampiezza è massimo (1.0).
- min_radius: Il raggio della maschera in pixel quando il valore dell'ampiezza è minimo (0.0).
- Se hai già un video maschera composito generato puoi disattivare il gruppo 'Override Composite Mask' e caricarlo. Si consiglia di bypassare i gruppi di maschere di dilatazione se si esegue l'override per risparmiare tempo di elaborazione.
Modelli
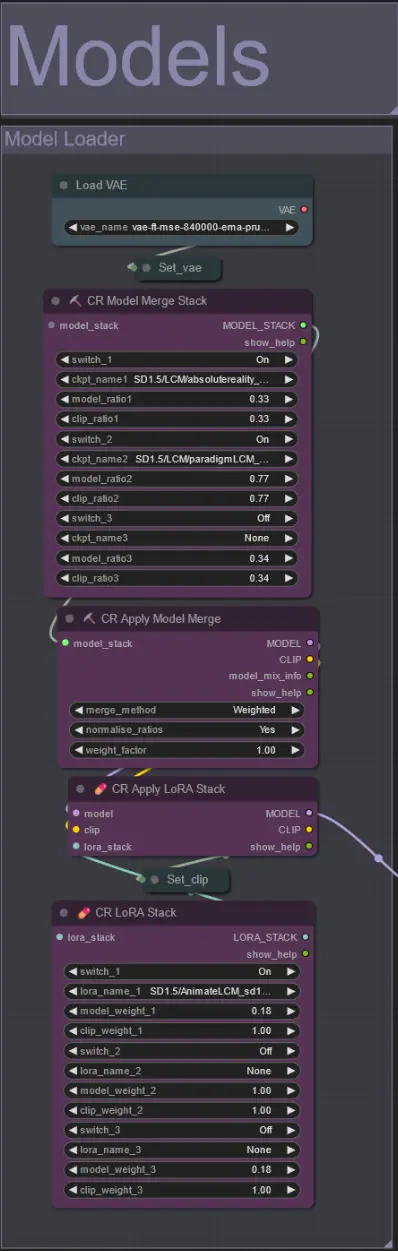
- Usa un buon modello LCM per il checkpoint. Raccomando ParadigmLCM di Machine Delusions.
- Unisci più modelli insieme usando lo stack di fusione del modello per ottenere vari effetti interessanti. Assicurati che i pesi sommino a 1.0 per i modelli abilitati.
- Facoltativamente specifica l'AnimateLCM_sd15_t2v_lora.safetensors con un peso basso di 0.18 per migliorare ulteriormente il risultato finale.
- Aggiungi eventuali loras aggiuntivi al modello utilizzando lo stacker Lora sotto il caricatore del modello.
AnimateDiff

- Imposta un diverso Motion Lora invece di quello che ho usato (LiquidAF-0-1.safetensors)
- Aumenta/diminuisci le scale e gli effetti per aumentare/diminuire la quantità di movimento nel risultato finale.
