AnimateDiff + ControlNet + オートマスク | コミックスタイル
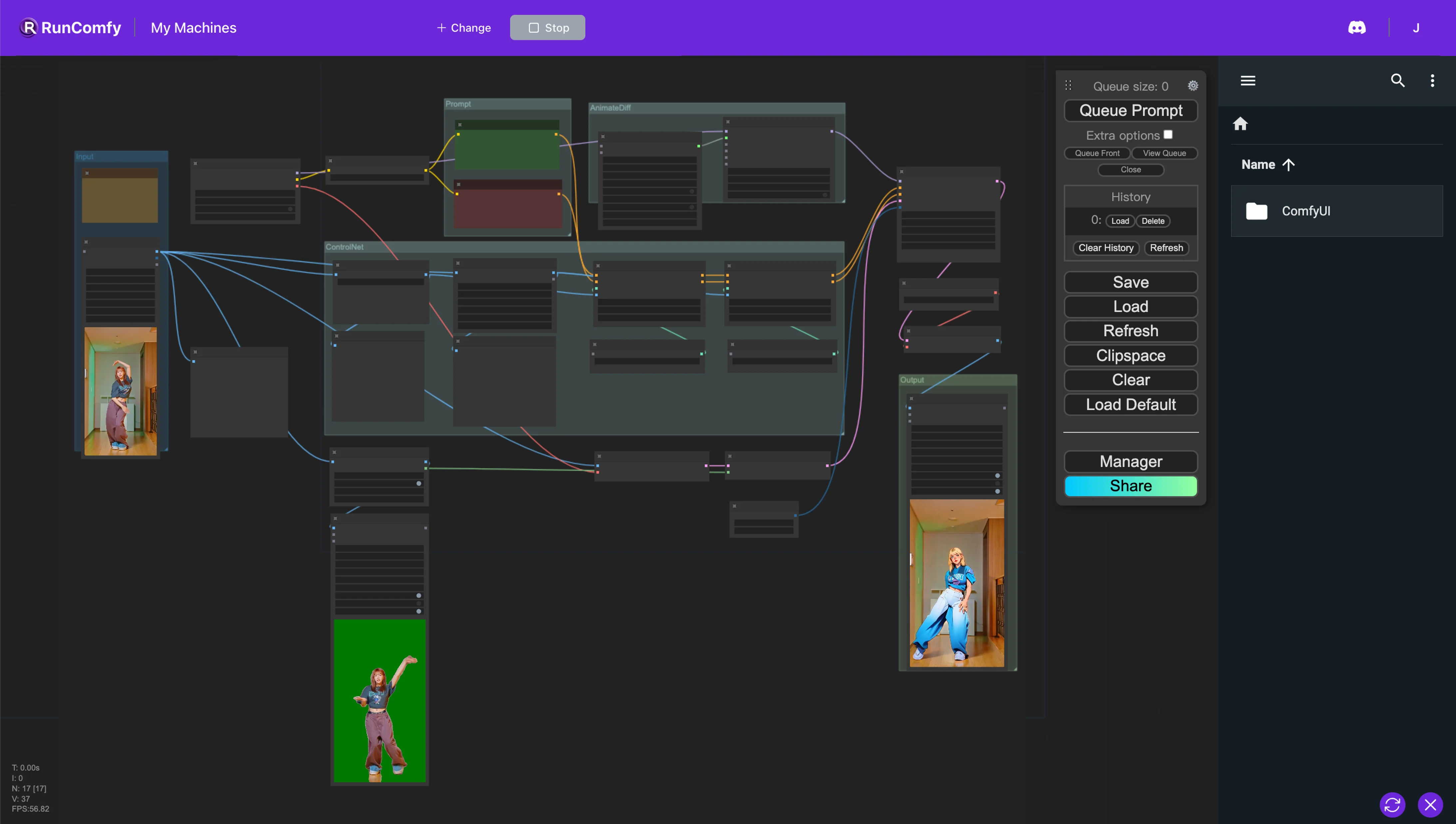
このComfyUIワークフローでは、Animatediff、ControlNet(深度とOpenPoseを特徴とする)、オートマスクなどのカスタムノードを利用して、動画をシームレスにスタイル変換します。このプロセスでは、リアルなキャラクターをアニメに変換しながら、元の背景を細心の注意を払って保持します。ComfyUI Vid2Vid ワークフロー
- 完全に動作するワークフロー
- 欠落したノードやモデルはありません
- 手動セットアップは不要
- 魅力的なビジュアルを特徴としています
ComfyUI Vid2Vid 例
ComfyUI Vid2Vid 説明
1. ComfyUI AnimateDiff、ControlNet、オートマスクのワークフロー
このComfyUIワークフローでは、キャラクターをアニメスタイルに変換しながら元の背景を保持することに特化した、動画のスタイル変換のための強力なアプローチを紹介します。この変換は、AnimateDiff、ControlNet、オートマスクなど、いくつかの重要なコンポーネントによってサポートされています。
AnimateDiffは、微分アニメーション技術用に設計されており、アニメーション内で一貫したコンテキストを維持することができます。このコンポーネントは、遷移をスムーズにし、スタイル変換された動画コンテンツの動きの流動性を高めることに重点を置いています。
ControlNetは、正確な人物のポーズの複製と操作において重要な役割を果たします。高度なポーズ推定を活用して人間の動きのニュアンスを正確に捉え、制御することで、キャラクターをアニメの形に変換しながら、元のポーズを保持します。
オートマスクは、自動セグメンテーションに関与し、キャラクターを背景から分離することに長けています。このテクノロジーにより、周囲の環境を変更することなくキャラクターの変換を実行し、元の背景の完全性を維持しながら、動画要素を選択的にスタイル変換できます。
このComfyUIワークフローは、標準の動画コンテンツをスタイル化されたアニメーションに変換し、アニメスタイルのキャラクター生成の効率と品質に重点を置いています。
2. AnimateDiffの概要
2.1. AnimateDiffの紹介
AnimateDiffは、Stable Diffusionモデルと専用のモーションモジュールを活用して、静止画やテキストプロンプトを動的な動画にアニメーション化するために設計されたAIツールとして登場しました。このテクノロジーは、フレーム間のシームレスな遷移を予測することでアニメーション処理を自動化し、無料のオンラインプラットフォームを通じて、コーディングスキルやコンピューティングリソースを必要とせずに、ユーザーがアクセスできるようにします。
2.2. AnimateDiffの主な特長
2.2.1. 包括的なモデルのサポート: AnimateDiffは、Stable Diffusion V1.5用のAnimateDiff v1、v2、v3や、Stable Diffusion SDXL用のAnimateDiff sdxlなど、さまざまなバージョンと互換性があります。複数のモーションモデルを同時に使用できるため、複雑で階層的なアニメーションを作成できます。
