AnimateDiff + ControlNet | セラミックアートスタイル
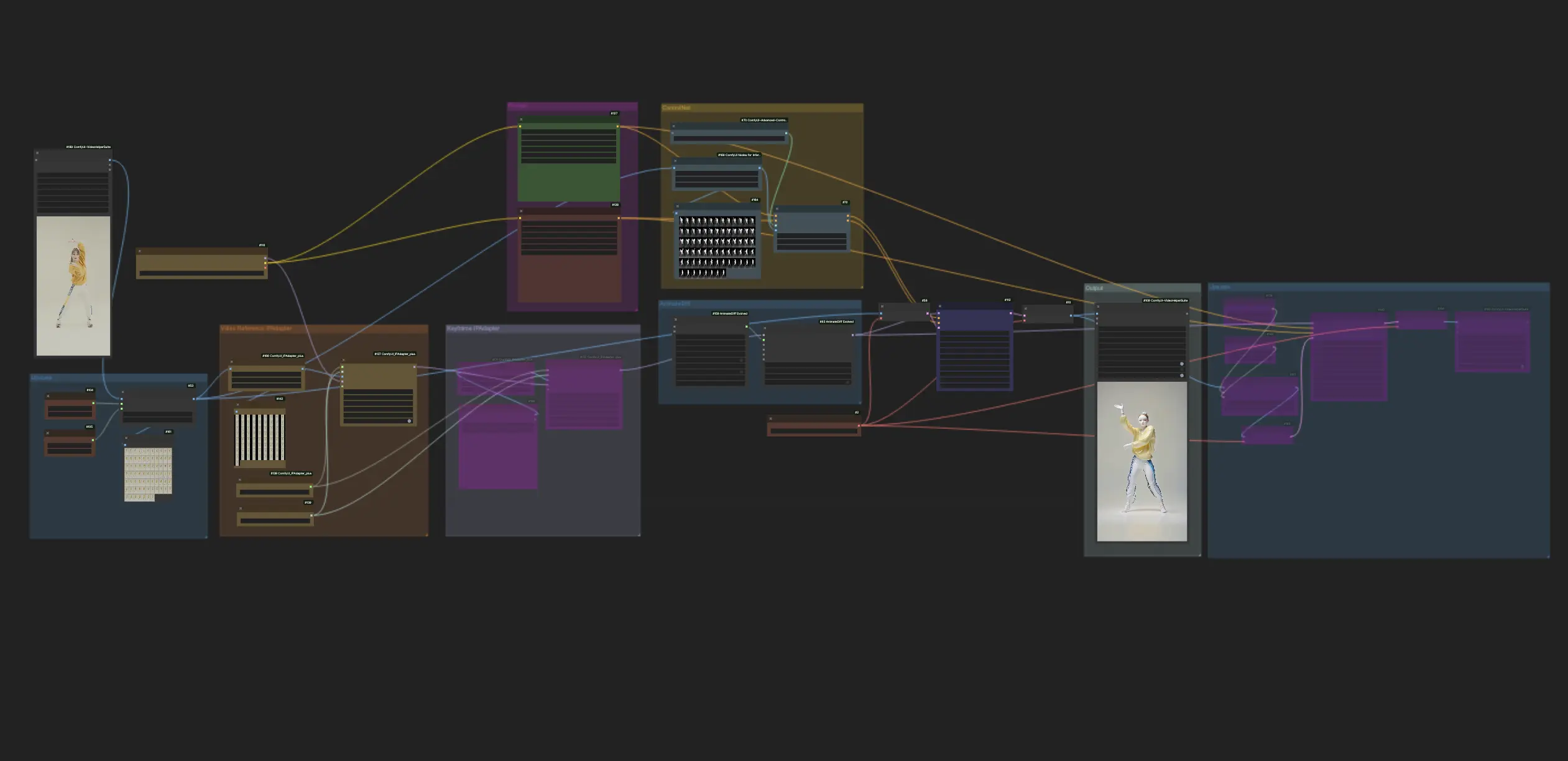
ComfyUI内のこのワークフローは、深度に焦点を当てたAnimateDiffとControlNet、その他Loraなどを使用して、ビデオをセラミックアートスタイルに巧みに変換します。これにより、オリジナルのコンテンツが独特の芸術的な雰囲気を採用し、効果的にセラミックアートの傑作の領域に高められます。ComfyUI Vid2Vid (Art) ワークフロー
- 完全に動作するワークフロー
- 欠落したノードやモデルはありません
- 手動セットアップは不要
- 魅力的なビジュアルを特徴としています
ComfyUI Vid2Vid (Art) 例
ComfyUI Vid2Vid (Art) 説明
1. ComfyUIワークフロー:AnimateDiff + ControlNet | セラミックアートスタイル
