
Questa guida su Unsampling, scritta da Inner-Reflections, contribuisce notevolmente a esplorare il metodo Unsampling per ottenere un trasferimento di stile video drammaticamente coerente.
1. Introduzione: Controllo del Rumore Latente con Unsampling
Il Rumore Latente è la base di tutto ciò che facciamo con Stable Diffusion. È sorprendente fare un passo indietro e pensare a cosa siamo in grado di realizzare con questo. Tuttavia, generalmente parlando, siamo costretti a usare un numero casuale per generare il rumore. E se potessimo controllarlo?
Non sono il primo a usare Unsampling. Esiste da molto tempo ed è stato utilizzato in diversi modi. Tuttavia, fino ad ora, generalmente non sono stato soddisfatto dei risultati. Ho passato diversi mesi a trovare le migliori impostazioni e spero che questa guida vi piaccia.
Utilizzando il processo di campionamento con AnimateDiff/Hotshot possiamo trovare un rumore che rappresenta il nostro video originale e quindi rende più facile qualsiasi tipo di trasferimento di stile. È particolarmente utile mantenere Hotshot coerente dato il suo contesto di 8 fotogrammi.
Questo processo di unsampling essenzialmente converte il nostro video di input in rumore latente che mantiene il movimento e la composizione dell'originale. Possiamo quindi usare questo rumore rappresentativo come punto di partenza per il processo di diffusione piuttosto che un rumore casuale. Questo permette all'IA di applicare lo stile target mantenendo la coerenza temporale.
Questa guida presuppone che abbiate installato AnimateDiff e/o Hotshot. Se non l'avete già fatto, le guide sono disponibili qui:
AnimateDiff: https://civitai.com/articles/2379
Guida Hotshot XL: https://civitai.com/articles/2601/
Link alla risorsa - Se volete pubblicare video su Civitai utilizzando questo flusso di lavoro. https://civitai.com/models/544534
2. Requisiti di Sistema per questo Flusso di Lavoro
Si consiglia un computer Windows con una scheda grafica NVIDIA con almeno 12GB di VRAM. Sulla piattaforma RunComfy, utilizzare una macchina di classe Media (16GB di VRAM) o superiore. Questo processo non richiede più VRAM rispetto ai flussi di lavoro standard di AnimateDiff o Hotshot, ma richiede quasi il doppio del tempo, poiché esegue essenzialmente il processo di diffusione due volte: una volta per l'upsampling e una volta per il resampling con lo stile target.
3. Spiegazioni dei Nodi e Guida alle Impostazioni
Nodo: Custom Sampler
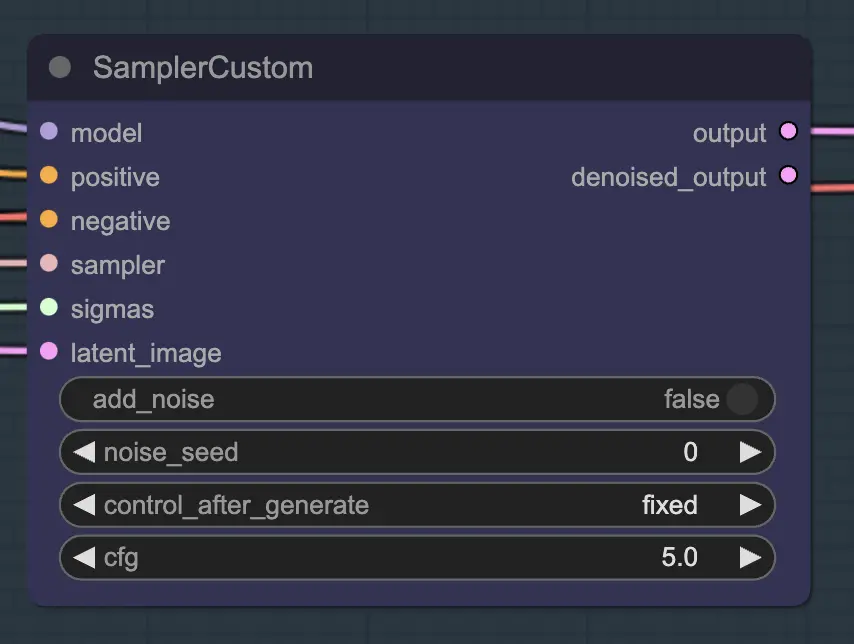
La parte principale di questo è l'utilizzo del Custom Sampler che divide tutte le impostazioni che di solito vedete nel KSampler regolare in pezzi:
Questo è il nodo KSampler principale - per l'unsampling aggiungere rumore/seme non ha alcun effetto (che io sappia). Il CFG è importante - generalmente parlando, più alto è il CFG in questo passaggio, più il video assomiglierà all'originale. Un CFG più alto costringe l'unsampler a corrispondere più strettamente all'input.
