AnimateDiff + ControlNet + IPAdapter V1 | Flat Anime Style
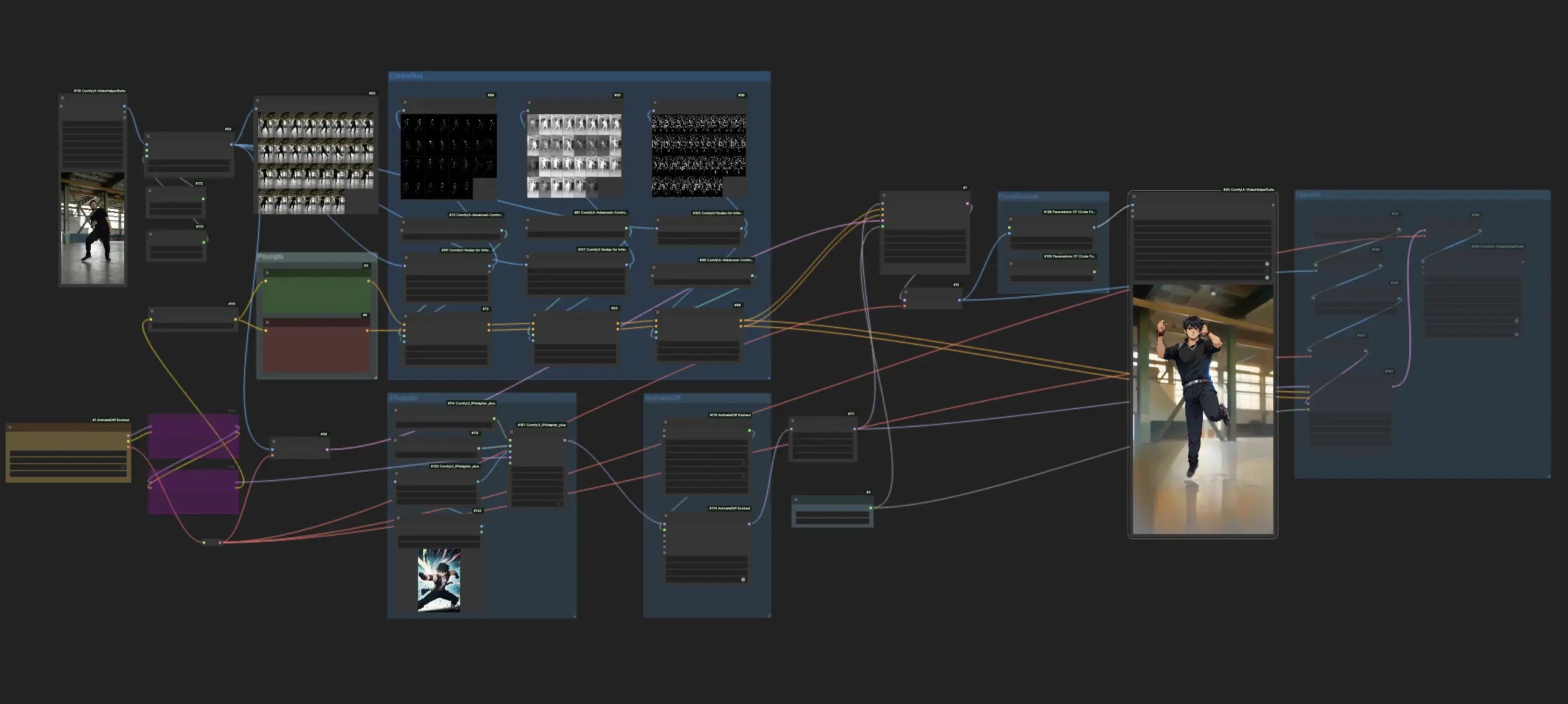
Questo workflow di ComfyUI utilizza AnimateDiff, ControlNet (incorporando Depth, Softedge e OpenPose), IPAdapter, Face Restore, Lora e altro, per convertire i contenuti video originali in un distintivo Flat Anime Style. Semplifica il processo, consentendo la creazione di video con un'estetica anime unica senza sforzo.ComfyUI Vid2Vid (Anime) Flusso di lavoro
- Workflow completamente operativi
- Nessun nodo o modello mancante
- Nessuna configurazione manuale richiesta
- Presenta visuali mozzafiato
ComfyUI Vid2Vid (Anime) Esempi
ComfyUI Vid2Vid (Anime) Descrizione
1. Workflow di ComfyUI: AnimateDiff + ControlNet + IPAdapter | Flat Anime Style
Questo workflow di ComfyUI utilizza AnimateDiff, ControlNet con Depth, Softedge, ecc., IPAdapter e FaceRestore per trasformare i contenuti video originali in un distintivo Flat Anime Style. Dopo aver ottenuto il risultato, puoi attivare i nodi di upscale per migliorare la risoluzione del tuo video.