このワークフローは、深度に焦点を当てたAnimateDiff、ControlNet、および特定のLoraを利用して、ビデオをセラミックアートスタイルに巧みに変換します。様々なプロンプトを使用して多様なアートスタイルを実現し、アイデアを現実のものにすることをお勧めします。
2. AnimateDiffの使用方法
AnimateDiffは、Stable Diffusionモデルと専用のモーションモジュールを活用して、静止画とテキストプロンプトを動的なビデオにアニメーション化するように設計されています。フレーム間のシームレスな遷移を予測することでアニメーションプロセスを自動化し、コーディングスキルのないユーザーでも利用できるようにします。
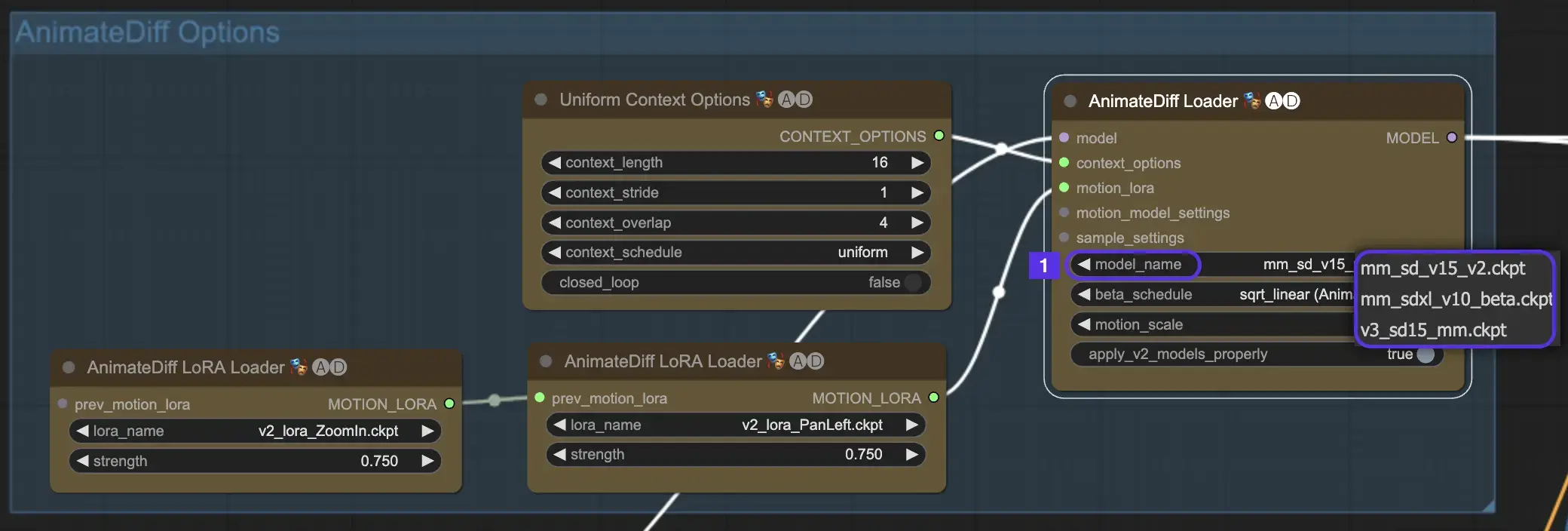
2.1 AnimateDiffモーションモジュール