Nodo: KSampler Select
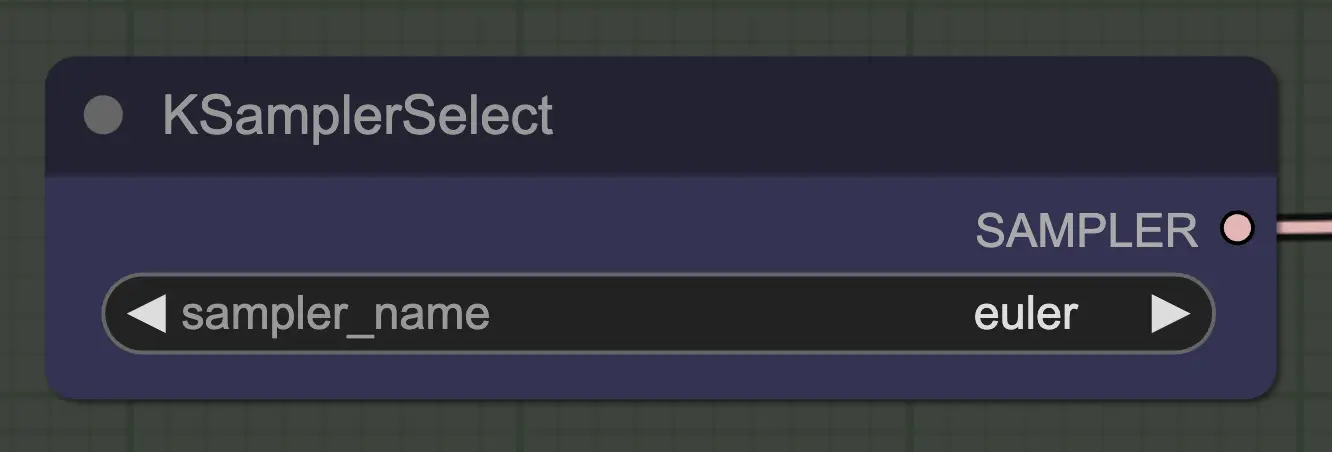
La cosa più importante è usare un sampler che converga! Ecco perché stiamo usando euler invece di euler a poiché quest'ultimo risulta in maggiore casualità/instabilità. I sampler ancestrali che aggiungono rumore a ogni passaggio impediscono all'unsampling di convergere pulitamente. Se volete leggere di più su questo, ho sempre trovato utile questo articolo. @spacepxl su reddit suggerisce che DPM++ 2M Karras è forse il sampler più accurato a seconda del caso d'uso.
