AnimateDiff + ControlNet | 세라믹 아트 스타일
ComfyUI 내의 이 워크플로우는 심도에 초점을 맞춘 AnimateDiff와 ControlNet을 Lora와 같은 다른 도구들과 함께 사용하여 동영상을 세라믹 아트 스타일로 능숙하게 변환합니다. 이를 통해 원본 콘텐츠가 독특하고 예술적인 멋을 띠게 되어 세라믹 예술 걸작의 경지로 효과적으로 승화됩니다.ComfyUI Vid2Vid (Art) 워크플로우
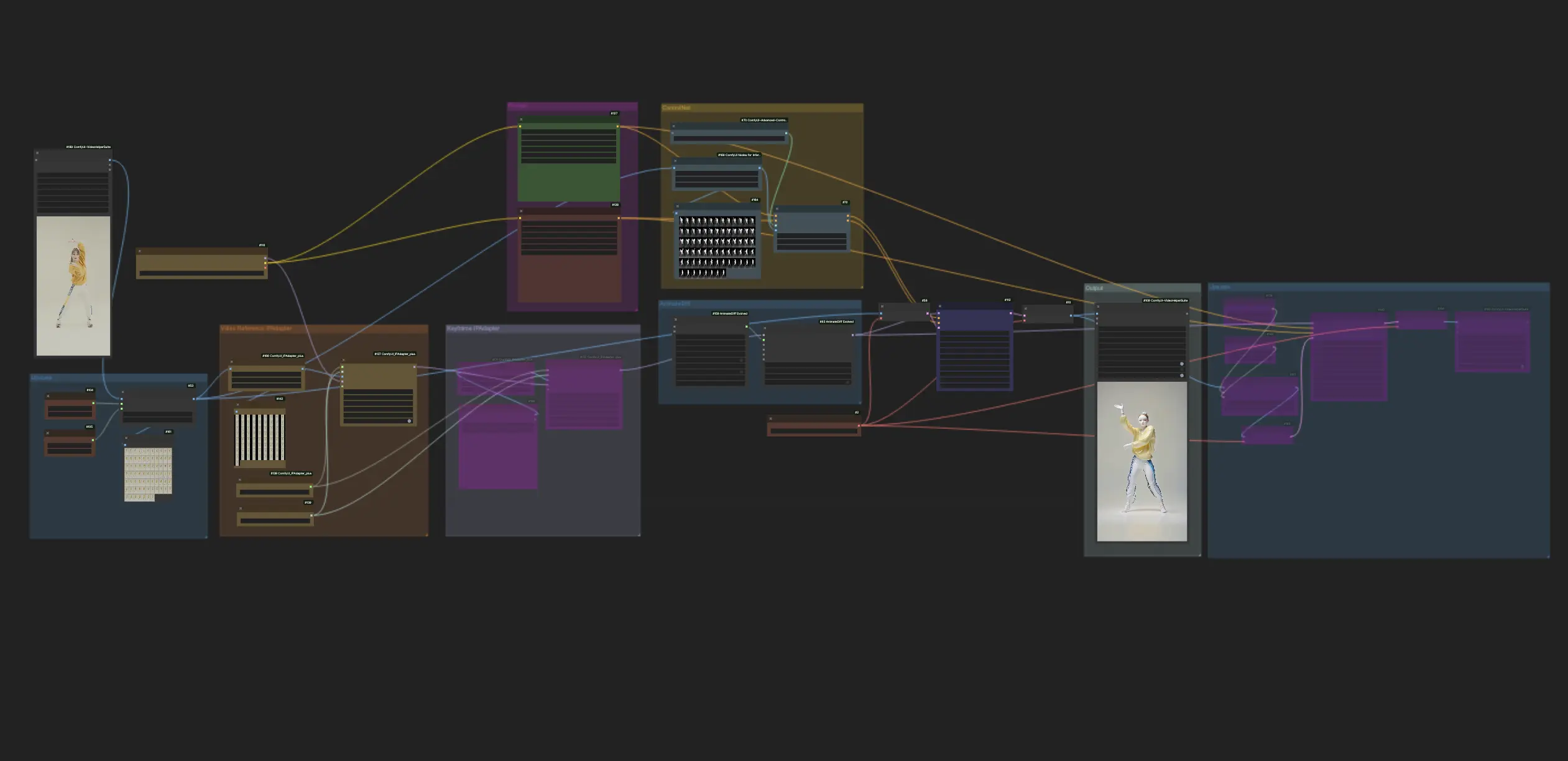
- 완전히 작동 가능한 워크플로우
- 누락된 노드 또는 모델 없음
- 수동 설정 불필요
- 멋진 시각 효과 제공
ComfyUI Vid2Vid (Art) 예제
ComfyUI Vid2Vid (Art) 설명
1. ComfyUI 워크플로우: AnimateDiff + ControlNet | 세라믹 아트 스타일
이 워크플로우는 AnimateDiff, 심도에 초점을 맞춘 ControlNet, 특정 Lora를 활용하여 동영상을 세라믹 아트 스타일로 능숙하게 변환합니다. 다양한 프롬프트를 사용하여 여러 가지 예술 스타일을 구현하고 아이디어를 현실로 만들 수 있습니다.
