EchoMimic | Animazioni di Ritratti Guidate dall'Audio
EchoMimic è uno strumento che ti consente di creare teste parlanti realistiche e gesti del corpo che si sincronizzano perfettamente con l'audio fornito. Sfruttando tecniche avanzate di intelligenza artificiale, EchoMimic analizza l'input audio e genera espressioni facciali realistiche, movimenti delle labbra e linguaggio del corpo che si abbinano perfettamente alle parole e alle emozioni espresse. Con EchoMimic, puoi dare vita ai tuoi personaggi e creare contenuti animati che catturano l'attenzione del tuo pubblico.ComfyUI EchoMimic Flusso di lavoro
- Workflow completamente operativi
- Nessun nodo o modello mancante
- Nessuna configurazione manuale richiesta
- Presenta visuali mozzafiato
ComfyUI EchoMimic Esempi
ComfyUI EchoMimic Descrizione
EchoMimic è uno strumento per generare animazioni di ritratti guidate dall'audio estremamente realistiche. Utilizza tecniche di deep learning per analizzare l'audio di input e generare espressioni facciali, movimenti delle labbra e gesti della testa corrispondenti che si abbinano strettamente al contenuto emotivo e fonetico del discorso.
EchoMimic V2 è stato sviluppato da un team di ricercatori del Terminal Technology Department di Alipay, Ant Group, inclusi Rang Meng, Xingyu Zhang, Yuming Li e Chenguang Ma. Per informazioni dettagliate, visita /. Il nodo ComfyUI_EchoMimic è stato sviluppato da /. Tutto il merito va al loro significativo contributo.
EchoMimic V1 e V2
- EchoMimic V1: Animazioni di Ritratti Guidate dall'Audio Realistiche con Controllo Personalizzabile dei Landmark
- EchoMimic V2: Animazioni Umane Semplificate, Espressive e Semi-Corpo
