LayerDiffuse | Da testo a immagine trasparente
Il modello LayerDiffuse introduce un nuovo approccio alla manipolazione delle immagini, consentendo la creazione diretta di immagini trasparenti. All'interno di questo flusso di lavoro ComfyUI LayerDiffuse, sono integrati tre sotto-flussi di lavoro specializzati: creazione di immagini trasparenti, generazione dello sfondo dal primo piano e il processo inverso di creazione del primo piano basato sullo sfondo esistente.ComfyUI LayerDiffuse Flusso di lavoro

- Workflow completamente operativi
- Nessun nodo o modello mancante
- Nessuna configurazione manuale richiesta
- Presenta visuali mozzafiato
ComfyUI LayerDiffuse Esempi

ComfyUI LayerDiffuse Descrizione
1. Panoramica del flusso di lavoro ComfyUI LayerDiffuse
Il flusso di lavoro ComfyUI LayerDiffuse integra tre sotto-flussi di lavoro specializzati: creazione di immagini trasparenti, generazione dello sfondo dal primo piano e il processo inverso di generazione del primo piano basato sullo sfondo esistente. Ognuno di questi sotto-flussi di lavoro LayerDiffuse opera in modo indipendente, offrendoti la flessibilità di scegliere e attivare la funzionalità specifica di LayerDiffuse che soddisfa le tue esigenze creative.
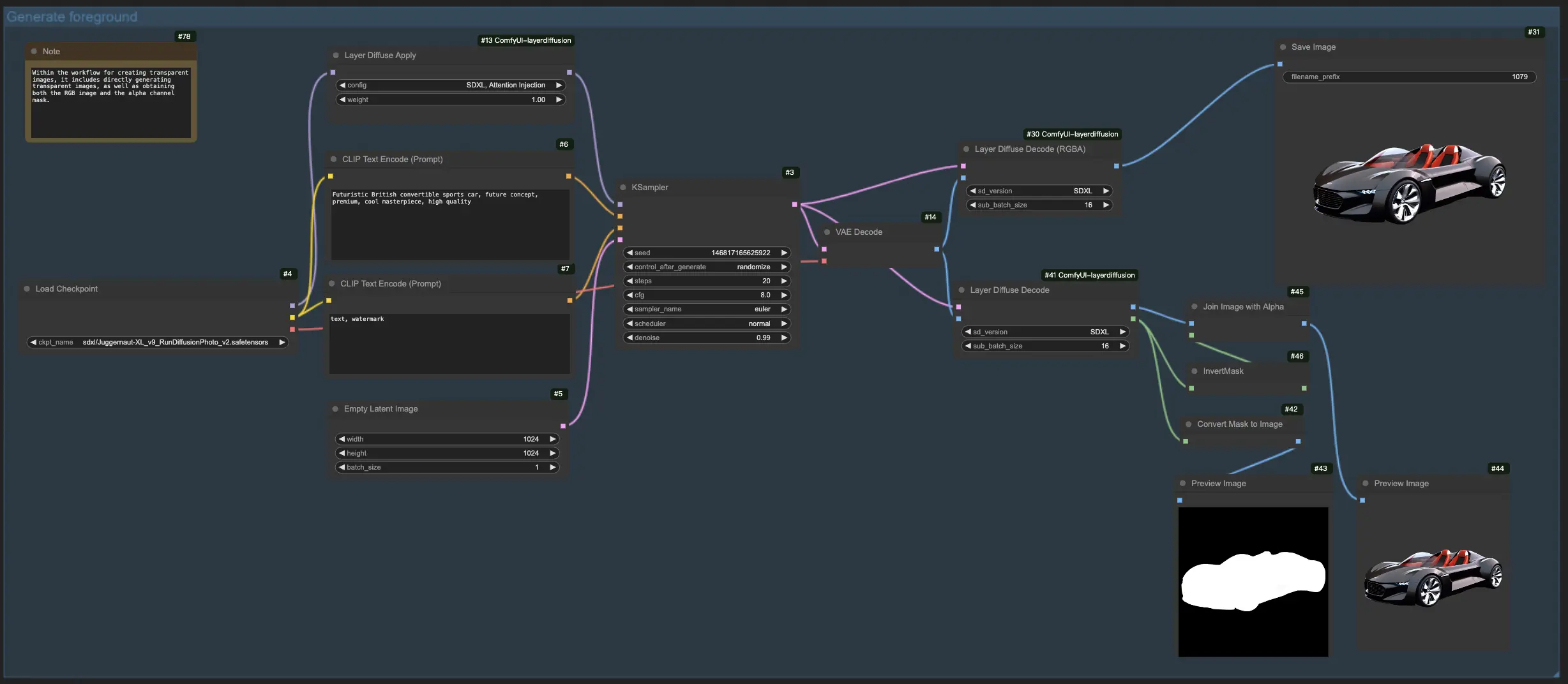
1.1. Creazione di immagini trasparenti con LayerDiffuse:
Questo flusso di lavoro consente la creazione diretta di immagini trasparenti, offrendoti la flessibilità di generare immagini con o senza specificare la maschera del canale alfa.