2. AnimateDiff 사용 방법
AnimateDiff는 Stable Diffusion 모델과 특수 모션 모듈을 활용하여 정적 이미지와 텍스트 프롬프트를 역동적인 비디오로 애니메이션화하도록 설계되었습니다. 프레임 간의 원활한 전환을 예측하여 애니메이션 프로세스를 자동화함으로써 코딩 기술이 없는 사용자도 쉽게 접근할 수 있습니다.
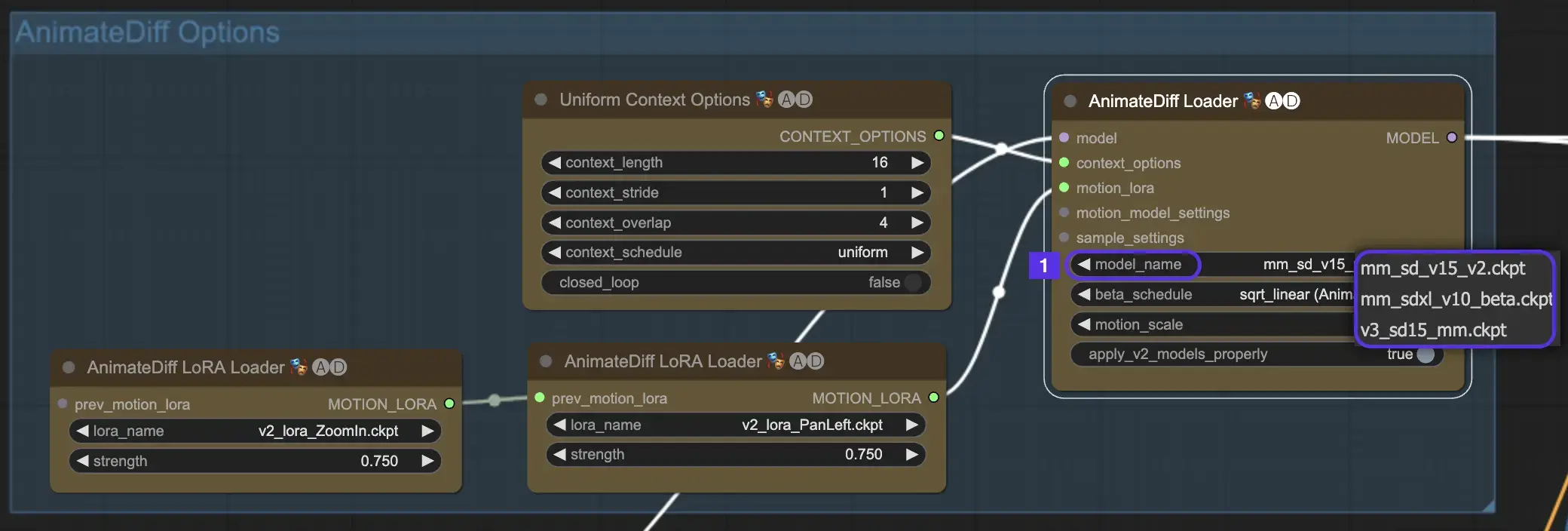
2.1 AnimateDiff 모션 모듈
시작하려면 model_name 드롭다운에서 원하는 AnimateDiff 모션 모듈을 선택하세요:
- AnimateDiff V3의 경우 v3_sd15_mm.ckpt 사용