始めるには、model_nameドロップダウンから目的のAnimateDiffモーションモジュールを選択します。
- AnimateDiff V3の場合はv3_sd15_mm.ckptを使用
- AnimateDiff V2の場合はmm_sd_v15_v2.ckptを使用
- AnimateDiff SDXLの場合はmm_sdxl_v10_beta.ckptを使用
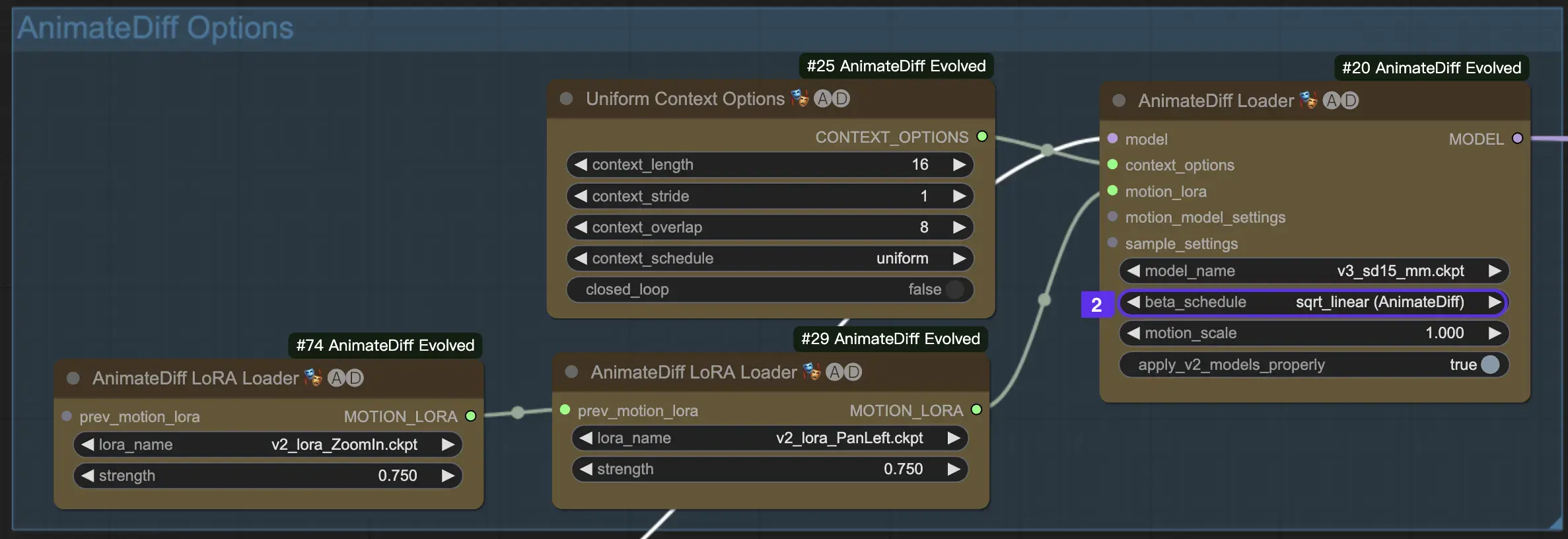
2.2 ベータスケジュール
AnimateDiffのベータスケジュールは、アニメーション作成全体でノイズ削減プロセスを調整するために重要です。
AnimateDiffのV3およびV2バージョンでは、sqrt_linear設定が推奨されますが、linear設定を試すとユニークな効果が得られる場合があります。
AnimateDiff SDXLでは、linear設定(AnimateDiff-SDXL)が推奨されます。
