
ダンスビデオ変換ComfyUIワークフローの機能
ダンスビデオ変換ComfyUIワークフローは、元の振り付けを維持しながらプロフェッショナルな顔交換を行い、ダンスビデオを驚くべき新しいシーンに変換し、高品質の出力を保証します。このプロセスは、モーション分析から顔交換までの段階で進行し、各ステップで品質チェックを可能にします。
ダンスビデオ変換ComfyUIワークフローの仕組み
このワークフローは、複雑な変換を自動化し、ビデオ、顔画像、シーン説明のみを必要とするいくつかの段階を経てダンスビデオを変換します: モーション分析 → スタイル転送 → 顔交換
- ダンスの動きと空間情報を分析
- 説明に従ってシーンを変換
- 表情を維持しながら新しい顔を統合
ダンスビデオ変換ComfyUIワークフローの主な機能
- 縦型フォーマット(9:16アスペクト比)に最適化
- 安定した変換のためのトリプルControlNetシステム
- 自然なブレンディングによるプロフェッショナルな顔交換
- 高速テストモード(50フレームを数分で処理)
- 高解像度出力サポート(最大896px高さ)
- AnimateDiffを使用した高度なモーション維持
- 品質確認のためのデュアル出力システム
クイックスタートガイド
ステップ1: 初期設定
各ノードで:
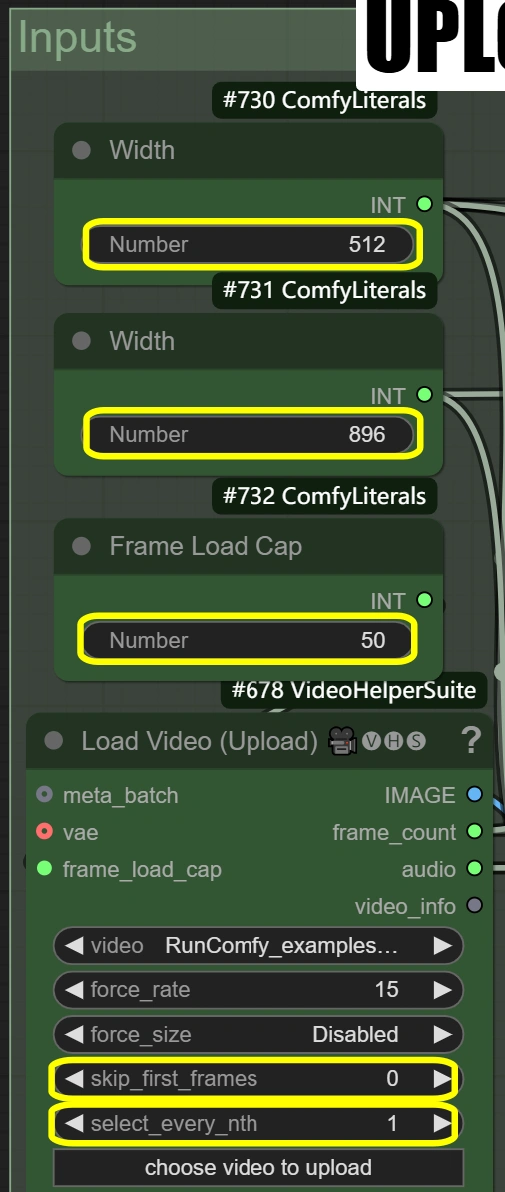
- Load Video (Upload):
- 9:16アスペクト比の10-15秒のダンスビデオをアップロード
- ビデオが9:16でない場合は、ビデオに合わせて幅と高さのパラメータを調整する必要があります。
- フレームロードキャップ: 50(クイックテスト用に最初の50フレームのみレンダリング)
- Load Image:
- 明確な正面の顔写真をアップロード
- Batch Prompt Schedule:
- シーンと変換したい他の側面を簡潔に説明 "0": "[person] in KC Chiefs jersey wearing bluejeans and a baseball cap dancing in the locker room"