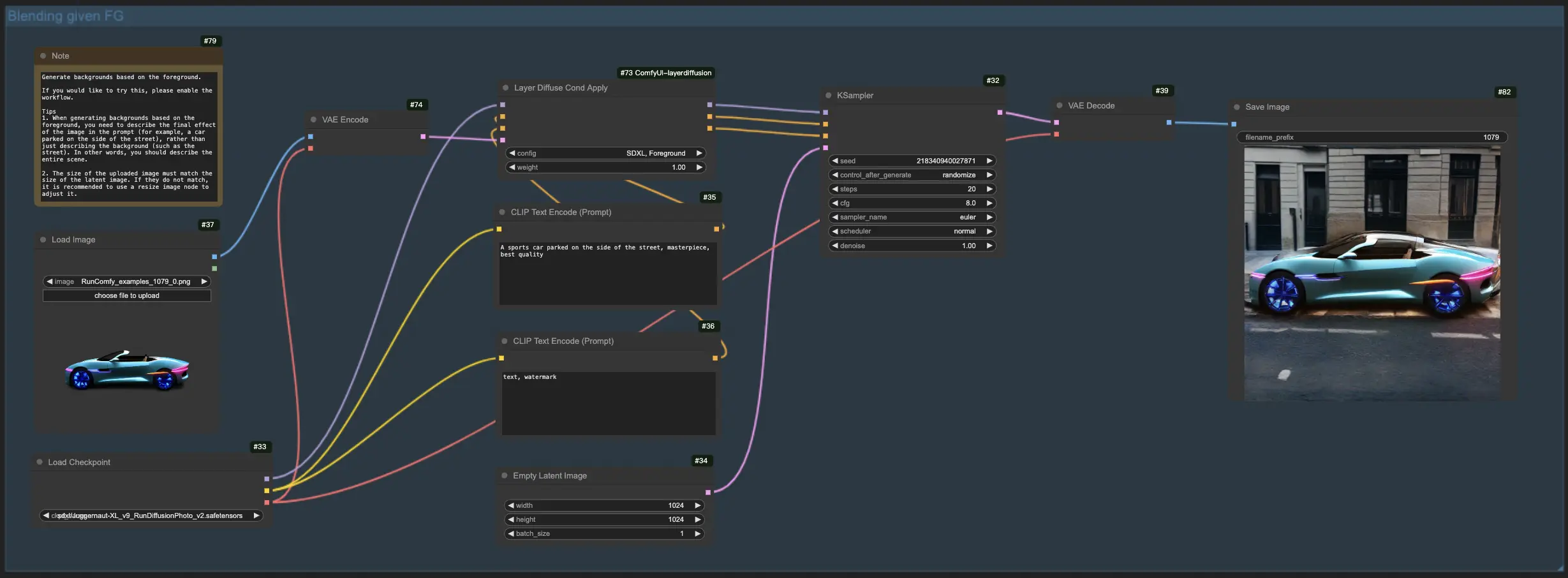
1.2. Generazione dello sfondo dal primo piano con LayerDiffuse:
Per questo flusso di lavoro LayerDiffuse, inizia caricando l'immagine in primo piano e creando un prompt descrittivo. LayerDiffuse quindi fonde questi elementi per produrre l'immagine desiderata. Quando stendi il tuo prompt per LayerDiffuse, è fondamentale descrivere l'intera scena (ad esempio, "un'auto parcheggiata sul lato della strada") invece di descrivere solo l'elemento dello sfondo (ad esempio, "la strada").