- AnimateDiff V2의 경우 mm_sd_v15_v2.ckpt 사용
- AnimateDiff SDXL의 경우 mm_sdxl_v10_beta.ckpt 사용
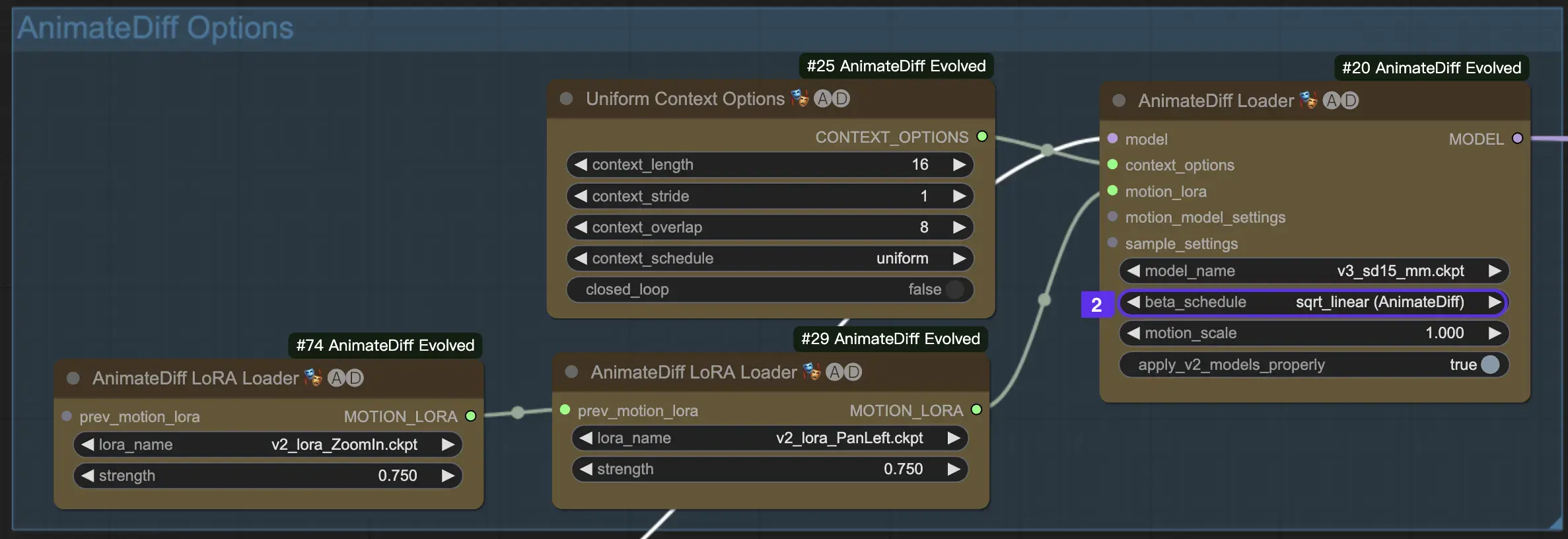
2.2 베타 스케줄
AnimateDiff의 베타 스케줄은 애니메이션 제작 과정 전반에 걸쳐 노이즈 감소 프로세스를 조정하는 데 중요합니다.
AnimateDiff의 V3 및 V2 버전의 경우 sqrt_linear 설정이 권장되지만 linear 설정을 실험하면 독특한 효과를 얻을 수 있습니다.
AnimateDiff SDXL의 경우 linear 설정(AnimateDiff-SDXL)이 권장됩니다.