- 必要に応じてネガティブプロンプトを設定 <img src="https://cdn.runcomfy.net/workflow_assets/1181/readme01.webp" alt="dance video transform" width="450"/> <img src="https://cdn.runcomfy.net/workflow_assets/1181/readme02.webp" alt="dance video transform" width="450"/> <img src="https://cdn.runcomfy.net/workflow_assets/1181/readme03.webp" alt="dance video transform" width="450"/>
ステップ2: クイックテストラン
- "Queue Prompt"をクリック
- 約2秒のビデオを処理
- 2つの出力が表示されます:
- 最初の出力: シーン変換のみ
- 2番目の出力: 顔交換が適用されたもの

ステップ3: フルビデオ処理
クイックテストが良好であることを確認した後:
- "Load Video"ノードに戻る
- フレームロードキャップを0に変更してフルビデオを処理
- "Queue Prompt"をクリックして完全な処理を行う (これにはかなりの時間がかかります)
著者の 初心者へのヒント
- メモを確認する: インターフェース内のメモを探して、それがステップバイステップで案内します
- 高度な設定を心配しないでください: ここで言及されている以上の調整は通常必要ありません
- アスペクト比の重要性: アスペクト比が正しいことを確認してください、そうでないとビデオが引き伸ばされたり切り取られたりする可能性があります
キーノードリファレンス
AnimateDiff設定
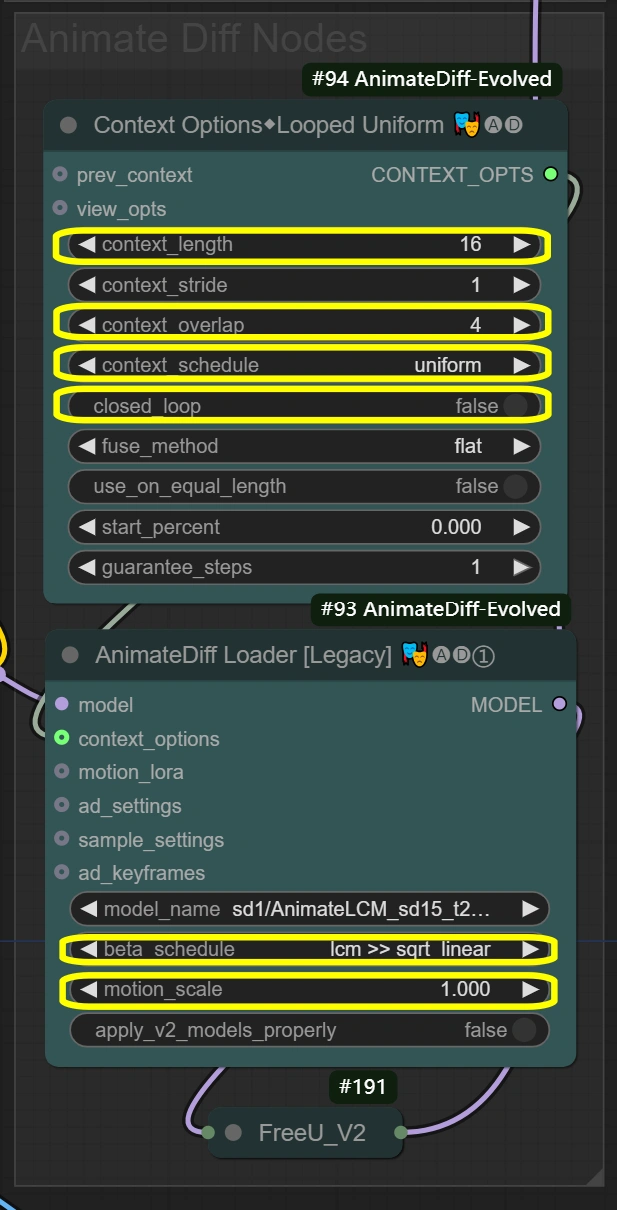
