Stable Cascade | 텍스트 투 이미지
이 ComfyUI 워크플로우에서는 거의 모든 모델 비교에서 프롬프트 정렬과 미적 품질 모두 더 나은 성능을 보이는 텍스트 투 이미지 모델인 Stable Cascade를 사용합니다. 더 자세한 프롬프트를 시도하여 결과를 확인할 수 있습니다.ComfyUI Stable Cascade 워크플로우
- 완전히 작동 가능한 워크플로우
- 누락된 노드 또는 모델 없음
- 수동 설정 불필요
- 멋진 시각 효과 제공
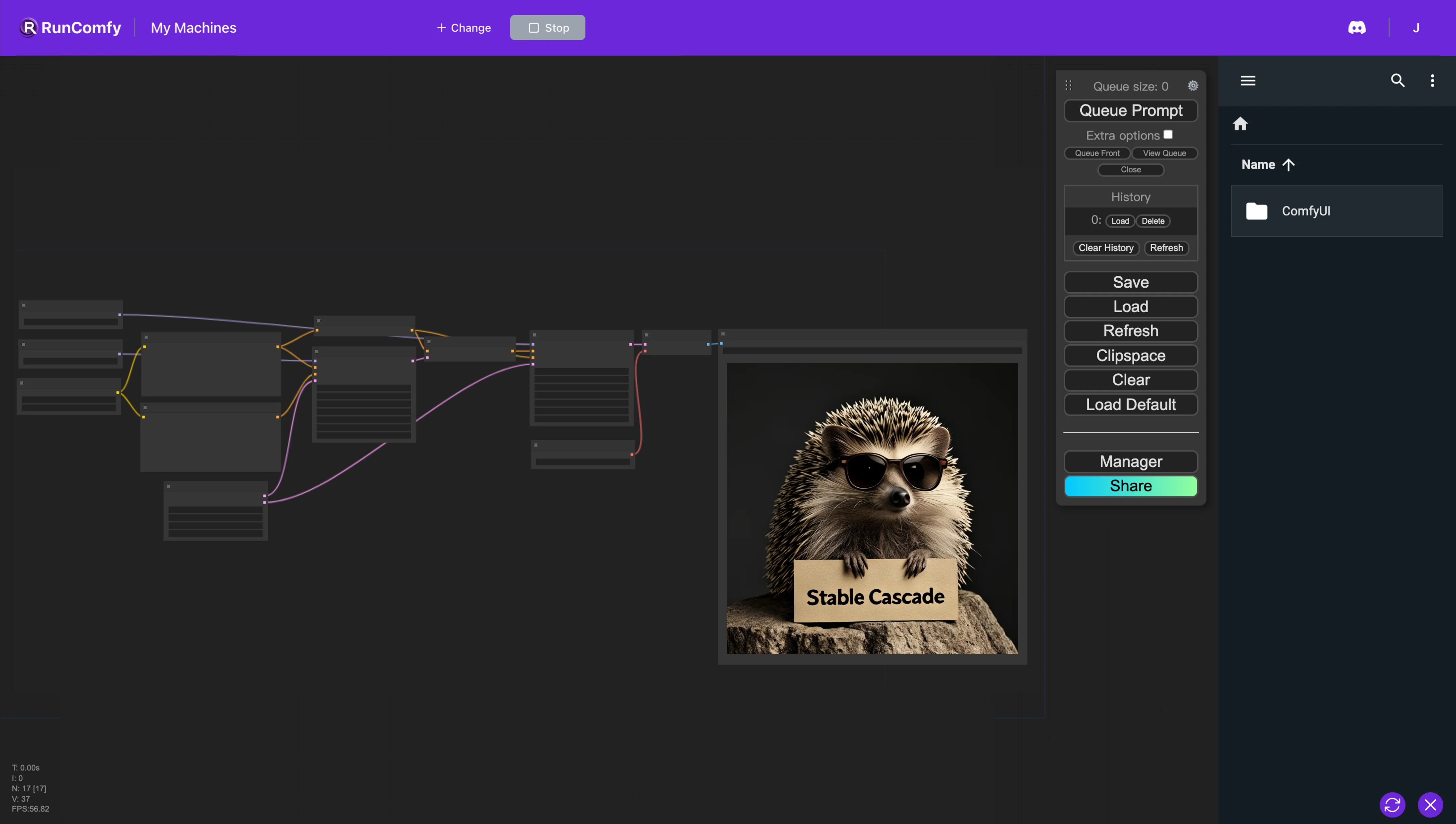
ComfyUI Stable Cascade 예제

ComfyUI Stable Cascade 설명
1. Stable Cascade ComfyUI 워크플로우
이 ComfyUI 워크플로우에서는 프롬프트 정렬과 미적 우수성으로 유명한 최고의 텍스트 투 이미지 모델인 Stable Cascade를 활용합니다. 다른 Stable Diffusion 모델과 달리 Stable Cascade는 3단계 파이프라인(Stage A, B, C) 아키텍처를 사용합니다. 이 설계는 매우 효율적인 잠재 공간에서 계층적 이미지 압축을 가능하게 하여 탁월한 이미지 품질을 제공합니다.