2. Panoramica di AnimateDiff
Per favore, controlla i dettagli su
3. Panoramica di ControlNet
Per favore, controlla i dettagli su
4. Come usare Face Restore
"FaceRestore" in ComfyUI è un'estensione personalizzata progettata per ripristinare i volti nelle immagini. Sfrutta le capacità del modello CodeFormer per migliorare la fedeltà dell'immagine. Ecco le spiegazioni dettagliate.
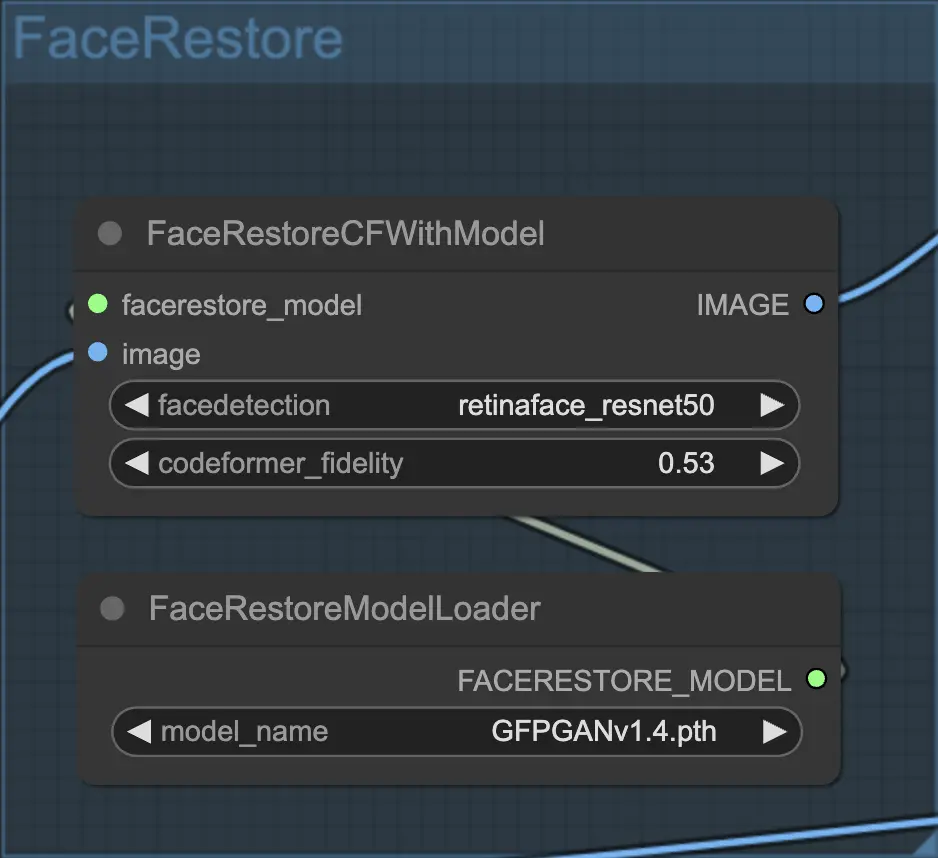
4.1. Input del nodo "Face Restore CF With Model"
facerestore_model: Specifica il modello di ripristino del volto da utilizzare. Questo è essenziale per definire l'algoritmo che verrà applicato per migliorare i volti nelle tue immagini.
image: Questa è l'immagine di input che contiene i volti che desideri ripristinare. Il nodo elaborerà questa immagine e applicherà il ripristino del volto sui volti rilevati.
facedetection: Scegli il modello di rilevamento del volto tra le seguenti opzioni. Questo modello è responsabile dell'identificazione e del ritaglio dei volti dall'immagine di input: Ognuna di queste opzioni ha i suoi punti di forza, con alcune più accurate mentre altre sono più veloci o più leggere in termini di risorse computazionali richieste.
- retinaface_resnet50
- retinaface_mobile0.25
- YOLOv5l
- YOLOv5n
codeformer_fidelity (FLOAT): Un parametro critico che ti permette di regolare la fedeltà del modello CodeFormer. Questa impostazione determina l'equilibrio tra il ripristino del volto con alta fedeltà all'originale e il miglioramento dell'immagine. Un valore più alto potrebbe conservare più caratteristiche originali, mentre un valore più basso potrebbe risultare in un ripristino più "idealizzato".
4.2. Output del nodo "Face Restore CF With Model"
IMAGE: L'output è l'immagine elaborata in cui i volti sono stati ripristinati. Questa immagine è il risultato del processo di ripristino del volto, mostrando una maggiore chiarezza, dettagli e una qualità visiva complessivamente migliorata dei volti rilevati nell'immagine di input.