Nodo: Align Your Step Scheduler
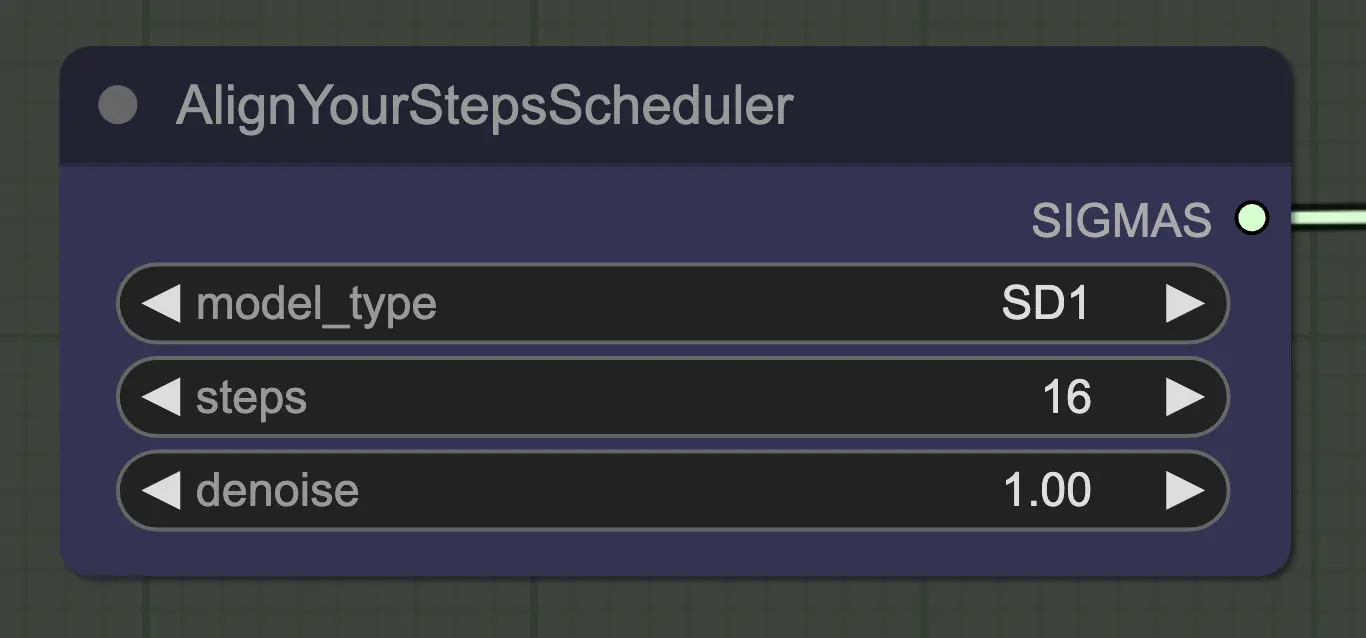
Qualsiasi scheduler funzionerà bene qui - Align Your Steps (AYS) tuttavia ottiene buoni risultati con 16 passaggi, quindi ho optato per usarlo per ridurre il tempo di calcolo. Più passaggi convergeranno più completamente ma con rendimenti decrescenti.
Nodo: Flip Sigma
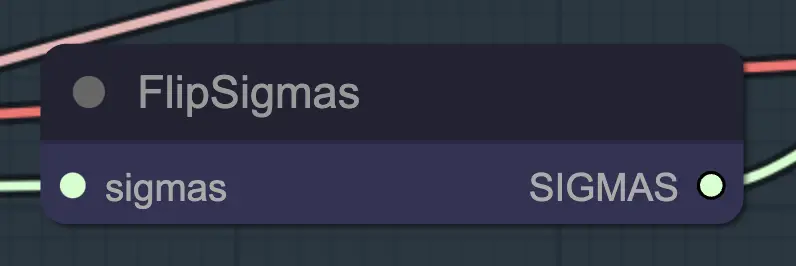
Flip Sigma è il nodo magico che fa avvenire l'unsampling! Invertendo il programma sigma, invertiamo il processo di diffusione per passare da un'immagine di input pulita a un rumore rappresentativo.
