Audioreactive Dancers Evolved
O Workflow Audioreactive Dancers Evolved transforma sujeitos de vídeo em animações cativantes sincronizadas com batidas musicais, ambientadas em fundos dinâmicos, geométricos e psicodélicos. Projetado para flexibilidade, permite aos usuários controlar quadros de vídeo, mascaramento, resposta ao áudio e detalhes de padrões. Com recursos como máscaras de dilatação, ControlNet e animação de ruído sincronizada com batidas, este workflow ComfyUI capacita criativos a misturar arte, som e movimento, criando experiências visuais imersivas e rítmicas com visuais audioreativos.ComfyUI Audioreactive Dancers Evolved Fluxo de Trabalho

- Fluxos de trabalho totalmente operacionais
- Sem nós ou modelos ausentes
- Nenhuma configuração manual necessária
- Apresenta visuais impressionantes
ComfyUI Audioreactive Dancers Evolved Exemplos
ComfyUI Audioreactive Dancers Evolved Descrição
Crie animações de vídeo impressionantes transformando seu sujeito (dançarino) e dê a eles um fundo dinâmico audioreativo composto por várias geometrías intrincadas e padrões psicodélicos. Você pode usar este workflow com um único sujeito ou múltiplos sujeitos. Com este workflow, você pode produzir efeitos visuais audioreativos hipnotizantes que se sincronizam perfeitamente com o ritmo da música, oferecendo uma experiência imersiva. O workflow permite que você o use com um único sujeito ou múltiplos sujeitos, todos aprimorados com elementos audioreativos.
Como usar o Workflow Audioreactive Dancers Evolved:
- Carregue um vídeo do sujeito na seção de Input
- Selecione a largura e altura desejadas do vídeo final, juntamente com quantos quadros do vídeo de entrada devem ser pulados com "every_nth". Você também pode limitar o número total de quadros a serem renderizados com "frame_load_cap".
- Preencha os prompts positivos e negativos. Defina os tempos dos quadros em lote para coincidir com quando você gostaria que as transições de cena ocorressem.
- Carregue imagens para cada uma das cores de máscara de sujeito padrão do IP Adapter:
- Vermelho, Verde, Azul = sujeito(s)
- Preto = Fundo
- Branco = Máscara de dilatação audioreativa branca
- Amarelo, Magenta = Padrões de máscara de ruído de fundo
- Carregue um bom checkpoint LCM (eu uso ParadigmLCM por Machine Delusions) na seção "Models".
- Adicione quaisquer loras usando a pilha de Lora abaixo do carregador de modelos
- Clique em Queue Prompt
Guia em Vídeo
Cor de Nó e Grupo
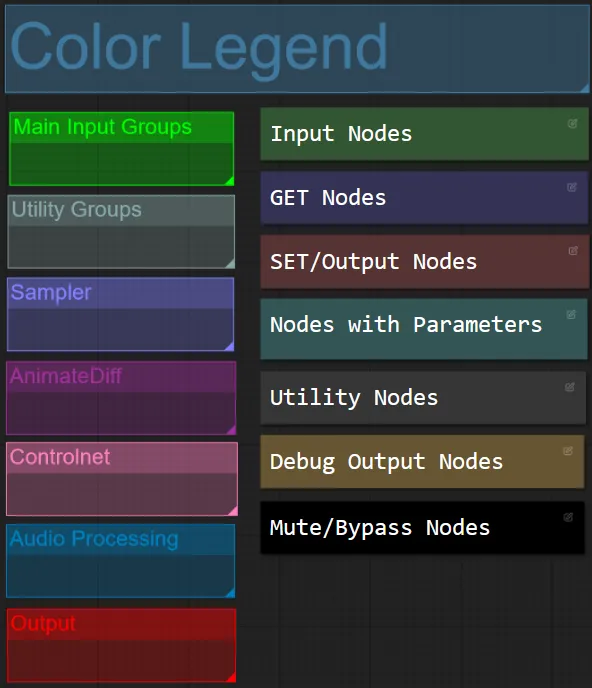
- Para este workflow, coordenei as cores dos nós com base em sua funcionalidade dentro de cada grupo.
