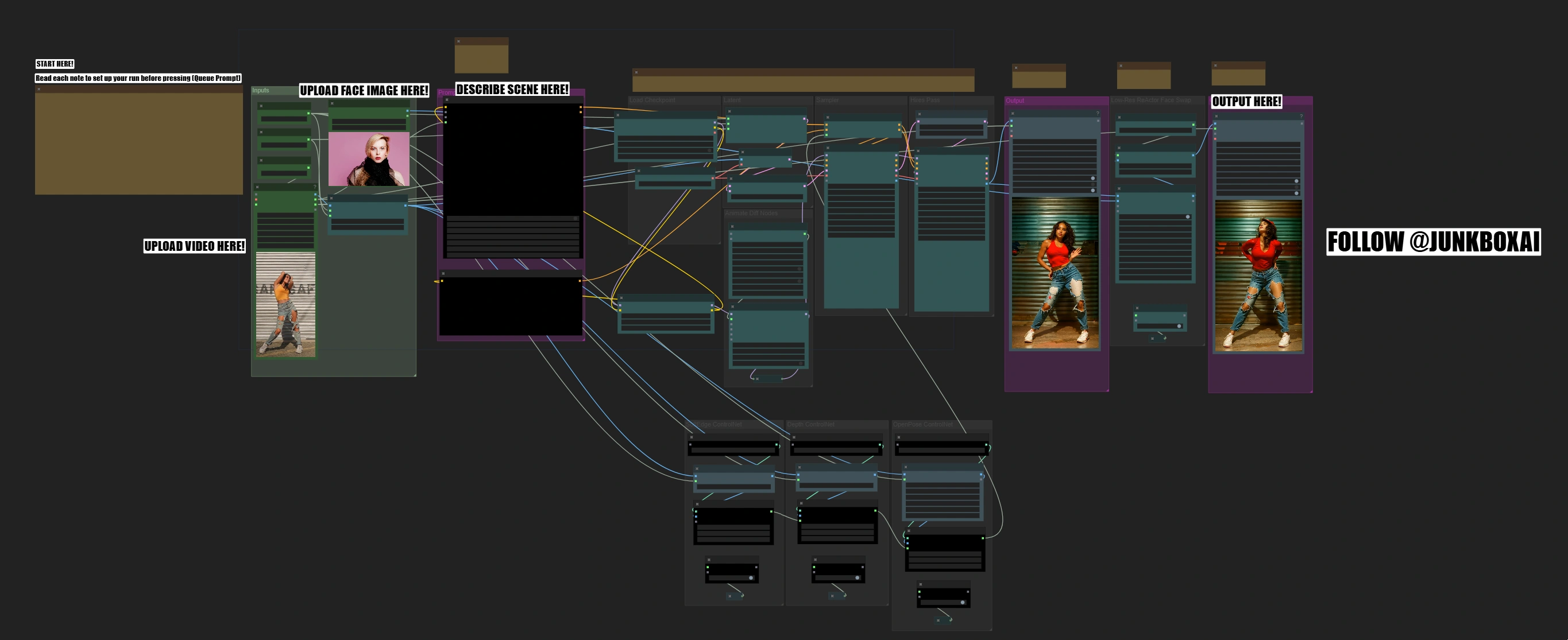
Dance Video Transform | Scene Customization & Face Swap
Questo flusso di lavoro Dance Video Transform combina il modello SD1.5, AnimateDiff, ControlNet e ReActor face swap per offrire trasformazioni coreografiche di alta qualità. Preserva il movimento del ballerino utilizzando una guida tripla ControlNet (Edge, Depth e OpenPose), mentre ReActor e CodeFormer garantiscono un face-swapping accurato con una fedeltà migliorata. Il flusso di lavoro supporta il controllo dinamico delle scene tramite la pianificazione dei prompt in batch, consentendo una personalizzazione specifica per frame. Con le opzioni di contesto di AnimateDiff e la scalatura adattiva del movimento, assicura una conservazione del movimento fluida e naturale durante tutta la trasformazione.ComfyUI Dance Video Transform Flusso di lavoro
- Workflow completamente operativi
- Nessun nodo o modello mancante
- Nessuna configurazione manuale richiesta
- Presenta visuali mozzafiato
ComfyUI Dance Video Transform Esempi
ComfyUI Dance Video Transform Descrizione
Cosa fa il Dance Video Transform ComfyUI Workflow
Il Dance Video Transform ComfyUI Workflow trasforma i video di danza in nuove scene sorprendenti con face swapping professionale, preservando la coreografia originale e garantendo un output di alta qualità. Il processo avviene in fasi, dall'analisi del movimento alla sostituzione del volto, permettendo controlli di qualità ad ogni passaggio.