La differenza principale è che EchoMimic V2 mira a ottenere sorprendenti animazioni umane a mezzo busto semplificando le condizioni di controllo non necessarie rispetto a EchoMimic V1. EchoMimic V2 utilizza una strategia innovativa di Armonizzazione Dinamica Audio-Postura per migliorare le espressioni facciali e i gesti del corpo.
Punti di Forza e Debolezze di EchoMimic V2
Punti di Forza:
- EchoMimic V2 genera animazioni di ritratti guidate dall'audio altamente realistiche ed espressive
- EchoMimic V2 estende l'animazione alla parte superiore del corpo, non solo alla regione della testa
- EchoMimic V2 riduce la complessità delle condizioni mantenendo la qualità dell'animazione rispetto a EchoMimic V1
- EchoMimic V2 incorpora senza soluzione di continuità i dati dei ritratti per migliorare le espressioni facciali
Debolezze:
- EchoMimic V2 richiede una fonte audio abbinata al ritratto per ottenere i migliori risultati
- EchoMimic V2 attualmente manca di codice di sincronizzazione delle pose, utilizzando un file di posa predefinito
- Generare animazioni più lunghe di alta qualità con EchoMimic V2 può essere intensivo dal punto di vista computazionale
- EchoMimic V2 funziona meglio su immagini di ritratti ritagliate piuttosto che su scatti a figura intera
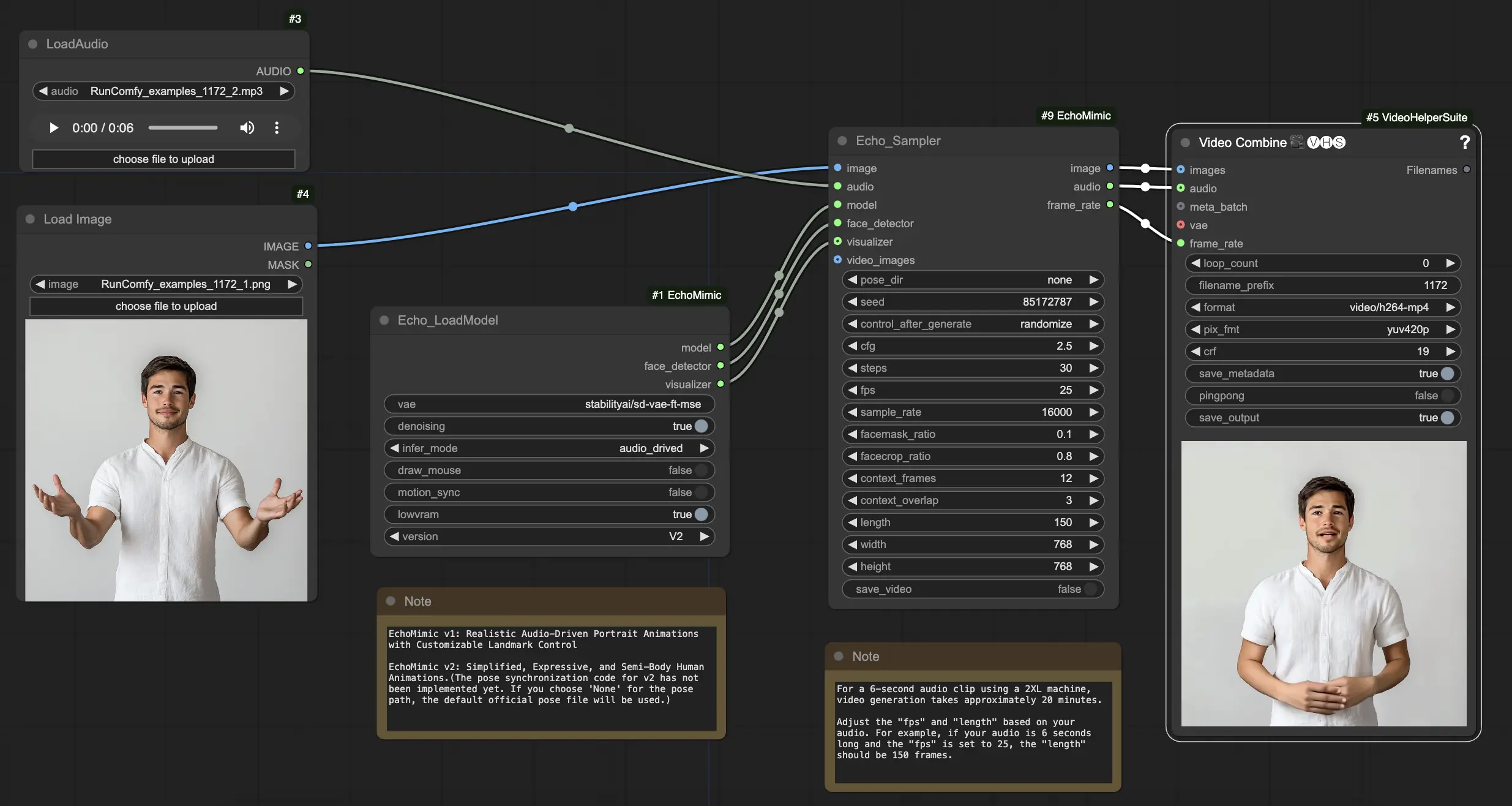
Come Usare il Workflow ComfyUI EchoMimic
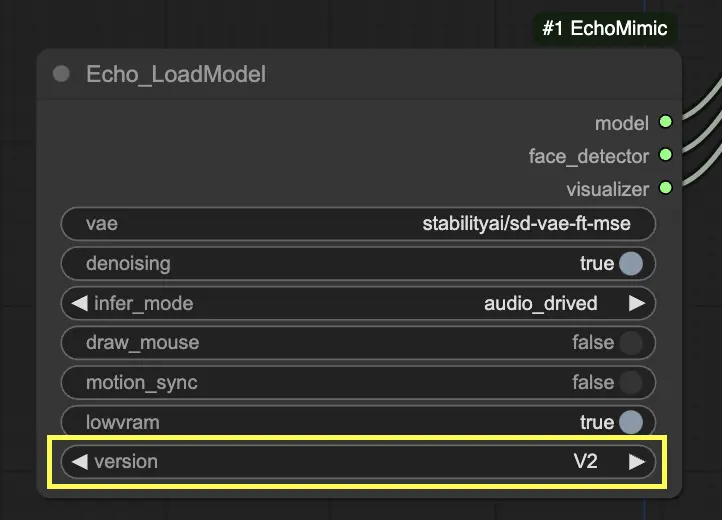
Nel nodo "Echo_LoadModel", hai l'opzione di selezionare tra EchoMimic v1 ed EchoMimic v2:
- EchoMimic v1: Questa versione si concentra sulla generazione di animazioni di ritratti guidate dall'audio realistiche con la possibilità di personalizzare il controllo dei landmark. È adatta per creare animazioni facciali realistiche che si abbinano strettamente all'audio di input.