- Os títulos das seções dos grupos são coordenados por cores para facilitar a diferenciação.
Input
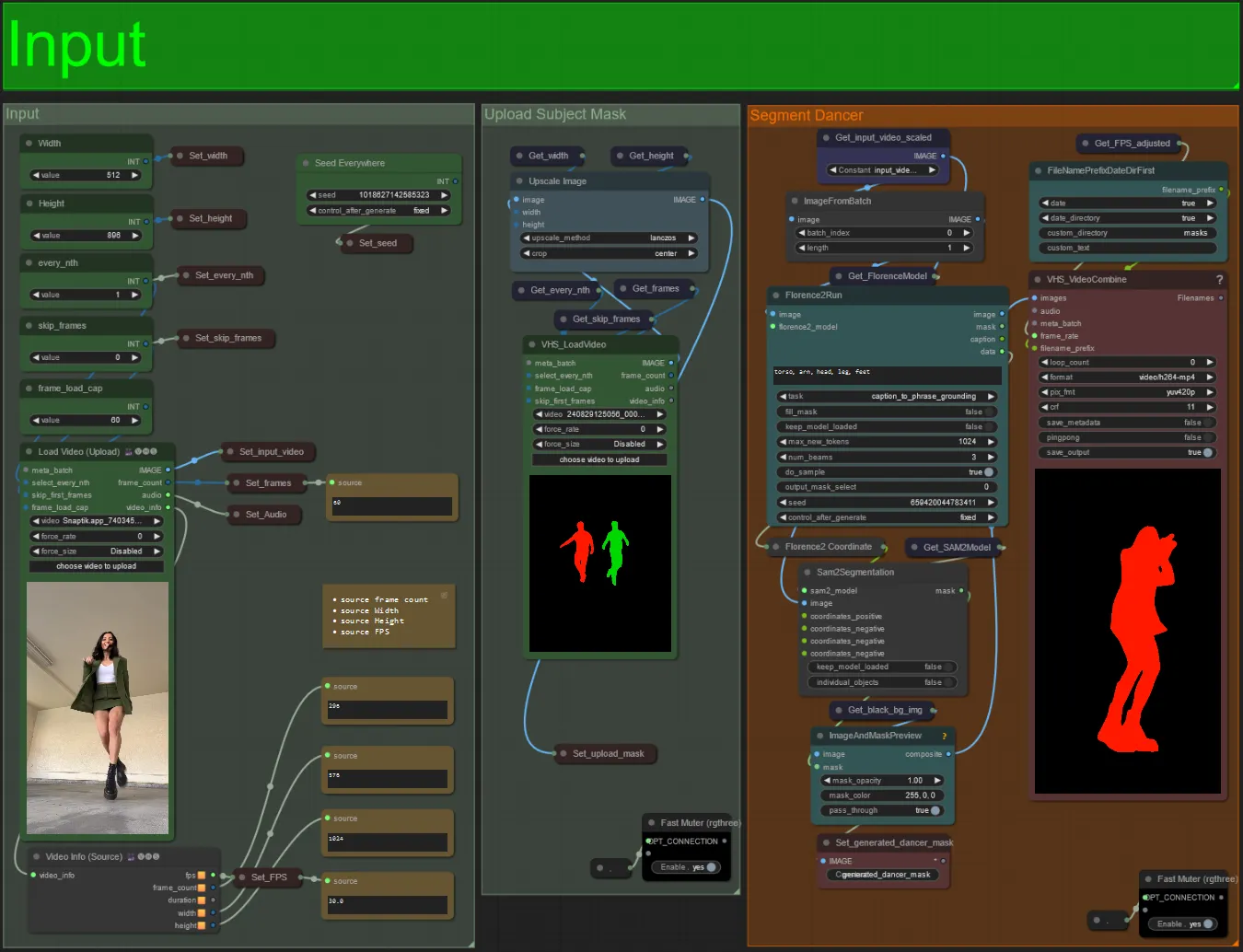
- Carregue seu vídeo de sujeito desejado no nó Load Video (Upload).
- Você pode ajustar a largura e altura de saída usando as duas entradas no canto superior esquerdo.
- every_nth define se deve usar cada outro quadro, cada terceiro quadro e assim por diante (2 = cada outro quadro). Deixado em 1 por padrão.