Come funziona il Dance Video Transform ComfyUI Workflow
Il flusso di lavoro trasforma il tuo video di danza automatizzando queste complesse trasformazioni attraverso diverse fasi, richiedendo solo il tuo video, un'immagine del viso e la descrizione della scena: Analisi del movimento → Trasferimento di stile → Sostituzione del volto
- Analizza i movimenti di danza e le informazioni spaziali
- Trasforma la scena secondo la tua descrizione
- Integra il nuovo volto mantenendo le espressioni
Caratteristiche principali del Dance Video Transform ComfyUI Workflow
- Ottimizzato per il formato verticale (rapporto di aspetto 9:16)
- Sistema Triple ControlNet per trasformazioni stabili
- Face swapping professionale con fusione naturale
- Modalità di test veloce (elabora 50 frame in pochi minuti)
- Supporto per output ad alta risoluzione (fino a 896px di altezza)
- Conservazione avanzata del movimento utilizzando AnimateDiff
- Sistema di output duale per la verifica della qualità
Guida Rapida
Passo 1: Configurazione Iniziale
Nei rispettivi nodi:
-
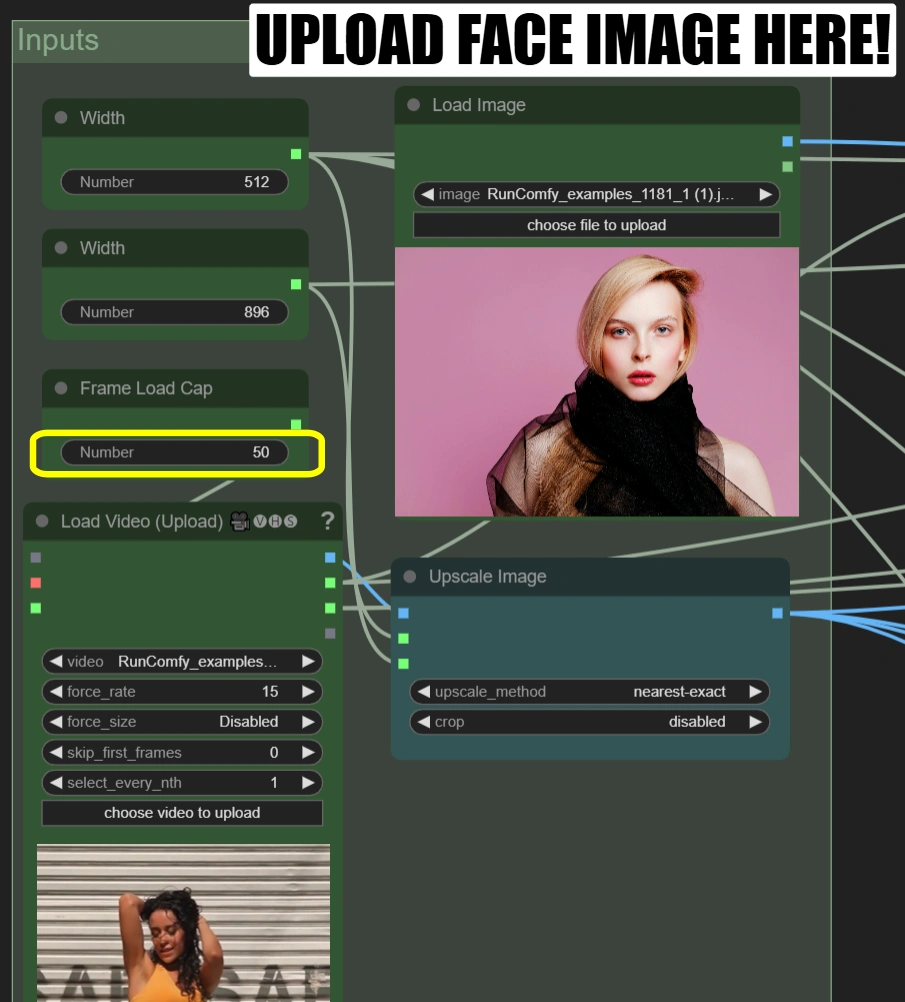
Carica Video (Upload):
- Carica un video di danza di 10-15 secondi con un rapporto di aspetto 9:16
- Se il tuo video non è in 9:16, dovrai regolare i parametri di Larghezza e Altezza per adattarli al tuo video.
- Limite di Caricamento Frame: 50 (renderizza solo i primi 50 frame per un test rapido)
-
Carica Immagine:
- Carica una foto chiara del viso frontale
-
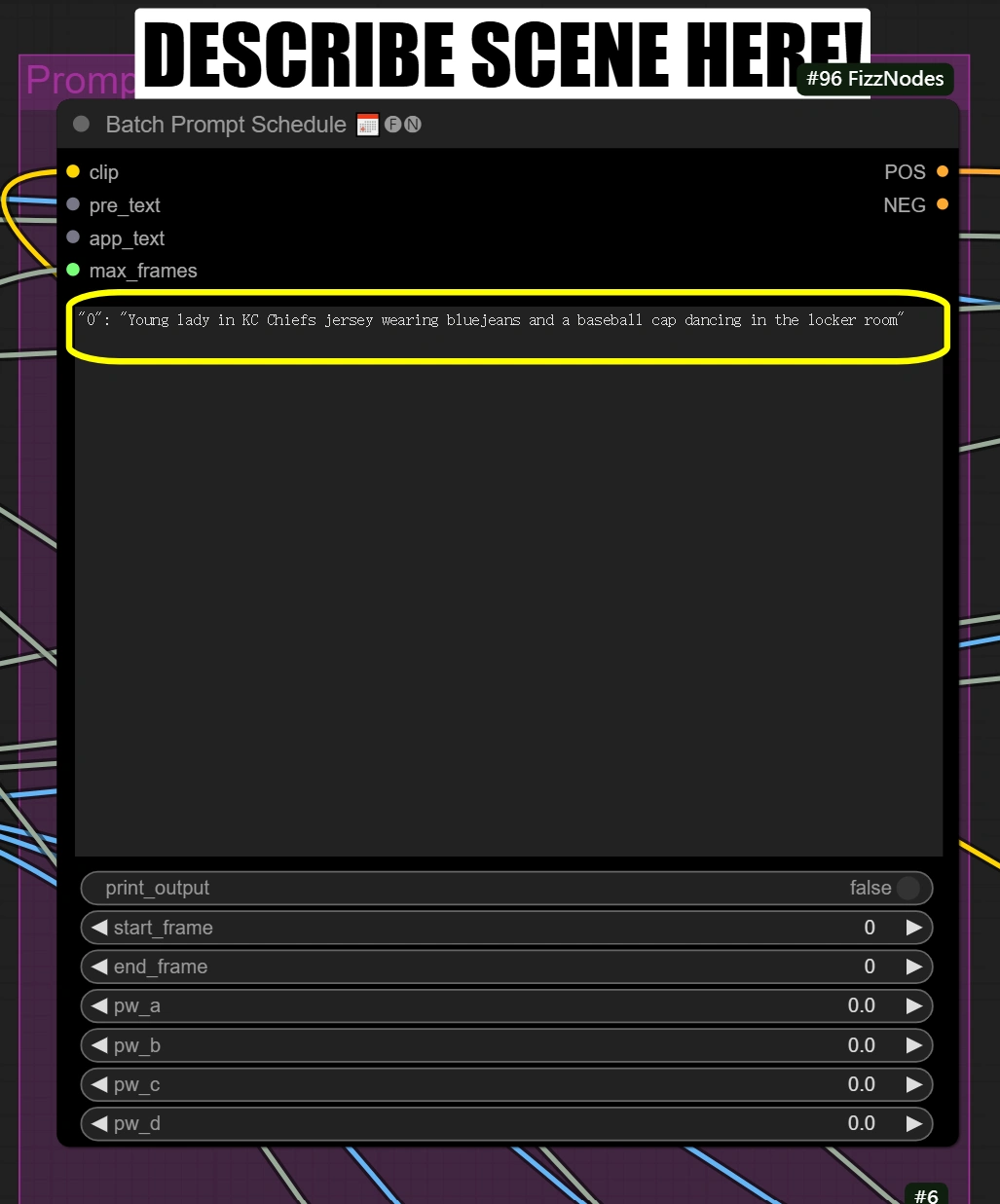
Pianificazione dei Prompt in Batch:
- Descrivi brevemente la scena e qualsiasi altro aspetto che vuoi trasformare