- EchoMimic v2: Questa versione mira a semplificare il processo di animazione pur fornendo animazioni umane espressive e semi-corpo. Estende l'animazione oltre la sola regione facciale per includere i movimenti della parte superiore del corpo. Tuttavia, si prega di notare che la funzione di sincronizzazione delle pose per v2 non è ancora implementata nella versione attuale del workflow ComfyUI. Se selezioni 'None' per il percorso della posa, verrà utilizzato invece il file di posa ufficiale predefinito.
Ecco una guida passo-passo su come utilizzare il workflow ComfyUI fornito:
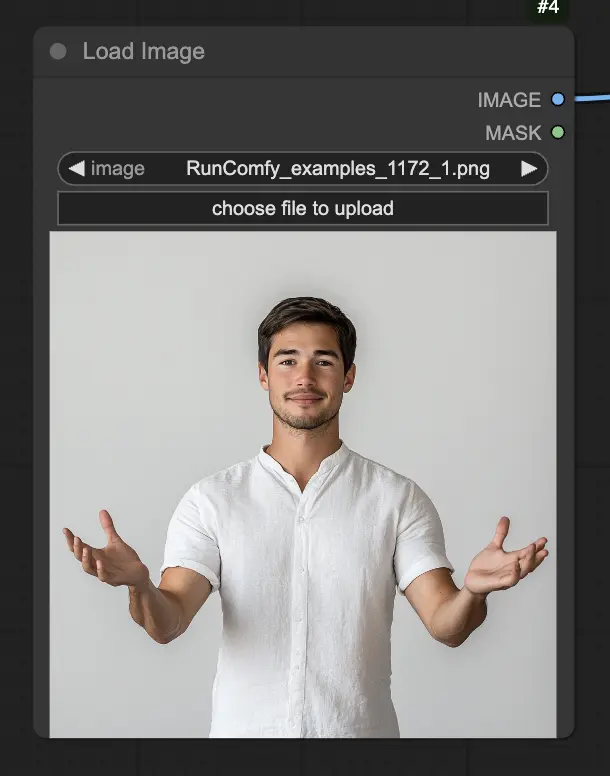
Passo 1. Carica la tua immagine del ritratto utilizzando il nodo LoadImage. Dovrebbe essere un'inquadratura ravvicinata della testa e delle spalle del soggetto.
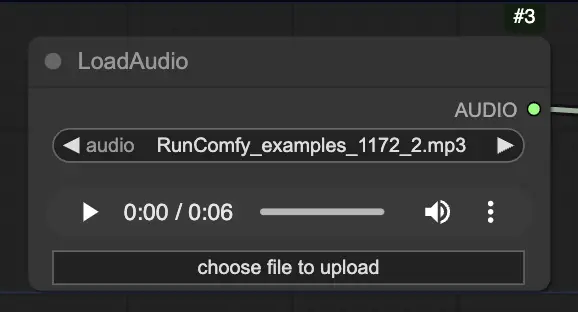
Passo 2. Carica il tuo file audio utilizzando il nodo LoadAudio. Il discorso nell'audio dovrebbe corrispondere all'identità del soggetto del ritratto.
Passo 3. Usa il nodo Echo_LoadModel per caricare il modello EchoMimic. Impostazioni chiave:
- Scegli la versione (V1 o V2).
- Seleziona la modalità di inferenza, ad es. modalità guidata dall'audio.