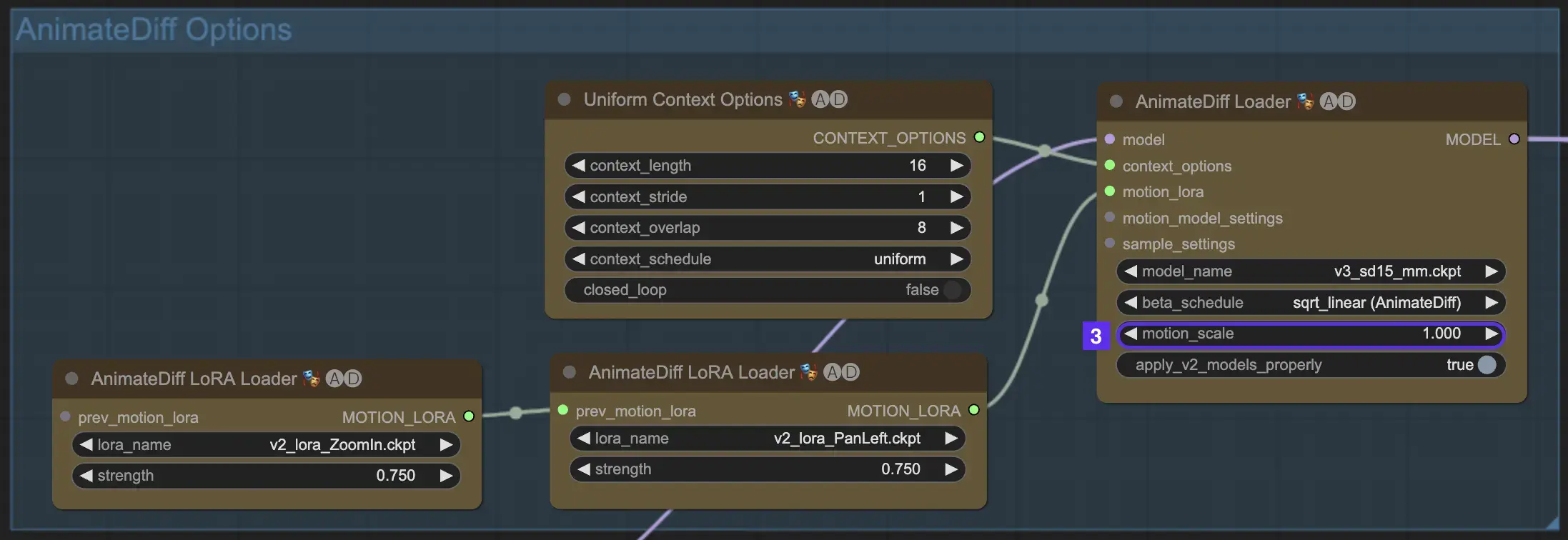
2.3 모션 스케일
AnimateDiff의 모션 스케일 기능을 사용하면 애니메이션의 모션 강도를 조정할 수 있습니다. 모션 스케일이 1 미만이면 더 미묘한 움직임이 발생하고 1을 초과하면 움직임이 증폭됩니다.
2.4 컨텍스트 길이
AnimateDiff의 Uniform Context Length는 Batch Size로 정의된 장면 간의 원활한 전환을 보장하는 데 필수적입니다. 숙련된 편집자처럼 장면을 원활하게 연결하여 자연스러운 내레이션을 만듭니다. Uniform Context Length를 길게 설정하면 더 부드러운 전환이 보장되는 반면, 길이를 짧게 하면 특정 효과에 유리한 더 빠르고 뚜렷한 장면 변화가 이루어집니다. 기본 Uniform Context 길이는 16으로 설정되어 있습니다.