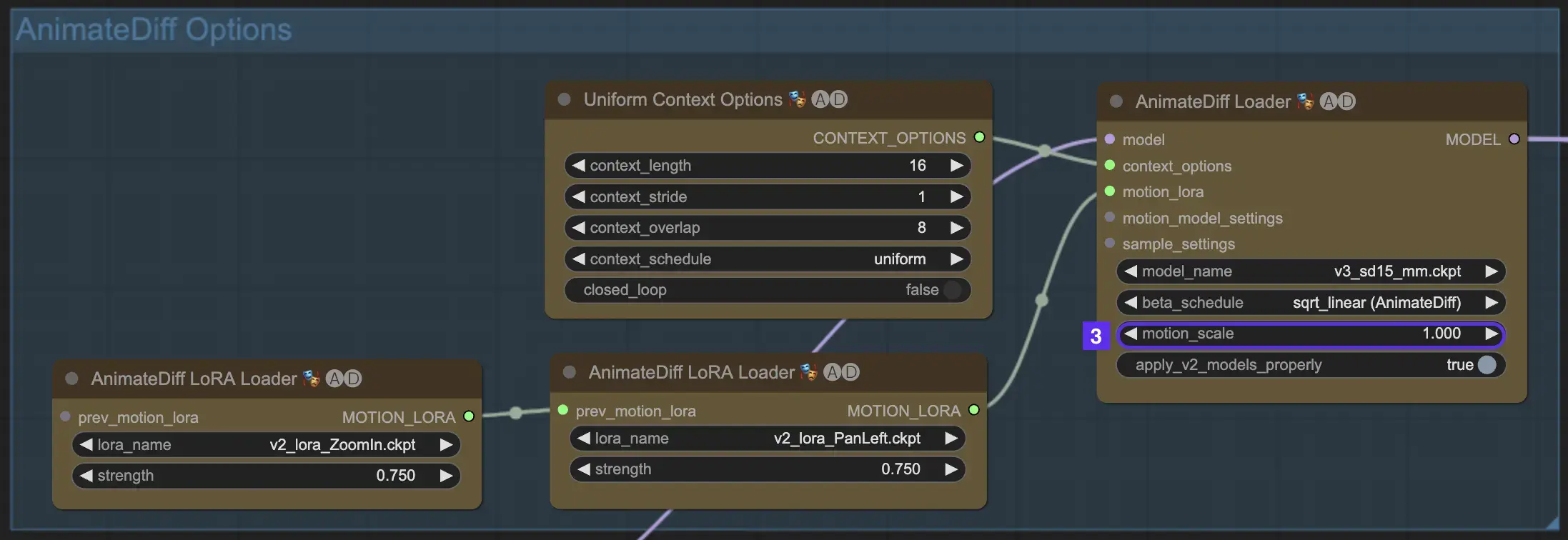
2.3 モーションスケール
AnimateDiffのモーションスケール機能により、アニメーションのモーション強度を調整できます。1未満のモーションスケールではより微妙なモーションになり、1を超えるスケールではモーションが増幅されます。
2.4 コンテキスト長
AnimateDiffの均一コンテキスト長は、バッチサイズによって定義されたシーン間のシームレスな遷移を確保するために不可欠です。熟練した編集者のように機能し、シーンを滑らかにつなぎ合わせて流れるような語りを実現します。均一コンテキスト長を長く設定すると、よりスムーズな遷移が保証され、短い長さでは、特定の効果に有益な、より素早く明確なシーン変更が提供されます。標準の均一コンテキスト長は16に設定されています。
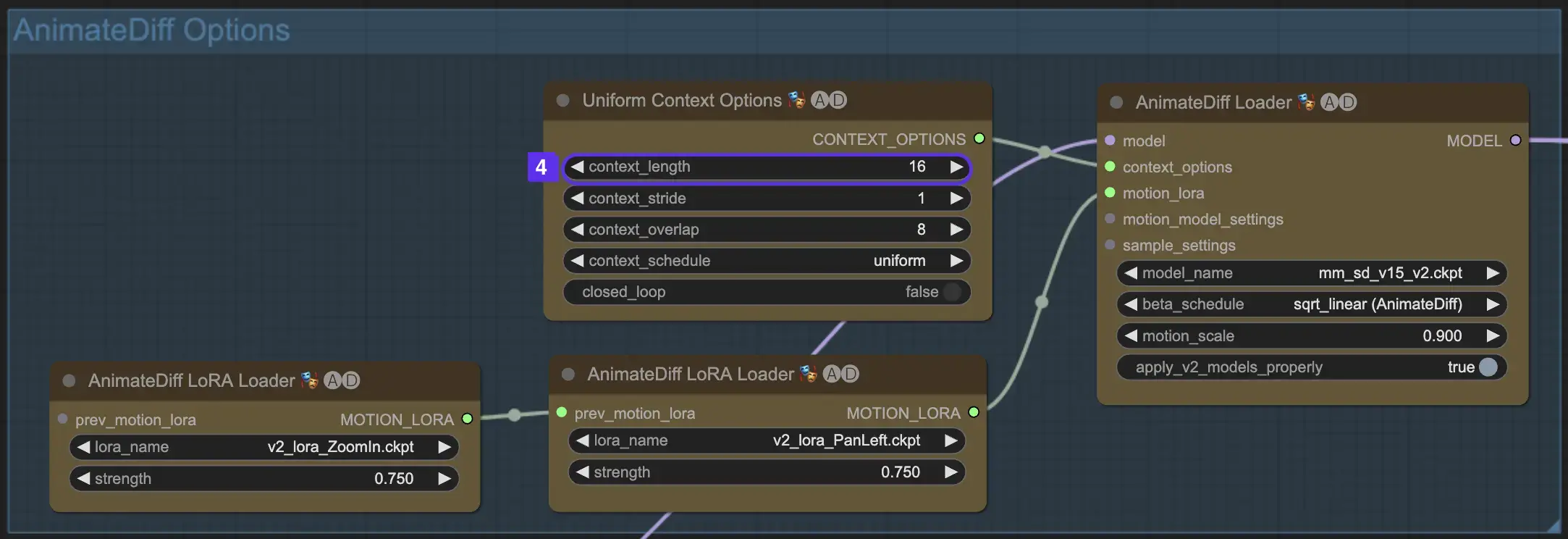
