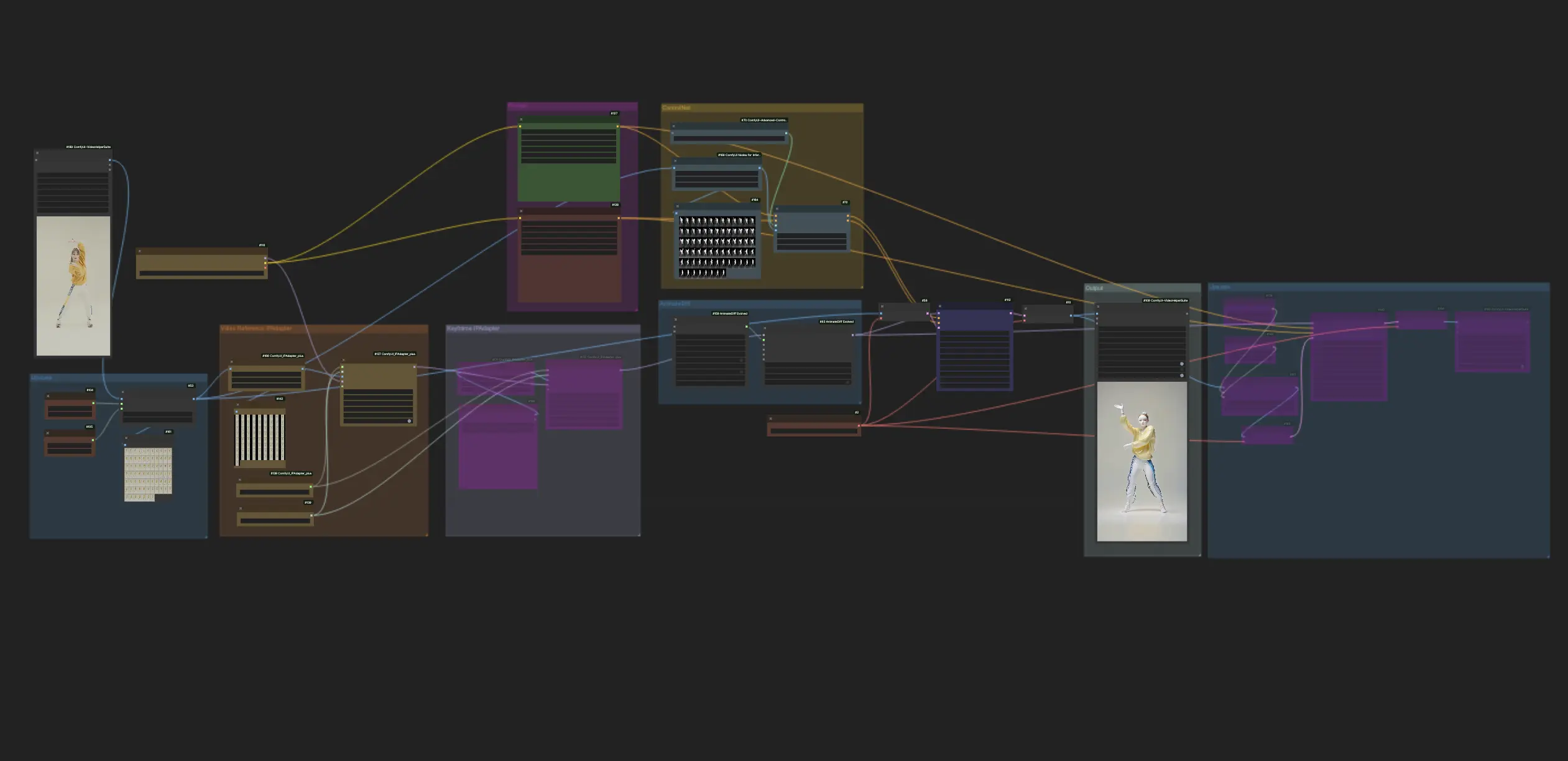
AnimateDiff + ControlNet | Stile Arte Ceramica
Questo workflow all'interno di ComfyUI impiega AnimateDiff e ControlNet incentrato sulla profondità, tra gli altri come Lora, per trasformare abilmente i video in Stile Arte Ceramica. Permette al contenuto originale di adottare un tocco artistico distintivo, elevandolo efficacemente al regno dei capolavori dell'arte ceramica.ComfyUI Vid2Vid (Art) Flusso di lavoro
- Workflow completamente operativi
- Nessun nodo o modello mancante
- Nessuna configurazione manuale richiesta
- Presenta visuali mozzafiato
ComfyUI Vid2Vid (Art) Esempi
ComfyUI Vid2Vid (Art) Descrizione
1. Workflow ComfyUI: AnimateDiff + ControlNet | Stile Arte Ceramica
Questo workflow utilizza AnimateDiff, ControlNet focalizzato sulla profondità e specifici Lora per trasformare abilmente i video in uno Stile Arte Ceramica. Sei incoraggiato a usare diversi prompt per ottenere vari stili artistici, trasformando le tue idee in realtà.