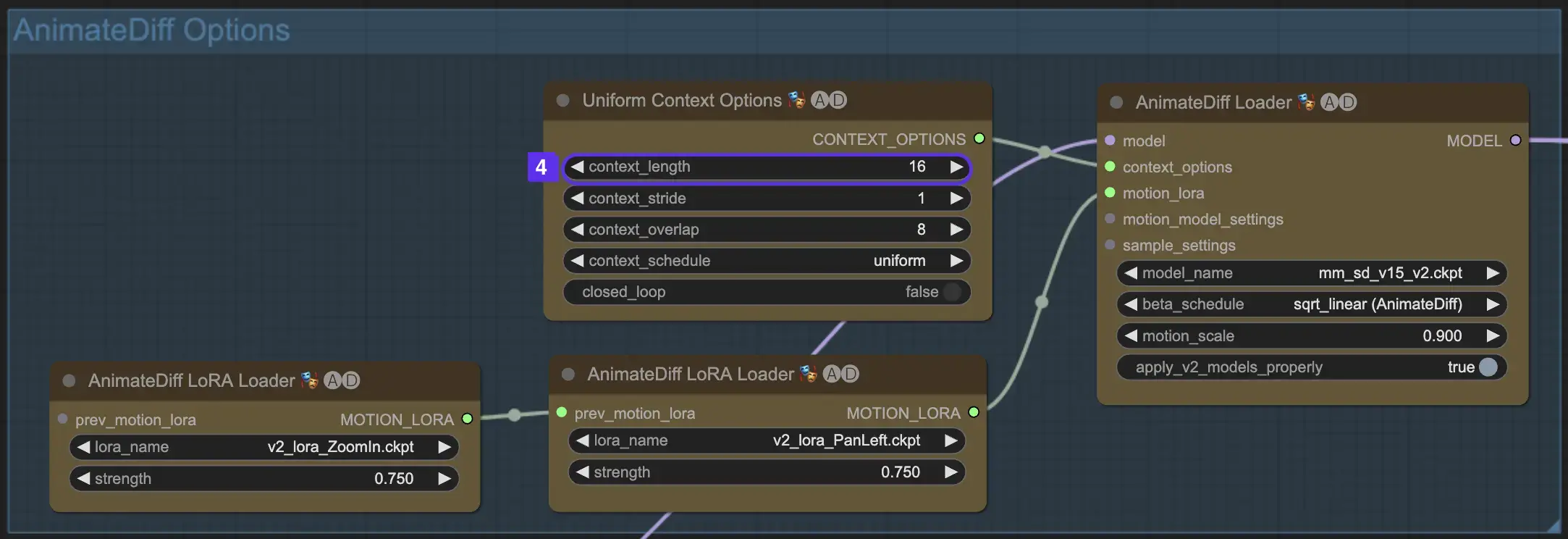
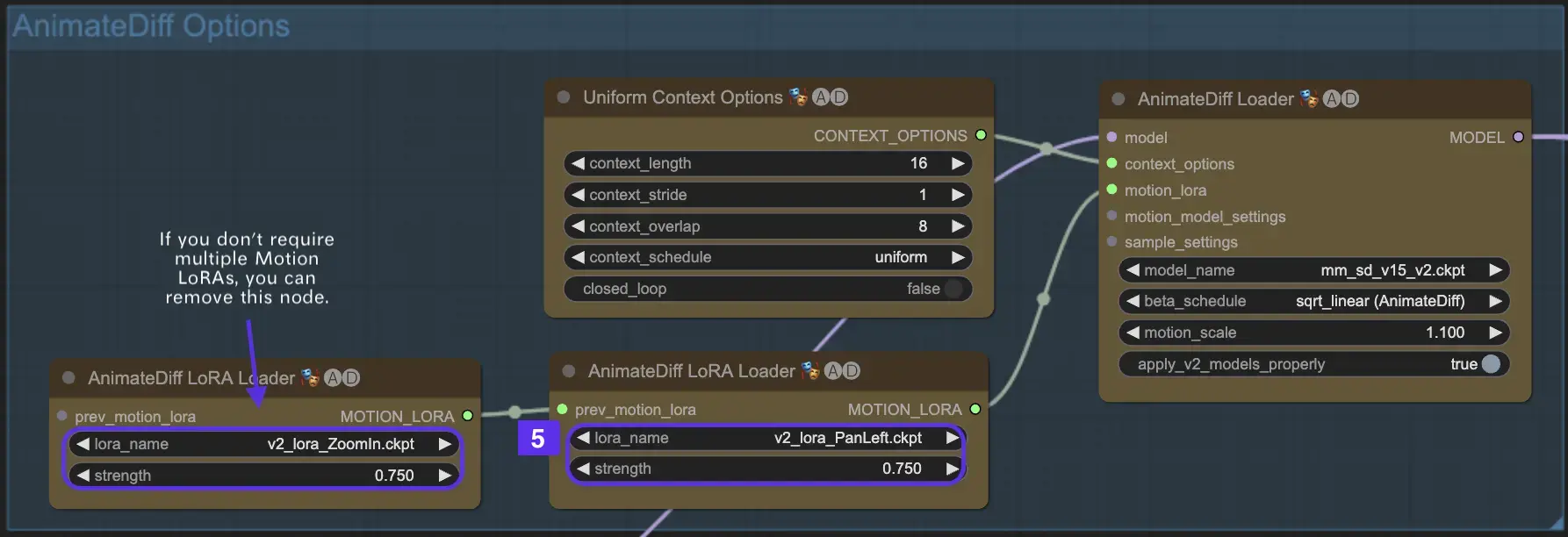
2.5 향상된 카메라 역동성을 위해 Motion LoRA 활용(AnimateDiff v2에만 해당)
AnimateDiff v2에서만 호환되는 Motion LoRA는 역동적인 카메라 움직임의 추가 레이어를 도입합니다. 일반적으로 0.75 정도의 LoRA 가중치와 최적의 균형을 이루면 배경 왜곡 없이 부드러운 카메라 움직임을 보장할 수 있습니다.
또한 다양한 Motion LoRA 모델을 연결하면 복잡한 카메라 역동성을 구현할 수 있습니다. 이를 통해 창작자는 애니메이션에 이상적인 조합을 실험하고 발견하여 애니메이션을 영화 수준으로 끌어올릴 수 있습니다.
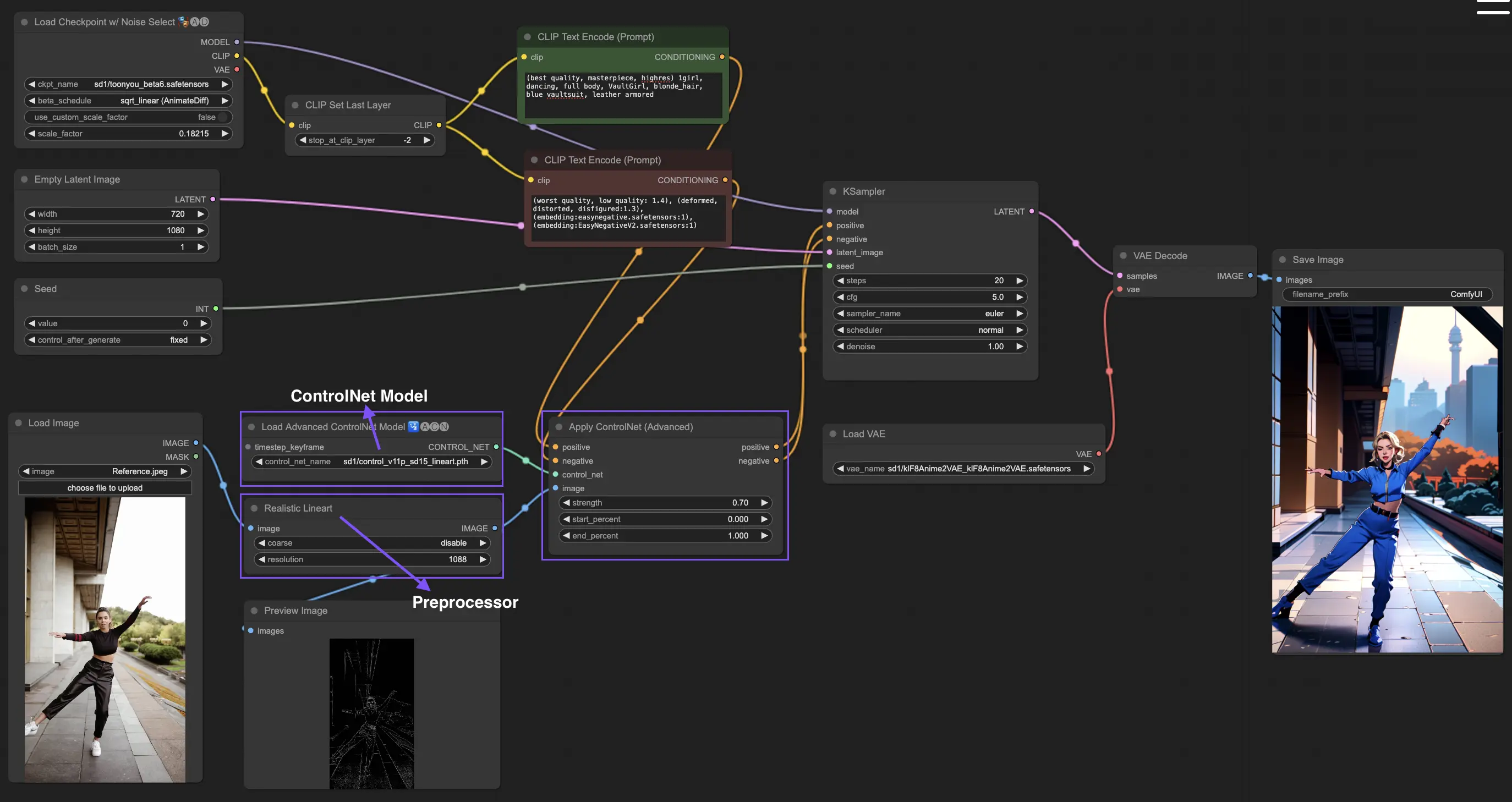