IP Adapters
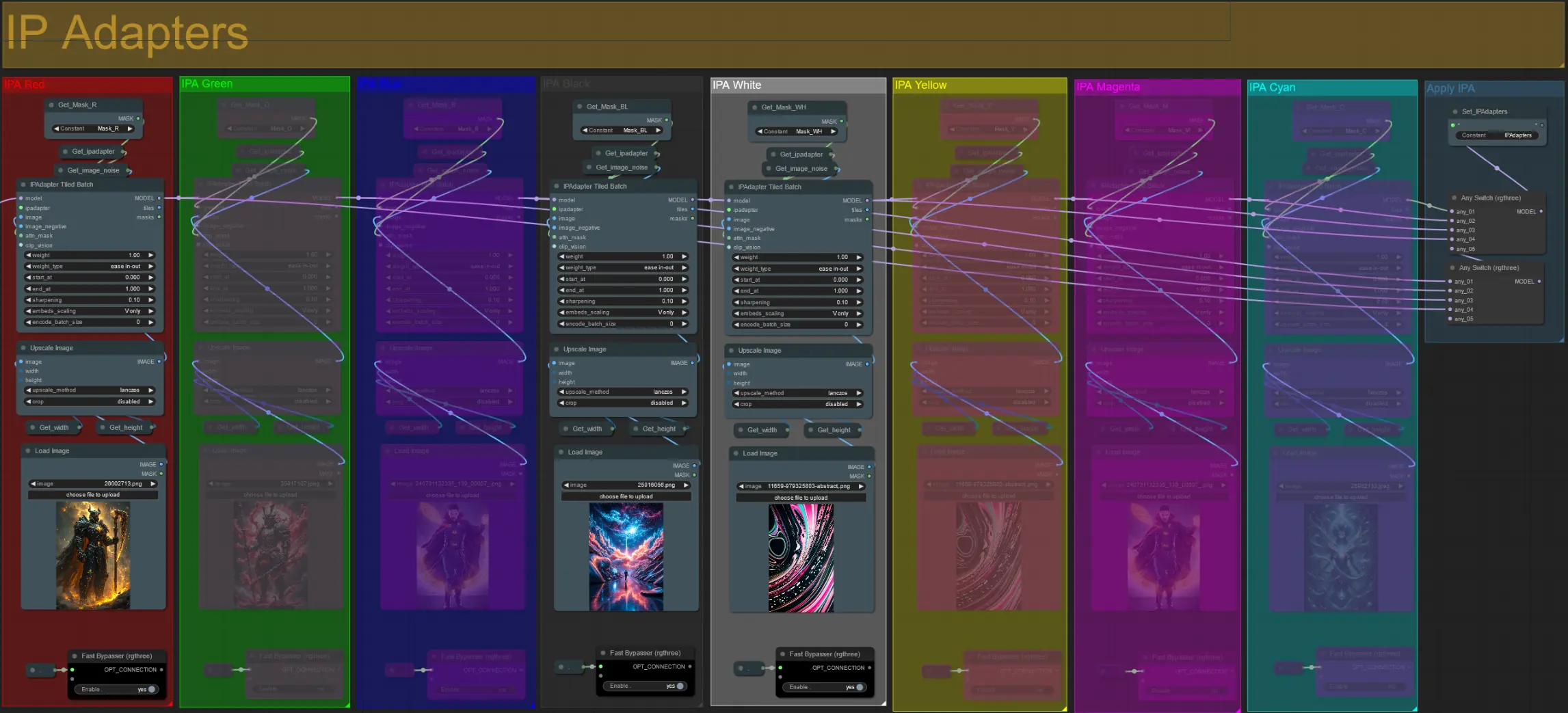
- Qui puoi specificare le immagini di riferimento che verranno utilizzate per rendere gli sfondi per ciascuna delle maschere di dilatazione, nonché i tuoi soggetti video.
- Il colore di ciascun gruppo rappresenta la maschera che mira:
Rosso, Verde, Blu:
- Immagini di riferimento della maschera del soggetto.
Nero:
- Immagine di riferimento della maschera di sfondo, carica un'immagine di riferimento per lo sfondo.
Bianco, Giallo, Magenta, Ciano:
- Immagini di riferimento della maschera di dilatazione, carica un'immagine di riferimento per ciascun colore della maschera di dilatazione in uso.