ここでは、ビデオ変換全体でスムーズなモーション維持を実現するノードを作成します。 コンテキストオプションは、フレームをどのようにグループ化して処理するかを定義し、これらの設定をAnimateDiff Loaderに送り、実際のモーション維持を適用します。コンテキストの長さとオーバーラップ設定は、AnimateDiff Loaderが動きの一貫性を維持する方法に直接影響します。
- コンテキストオプションノード (#94): 一貫したモーションのためのフレームグループ化と時間処理制御を実現します。
- context_length:
- 処理するフレーム数を制御
- 高い = スムーズだがVRAM使用量が増加
- 低い = 高速だが動きの一貫性を失う可能性
- context_overlap:
- フレーム遷移の滑らかさを処理
- 高い = より良いブレンディングだが処理が遅くなる
- 低い = 高速だが遷移にギャップが生じる可能性
- context_schedule:
- フレームの分配を制御
- "uniform"はダンスモーションに最適
- 特定の必要がない限り変更しない
- closed_loop:
- ビデオループの動作を制御
- 完全なループビデオの場合のみTrue
- context_length:
- AnimateDiff Loaderノード (#93): AnimateDiffモデルを使用してモーション維持を実装し、時系列の一貫性を適用します。
- motion_scale:
- モーション強度を制御
- 高い: 動きが誇張される
- 低い: 動きが抑えられる
- beta_schedule: lcm >> sqrt_linear
- サンプリングの動作を制御
- このワークフローに最適化
- 必要がない限り変更しない
- motion_scale:
ControlNetスタック
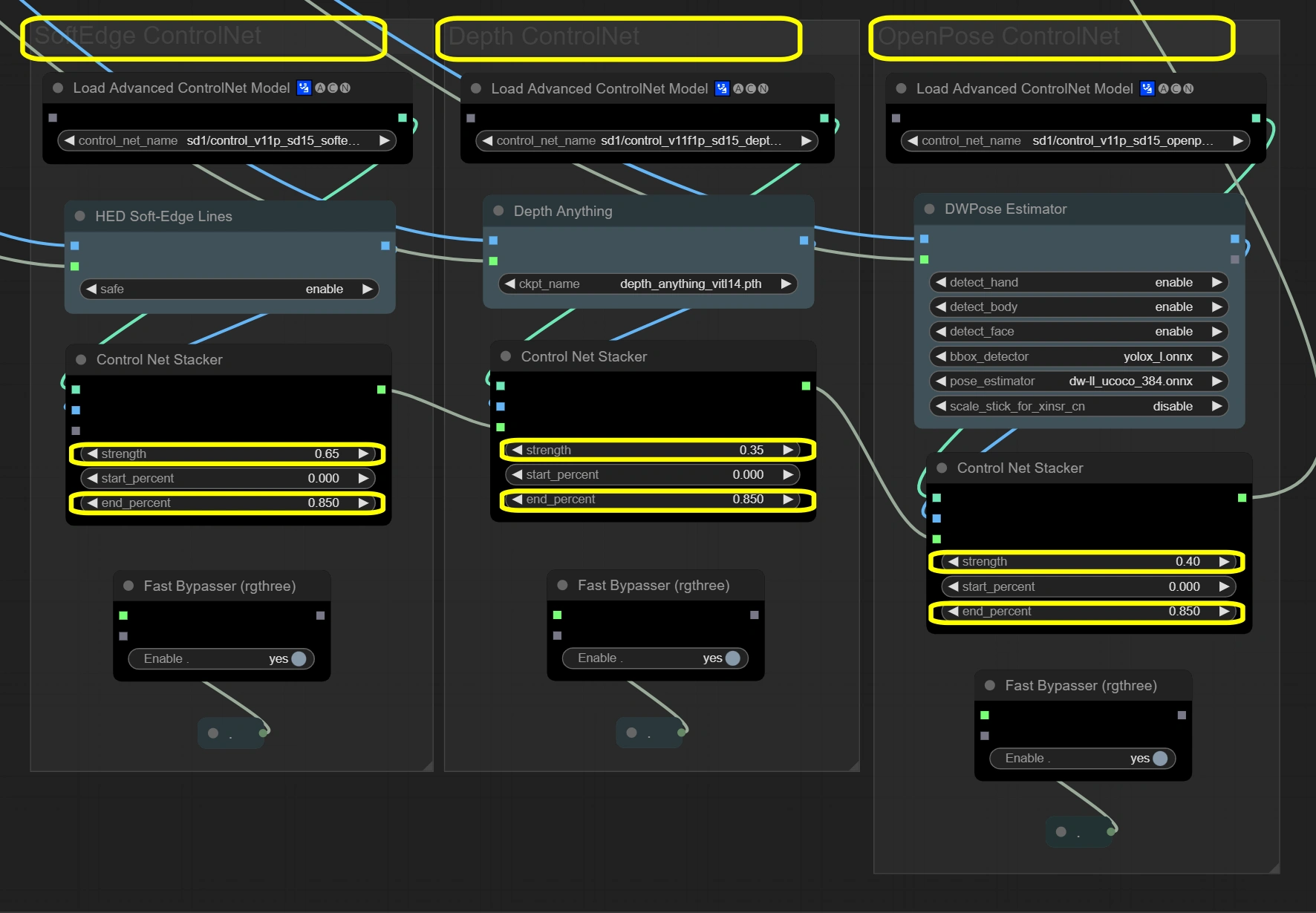