"0": "[persona] con maglia dei KC Chiefs, indossando bluejeans e un berretto da baseball che balla nello spogliatoio"
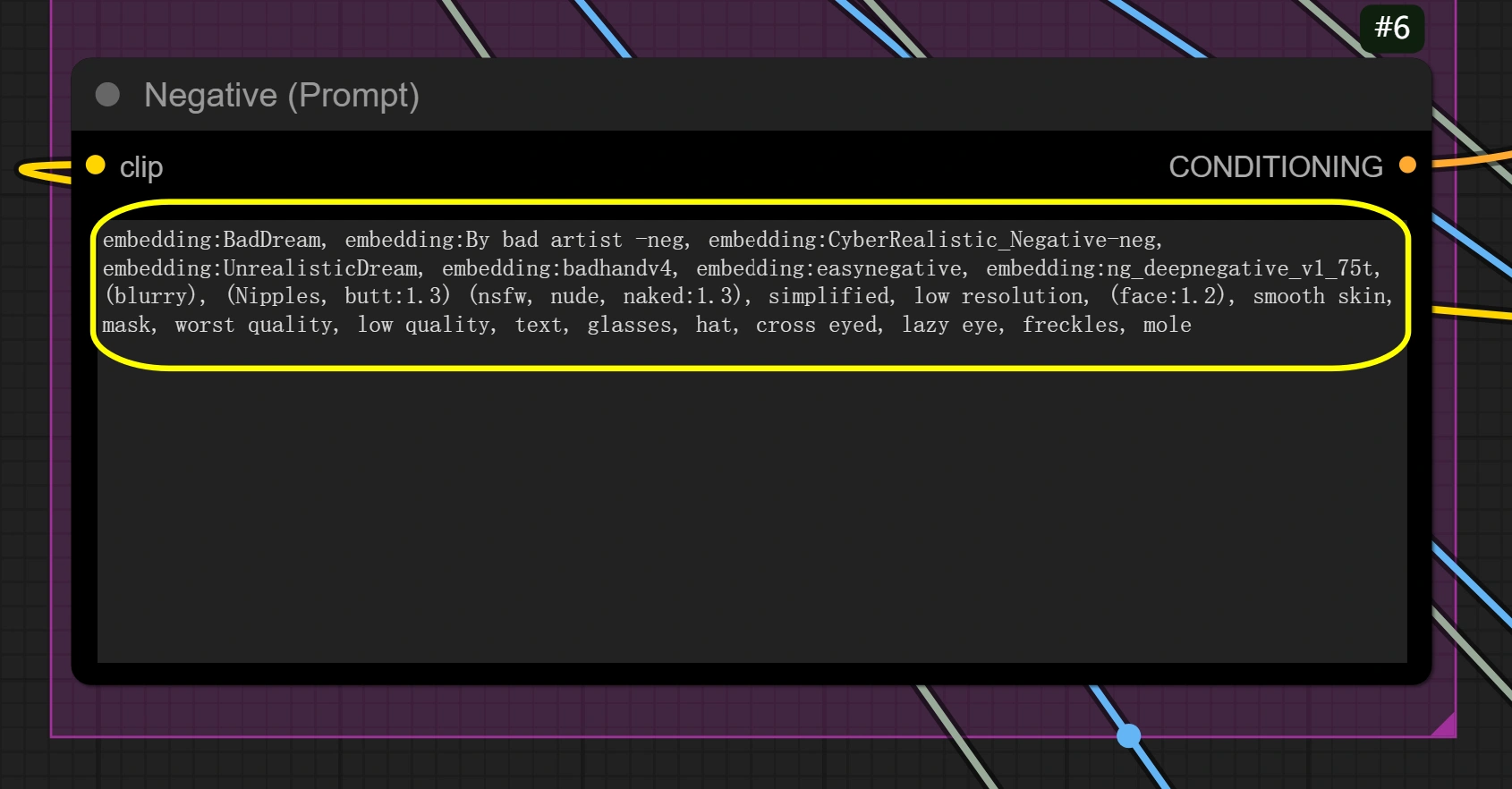
- Imposta il prompt negativo se necessario
Passo 2: Test Rapido
- Clicca "Queue Prompt"
- Questo elabora ~2 secondi di video
- Vedrai due output:
- Primo output: Solo trasformazione della scena
- Secondo output: Con face swap applicato

Passo 3: Elaborazione Completa del Video
Solo dopo che il test rapido appare soddisfacente:
- Torna al nodo "Carica Video"
- Cambia Limite di Caricamento Frame a 0 per l'intero video
- Clicca "Queue Prompt" per elaborazione completa (Questo richiederà molto più tempo)
Consigli dell per Principianti
- Segui le Note: Cerca eventuali note nell'interfaccia—ti guideranno passo dopo passo
- Non Preoccuparti delle Impostazioni Avanzate: La maggior parte delle volte non è necessario regolare nulla oltre a quanto menzionato qui
- Importanza del Rapporto di Aspetto: Assicurati che il rapporto di aspetto sia corretto, altrimenti il video potrebbe apparire allungato o tagliato
Riferimento ai Nodi Chiave
Impostazioni AnimateDiff
I nodi qui creano una conservazione del movimento fluida durante tutta la trasformazione video. Le Opzioni di Contesto definiscono come i frame devono essere raggruppati e processati, alimentando queste impostazioni all'AnimateDiff Loader, che poi applica la conservazione del movimento effettiva. Le impostazioni di lunghezza e sovrapposizione del contesto influenzano direttamente come l'AnimateDiff Loader mantiene la coerenza del movimento.