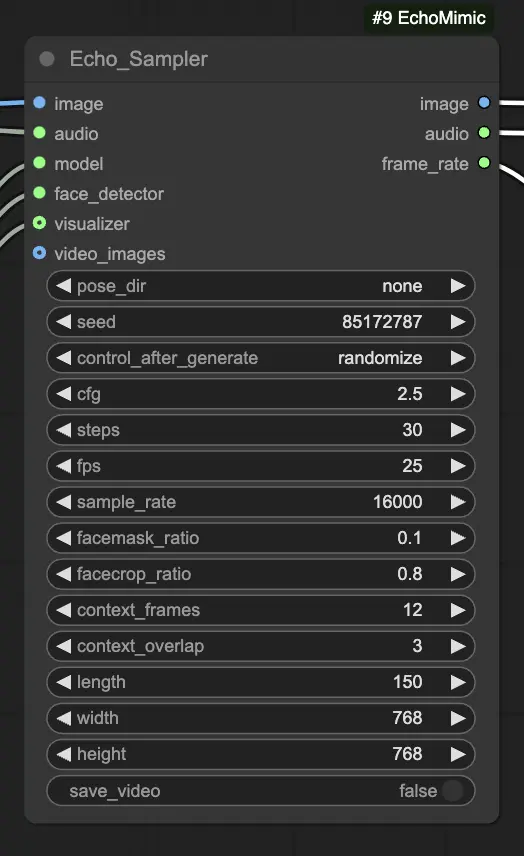
Passo 4. Collega l'immagine, l'audio e il modello caricato al nodo Echo_Sampler. Impostazioni chiave:
- pose_dir: Il percorso della directory per i file della sequenza delle pose utilizzati nelle modalità di animazione guidate dalle pose. Se impostato su "none", non verrà utilizzata alcuna sequenza di pose.
- seed: Il seme casuale per generare risultati coerenti tra le esecuzioni. Dovrebbe essere un numero intero tra 0 e MAX_SEED.
- cfg: La scala di guida senza classificatore, che controlla la forza della condizione audio. Valori più alti producono movimenti guidati dall'audio più pronunciati. Il valore predefinito è 2.5, e può variare da 0.0 a 10.0.
- steps: Il numero di passaggi di diffusione per generare ciascun fotogramma. Valori più alti producono animazioni più fluide ma richiedono più tempo per essere generate. Il valore predefinito è 30, e può variare da 1 a 100.
- fps: Il frame rate del video di output in fotogrammi al secondo. Il valore predefinito è 25, e può variare da 5 a 100.
- sample_rate: La frequenza di campionamento dell'audio di input in Hz. Il valore predefinito è 16000, e può variare da 8000 a 48000 in incrementi di 1000.
- facemask_ratio: Il rapporto dell'area della maschera facciale rispetto all'area dell'immagine completa. Controlla la dimensione della regione intorno al volto che viene animata. Il valore predefinito è 0.1, e può variare da 0.0 a 1.0.
- facecrop_ratio: Il rapporto dell'area del ritaglio del volto rispetto all'area dell'immagine completa. Determina quanto dell'immagine è dedicato alla regione del volto. Il valore predefinito è 0.8, e può variare da 0.0 a 1.0.
- context_frames: Il numero di fotogrammi passati e futuri da utilizzare come contesto per generare ciascun fotogramma. Il valore predefinito è 12, e può variare da 0 a 50.
- context_overlap: Il numero di fotogrammi sovrapposti tra finestre di contesto adiacenti. Il valore predefinito è 3, e può variare da 0 a 10.
- length: La lunghezza del video di output in fotogrammi. Dovrebbe essere basata sulla durata del tuo audio di input e sull'impostazione fps. Ad esempio, se il tuo audio dura 6 secondi e l'fps è impostato su 25, la lunghezza dovrebbe essere di 150 fotogrammi. La lunghezza può variare da 50 a 5000 fotogrammi.
- width: La larghezza dei fotogrammi video di output in pixel. Il valore predefinito è 512, e può variare da 128 a 1024 in incrementi di 64.
- height: L'altezza dei fotogrammi video di output in pixel. Il valore predefinito è 512, e può variare da 128 a 1024 in incrementi di 64.
Si prega di notare che la generazione video può richiedere del tempo. Ad esempio, creare un video da una clip audio di 6 secondi utilizzando una macchina 2XL su RunComfy richiede circa 20 minuti.