ここでは、3層のガイダンスシステムを通じてビデオの完全性を維持します。 3つのControlNetが入力フレームを同時に処理し、それぞれ異なる側面に焦点を当てます。Soft Edgeは基本的な構造を提供し、Depthは空間理解を追加し、OpenPoseは動きの正確性を保証します。結果はスタッカーを通じて結合され、安定性のために合計強度が1.4を超えないようにします。
- Soft Edge ControlNet: 元のフレームから構造要素と形状を抽出し、保存します。
- Strength:
- 構造の保存を制御
- 高い = 元の形状への強い固執
- 低い = 形状変更の創造的自由
- End percent:
- 制御の影響が停止する時点
- 高い = プロセス全体での影響が長くなる
- 低い = 後のステップでの逸脱を許可
- Strength:
- Depth ControlNet: 空間関係を処理し、3Dの一貫性を維持します。
- Strength:
- 空間認識を制御
- 高い = 強い3D一貫性
- 低い = 空間での芸術的自由
- End percent:
- 深度の影響の持続時間を維持
- 一貫性のためにSoft Edgeと一致させる必要があります
- Strength:
- OpenPose ControlNet: 正確な動きのためにポーズ情報をキャプチャして転送します。
- Strength:
- ポーズの保存を制御
- 高い = 厳格なポーズフォロー
- 低い = より柔軟なポーズ解釈
- End percent:
- ポーズの影響を維持
- プロセス全体で動きを自然に保つ
- Strength:
顔処理
ここでは、自然な結果を得るための顔交換と強化を行います。 プロセスは2段階で進行し、FaceRestoreが最初に元の顔の品質を向上させ、次にReActorが向上した顔を参照として交換を行います。この2段階のプロセスにより、表情を維持しながら自然な統合が保証されます。
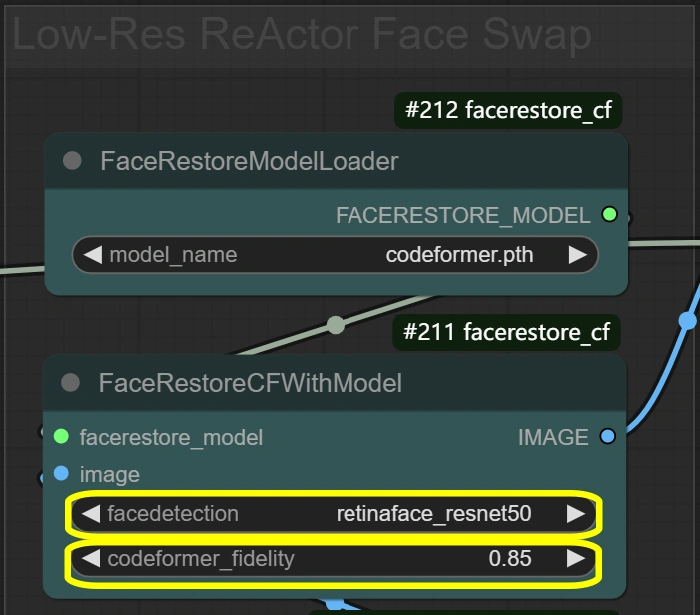
- FaceRestoreシステム: 顔の詳細を強化し、交換の準備をします。
- Fidelity:
- 復元における詳細保存を制御
- 高い = より詳細だがアーティファクトの可能性