2. Come usare AnimateDiff
AnimateDiff è progettato per animare immagini statiche e prompt di testo in video dinamici, sfruttando i modelli Stable Diffusion e un modulo di movimento specializzato. Automatizza il processo di animazione predicendo transizioni senza interruzioni tra i fotogrammi, rendendolo accessibile agli utenti senza competenze di programmazione.
2.1 Moduli di movimento AnimateDiff
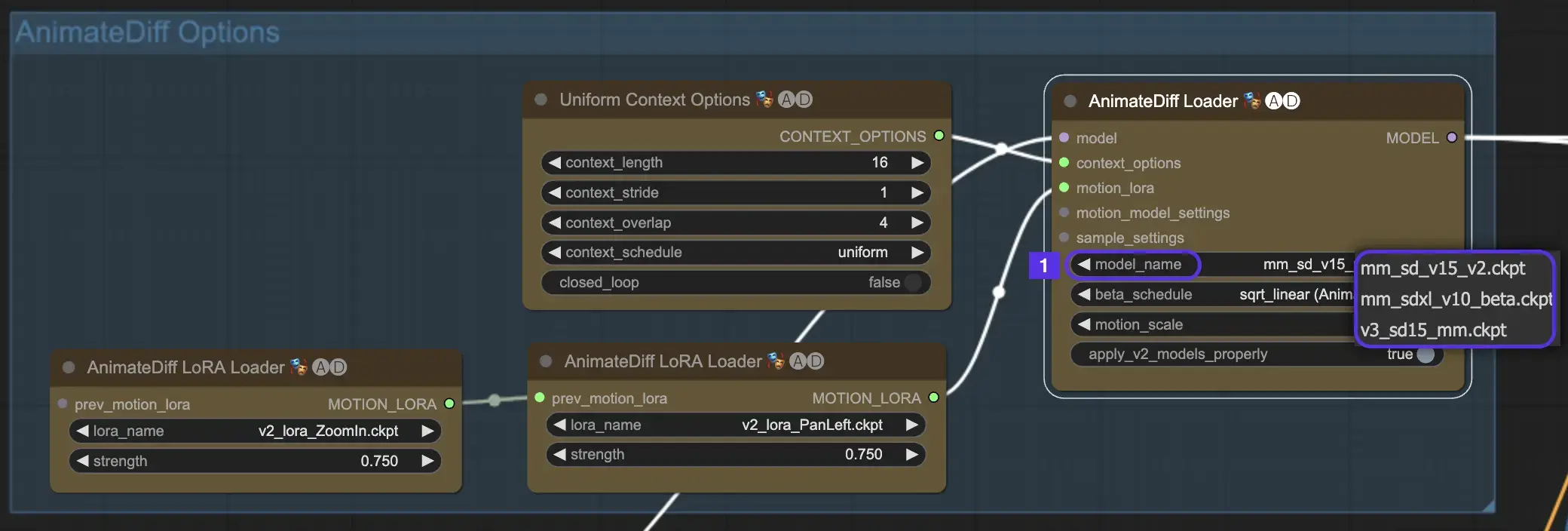
Per iniziare, seleziona il modulo di movimento AnimateDiff desiderato dal menu a discesa model_name:
- Usa v3_sd15_mm.ckpt per AnimateDiff V3
- Usa mm_sd_v15_v2.ckpt per AnimateDiff V2
- Usa mm_sdxl_v10_beta.ckpt per AnimateDiff SDXL
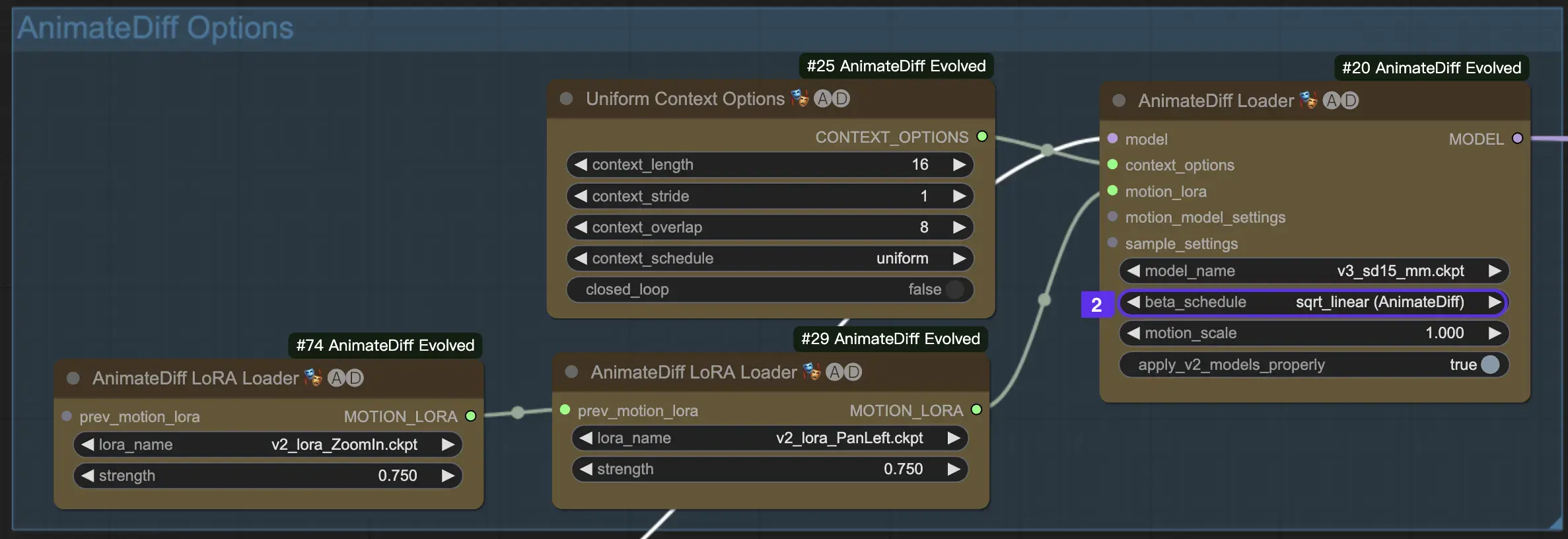
2.2 Beta Schedule
Il Beta Schedule in AnimateDiff è cruciale per regolare il processo di riduzione del rumore durante la creazione dell'animazione.
Per le versioni V3 e V2 di AnimateDiff, si consiglia l'impostazione sqrt_linear, anche se sperimentare con l'impostazione linear può produrre effetti unici.