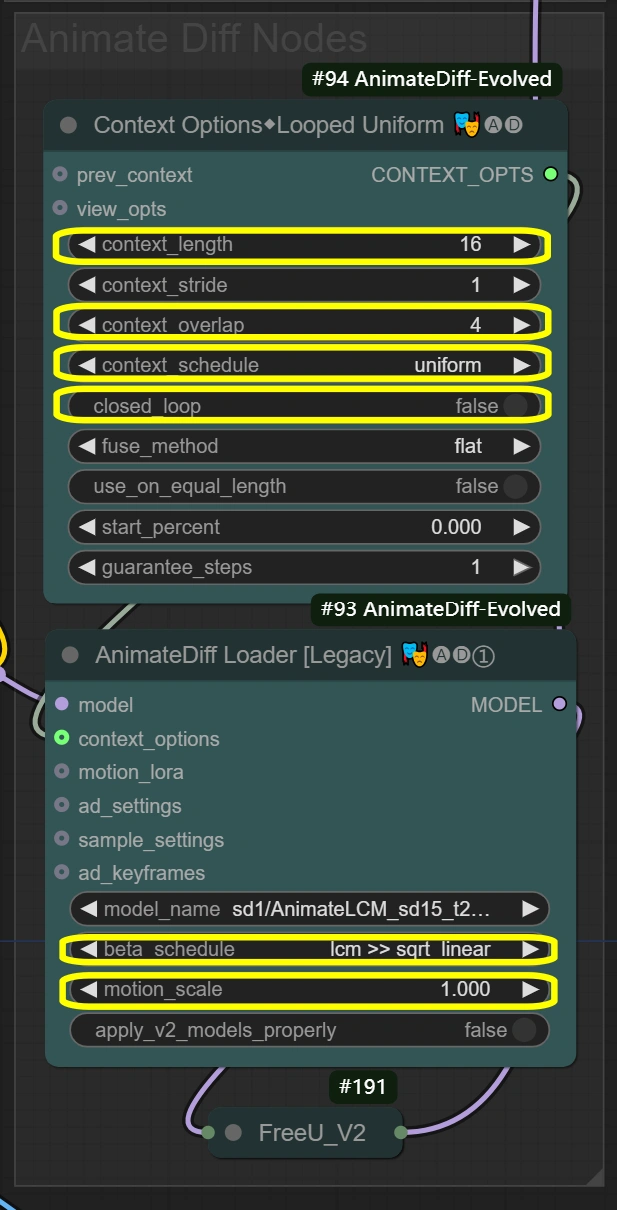
- Nodo Opzioni di Contesto (#94): Realizza il raggruppamento dei frame e il controllo del processamento temporale per un movimento coerente.
- context_length:
- Controlla quanti frame vengono processati insieme
- Più alto = più fluido ma più utilizzo di VRAM
- Più basso = più veloce ma potrebbe perdere coerenza del movimento
- context_overlap:
- Gestisce la fluidità della transizione dei frame
- Più alto = migliore fusione ma elaborazione più lenta
- Più basso = più veloce ma potrebbe mostrare gap nelle transizioni
- context_schedule:
- Controlla la distribuzione dei frame
- "uniform" ideale per il movimento di danza
- Non cambiare a meno di esigenze specifiche
- closed_loop:
- Controlla il comportamento del loop video
- True solo per video perfettamente in loop
- context_length:
- Nodo AnimateDiff Loader (#93): Implementa la conservazione del movimento utilizzando il modello AnimateDiff e applica la coerenza temporale.
- motion_scale:
- Controlla l'intensità del movimento
- Più alto: Movimento esagerato
- Più basso: Movimento attenuato
- beta_schedule: lcm >> sqrt_linear
- Controlla il comportamento del campionamento
- Ottimizzato per questo flusso di lavoro
- Non modificare a meno che non sia necessario
- motion_scale:
Stack ControlNet
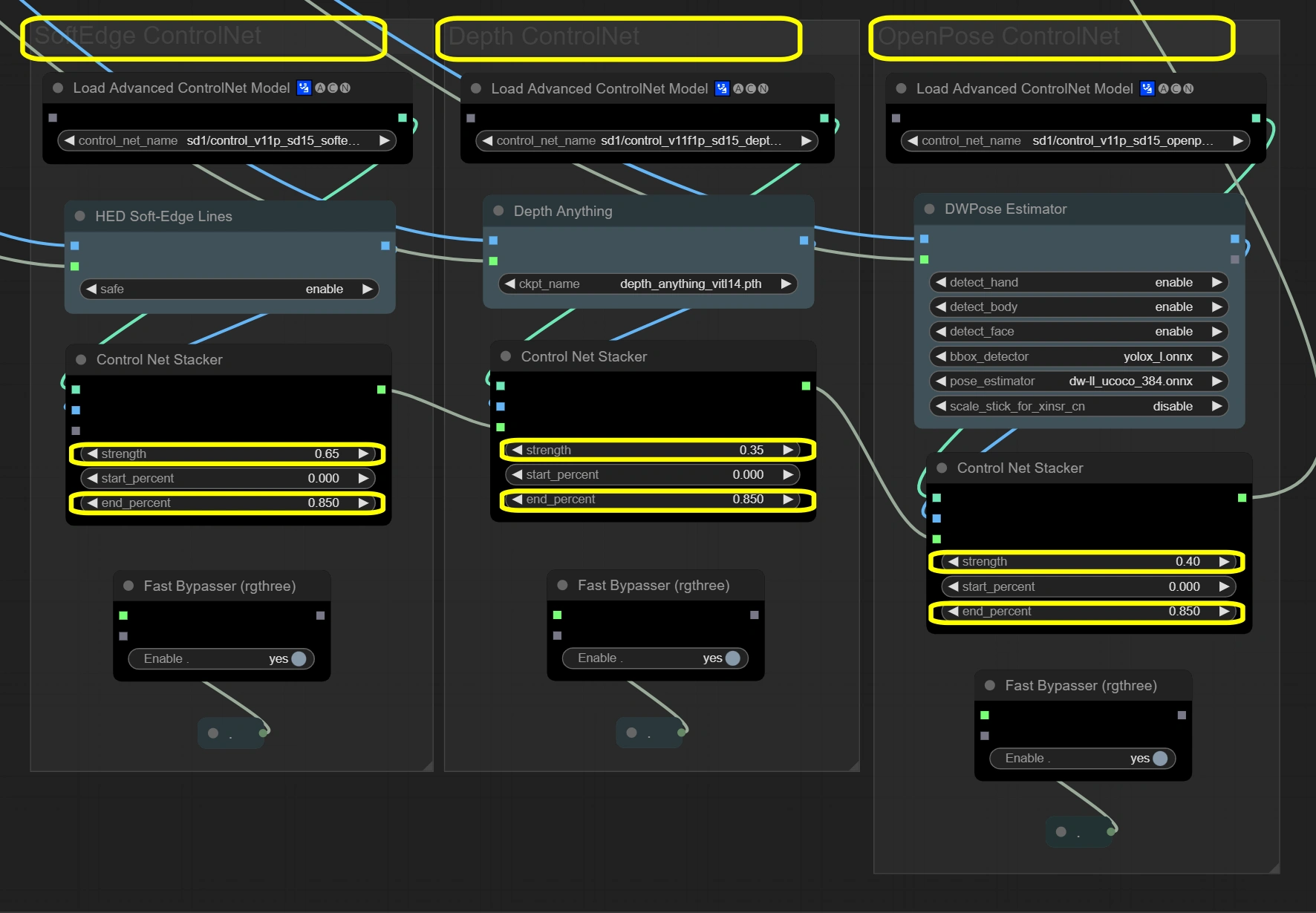
I nodi qui mantengono l'integrità del video attraverso un sistema di guida a tre livelli. I tre ControlNet elaborano i frame di input simultaneamente, ognuno concentrandosi su aspetti diversi. Soft Edge fornisce la struttura di base, Depth aggiunge comprensione spaziale e OpenPose garantisce l'accuratezza del movimento. I risultati si combinano tramite stacker con una forza totale che non supera 1.4 per la stabilità.