2.2.2. コンテキストバッチサイズによるアニメーションの長さの決定: AnimateDiffでは、コンテキストバッチサイズを調整することで、無限の長さのアニメーションを作成できます。この機能により、ユーザーは独自の要件に合わせてアニメーションの長さと遷移をカスタマイズでき、非常に適応性の高いアニメーション処理を提供します。
2.2.3. なめらかな遷移のためのコンテキスト長: AnimateDiffの「Uniform Context Length」の目的は、アニメーションの異なるセグメント間のシームレスな遷移を確保することです。「Uniform Context Length」を調整することで、ユーザーはシーン間の遷移のダイナミクスをコントロールできます。長さを長くするとよりスムーズでシームレスな遷移になり、短くするとより速くて顕著な変化になります。
2.2.4. モーションのダイナミクス: AnimateDiff v2では、アニメーションに映画的なカメラの動きを追加するための専用のモーションLoRAが利用できます。この機能は、アニメーションに動的なレイヤーを導入し、視覚的な魅力を大幅に高めます。
2.2.5. 高度なサポート機能: AnimateDiffは、ControlNet、SparseCtrl、IPAdapterなど、さまざまなツールと連携するように設計されており、プロジェクトの創造的な可能性を広げようとするユーザーに大きなメリットを提供します。
3. ControlNetの概要
3.1. ControlNetの紹介
ControlNetは、条件付き入力で画像拡散モデルを拡張するためのフレームワークを導入し、画像合成プロセスの改良と誘導を目的としています。これは、特定の拡散モデル内のニューラルネットワークブロックを2つのセットに複製することで実現します。1つは元の機能を保持するために「ロック」され、もう1つは提供された特定の条件に適応する「トレーナブル」になります。この二重構造により、開発者はOpenPose、Tile、IP-Adapter、Canny、Depth、LineArt、MLSD、Normal Map、Scribbles、Segmentation、Shuffle、T2I Adapterなどのモデルを使用して、さまざまな条件付き入力を組み込むことができ、生成される出力に直接影響を与えることができます。このメカニズムを通じて、ControlNetは開発者に画像生成プロセスを制御および操作するための強力なツールを提供し、拡散モデルの柔軟性とさまざまな創造的タスクへの適用性を高めます。
プリプロセッサとモデルの統合
3.1.1. 前処理の設定: ControlNetを開始するには、適切なプリプロセッサを選択する必要があります。プレビューオプションを有効にすると、前処理の影響を視覚的に理解できるため、お勧めです。前処理後、ワークフローは前処理された画像をさらなる処理ステップに使用するように移行します。
3.1.2. モデルのマッチング: モデル選択プロセスを簡素化するために、ControlNetは共有キーワードに基づいてモデルをそれに対応するプリプロセッサと整合させ、シームレスな統合プロセスを促進します。