Per AnimateDiff SDXL, si consiglia l'impostazione linear (AnimateDiff-SDXL).
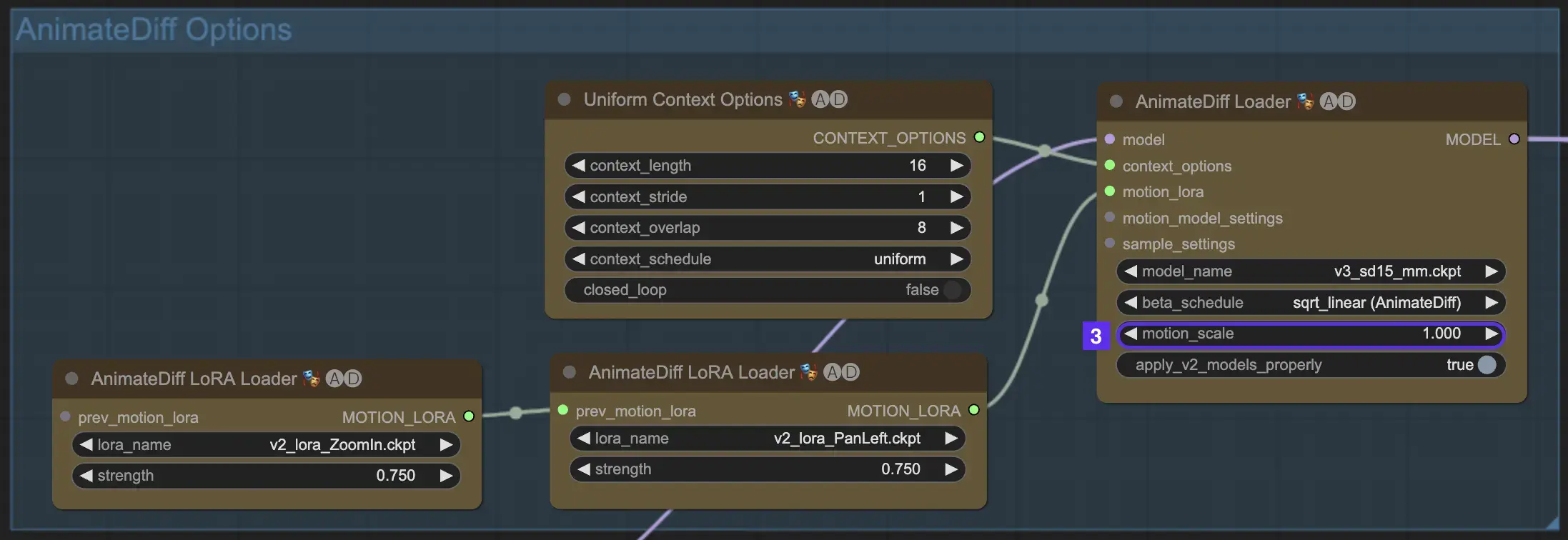
2.3 Motion Scale
La funzione Motion Scale in AnimateDiff consente di regolare l'intensità del movimento nelle tue animazioni. Una Motion Scale inferiore a 1 porta a movimenti più sottili, mentre una scala superiore a 1 amplifica il movimento.
2.4 Context Length
L'Uniform Context Length in AnimateDiff è essenziale per garantire transizioni fluide tra le scene definite dalla tua Batch Size. Agisce come un editor esperto, collegando senza interruzioni le scene per una narrazione fluida. Impostare un Uniform Context Length più lungo assicura transizioni più fluide, mentre una lunghezza più breve offre cambi di scena più rapidi e distinti, utili per alcuni effetti. La lunghezza standard dell'Uniform Context è impostata a 16.