- Soft Edge ControlNet: Estrae e preserva elementi strutturali e forme dai frame originali.
- Strength:
- Controlla la conservazione strutturale
- Più alto = maggiore aderenza alle forme originali
- Più basso = più libertà creativa nella modifica delle forme
- End percent:
- Quando l'influenza del controllo si arresta
- Più alto = influenza più lunga durante il processo
- Più basso = consente più deviazione nei passaggi successivi
- Strength:
- Depth ControlNet: Elabora le relazioni spaziali e mantiene la coerenza 3D.
- Strength:
- Controlla la consapevolezza spaziale
- Più alto = maggiore coerenza 3D
- Più basso = più libertà artistica con lo spazio
- End percent:
- Mantiene la durata dell'influenza della profondità
- Dovrebbe corrispondere a Soft Edge per coerenza
- Strength:
- OpenPose ControlNet: Cattura e trasferisce informazioni sulla posa per un movimento accurato.
- Strength:
- Controlla la preservazione della posa
- Più alto = maggiore aderenza alla posa
- Più basso = più interpretazione flessibile della posa
- End percent:
- Mantiene l'influenza della posa
- Mantiene il movimento naturale durante il processo
- Strength:
Elaborazione del Viso
I nodi qui gestiscono la sostituzione e il miglioramento del viso per risultati naturali. Il processo funziona in due fasi: FaceRestore prima migliora la qualità del viso originale, poi ReActor esegue lo swap utilizzando il viso migliorato come riferimento. Questo processo a due fasi assicura un'integrazione naturale pur preservando le espressioni.
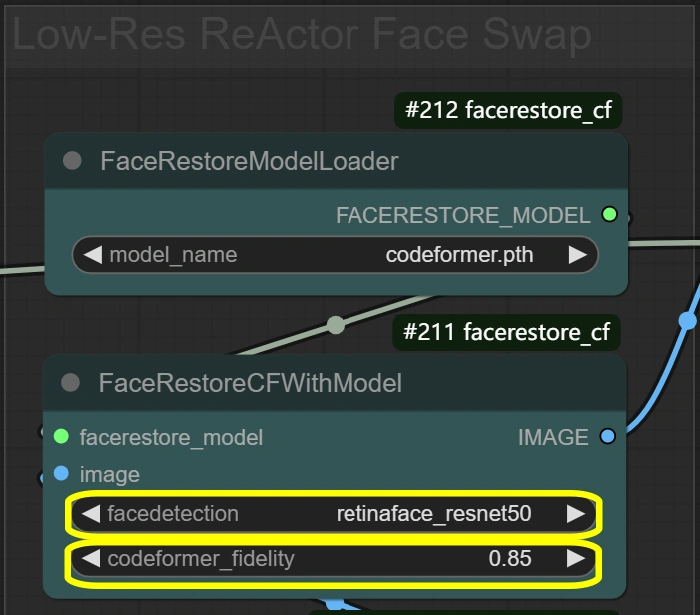
- Sistema FaceRestore: Migliora i dettagli facciali e prepara per lo swapping.
- Fidelity:
- Controlla la conservazione dei dettagli nel restauro
- Più alto = più dettagliato ma potenziali artefatti
- Più basso = più uniforme ma potrebbe perdere dettagli
- Detection:
- Scelta del modello di rilevamento del viso
- Affidabile per la maggior parte degli scenari
- Non cambiare a meno che i volti non vengano rilevati
- Fidelity:
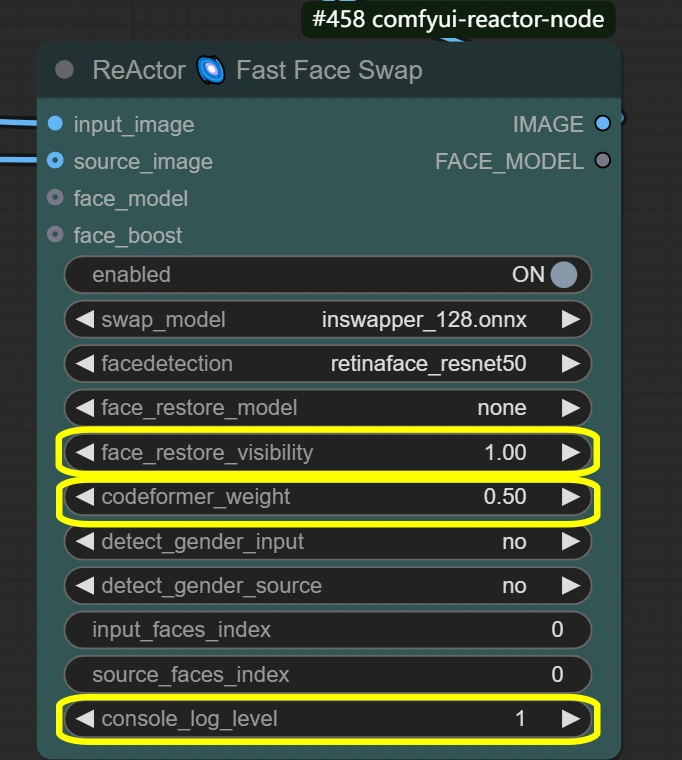
- ReActor Face Swap: Esegue la sostituzione del viso e la fusione con espressioni preservate.