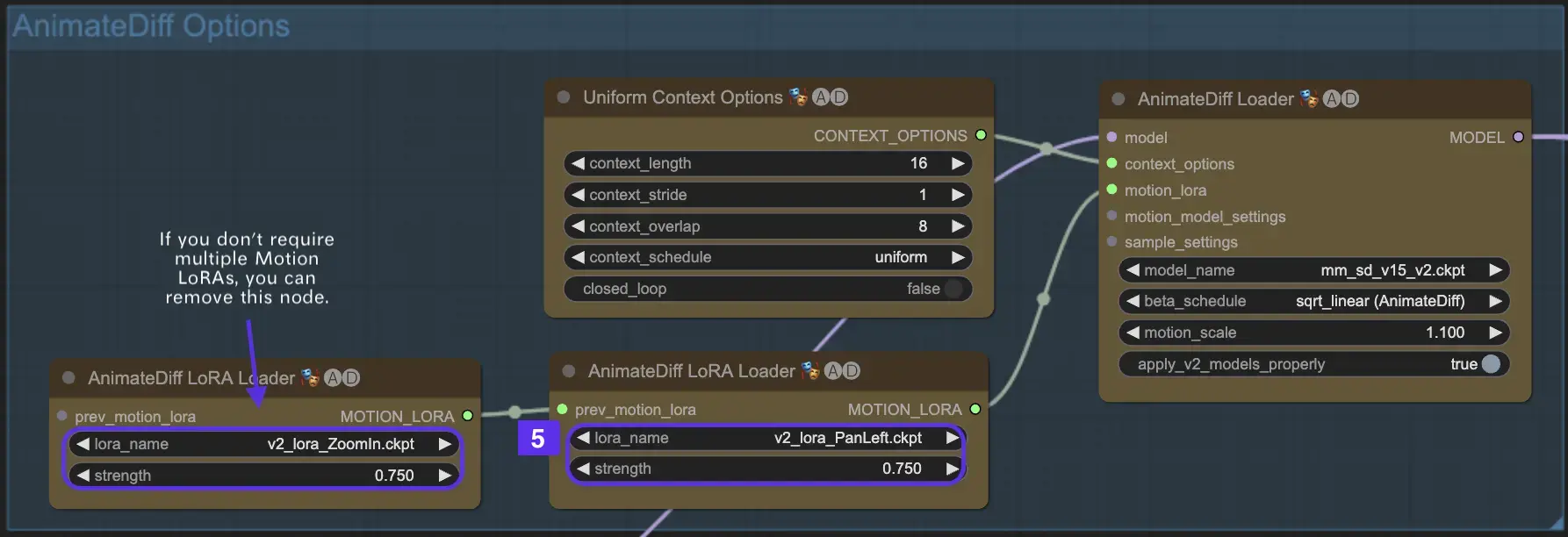
2.5 モーションLoRAを利用した強化カメラダイナミクス(AnimateDiff v2に固有)
AnimateDiff v2とのみ互換性のあるモーションLoRAは、ダイナミックなカメラ移動の追加レイヤーを導入します。通常0.75前後のLoRA重みで最適なバランスを達成することで、背景の歪みのないスムーズなカメラモーションが保証されます。
さらに、様々なモーションLoRAモデルを連鎖させることで、複雑なカメラダイナミクスが可能になります。これにより、クリエイターは実験を行い、アニメーションに理想的な組み合わせを発見して、映画のレベルに高めることができます。
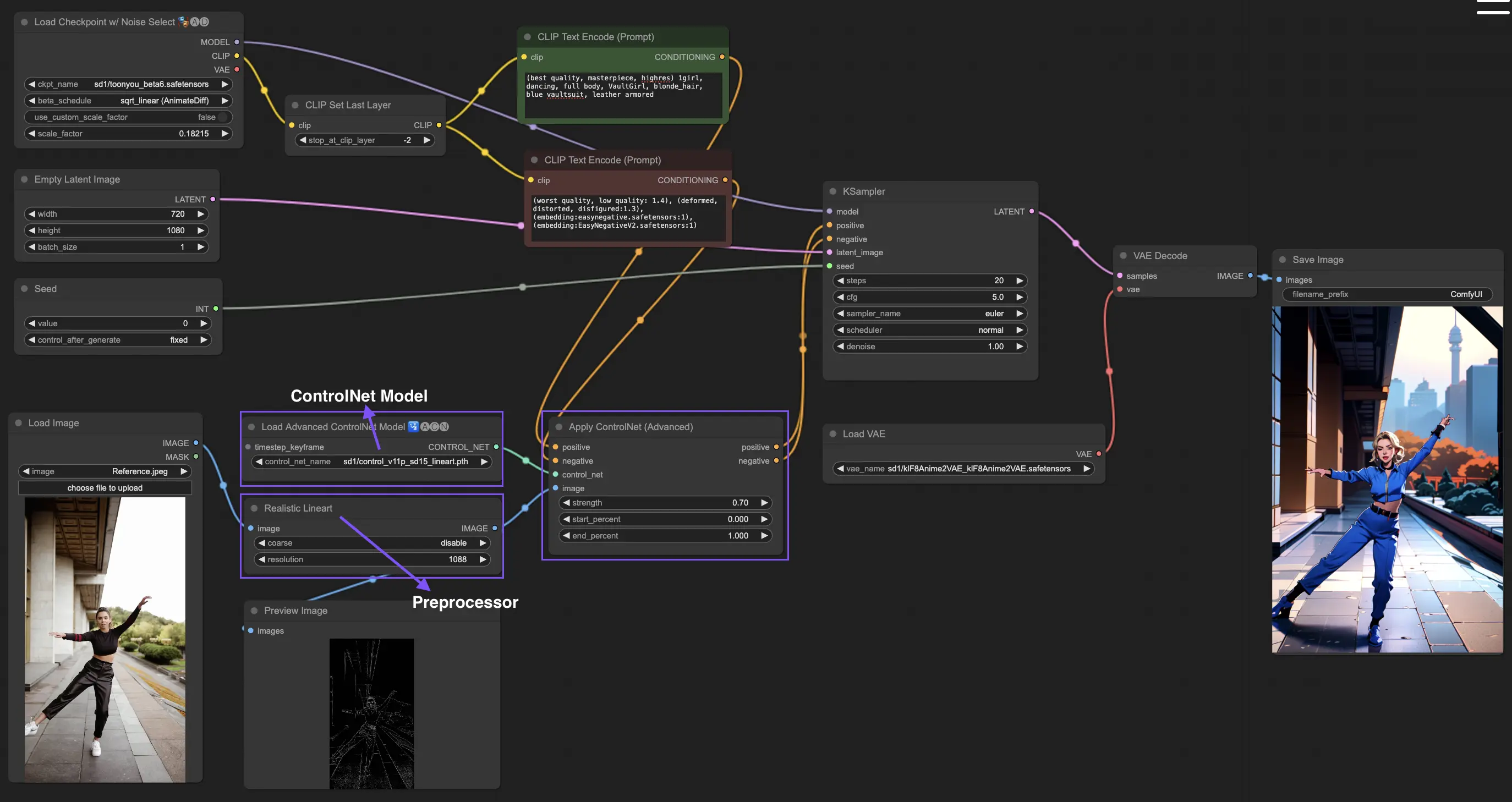
3. ControlNetの使用方法