- 低い = スムーズだが詳細を失う可能性
- Detection:
- 顔検出モデルの選択
- ほとんどのシナリオで信頼性がある
- 顔が検出されない場合のみ変更
- Fidelity:
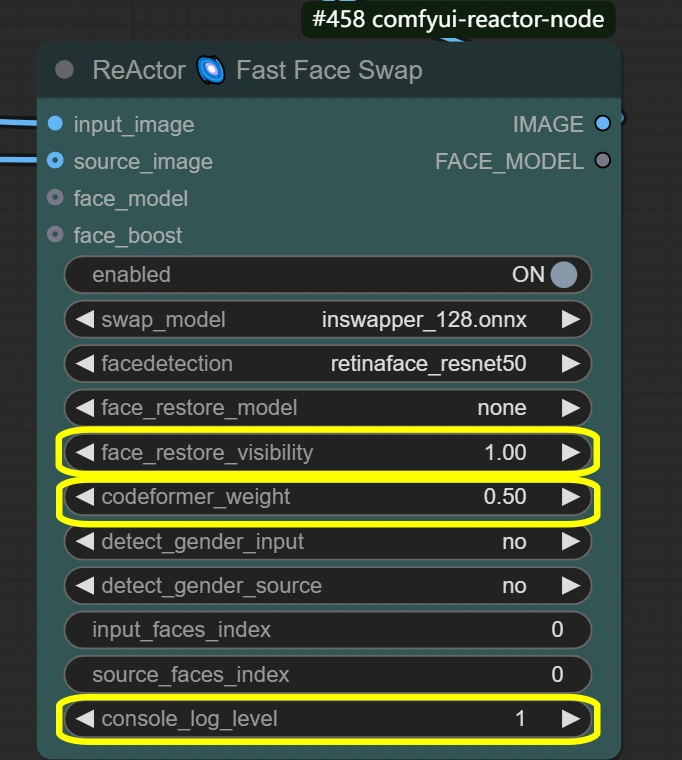
- ReActor顔交換: 顔交換と表情を保存したブレンディングを行います。
- Visibility:
- 交換の視認性を制御
- 高い = 強い顔交換効果
- 低い = より控えめなブレンディング
- Weight:
- 顔の特徴保存のバランス
- 高い = ソース顔の特徴が強い
- 低い = ターゲットとのブレンディングが良好
- Console log level:
- デバッグ情報を制御
- 高い = 詳細なログ
- Visibility:
追加ノード詳細
入力と前処理
目的: ビデオをロードし、寸法を調整し、処理のためにVAEモデルを準備します。
- Load Video:
- Frame Load Cap:
- 処理するフレーム数を制御
- 50 = クイックテスト(約2秒を処理)
- 0 = 全ビデオを処理
- 全処理時間に影響
- Skip First Frames:
- ビデオの開始点を定義
- 高い = ビデオの後半から開始
- イントロをスキップするのに便利
- Select Every Nth:
- フレームサンプリングレートを制御
- 高い数値はフレームをスキップ
- 1 = すべてのフレームを使用
- 2 = 2フレームごとに使用など
- Frame Load Cap:
- Image Scale:
- Width: 512
- 出力フレームの幅を制御
- 高さと9:16比率を維持する必要があります
- Height: 896
- 出力フレームの高さを制御
- 幅と9:16比率を維持する必要があります
- Method: nearest-exact
- シャープネスを維持するのに最適
- 他の方法ではコンテンツがぼやける可能性
- ダンスビデオに推奨
- 特定の必要がない限り変更しない