Nodo: Prompt
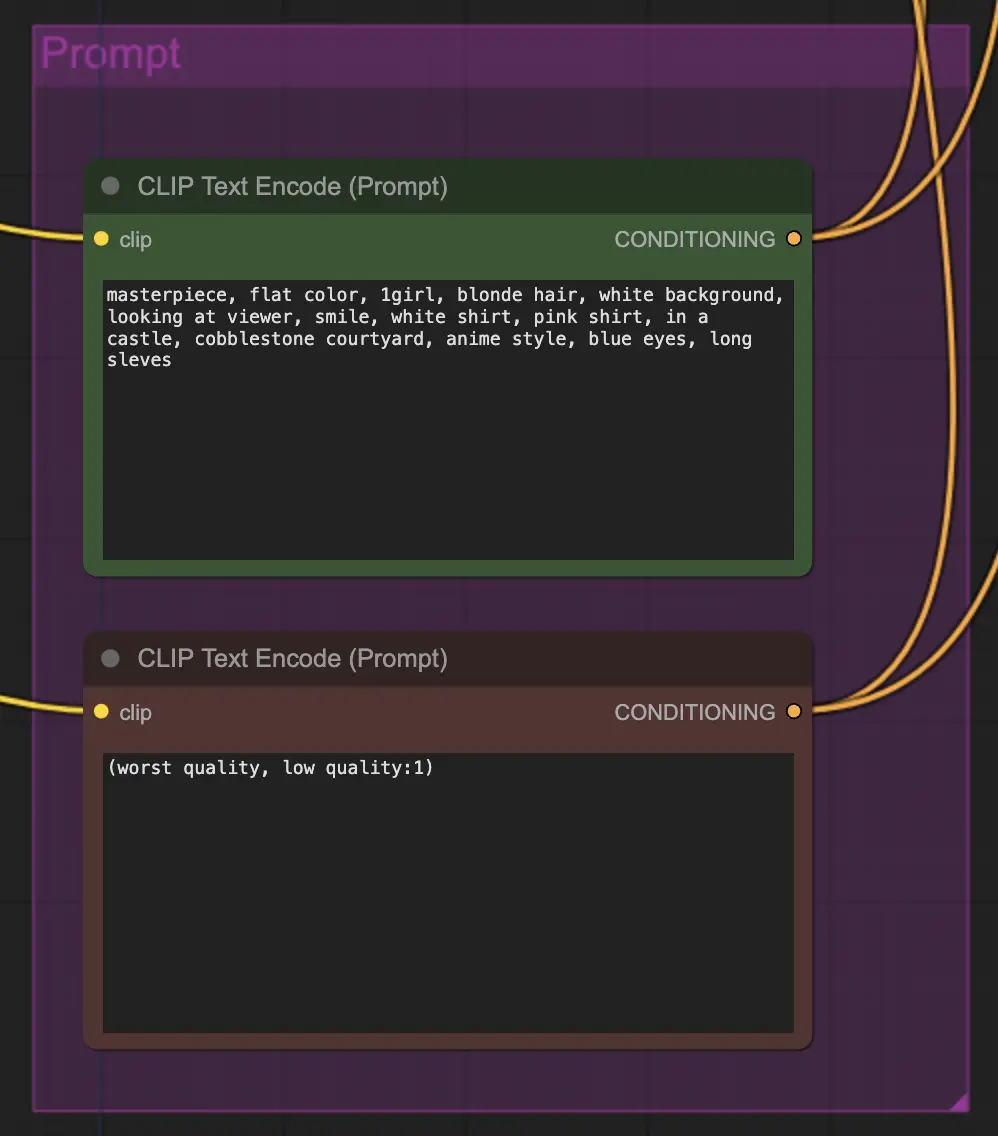
Il prompt è molto importante in questo metodo per qualche motivo. Un buon prompt può davvero migliorare la coerenza del video, specialmente più si vuole spingere la trasformazione. In questo esempio ho fornito lo stesso conditioning sia all'unsampler che al resampler. Sembra funzionare bene generalmente - nulla vi impedisce comunque di mettere un conditioning vuoto nell'unsampler - trovo che aiuti a migliorare il trasferimento di stile, forse con una leggera perdita di coerenza.