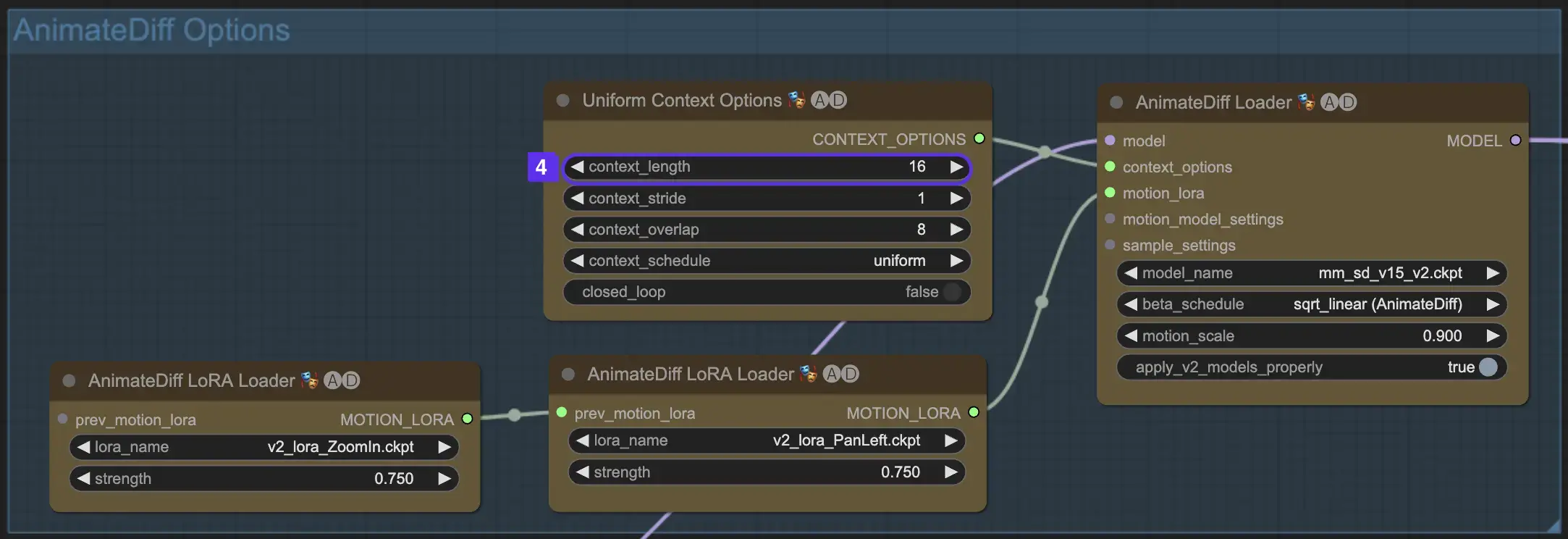
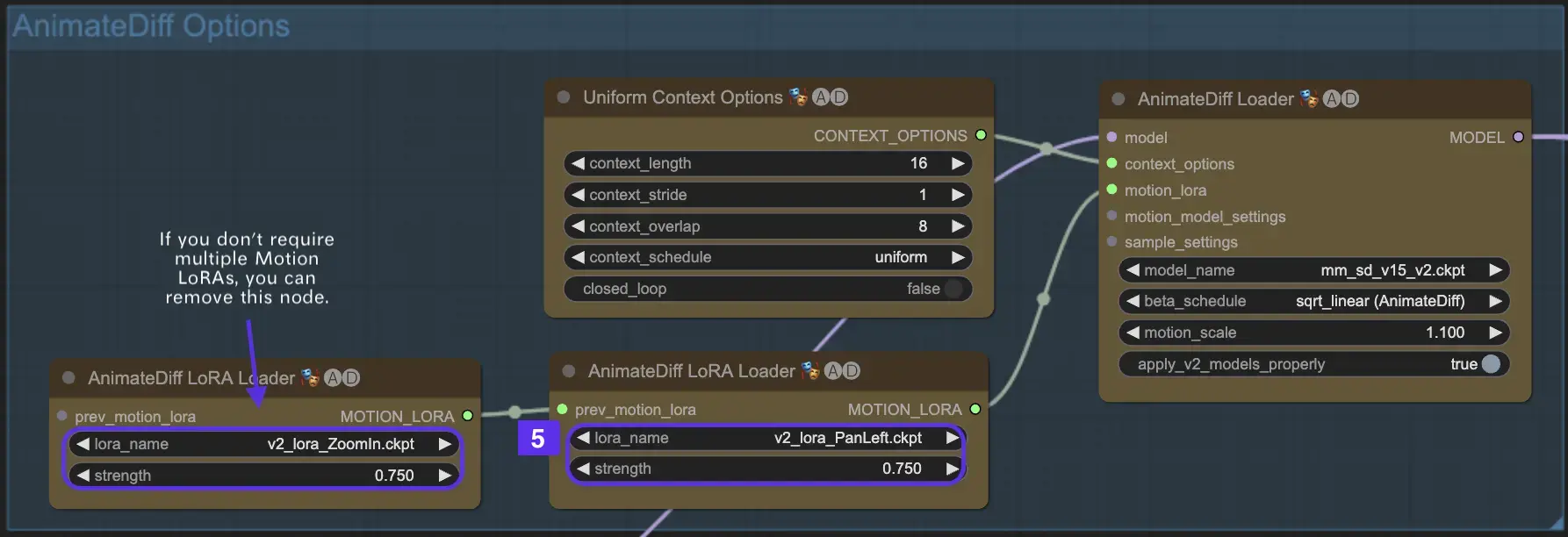
2.5 Utilizzo di Motion LoRA per una dinamica della videocamera migliorata (specifico per AnimateDiff v2)
I Motion LoRA, compatibili solo con AnimateDiff v2, introducono un ulteriore livello di movimento dinamico della videocamera. Raggiungere il giusto equilibrio con il peso LoRA, tipicamente intorno a 0,75, assicura un movimento fluido della videocamera privo di distorsioni dello sfondo.
Inoltre, concatenare vari modelli Motion LoRA consente una dinamica complessa della videocamera. Questo permette ai creatori di sperimentare e scoprire la combinazione ideale per la loro animazione, elevandola a un livello cinematografico.
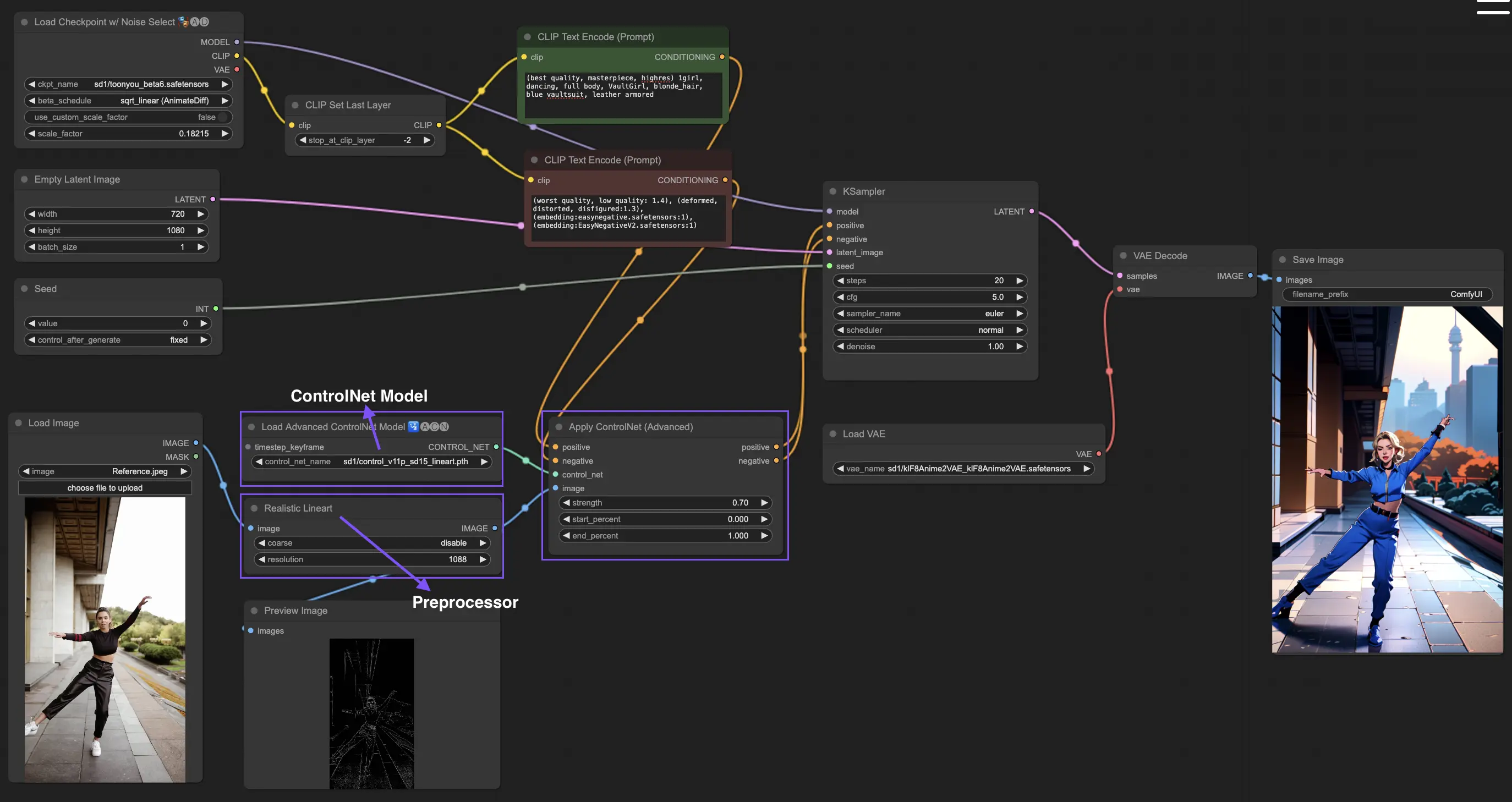
3. Come usare ControlNet
