Hallo2 | Animazione di Ritratti Lip-Sync
Hallo2 è un modello AI avanzato che genera animazioni di ritratti di alta qualità, sincronizzate con le labbra, guidate da input audio. Utilizzando tecniche come modelli di diffusione, codifica audio e rilevamento del volto, Hallo2 crea animazioni in 4K con movimenti della bocca e espressioni accuratamente sincronizzati. Integrato perfettamente nel framework ComfyUI, Hallo2 consente agli utenti di creare animazioni di ritratti realistiche e sincronizzate con le labbra.ComfyUI Hallo2 Lip-Sync Flusso di lavoro
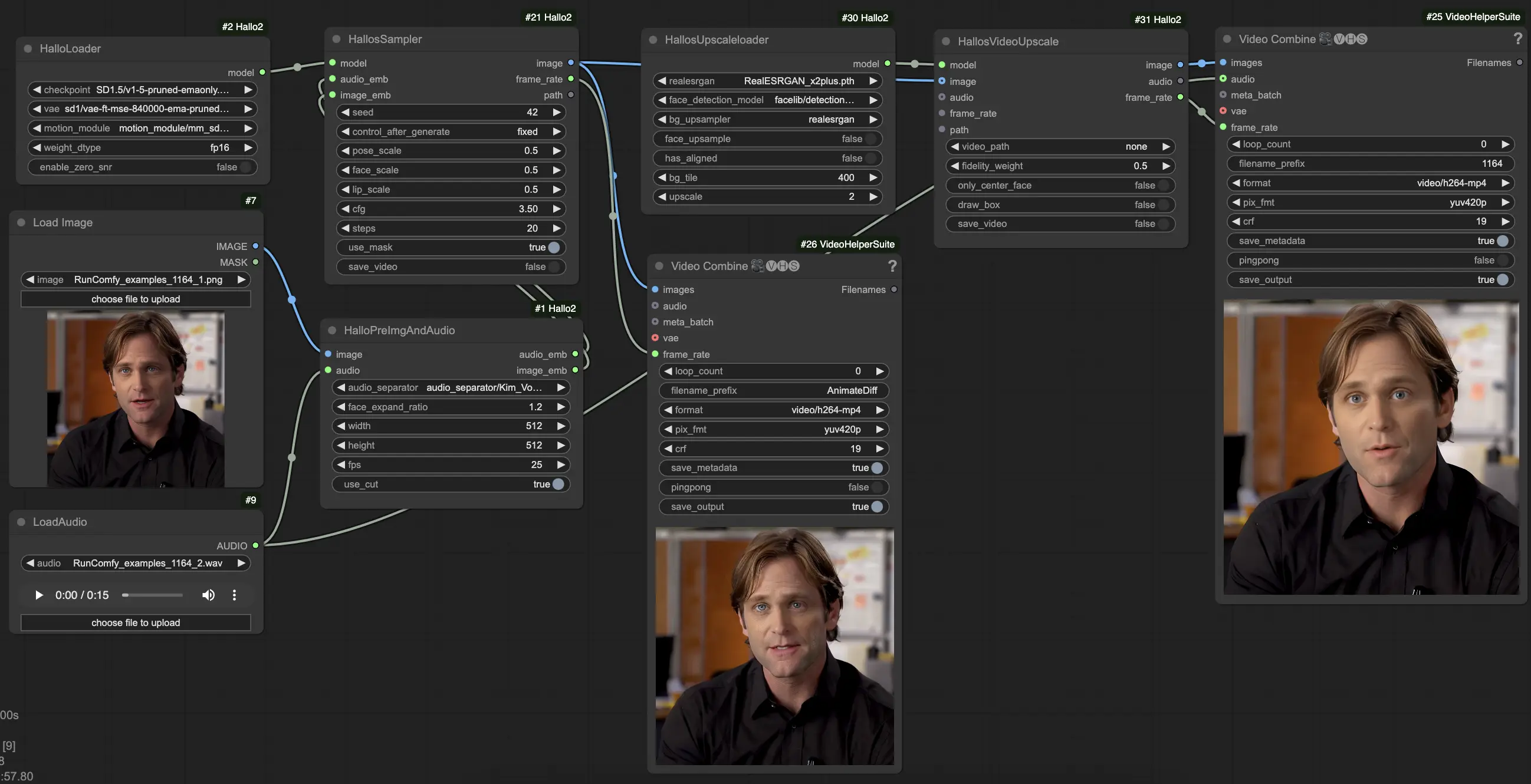
- Workflow completamente operativi
- Nessun nodo o modello mancante
- Nessuna configurazione manuale richiesta
- Presenta visuali mozzafiato
ComfyUI Hallo2 Lip-Sync Esempi
ComfyUI Hallo2 Lip-Sync Descrizione
La tecnica Hallo2 è stata sviluppata da Jiahao Cui, Hui Li, Yao Yao, Hao Zhu, Hanlin Shang, Kaihui Cheng, Hang Zhou, Siyu Zhu e Jingdong Wang della Fudan University e Baidu Inc. Per ulteriori informazioni, visita . I nodi e il flusso di lavoro ComfyUI_Hallo2 sono stati sviluppati da smthemex. Per maggiori dettagli, visita . Tutti i crediti per i loro contributi.