- Width: 512
- VAE Loader:
- Model: vae-ft-mse-840000-ema-pruned
- 安定性と品質に最適化
- 画像のエンコード/デコードを処理
- バランスの取れた圧縮比
- 特定の必要がない限り変更しない
- VAE Mode: 変更しない
- 現在のワークフローに最適化
- エンコーディング品質に影響
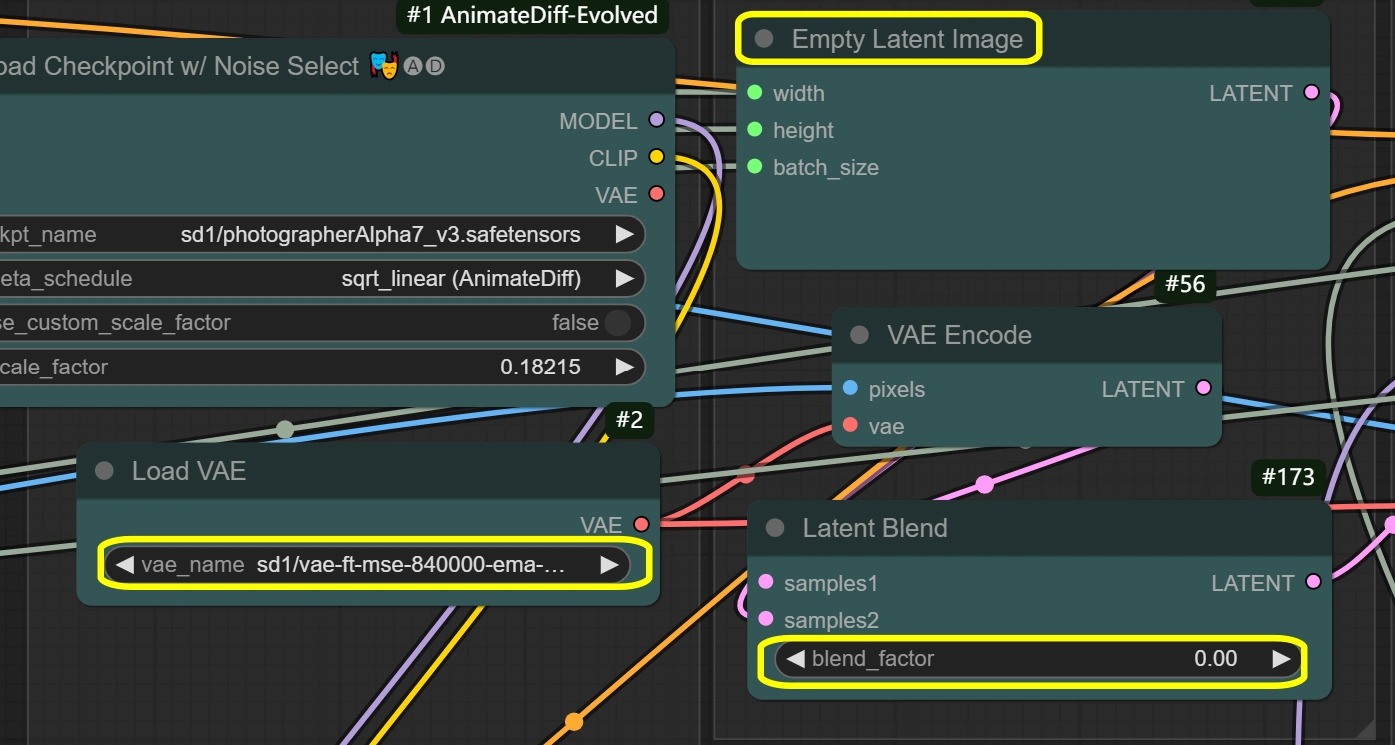
- Model: vae-ft-mse-840000-ema-pruned
潜在処理
目的: すべての潜在空間操作と変換を処理します。
- Empty Latent Image:
- Width/Height: 入力に一致
- Image Scaleの寸法に一致する必要があります
- メモリ使用量に直接影響
- 大きいサイズはより多くのVRAMを必要とします
- 入力より小さくできません
- Batch Size: ビデオフレームから
- フレーム数から自動設定
- 処理速度とVRAMに影響
- 高い = より多くのメモリが必要
- Width/Height: 入力に一致
- VAE Encode:
- VAE Model: VAE Loaderから
- VAE Loaderの設定を使用
- 一貫性を維持
- Decode: 有効
- デコード品質を制御
- VRAMが制限されている場合のみ無効化
- 出力品質に影響
- VAE Model: VAE Loaderから
- Latent Blend:
- Blend Factor:
- 潜在空間の混合を制御
- 0 = 元のコンテンツを完全に保持
- 高い = より多くの空の潜在影響
- スタイル転送の強度に影響
- Blend Factor:
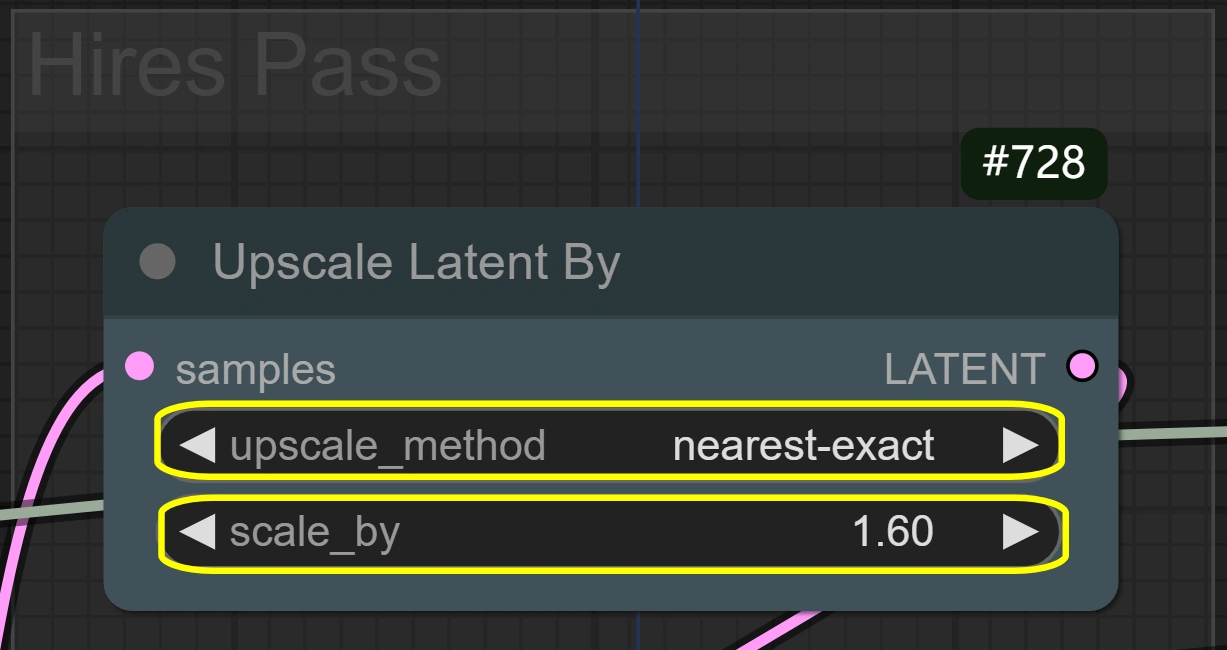
- Latent Upscale By:
- Method: nearest-exact
- シャープネスを維持するのに最適
- 他の方法ではぼやける可能性
- モーションの詳細を保持
- Scale:
- サイズ増加を制御
- 高い = より良い詳細だがより多くのVRAM
- 低い = 高速処理
- 1.6はほとんどの場合に最適
- Method: nearest-exact
json
サンプリングと洗練
目的: 品質変換のための2段階のサンプリングプロセス。
- KSampler (First Pass):
- Steps:
- ノイズ除去ステップの数
- 高い = より良い品質だが遅い
- 6はlcmサンプラーに最適
- CFG:
- プロンプトの影響を制御
- 高い = 強いスタイルの固執
- 低い = より多くの自由
- Sampler: lcm
- 速度に最適化
- 良好な品質/速度バランス
- Scheduler: sgm_uniform
- lcmと最適に動作
- 時系列の一貫性を維持
- Denoise:
- 最初のパスのフル強度
- 変換の強度を制御
- Steps:
- KSampler (Hires Pass):
- Steps:
- 一貫性のために最初のパスと一致
- 洗練のために高いものは必要ない
- CFG:
- スタイルの一貫性を維持
- 詳細保存のバランス
- Sampler: lcm
- 最初のパスと同じ
- 一貫性を維持
- Scheduler: sgm_uniform
- 最初のパスと一貫性を維持
- 詳細な洗練に良好
- Denoise:
- 最初のパスより低い
- より多くの元の詳細を保存
- 洗練のための良いバランス
- Steps:
出力処理
目的: 顔交換あり/なしの最終ビデオ出力を作成します。
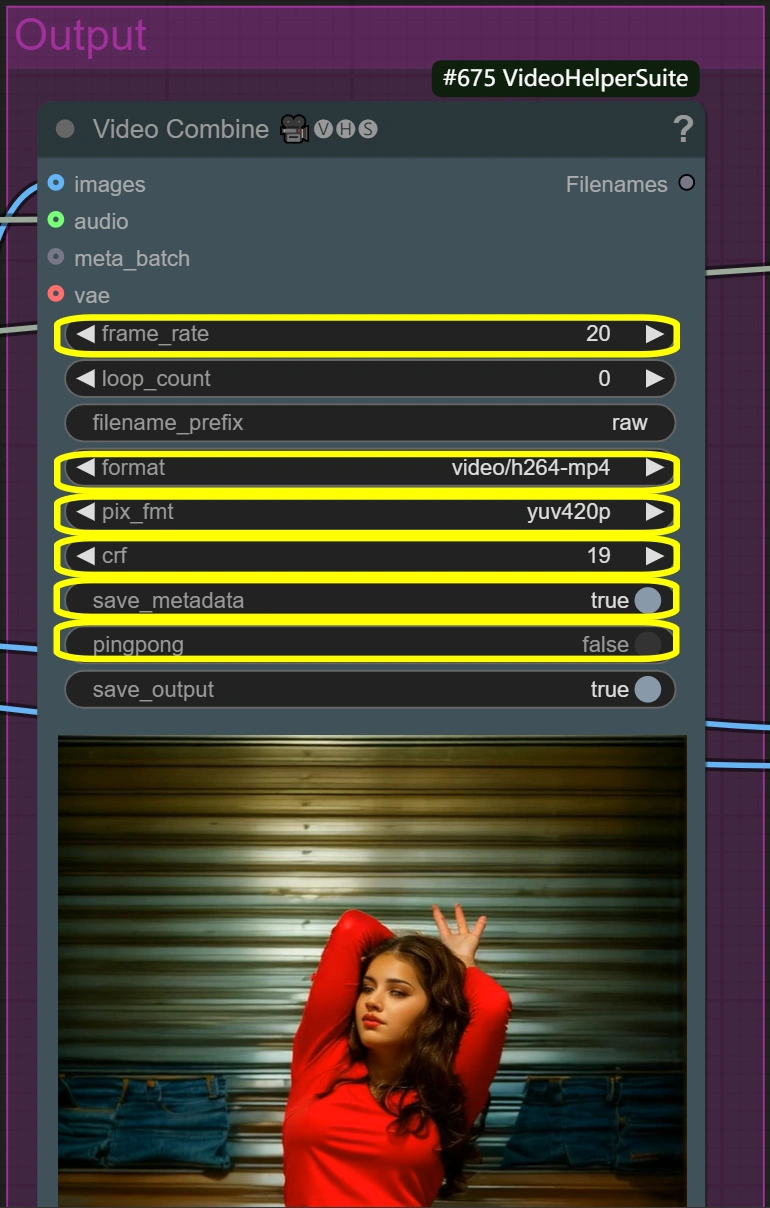
- Video Combine (Raw):
- Frame Rate:
- 標準的なビデオフレームレート
- 再生速度を制御
- 低い = 小さいファイルサイズ
- 高い = 滑らかな動き
- Format: video/h264-mp4
- 互換性のある標準フォーマット
- 品質/サイズの良好なバランス
- 広くサポートされています
- CRF:
- 圧縮品質を制御