- Visibility:
- Controlla la visibilità dello swap
- Più alto = effetto face swap più forte
- Più basso = fusione più sottile
- Weight:
- Bilanciamento della conservazione delle caratteristiche del viso
- Più alto = caratteristiche del viso della fonte più forti
- Più basso = migliore fusione con il target
- Console log level:
- Controlla le informazioni di debugging
- Più alto = log più dettagliati
- Visibility:
Dettagli Aggiuntivi sui Nodi
Input & Preprocessing
Scopo: Carica il video, regola le dimensioni e prepara il modello VAE per l'elaborazione.
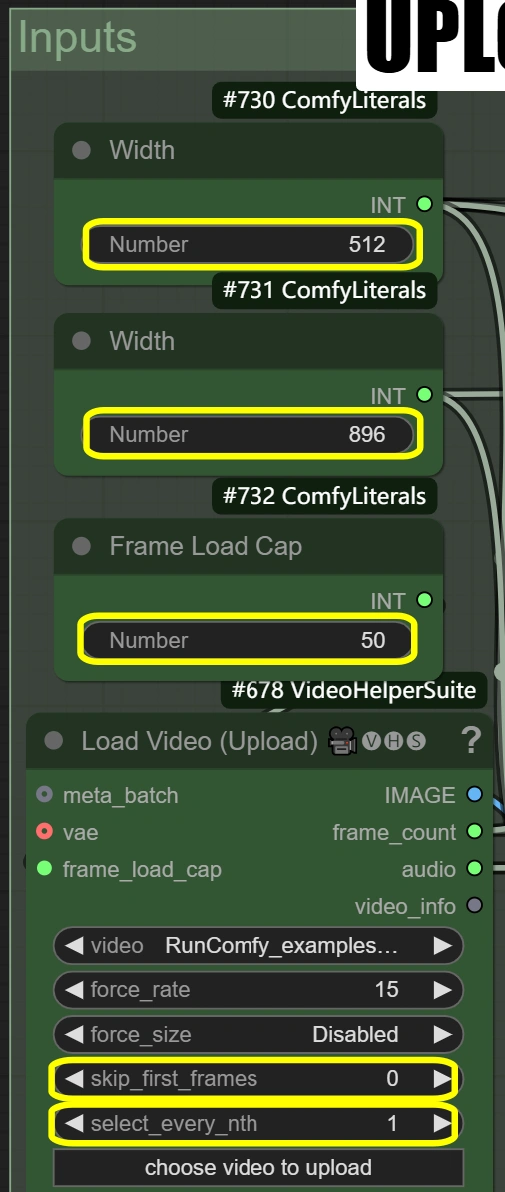
- Carica Video:
- Frame Load Cap:
- Controlla il numero di frame da elaborare
- 50 = test rapido (elabora ~2 secondi)
- 0 = elabora l'intero video
- Influisce sul tempo totale di elaborazione
- Skip First Frames:
- Definisce il punto di partenza nel video
- Più alto = inizia più avanti nel video
- Utile per saltare intro
- Select Every Nth:
- Controlla il tasso di campionamento dei frame
- Numeri più alti saltano i frame
- 1 = usa ogni frame
- 2 = usa ogni secondo frame, ecc.
- Frame Load Cap:
- Scala Immagine:
- Width: 512
- Controlla la larghezza del frame di output
- Deve mantenere il rapporto 9:16 con l'altezza
- Height: 896
- Controlla l'altezza del frame di output
- Deve mantenere il rapporto 9:16 con la larghezza
- Method: nearest-exact
- Migliore per mantenere la nitidezza
- Alternative possono sfocare il contenuto
- Consigliato per video di danza
- Non cambiare a meno di esigenze specifiche
- Width: 512
- VAE Loader:
- Model: vae-ft-mse-840000-ema-pruned
- Ottimizzato per stabilità e qualità
- Gestisce la codifica/decodifica delle immagini
- Rapporto di compressione bilanciato
- Non cambiare a meno di esigenze specifiche
- VAE Mode: Non cambiare
- Ottimizzato per il flusso di lavoro attuale
- Influisce sulla qualità di codifica
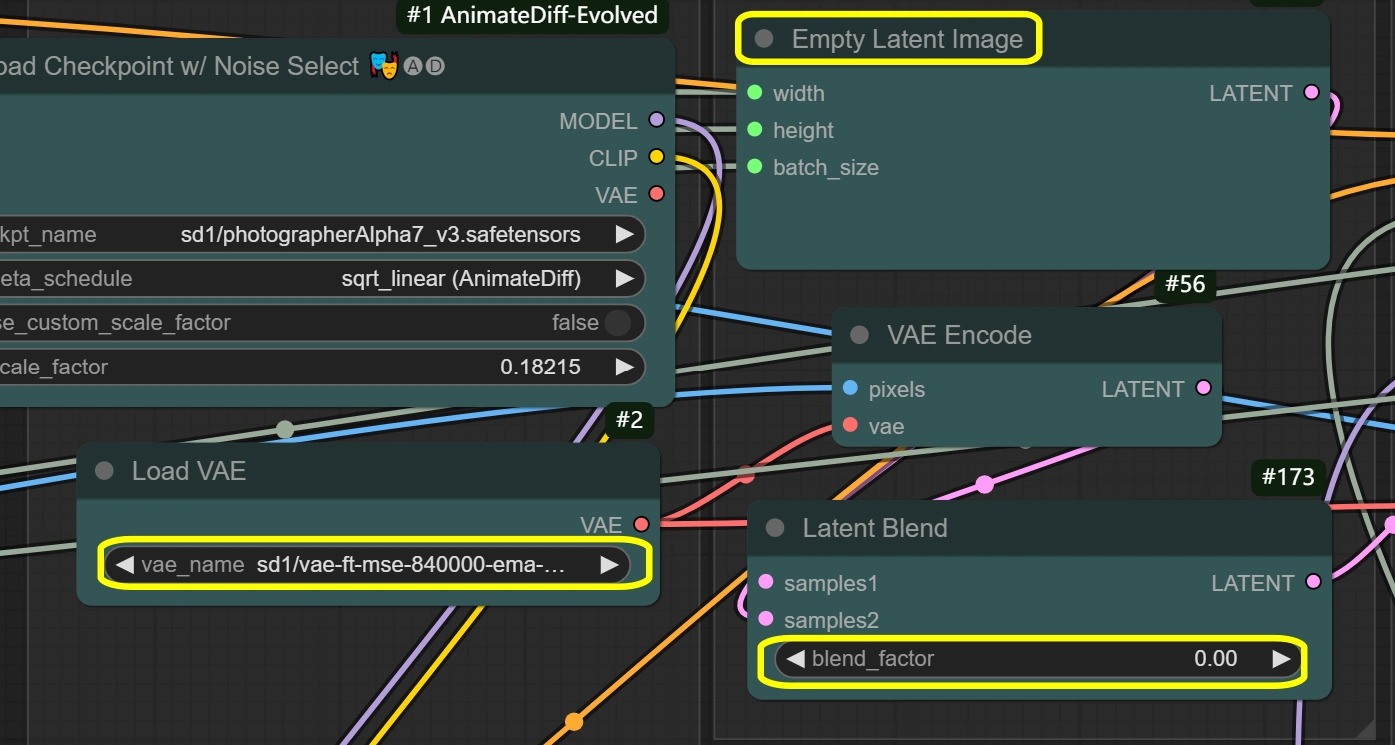
- Model: vae-ft-mse-840000-ema-pruned
Elaborazione Latente
Scopo: Gestisce tutte le operazioni e trasformazioni nello spazio latente.