2. Stable Cascade 개요
Stable Cascade는 혁신적인 아키텍처를 활용하는 획기적인 텍스트 투 이미지 모델로 등장했습니다. 이 모델은 더 높은 품질의 이미지, 더 빠른 속도, 더 낮은 비용, 그리고 더 쉬운 커스터마이징으로 차별화됩니다.
2.1. 3단계 프로세스 구조
Stable Cascade Stage A: Stable Cascade의 Stage A는 Vector-Quantized Generative Adversarial Network (VQGAN)을 활용하여 4배의 이미지 압축을 달성합니다. 이 단계에서는 학습된 코드북에서 8,192개의 고유한 항목 중 하나로 값을 혁신적으로 양자화하는데, 이는 팔레트에서 색상을 선택하는 것과 유사합니다. 이 양자화는 이미지를 공간적으로 4:1로 압축할 뿐만 아니라 이미지를 이산 토큰으로 표현하여 데이터 크기를 상당히 줄입니다. 이 방법은 Stable Diffusion이 부동 소수점 값을 사용하는 것과 대조적으로 더 컴팩트하고 효율적인 압축 기술을 제공합니다.
Stable Cascade Stage B: Stage B로 넘어가면 Stable Cascade는 이미지 데이터 정제 능력을 보여줍니다. 여기서 Stage A의 이산 토큰은 IP Adapter의 원리를 확산 기술과 독창적으로 통합하여 유사한 출력 이미지 생성을 안내하는 잠재 확산 모델을 통해 변환됩니다. Stage B는 토큰화된 데이터를 다시 풍부하고 상세한 부동 소수점 값으로 변환하는 능력이 뛰어나 이미지의 의미론적 품질을 높입니다. 이 단계는 입력과 완벽히 일치하는 노이즈 제거된 잠재 요소를 생성하는 데 초점을 맞춰 효율성을 고려하여 설계되었으며, 이를 통해 훈련 프로세스를 간소화하고 계산 요구 사항을 줄입니다.
Stable Cascade Stage C: Stage C는 Stage B의 의미론적 출력에 노이즈를 추가한 다음 ConvNeXt 블록 시퀀스를 사용하여 노이즈를 꼼꼼히 제거하는 새로운 접근 방식을 도입합니다. 목표는 다운샘플링의 필요성을 피하면서 의미론적 내용을 정확하게 복제하는 것입니다. 이 단계는 의미론적 블롭을 Stage B가 더 정제할 수 있는 일관된 조각으로 변환하는 데 중추적인 역할을 하며, 최종적으로 고품질 이미지 생성으로 이어집니다. Stage C의 ConvNeXt 블록의 전략적 사용은 일반적으로 이러한 고급 결과를 달성하는 데 필요한 막대한 계산 비용을 우회하면서 최고 수준의 성능을 효율적으로 제공하기 위한 노력을 보여줍니다.
2.2. Stable Cascade가 두각을 나타내는 이유
탁월한 미적 품질: 평가 결과에 따르면 Stable Cascade는 시각적으로 놀라운 이미지를 제공하는 데 있어 Stable Diffusion XL을 크게 능가하는 것으로 나타났습니다. SDXL보다 2.5배, SDXL Turbo보다 놀랍게도 5.5배 더 높은 미적 품질을 달성하여 고품질 비주얼 제작 능력이 탁월함을 보여줍니다.
향상된 추론 속도: 혁신적인 아키텍처 덕분에 Stable Cascade는 이전 모델보다 리소스를 더 효과적으로 활용하여 더 효율적인 추론 프로세스를 제공합니다. 42배의 놀라운 압축 비율로 1024x1024 이미지를 컴팩트한 24x24 크기로 변환할 수 있습니다. 이러한 효율성은 이미지 품질을 저하시키지 않으면서 생성 프로세스 속도를 높여 이미지를 신속하게 생성하는 데 있어 게임 체인저 역할을 합니다.
향상된 프롬프트 이해력: Stable Cascade는 또한 간단하거나 상세한 사용자 프롬프트를 이해하고 정렬하는 능력이 뛰어납니다. 인간 평가에 따르면 프롬프트를 정확하게 해석하는 데 있어 다른 모델을 능가하는 것으로 나타났으며, 이는 생성된 이미지가 사용자의 비전과 밀접하게 일치함을 보장합니다.