ControlNet
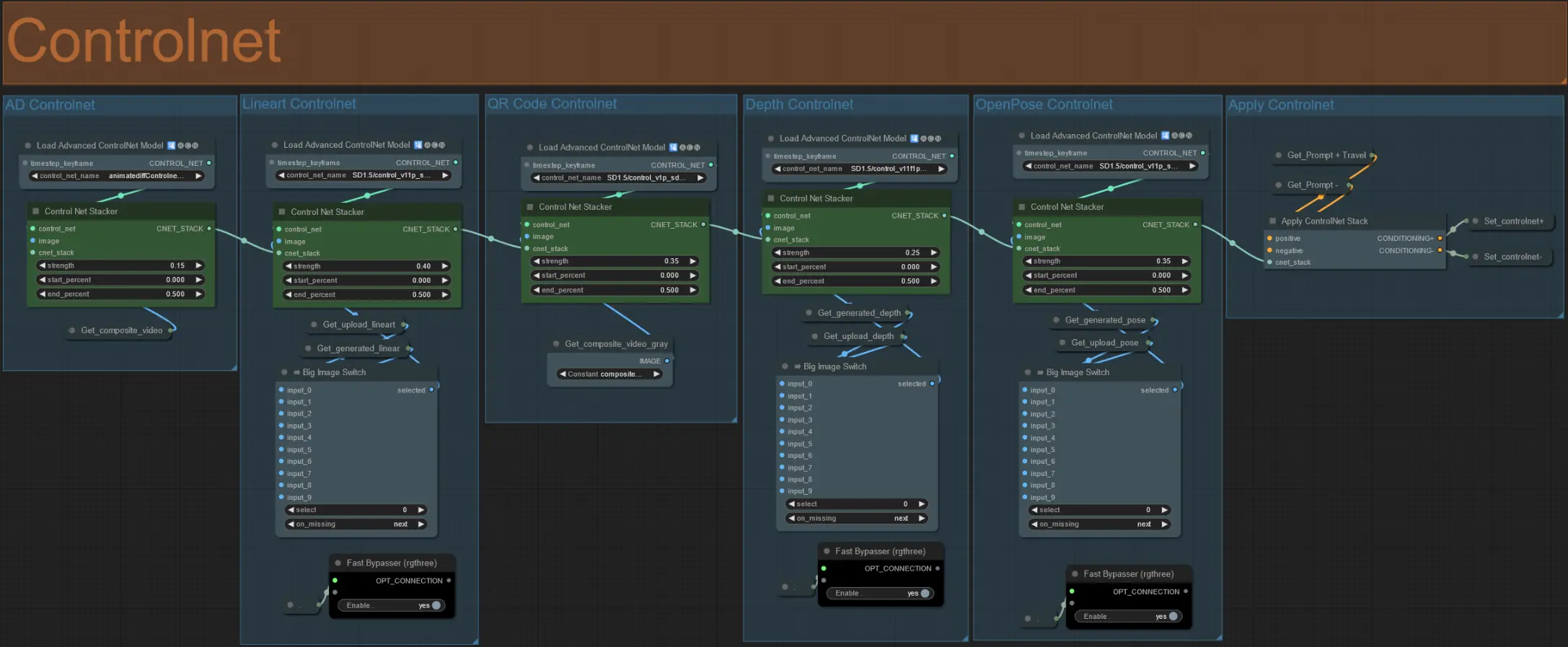
- Questo flusso di lavoro utilizza 5 diversi controlnets, inclusi AD, Lineart, QR Code, Depth e OpenPose.
- Tutti gli input ai controlnets sono generati automaticamente
- Puoi scegliere di sostituire il video di input per i controlnets Lineart, Depth e Openpose se desiderato disattivando i gruppi 'Override' come visto sotto:
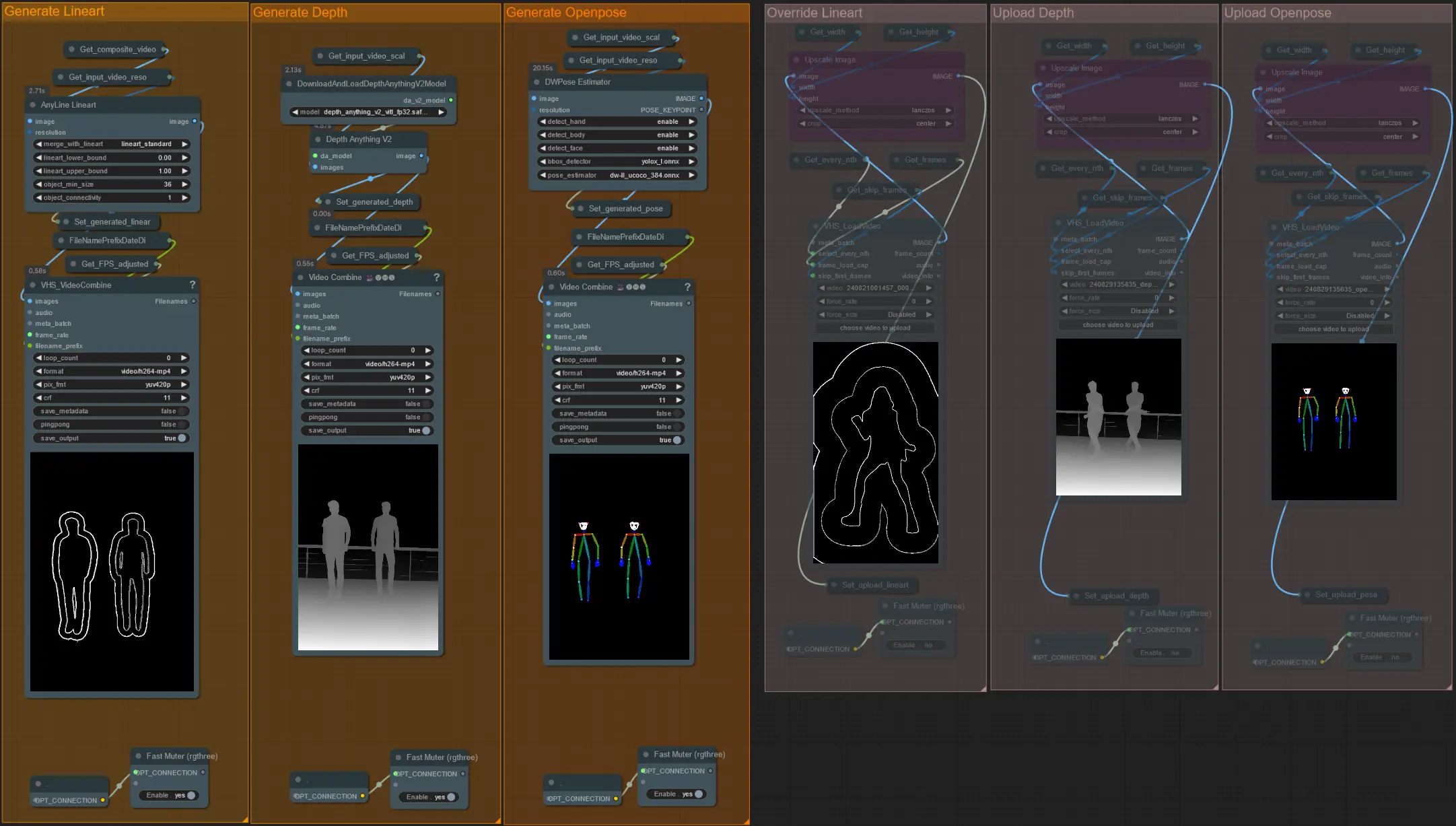
- Si consiglia inoltre di disattivare i gruppi 'Generate' se si esegue l'override per risparmiare tempo di elaborazione.
Consiglio:
- Bypassa il Ksampler e inizia un rendering con il tuo video di input completo. Una volta generati tutti i video preprocessor, salvali e caricali nei rispettivi override. Da ora in poi, quando testi il flusso di lavoro, non dovrai aspettare che ciascun video preprocessor venga generato individualmente.