- Immagine Latente Vuota:
- Width/Height: corrisponde all'input
- Deve corrispondere alle dimensioni della Scala Immagine
- Influisce direttamente sull'uso della memoria
- Dimensioni più grandi richiedono più VRAM
- Non può essere più piccolo dell'input
- Batch Size: dai frame video
- Impostato automaticamente dal conteggio dei frame
- Influisce sulla velocità di elaborazione e VRAM
- Più alto = più memoria necessaria
- Width/Height: corrisponde all'input
- Codifica VAE:
- VAE Model: dal VAE Loader
- Utilizza le impostazioni del VAE Loader
- Mantiene la coerenza
- Decode: abilitato
- Controlla la qualità della decodifica
- Disabilita solo se VRAM limitata
- Influisce sulla qualità dell'output
- VAE Model: dal VAE Loader
- Fusione Latente:
- Fattore di Fusione:
- Controlla la miscelazione degli spazi latenti
- 0 = contenuto sorgente completo
- Più alto = più influenza latente vuota
- Influisce sulla forza del trasferimento di stile
- Fattore di Fusione:
- Upscale Latente Di:
- Metodo: nearest-exact
- Migliore per mantenere la nitidezza
- Metodi alternativi possono sfocare
- Preserva i dettagli del movimento
- Scala:
- Controlla l'aumento delle dimensioni
- Più alto = migliore dettaglio ma più VRAM
- Più basso = elaborazione più veloce
- 1.6 ottimale per la maggior parte dei casi
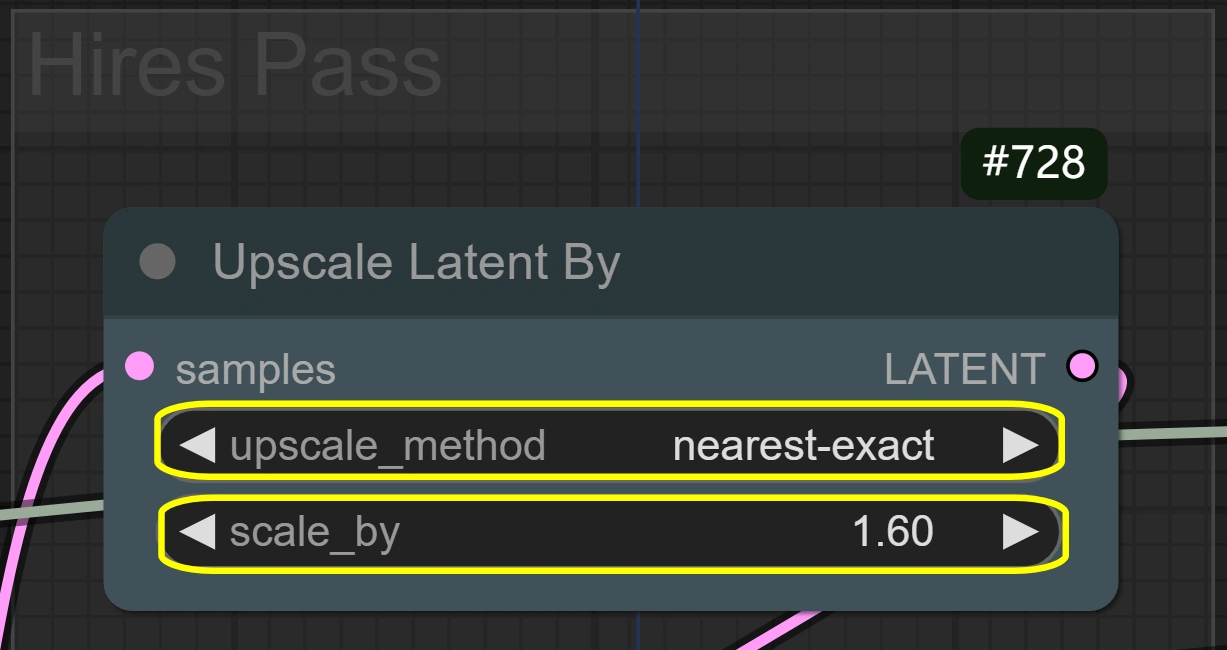
- Metodo: nearest-exact
Campionamento & Raffinamento
Scopo: Processo di campionamento a due fasi per la trasformazione di qualità.