- skip_frames é usado para pular quadros no início do vídeo. (100 = pular os primeiros 100 quadros do vídeo de entrada). Deixado em 0 por padrão.
- frame_load_cap é usado para especificar quantos quadros totais do vídeo de entrada devem ser carregados. Melhor manter baixo ao testar configurações (30 - 60, por exemplo) e depois aumentar ou definir para 0 (sem limite de quadros) ao renderizar o vídeo final.
- Os campos numéricos no canto inferior direito exibem informações sobre o vídeo de entrada carregado: quadros totais, largura, altura e FPS de cima para baixo.
- Se você já tiver um vídeo de máscara do sujeito gerado, pode desmutar a seção "Upload Subject Mask" e carregar o vídeo de máscara. Opcionalmente, você pode mutar a seção "Segment Dancer" para economizar algum tempo de processamento.
- Às vezes, o sujeito segmentado não será perfeito, você pode verificar a qualidade da máscara usando a caixa de visualização no canto inferior direito vista acima. Se for esse o caso, você pode brincar com o prompt no nó "Florence2Run" para direcionar diferentes partes do corpo, como "cabeça", "peito", "pernas", etc., e ver se obtém um resultado melhor.
Prompt
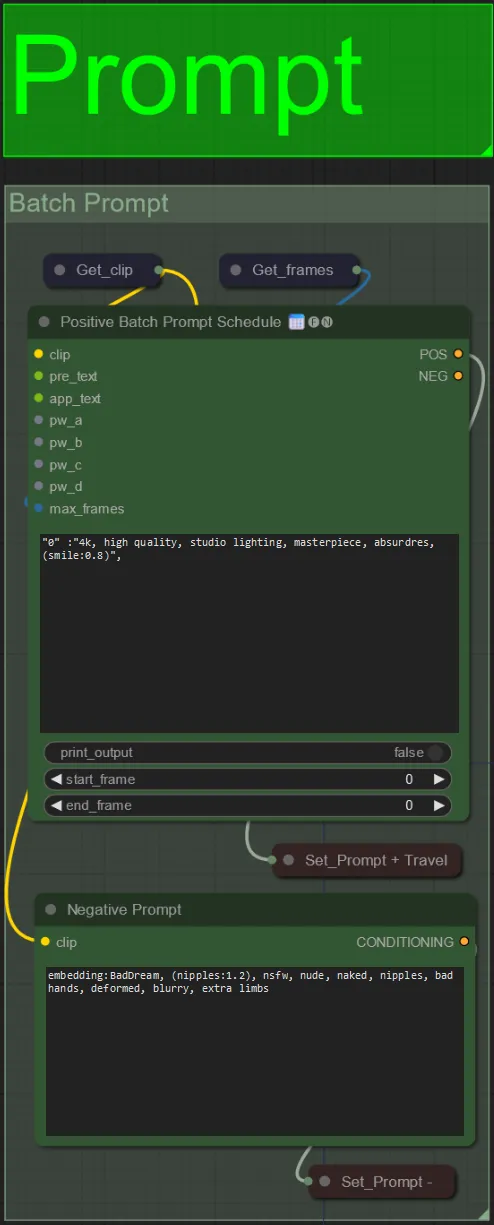
- Defina o prompt positivo usando formatação em lote:
- por exemplo, "0": "4k, obra-prima, 1 garota em pé na praia, absurdres", "25": "HDR, cena de pôr do sol, 1 garota com cabelo preto e uma jaqueta branca, absurdres", …
- O prompt negativo está em formato normal, você pode adicionar embeddings se desejar.