1. Informazioni su Hallo2
Hallo2 è un modello all'avanguardia per la generazione di video animati di ritratti guidati dall'audio di alta qualità, lunga durata e risoluzione 4K. Si basa sul modello originale Hallo con diversi miglioramenti chiave:
- Supporta la generazione di video molto più lunghi, fino a decine di minuti o addirittura ore
- Genera video in risoluzione 4K
- Permette di controllare espressione e posa utilizzando prompt testuali oltre all'audio
Hallo2 raggiunge questo obiettivo utilizzando tecniche avanzate come l'augmentazione dei dati per mantenere la coerenza su lunghe durate, la quantizzazione vettoriale dei codici latenti per la risoluzione 4K e un processo di denoising migliorato guidato sia dall'audio che dal testo.
2. Caratteristiche Tecniche di Hallo2
Hallo2 combina diversi modelli AI avanzati e tecniche per creare i suoi video di ritratti di alta qualità:
- Diffusion Model: Questo è il "motore" principale che genera i fotogrammi video. Inizia con rumore casuale e lo affina gradualmente per corrispondere all'output desiderato, guidato dai prompt audio e testuali.
- 3D U-Net: Questo è un tipo di rete neurale che funge da "scultore" nel processo di diffusione. Osserva il fotogramma rumoroso corrente, l'audio e le istruzioni testuali, e suggerisce come modificare il rumore per farlo sembrare più simile al ritratto finale.
- Audio Encoder: Hallo2 utilizza un modello chiamato Wav2Vec2 come "orecchie" per comprendere l'audio, convertendo la forma d'onda grezza in una rappresentazione compatta che cattura tono, velocità e contenuto del discorso.
- Face Detector: Per aiutare a focalizzarsi sull'animazione del volto, Hallo2 utilizza un modello di rilevamento del volto per localizzare automaticamente il volto del ritratto nell'immagine di riferimento. Sa quindi dove applicare i movimenti delle labbra e delle espressioni.
- Image Compressor: Per lavorare efficacemente con immagini ad alta risoluzione 4K, Hallo2 utilizza un tipo speciale di modello autoencoder (VQ-VAE) per comprimerle in una rappresentazione "latente" più piccola, e quindi decodificarle nuovamente a 4K alla fine. È come i JPEG che riducono le dimensioni dei file delle immagini preservando la qualità.
- Augmentation Tricks: Per mantenere la qualità su video lunghi, Hallo2 applica alcuni "augmentazioni dei dati" intelligenti ai fotogrammi generati precedentemente prima di usarli per influenzare il fotogramma successivo. Questi includono l'eliminazione occasionale di patch casuali o l'aggiunta di rumore sottile. Questo aiuta a prevenire errori cumulativi che altrimenti potrebbero accumularsi e rovinare la coerenza nel tempo.
In sintesi - Hallo2 prende in input audio e un'immagine di ritratto, ha un "agente" AI che scolpisce i fotogrammi video per abbinarli rimanendo fedele al ritratto originale, e impiega alcuni trucchi extra per mantenere tutto sincronizzato e coerente anche in video lunghi. Tutte queste parti lavorano insieme in una pipeline a più fasi per produrre i risultati impressionanti che vedi.
3. Come Usare il Flusso di Lavoro ComfyUI Hallo2
Hallo2 è stato integrato in ComfyUI tramite un flusso di lavoro personalizzato con diversi nodi specializzati. Ecco come usarlo:
- Carica la tua immagine di ritratto di riferimento usando il nodo
LoadImage. Deve essere un ritratto chiaro frontale. (Suggerimenti: Più il ritratto di riferimento è ben inquadrato e illuminato, migliori saranno i risultati. Evita profili laterali, occlusioni, sfondi occupati ecc.) - Carica il tuo audio guida usando il nodo
LoadAudio. Deve corrispondere all'umore che vuoi fare esprimere al ritratto. - Collega l'immagine e l'audio al nodo
HalloPreImgAndAudio. Questo preelabora l'immagine e l'audio in embeddings. Parametri chiave:audio_separator: Modello per separare il discorso dal rumore di fondo. Generalmente lasciare il valore predefinito.face_expand_ratio: Quanto espandere la regione del volto rilevato. Valori più alti includono più capelli/sfondo.width/height: Risoluzione di generazione. Valori più alti sono più lenti ma più dettagliati. 512-1024 quadrato è un buon equilibrio.fps: FPS video target. 25 è un buon valore predefinito.
- Carica il modello core Hallo2 usando il nodo
HalloLoader. Puntalo al tuo checkpoint Hallo2, VAE e file del modulo di movimento. - Collega l'immagine preelaborata e gli embeddings audio insieme al modello caricato al nodo
HalloSampler. Questo esegue la generazione video effettiva. Parametri chiave:seed: Seme casuale che determina dettagli minori. Cambialo se non ti piace il primo risultato.pose_scale/face_scale/lip_scale: Quanto scalare l'intensità di posa, espressione facciale e movimenti delle labbra. 1.0 = intensità piena, 0.0 = congelato.cfg: Scala di guida senza classificatore. Più alto = segue più da vicino il condizionamento ma è meno diversificato.steps: Numero di passaggi di denoising. Più passaggi = migliore qualità ma più lento.
- A questo punto, puoi visualizzare il video generato. Per migliorare ulteriormente la qualità con la super-risoluzione, aggiungi i nodi
HallosUpscaleloadereHallosVideoUpscalealla fine della catena. Il caricatore di upscaling legge in un modello di upscaling pre-addestrato, mentre il nodo di upscaling esegue effettivamente l'upscaling a 4K.