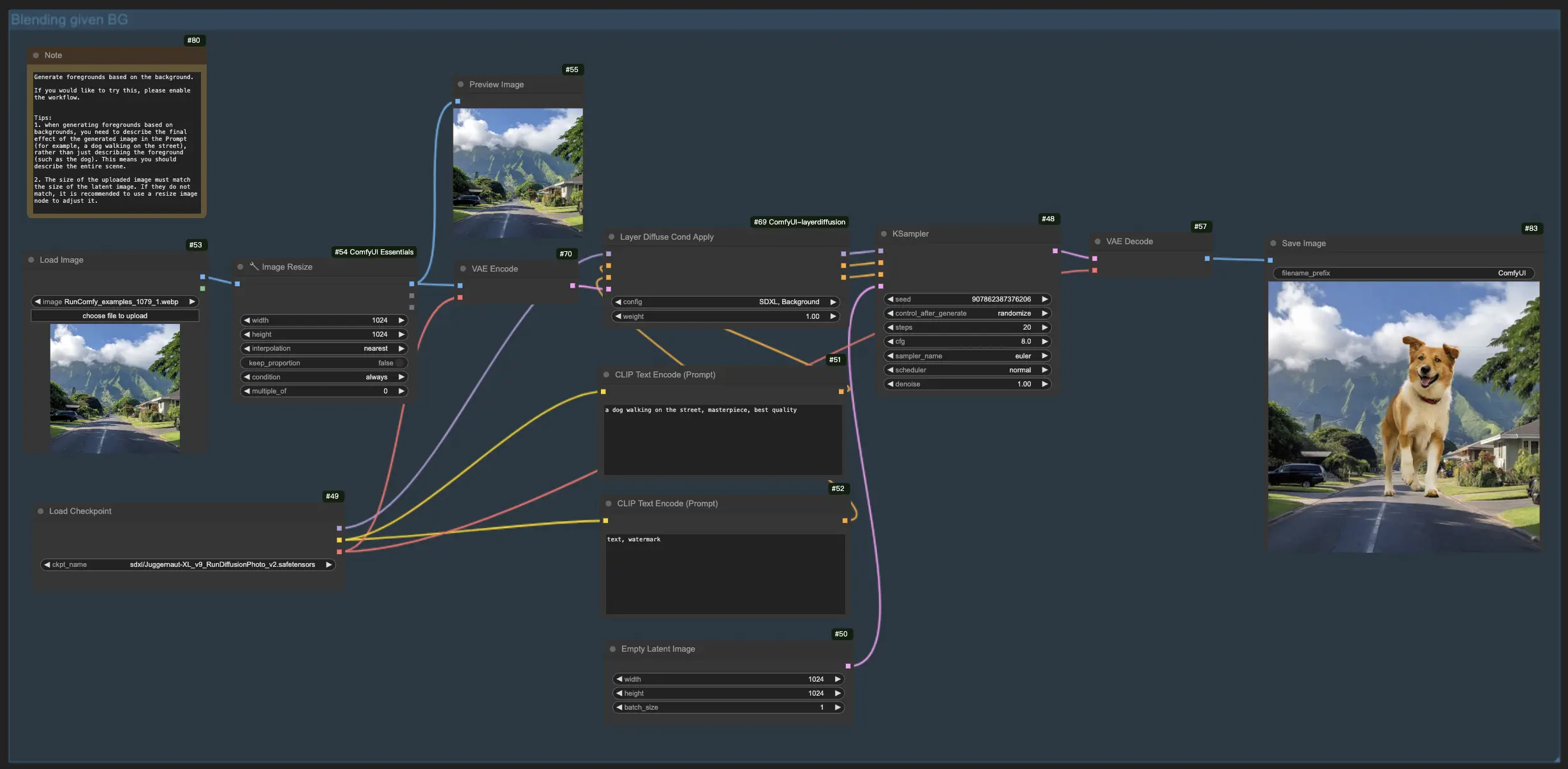
1.3. Generazione del primo piano basato sullo sfondo:
Rispecchiando il flusso di lavoro precedente, questa funzionalità LayerDiffuse inverte il focus, puntando a fondere gli elementi in primo piano con uno sfondo esistente. Pertanto, devi caricare l'immagine di sfondo e descrivere l'immagine finale prevista nel tuo prompt, enfatizzando l'intera scena (ad esempio, "un cane che cammina per strada") rispetto ai singoli elementi (ad esempio, "il cane").
Per ulteriori flussi di lavoro LayerDiffuse, controlla su
2. Efficacia del flusso di lavoro LayerDiffuse
Mentre il processo di creazione di immagini trasparenti è solido e produce risultati di alta qualità in modo affidabile, i flussi di lavoro per la fusione di sfondi e primi piani sono più sperimentali. Potrebbero non raggiungere sempre una fusione perfetta, indicativo della natura innovativa ma in via di sviluppo di questa tecnologia.
3. Introduzione tecnica a LayerDiffuse
LayerDiffuse è un approccio innovativo progettato per consentire ai modelli di diffusione latente pre-addestrati su larga scala di generare immagini con trasparenza. Questa tecnica introduce il concetto di "trasparenza latente", che comporta la codifica della trasparenza del canale alfa direttamente nel manifold latente dei modelli esistenti. Ciò consente la creazione di immagini trasparenti o di più livelli trasparenti senza alterare in modo significativo la distribuzione latente originale del modello pre-addestrato. L'obiettivo è mantenere l'output di alta qualità di questi modelli aggiungendo la capacità di generare immagini con trasparenza.
Per ottenere questo, LayerDiffuse affina i modelli di diffusione latente pre-addestrati regolando il loro spazio latente per includere la trasparenza come offset latente. Questo processo comporta modifiche minime al modello, preservando le sue qualità e prestazioni originali. L'addestramento di LayerDiffuse utilizza un dataset di 1 milione di coppie di livelli di immagini trasparenti, raccolte attraverso uno schema human-in-the-loop per garantire un'ampia varietà di effetti di trasparenza.
Il metodo si è dimostrato adattabile a vari generatori di immagini open source e può essere integrato in diversi sistemi di controllo condizionale. Questa versatilità consente una gamma di applicazioni, come la generazione di immagini con trasparenza specifica per primo piano/sfondo, la creazione di livelli con capacità di generazione congiunta e il controllo del contenuto strutturale dei livelli.