Nodo: Resampling
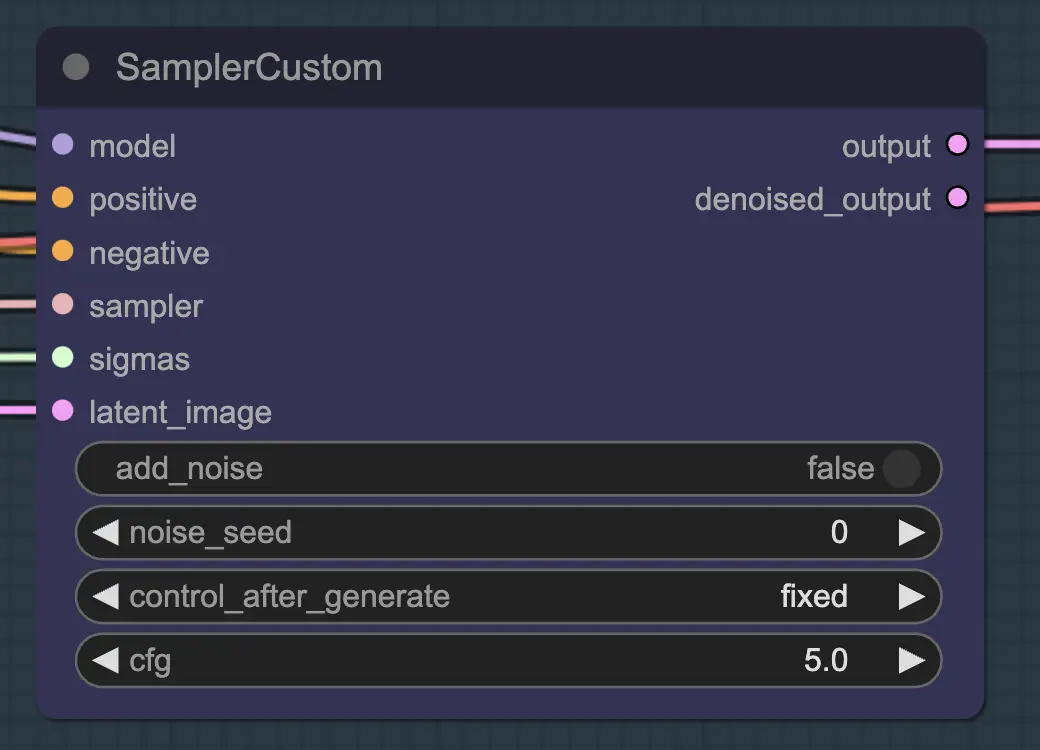
Per il resampling è importante avere l'aggiunta di rumore disattivata (anche se avere rumore vuoto nelle impostazioni di campionamento di AnimateDiff ha lo stesso effetto - ho fatto entrambi per il mio flusso di lavoro). Se aggiungete rumore durante il resampling otterrete un risultato incoerente e rumoroso, almeno con le impostazioni predefinite. Altrimenti, suggerisco di iniziare con un CFG abbastanza basso combinato con impostazioni deboli di ControlNet poiché sembra dare i risultati più coerenti pur permettendo al prompt di influenzare lo stile.
Altre Impostazioni
Il resto delle mie impostazioni sono preferenze personali. Ho semplificato questo flusso di lavoro quanto penso sia possibile pur includendo i componenti e le impostazioni chiave.
4. Informazioni sul Flusso di Lavoro
Il flusso di lavoro predefinito utilizza il modello SD1.5. Tuttavia, è possibile passare a SDXL semplicemente cambiando il checkpoint, VAE, modello AnimateDiff, modello ControlNet e modello di schedule dei passaggi a SDXL.
5. Note Importanti/Problemi
- Flashing - Se guardate i latenti decodificati e visualizzati in anteprima creati dall'unsampling nei miei flussi di lavoro, noterete alcuni con evidenti anomalie di colore. La causa esatta non mi è chiara, e generalmente non influenzano i risultati finali. Queste anomalie sono particolarmente evidenti con SDXL. Tuttavia, possono a volte causare flashing nel vostro video. La causa principale sembra essere legata ai ControlNets - quindi ridurre la loro forza può aiutare. Cambiare il prompt o anche alterare leggermente lo scheduler può anche fare la differenza. Continuo a incontrare questo problema a volte - se avete una soluzione, per favore fatemelo sapere!
- DPM++ 2M può a volte migliorare il flashing.
6. Dove Andare da Qui?
Questo sembra un modo completamente nuovo di controllare la coerenza del video, quindi c'è molto da esplorare. Se volete i miei suggerimenti:
- Provate a combinare/mascherare il rumore da diversi video sorgente.
- Aggiungete IPAdapter per una trasformazione coerente dei personaggi.
About Author
Inner-Reflections
- https://x.com/InnerRefle11312
- https://civitai.com/user/Inner_Reflections_AI