ControlNetは、テキストから画像へのモデルに正確な空間制御を導入することで画像生成を強化し、ユーザーがテキストプロンプトだけでなく、Stable Diffusionなどのモデルから得られる膨大なライブラリを利用してスケッチ、マッピング、視覚のセグメンテーションなどの複雑なタスクに対応することで、洗練された方法で画像を操作できるようにします。
以下は、ControlNetを使用した最もシンプルなワークフローです。
3.1 "Apply ControlNet"ノードの読み込み
ComfyUIで"Apply ControlNet"ノードを読み込むことで、画像作成を開始し、デザインにおける視覚要素とテキスト要素の組み合わせの舞台を設定します。
3.2 "Apply ControlNet"ノードの入力
Positive ConditioningとNegative Conditioningを使用して画像を形作り、ControlNetモデルを選択してスタイル特性を定義し、画像をControlNetモデルの要件に合わせて前処理して、変換の準備を整えます。
3.3 "Apply ControlNet"ノードの出力
ノードの出力は、ControlNetとの創造的入力の相互作用に基づいて、画像をさらに洗練するか、より詳細なカスタマイズのために別のControlNetを追加するかの選択肢を提供しながら、拡散モデルを導きます。
3.4 最良の結果を得るための"Apply ControlNet"の調整
Determining Strength、Adjusting Start Percent、Setting End Percentなどの設定を通じて、画像の創造プロセスと結果を微調整しながら、画像へのControlNetの影響を制御します。
詳細な情報については、をご確認ください。
このワークフローは、に触発され、いくつかの修正を加えたものです。詳細については、彼のYouTubeチャンネルをご覧ください。