- KSampler (Primo Passaggio):
- Steps:
- Numero di passaggi di denoising
- Più alto = migliore qualità ma più lento
- 6 ottimale per lcm sampler
- CFG:
- Controlla l'influenza del prompt
- Più alto = maggiore aderenza allo stile
- Più basso = più libertà
- Sampler: lcm
- Ottimizzato per velocità
- Buon equilibrio qualità/velocità
- Scheduler: sgm_uniform
- Funziona meglio con lcm
- Mantiene la coerenza temporale
- Denoise:
- Piena forza per il primo passaggio
- Controlla l'intensità della trasformazione
- Steps:
- KSampler (Passaggio Hires):
- Steps:
- Corrisponde al primo passaggio per coerenza
- Più alto non necessario per il raffinamento
- CFG:
- Mantiene la coerenza dello stile
- Conservazione equilibrata dei dettagli
- Sampler: lcm
- Stesso del primo passaggio
- Mantiene la coerenza
- Scheduler: sgm_uniform
- Mantiene la coerenza con il primo passaggio
- Buono per il raffinamento dei dettagli
- Denoise:
json
- Inferiore al primo passaggio
- Preserva più dettagli originali
- Buon equilibrio per il raffinamento
- Steps:
Elaborazione dell'Output
Scopo: Crea output video finali con e senza face swap.
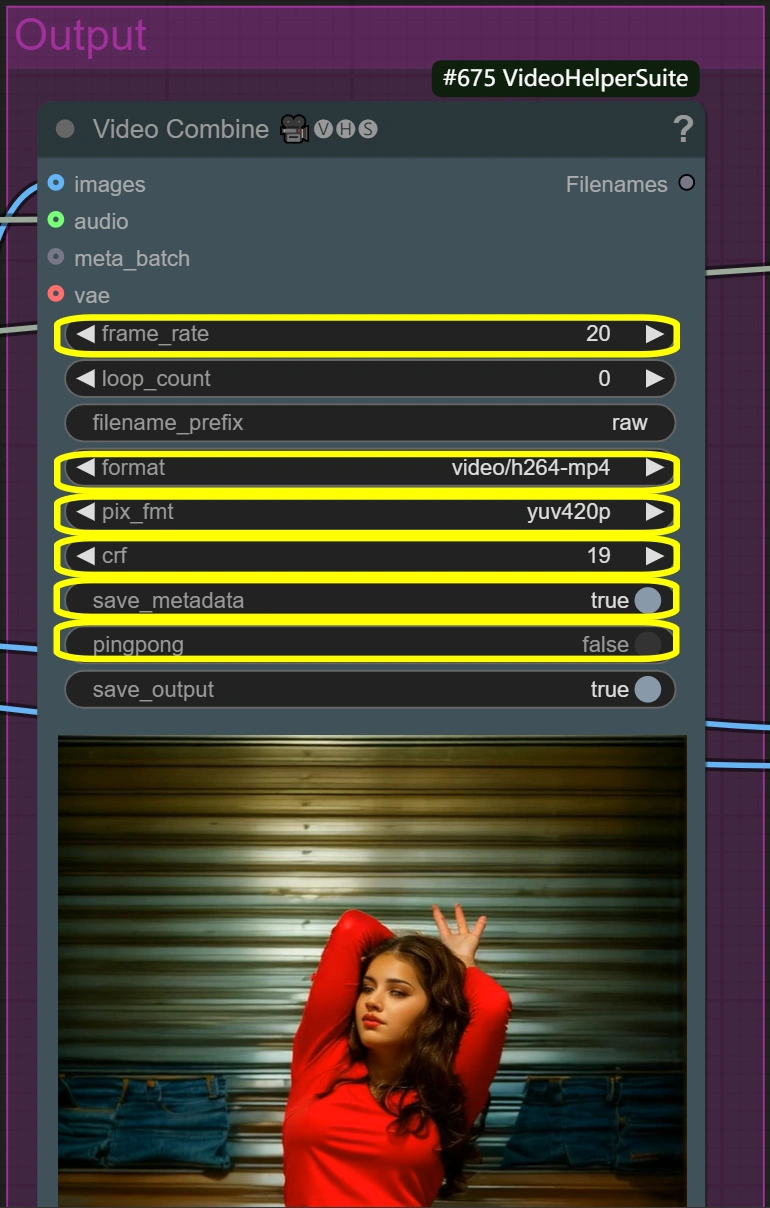
- Combinazione Video (Raw):
- Frame Rate:
- Frame rate standard video
- Controlla la velocità di riproduzione
- Inferiore = dimensione del file più piccola
- Superiore = movimento più fluido
- Formato: video/h264-mp4
- Formato standard per compatibilità
- Buon equilibrio qualità/dimensione
- Ampiamente supportato
- CRF:
- Controlla la qualità della compressione
- Inferiore = migliore qualità ma file più grande
- Superiore = file più piccolo ma qualità inferiore
- 19 è impostazione di alta qualità
- Formato Pixel: yuv420p
- Formato standard per compatibilità
- Non cambiare se non necessario
- Assicura ampio supporto alla riproduzione
- Frame Rate:
- Combinazione Video (Face Swap):
- Stessi parametri dell'output raw
- Utilizza impostazioni identiche per coerenza
- Aggiunge integrazione face swap
- Mantiene le impostazioni di qualità video
Consigli di Ottimizzazione
Compromessi Qualità vs Velocità
- Bilanciamento Risoluzione:
- Standard: 512x896
- Elaborazione più veloce
- Buono per la maggior parte degli usi
- Alta Qualità: 768x1344
- Maggiore dettaglio
- Tempo di elaborazione 2-3 volte più lungo
- Standard: 512x896
- Qualità Face Swap:
- Standard: Impostazioni predefinite
- Integrazione naturale
- Tempo di elaborazione bilanciato
- Qualità Massima:
- Aumenta codeformer_fidelity a 0.9
- Più lento ma volti più dettagliati
- Standard: Impostazioni predefinite
- Fluidità del Movimento:
- Elaborazione più Veloce:
- Riduci context_overlap a 2
- Transizioni leggermente meno fluide
- Miglior Movimento:
- Aumenta overlap a 6
- Usa più VRAM, elaborazione più lenta
- Elaborazione più Veloce:
Problemi Comuni & Soluzioni
- Fusione del Viso:
- Problema: Transizione del viso innaturale
- Soluzione: Regola codeformer_weight
- Prova intervallo 0.4-0.7
- Inferiore = migliore fusione
- Superiore = più dettagli del viso
- Forza dello Stile:
- Problema: Trasferimento di stile debole
- Soluzione: Aumenta cfg
- Prova intervallo 7-8
- Superiore = stile più forte
- Può influire sulla qualità del movimento
- Gestione della Memoria:
- Problema: Limitazioni VRAM
- Soluzioni:
- Abilita slicing VAE
- Riduci risoluzione
- Elabora segmenti più brevi
Maggiori Informazioni
Per ulteriori dettagli e creazioni sorprendenti, visita .