3.2. ControlNetの主な特長
ControlNetモデルの詳細な探求
3.2.1. OpenPoseスイート: 正確な人物のポーズ検出用に設計されたOpenPoseスイートには、体のポーズ、表情、手の動きを例外的な精度で検出するためのモデルが含まれています。さまざまなOpenPoseプリプロセッサは、基本的なポーズ分析から表情や手のニュアンスの詳細な捕捉まで、特定の検出要件に合わせて調整されています。
3.2.2. Tile Resampleモデル: 画像の解像度と詳細を向上させるTile Resampleモデルは、視覚的完全性を損なうことなく画質を向上させることを目的として、アップスケーリングツールと併用するのに最適です。
3.2.3. IP-Adapterモデル: 画像をプロンプトとして革新的に使用できるようにするIP-Adapterは、参照画像からの視覚的要素を生成された出力に統合し、テキストから画像への拡散機能を統合して、視覚的コンテンツを充実させます。
3.2.4. Cannyエッジ検出器: そのエッジ検出能力で高く評価されているCannyモデルは、画像の構造的本質を強調し、コアの構成を維持しながら創造的な視覚的再解釈を可能にします。
3.2.5. 深度知覚モデル: さまざまな深度プリプロセッサを通じて、ControlNetは画像から深度の手がかりを導出して適用することに長けており、生成された視覚情報に階層的な深度の視点を提供します。
3.2.6. LineArtモデル: LineArtプリプロセッサを使用して画像を芸術的な線画に変換します。アニメからリアルなスケッチまで、さまざまな芸術的嗜好に対応し、ControlNetはスタイルの要望のスペクトルに対応します。
3.2.7. 落書き処理: Scribble HED、Pidinet、xDoGなどのプリプロセッサを使用して、ControlNetは画像を独特の落書きアートに変換し、エッジ検出と芸術的な再解釈のためのさまざまなスタイルを提供します。
3.2.8. セグメンテーション技術: ControlNetのセグメンテーション機能は、画像要素を正確に分類し、オブジェクトのカテゴリに基づいて正確な操作を可能にするため、複雑なシーン構築に理想的です。
3.2.9. Shuffleモデル: 配色の革新的な方法を導入するShuffleモデルは、入力画像をランダム化して新しい配色パターンを生成し、元の画像のエッセンスを保持しながら創造的に変更します。
3.2.10. T2I Adapterのイノベーション: Color GridやCLIP Vision Styleを含むT2I Adapterモデルは、ControlNetを新しい創造的領域に推し進め、色やスタイルをブレンドおよび適応させて、視覚的に魅力的な出力を生成します。これらの出力は、元の画像の配色やスタイルの属性を尊重します。
3.2.11. MLSD(Mobile Line Segment Detection): 直線の検出に特化したMLSDは、構造的な明快さと精度を優先する建築やインテリアデザインに焦点を当てたプロジェクトにとって非常に貴重です。
3.2.12. ノーマルマップ処理: 表面方向データを利用するノーマルマッププリプロセッサは、参照画像の3D構造を複製し、詳細な表面分析により生成されたコンテンツのリアリズムを高めます。