3. ControlNet 사용 방법
ControlNet은 텍스트 기반 이미지 모델에 정확한 공간 제어를 도입하여 사용자가 단순히 텍스트 프롬프트를 넘어 정교한 방식으로 이미지를 조작할 수 있도록 합니다. 이는 Stable Diffusion과 같은 모델의 방대한 라이브러리를 활용하여 스케치, 매핑, 시각적 요소 분할과 같은 복잡한 작업을 수행합니다.
다음은 ControlNet을 사용하는 가장 간단한 워크플로우입니다.
3.1 "Apply ControlNet" 노드 로딩
ComfyUI에서 "Apply ControlNet" 노드를 로드하여 이미지 제작을 시작하면 디자인에서 시각적 요소와 텍스트 요소를 결합하기 위한 준비 단계가 마련됩니다.
3.2 "Apply ControlNet" 노드의 입력
긍정적이고 부정적인 조건 지정을 사용하여 이미지를 구성하고 ControlNet 모델을 선택하여 스타일 특성을 정의한 다음, 이미지를 사전 처리하여 ControlNet 모델 요구 사항과 일치하도록 하여 변환할 준비를 합니다.
3.3 "Apply ControlNet" 노드의 출력
노드 출력은 확산 모델을 안내하여 이미지를 더 세밀하게 다듬거나 ControlNet과 창의적인 입력의 상호 작용을 기반으로 더 많은 세부 정보와 사용자 지정 옵션을 추가할 수 있는 선택권을 제공합니다.
3.4 최상의 결과를 위한 "Apply ControlNet" 튜닝
강도 결정, 시작 백분율 조정, 종료 백분율 설정과 같은 설정을 통해 ControlNet이 이미지에 미치는 영향을 제어하여 이미지의 창작 과정과 결과를 미세 조정할 수 있습니다.
자세한 내용은 을 참조하세요.
이 워크플로우는 의 영감을 받아 일부 수정되었습니다. 자세한 내용은 그의 유튜브 채널을 방문하세요.

