Hunyuanビデオ | ビデオからビデオへ
ComfyUIのこのHunyuanワークフローを使用すると、既存のビジュアルを驚くべき新しいビジュアルに変換できます。テキストプロンプトとソースビデオを入力することで、Hunyuanモデルはソースからの動きと重要な要素を取り入れた印象的な翻訳を生成します。高度なアーキテクチャとトレーニング技術を使用して、Hunyuanは高品質で多様性と安定性のあるコンテンツを生成します。ComfyUI Hunyuan Video to Video ワークフロー
このワークフローを実行しますか?
- 完全に動作するワークフロー
- 欠落したノードやモデルはありません
- 手動セットアップは不要
- 魅力的なビジュアルを特徴としています
ComfyUI Hunyuan Video to Video 例
ComfyUI Hunyuan Video to Video 説明
Tencentによって開発されたオープンソースのAIモデルであるHunyuanビデオは、簡単に驚くべき動的ビジュアルを生成できます。Hunyuanモデルは、高度なアーキテクチャとトレーニング技術を利用して、質の高い、動きの多様性と安定性のあるコンテンツを理解し生成します。
Hunyuanビデオからビデオへのワークフローについて
ComfyUIのこのHunyuanワークフローは、入力テキストプロンプトと既存のドライビングビデオを組み合わせて新しいビジュアルコンテンツを作成します。Hunyuanモデルの能力を活用して、ドライビングビデオの動きと重要な要素をシームレスに取り入れながら、希望するテキストプロンプトに一致する印象的なビデオ翻訳を生成できます。
Hunyuanビデオからビデオへのワークフローの使用方法
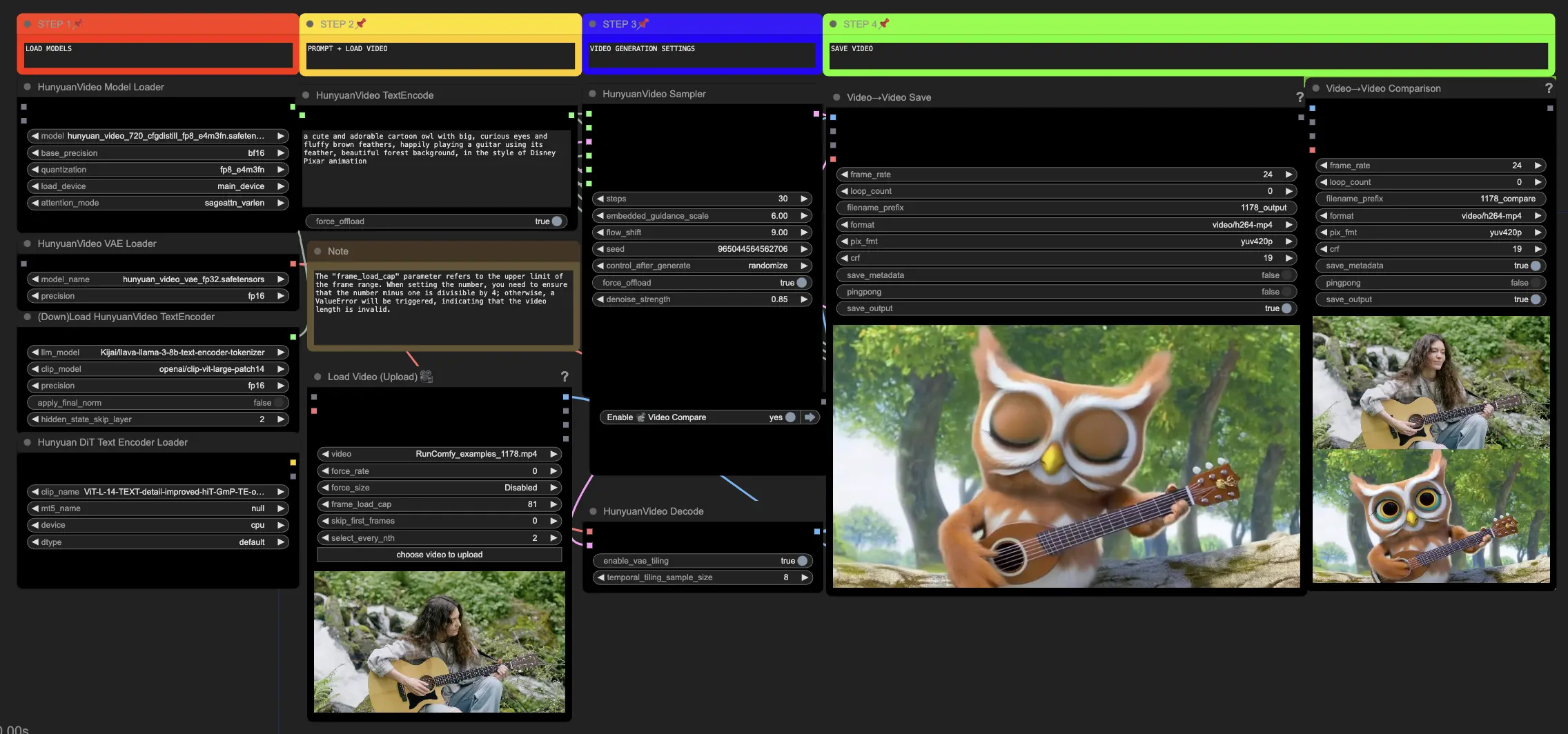
🟥 ステップ1: Hunyuanモデルをロード
- HyVideoModelLoaderノードで"hunyuan_video_720_cfgdistill_fp8_e4m3fn.safetensors"ファイルを選択してHunyuanモデルをロードします。これがメインのトランスフォーマーモデルです。
- HunyuanVideo VAEモデルは、HunyuanVideoVAELoaderノードで自動的にダウンロードされます。これはビデオフレームのエンコード/デコードに使用されます。
- DownloadAndLoadHyVideoTextEncoderノードでテキストエンコーダーをロードします。ワークフローは"Kijai/llava-llama-3-8b-text-encoder-tokenizer" LLMエンコーダーと"openai/clip-vit-large-patch14" CLIPエンコーダーをデフォルトで使用し、自動的にダウンロードされます。