- 低い = より良い品質だが大きなファイル
- 高い = 小さいファイルだが低い品質
- 19は高品質設定
- Pixel Format: yuv420p
- 互換性のある標準フォーマット
- 必要がない限り変更しない
- 幅広い再生サポートを保証
- Frame Rate:
- Video Combine (Face Swap):
- 生の出力と同じパラメータ
- 一貫性のために同一の設定を使用
- 顔交換の統合を追加
- ビデオ品質設定を維持
最適化のヒント
品質対速度のトレードオフ
- 解像度のバランス:
- 標準: 512x896
- 高速処理
- ほとんどの用途に適しています
- 高品質: 768x1344
- より良い詳細
- 処理時間が2-3倍長くなります
- 標準: 512x896
- 顔交換の品質:
- 標準: デフォルト設定
- 自然な統合
- バランスの取れた処理時間
- 最大品質:
- codeformer_fidelityを0.9に増加
- より遅いがより詳細な顔
- 標準: デフォルト設定
- モーションの滑らかさ:
- 高速処理:
- context_overlapを2に減少
- やや滑らかさが減少
- より良いモーション:
- オーバーラップを6に増加
- より多くのVRAMを使用し、処理が遅くなる
- 高速処理:
一般的な問題と解決策
- 顔のブレンディング:
- 問題: 不自然な顔の遷移
- 解決策: codeformer_weightを調整
- 0.4-0.7の範囲を試す
- 低い = より良いブレンディング
- 高い = より多くの顔の詳細
- スタイルの強度:
- 問題: 弱いスタイル転送
- 解決策: cfgを増加
- 7-8の範囲を試す
- 高い = より強いスタイル
- モーション品質に影響を与える可能性
- メモリ管理:
- 問題: VRAMの制限
- 解決策:
- VAEスライシングを有効にする
- 解像度を減少
- より短いセグメントを処理
詳細情報
詳細や素晴らしい作品については、junkboxaiのInstagramをご覧ください。