ControlNet migliora la generazione di immagini introducendo un controllo spaziale preciso sui modelli da testo a immagine, permettendo agli utenti di manipolare le immagini in modi sofisticati oltre ai semplici prompt di testo, utilizzando vaste librerie di modelli come Stable Diffusion per attività complesse come disegnare, mappare e segmentare le immagini.
Il seguente è il workflow più semplice che utilizza ControlNet.
3.1 Caricamento del nodo "Apply ControlNet"
Inizia la creazione dell'immagine caricando il nodo "Apply ControlNet" in ComfyUI, impostando le basi per combinare elementi visivi e testuali nel tuo design.
3.2 Input del nodo "Apply ControlNet"
Usa il Conditioning positivo e negativo per modellare la tua immagine, seleziona un modello ControlNet per definire i tratti di stile e preelabora la tua immagine per assicurarti che corrisponda ai requisiti del modello ControlNet, rendendola così pronta per la trasformazione.
3.3 Output del nodo "Apply ControlNet"
Gli output del nodo guidano il modello di diffusione, offrendo una scelta tra raffinare ulteriormente l'immagine o aggiungere più ControlNet per dettagli e personalizzazioni migliorate in base all'interazione di ControlNet con i tuoi input creativi.
3.4 Regolazione di "Apply ControlNet" per risultati ottimali
Controlla l'influenza di ControlNet sulla tua immagine attraverso impostazioni come Determining Strength, Adjusting Start Percent e Setting End Percent per regolare finemente il processo creativo e il risultato dell'immagine.
Per informazioni più dettagliate, consulta
Questo workflow è ispirato da con alcune modifiche. Per ulteriori informazioni, visita il suo canale YouTube.