以前のモデルと連携した他のCLIPまたはT5エンコーダーを使用することもできます。
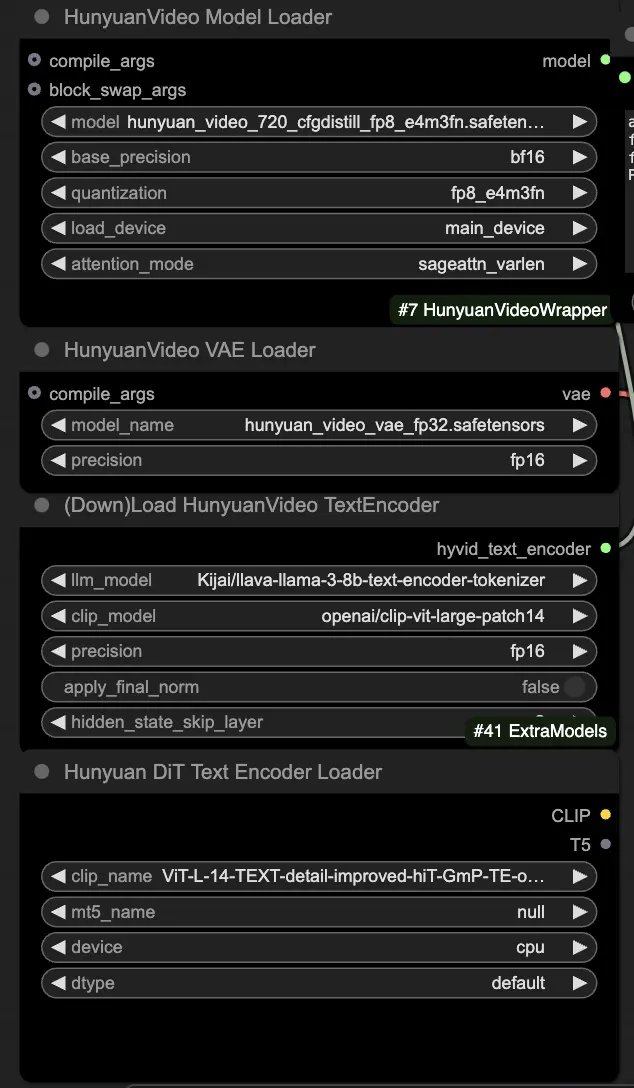
🟨 ステップ2: プロンプトを入力しドライビングビデオをロード
- HyVideoTextEncodeノードで生成したいビジュアルを説明するテキストプロンプトを入力します。
- VHS_LoadVideoノードでモーションリファレンスとして使用したいドライビングビデオをロードします。
- frame_load_cap: 生成するフレーム数。この数を設定する際、数値から1を引いた値が4で割り切れるようにする必要があります。そうでない場合、ビデオの長さが無効であることを示すValueErrorが発生します。
- skip_first_frames: ビデオのどの部分を使用するかを制御するためにこのパラメータを調整します。
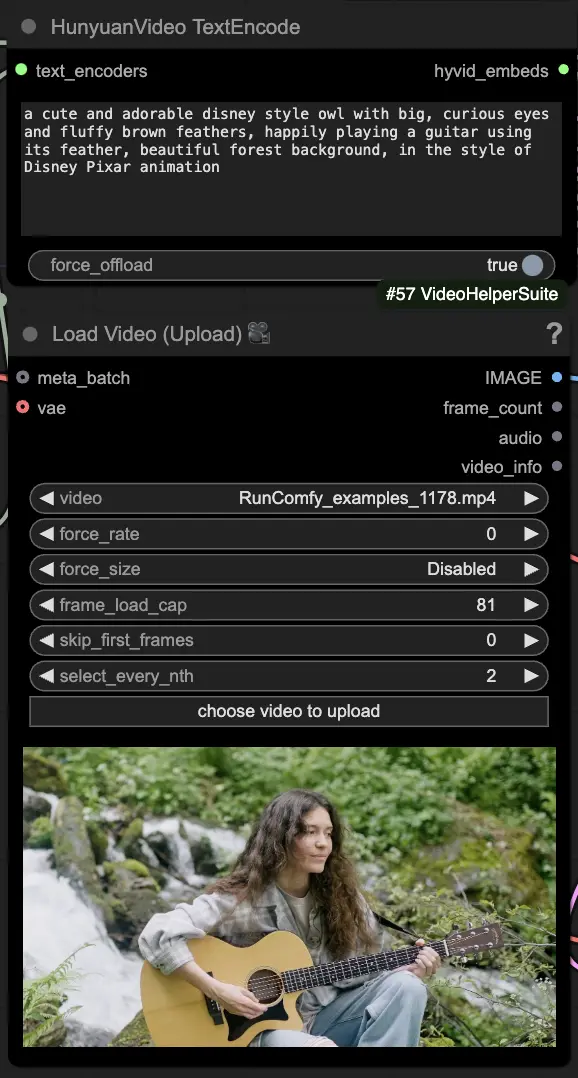
🟦 ステップ3: Hunyuan生成設定
- HyVideoSamplerノードでビデオ生成のハイパーパラメータを設定します:
