SDXL Turbo | Da Testo a Immagine Rapidamente
Questo workflow di ComfyUI sfrutta il modello SDXL Turbo per offrire un rapido processo di generazione da testo a immagine, richiedendo solo 1-4 passaggi. Per migliorare la stabilità e ottenere risultati migliori, integra anche un modello di ripristino del volto e un modello di upscale.ComfyUI SDXL Turbo Flusso di lavoro
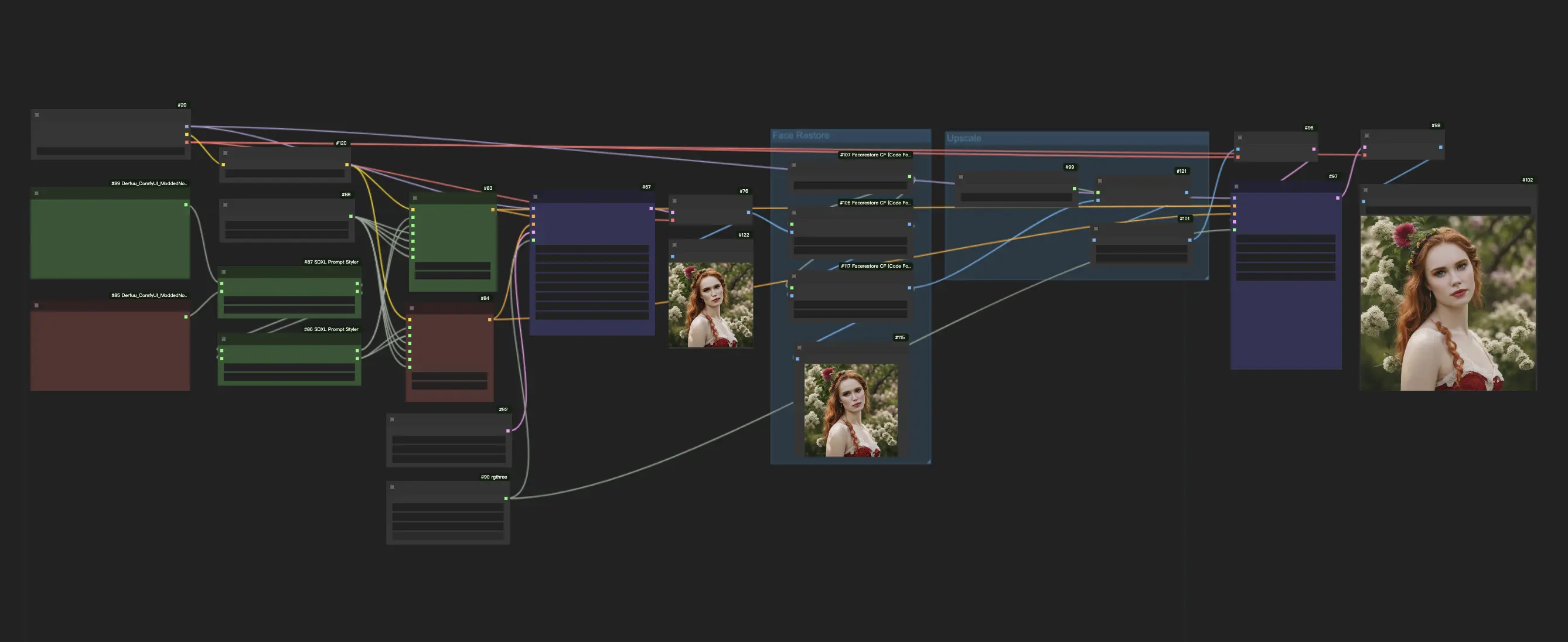
- Workflow completamente operativi
- Nessun nodo o modello mancante
- Nessuna configurazione manuale richiesta
- Presenta visuali mozzafiato
ComfyUI SDXL Turbo Esempi

ComfyUI SDXL Turbo Descrizione
1. Workflow SDXL Turbo di ComfyUI
SDXL Turbo sintetizza output di immagini in un singolo passaggio e genera output da testo a immagine in tempo reale. La qualità di SDXL Turbo è relativamente buona, anche se potrebbe non essere sempre stabile. Per migliorare i risultati, incorporare un modello di ripristino del volto e un modello di upscale per coloro che cercano risultati di qualità superiore.
2. Panoramica di SDXL Turbo
SDXL Turbo è un modello generativo da testo a immagine che converte in modo efficiente i prompt di testo in immagini fotorealistiche in una sola valutazione di rete. Sfruttando una tecnica chiamata Adversarial Diffusion Distillation (ADD), sviluppata da Stability AI, accorcia drasticamente il processo di sintesi dell'immagine a 1-4 passaggi, molto meno dei tradizionali 50 passaggi richiesti dai modelli precedenti. Questo modello, un avanzamento rispetto a SDXL 1.0, utilizza ADD per unire la distillazione del punteggio con una perdita avversaria, ottimizzando l'uso dei modelli di diffusione dell'immagine esistenti per una qualità superiore con meno passaggi di campionamento. L'introduzione di questa tecnica di distillazione non solo preserva la qualità dell'immagine, ma riduce anche significativamente lo sforzo computazionale necessario per la generazione dell'immagine.
3. Limitazioni di SDXL Turbo
Nonostante le sue capacità avanzate, SDXL Turbo ha alcune limitazioni. Genera immagini a una risoluzione fissa di 512x512 pixel e potrebbe avere difficoltà a eseguire il rendering di testo leggibile, a rappresentare accuratamente volti e persone e a raggiungere un fotorealismo perfetto. Questi vincoli sottolineano l'uso previsto del modello per la ricerca e l'esplorazione piuttosto che per rappresentazioni fattuali o accurate di entità del mondo reale.