Sampler
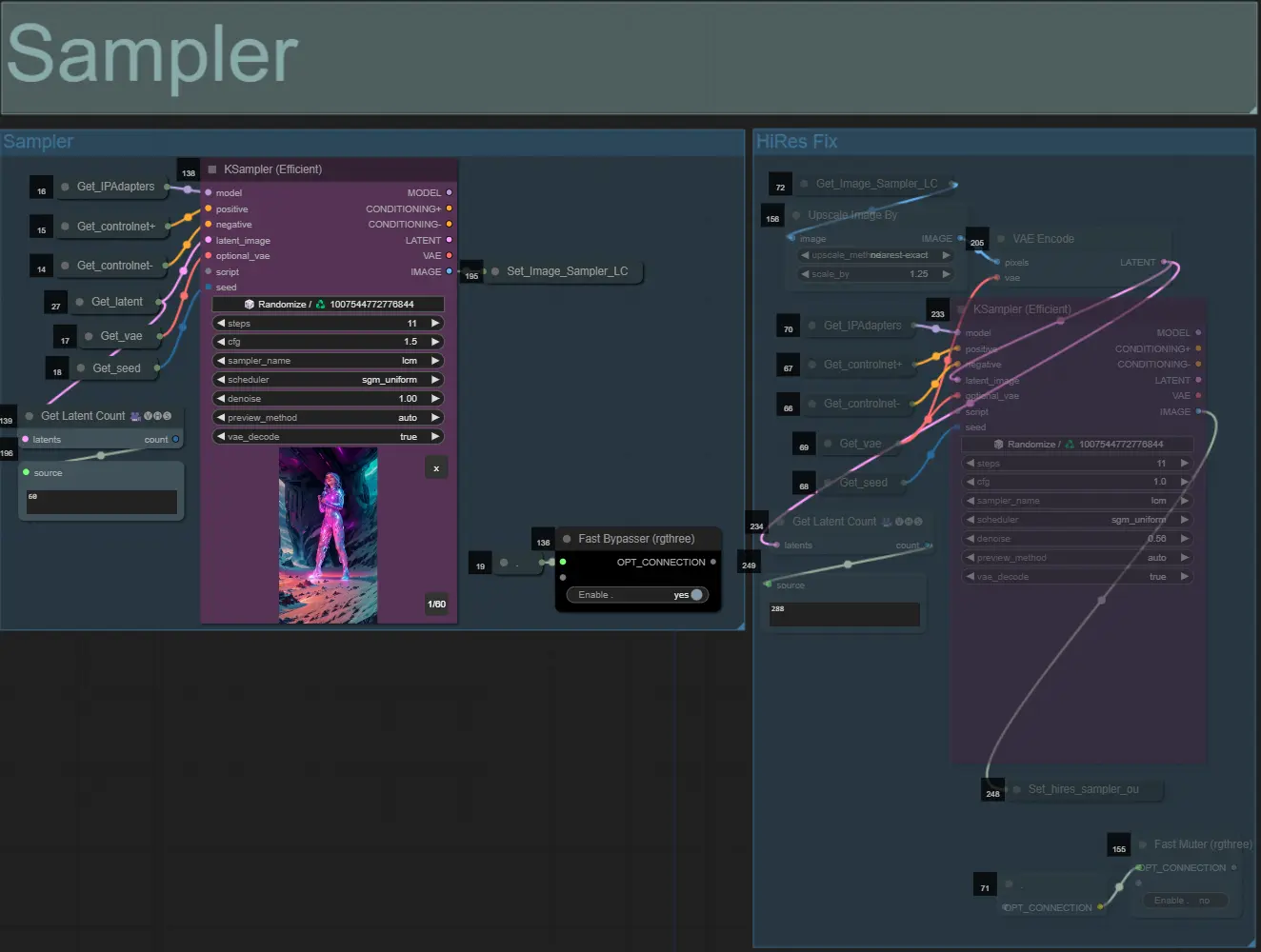
- Per impostazione predefinita, il gruppo HiRes Fix sampler sarà disattivato per risparmiare tempo di elaborazione durante i test
- Raccomando di bypassare il gruppo Sampler anche quando si sperimentano le impostazioni della maschera di dilatazione per risparmiare tempo.
- Nei rendering finali puoi attivare il gruppo HiRes Fix che aumenterà la risoluzione e aggiungerà dettagli al risultato finale.
Output

- Ci sono due gruppi di output: a sinistra per l'output del sampler standard, e a destra per l'output del HiRes Fix sampler.
Informazioni sull'autore
Akatz AI:
- Sito web:
- http://patreon.com/Akatz
- https://civitai.com/user/akatz
- https://www.youtube.com/@akatz_ai
- https://www.instagram.com/akatz.ai/
- https://www.tiktok.com/@akatz_ai
- https://x.com/akatz_ai
- https://github.com/akatz-ai
Contatti:
- Email: akatz.hello@gmail.com