- Steps: フレームあたりの拡散ステップ数。多いほど品質が向上しますが、生成が遅くなります。デフォルトは30です。
- Embedded_guidance_scale: プロンプトにどの程度従うか。高い値ほどプロンプトに忠実になります。
- Denoise_strength: 初期ドライビングビデオの使用強度を制御します。低い値(例: 0.6)は出力を初期に近づけます。
- "Fast Groups Bypasser"ノードで、比較ビデオのような追加機能を有効/無効にするためのアドオンとトグルを選択します。
🟩 ステップ4: Hunyuanビデオを生成
- VideoCombineノードはデフォルトで2つの出力を生成して保存します:
- 翻訳されたビデオ結果
- ドライビングビデオと生成された結果を示す比較ビデオ
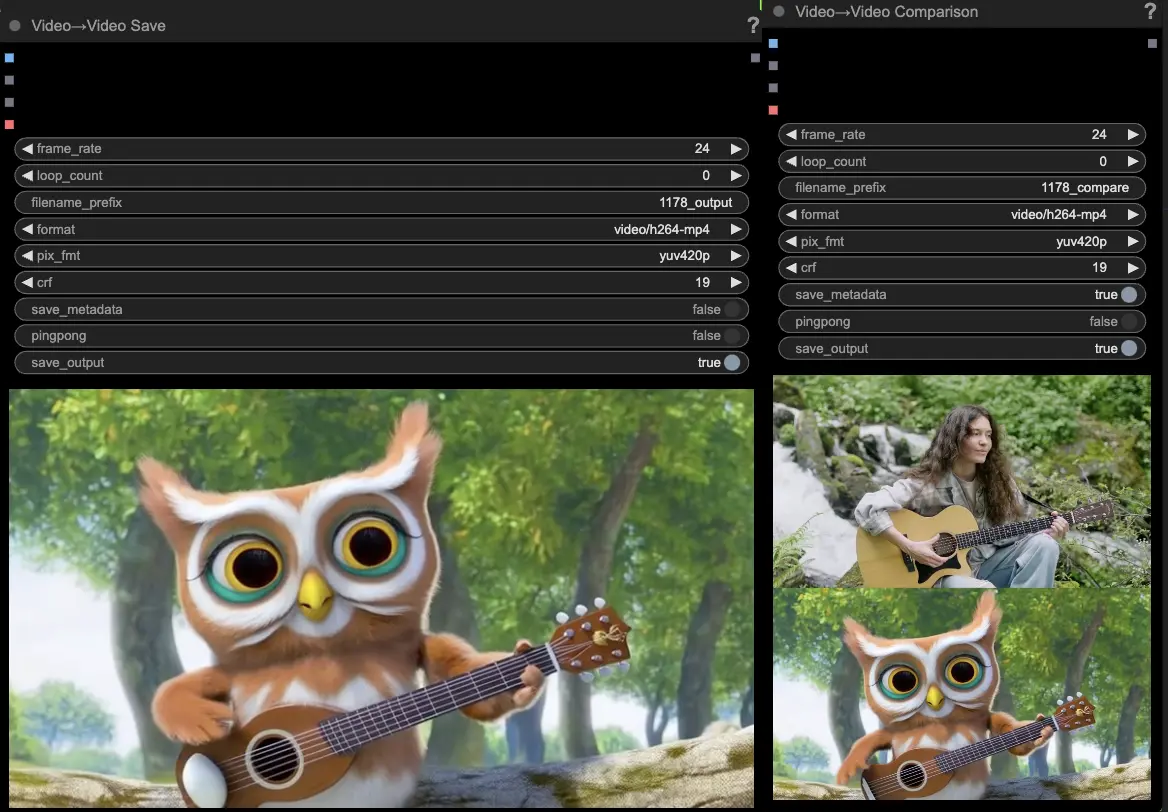
プロンプトと生成設定を調整することで、既存のビデオの動きによって駆動される新しいビデオをHunyuanモデルを使用して作成する際の印象的な柔軟性を提供します。このHunyuanワークフローの創造的な可能性をぜひ探求してください!
このHunyuanワークフローはBlack Mixtureによって設計されました。詳細についてはをご覧ください。また、ノードとワークフロー例に特別な感謝を捧げます。



