LatentSyncは、オーディオに条件付けされた潜在拡散モデルの力を活用して現実的なリップシンク生成を行う、最先端のエンドツーエンドのリップシンクフレームワークです。LatentSyncのユニークな点は、中間モーション表現に依存せずにオーディオとビジュアル要素の複雑な相関を直接モデル化する能力にあります。
LatentSyncのパイプラインの中心には、Stable Diffusionの統合があり、高品質の画像をキャプチャし生成する優れた能力で知られています。Stable Diffusionの能力を活用することにより、LatentSyncは音声とそれに対応する唇の動きの複雑な動態を効果的に学習し再現し、非常に正確で説得力のあるリップシンクアニメーションを実現します。
拡散ベースのリップシンク手法における主な課題の1つは、生成されたフレーム間での時間的一貫性を維持することです。これは現実的な結果にとって重要です。LatentSyncは、時間的一貫性を強化するために特別に設計された画期的なTemporal REPresentation Alignment (TREPA)モジュールを使用して、この問題に正面から取り組んでいます。TREPAは、大規模な自己教師付きビデオモデルを使用して生成されたフレームから時間的表現を抽出する高度な技術を採用しています。これらの表現をグラウンドトゥルースフレームと整合させることにより、LatentSyncのフレームワークは高い時間的一貫性を保証し、オーディオ入力に密接に一致する、驚くほど滑らかで説得力のあるリップシンクアニメーションを実現します。
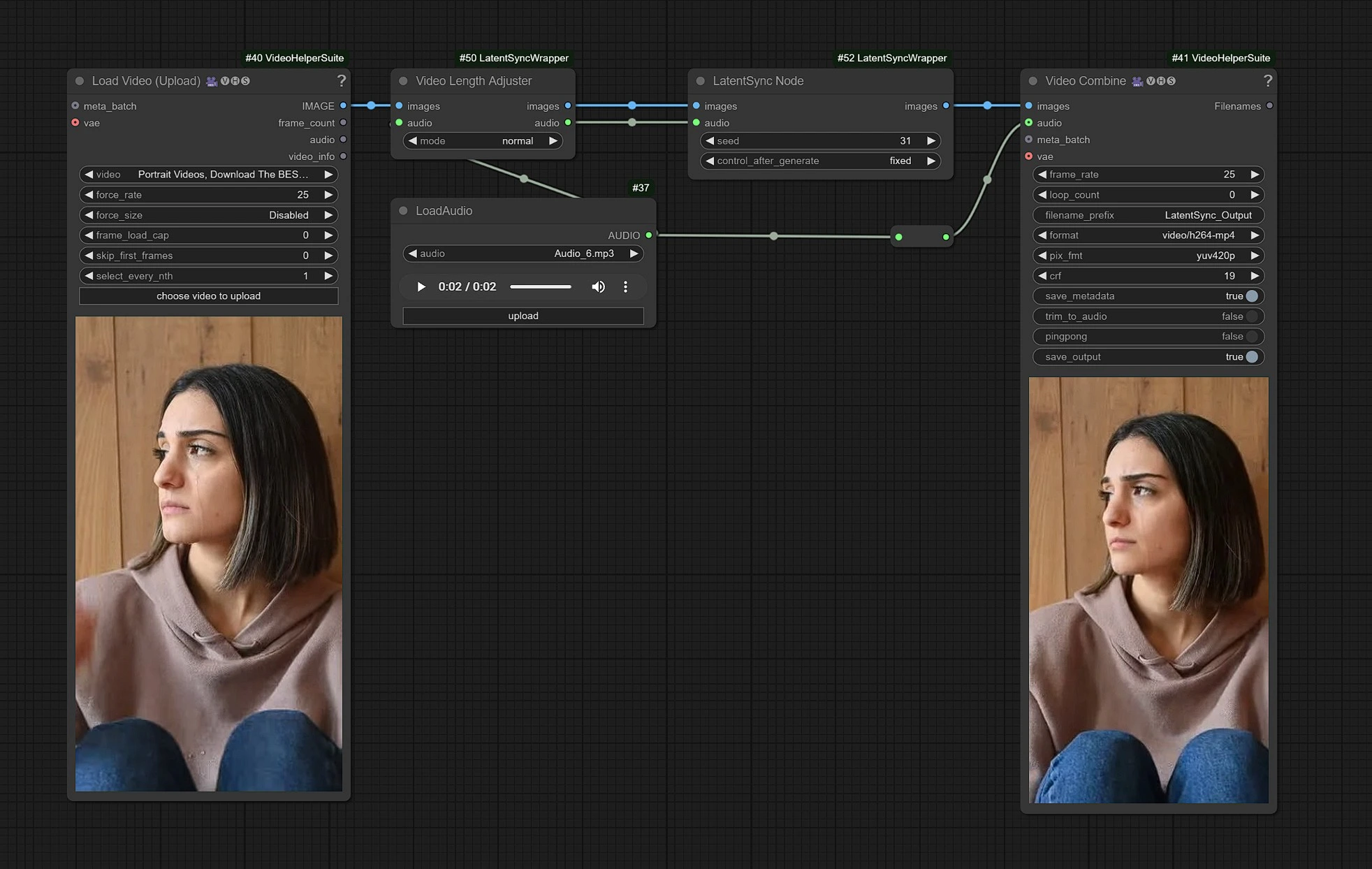
これはLatentSyncのワークフローであり、左側のノードはビデオアップロード用の入力、中央はLatentSyncノードの処理、右側は出力ノードです。
ビデオはオーディオモデルと適切に同期するために25 FPSに調整されます。
LatentSyncは、オーディオビジュアル生成の革新的なアプローチでリップシンクの新たな基準を設定します。精度、時間的一貫性、およびStable Diffusionの力を組み合わせることで、LatentSyncは同期コンテンツの作成方法を変革します。LatentSyncでリップシンクの可能性を再定義してください。
RunComfyは最高の ComfyUI プラットフォームです。次のものを提供しています: ComfyUIオンライン 環境とサービス、および ComfyUIワークフロー 魅力的なビジュアルが特徴です。 RunComfyはまた提供します AI Playground, アーティストが最新のAIツールを活用して素晴らしいアートを作成できるようにする。