Processamento de Áudio
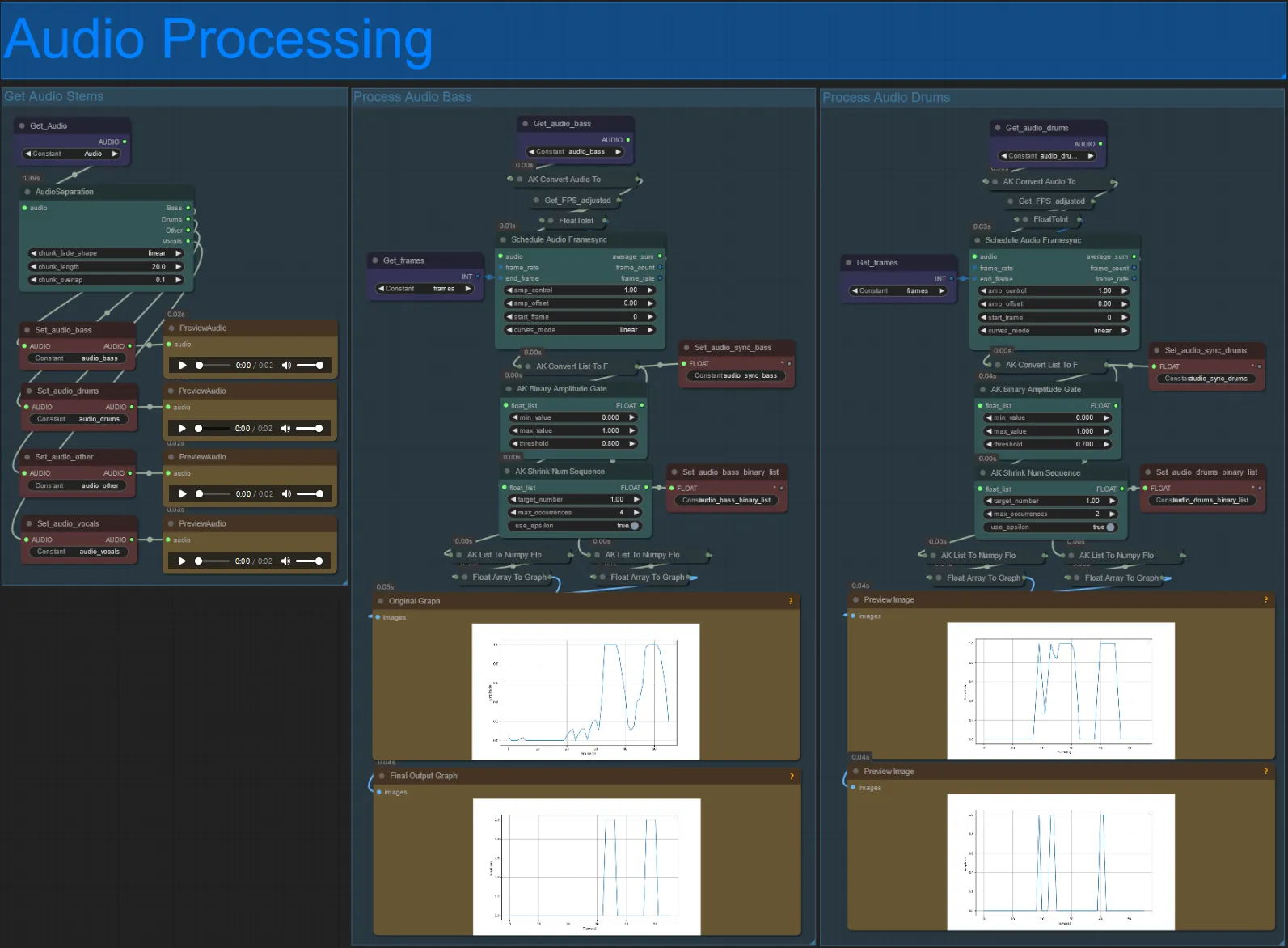
- Esta seção recebe o áudio do vídeo de entrada, extrai os stems (baixo, bateria, vocais, etc.) e depois o converte em uma amplitude normalizada sincronizada com os quadros do vídeo de entrada, para criar visuais audioreativos.
- amp_control = alcance total que a amplitude pode percorrer.
- amp_offset = o valor mínimo que a amplitude pode assumir.
- Exemplo: amp_control = 0.8 e amp_offset = 0.2 significa que o sinal percorrerá entre 0.2 e 1.0.
- Às vezes, o stem de Bateria terá as notas reais de Baixo da música, visualize cada um para ver qual usar para suas máscaras audioreativas.
- Use os gráficos para obter uma boa compreensão de como o sinal para aquele stem muda ao longo do vídeo
Geradores de Voronoi
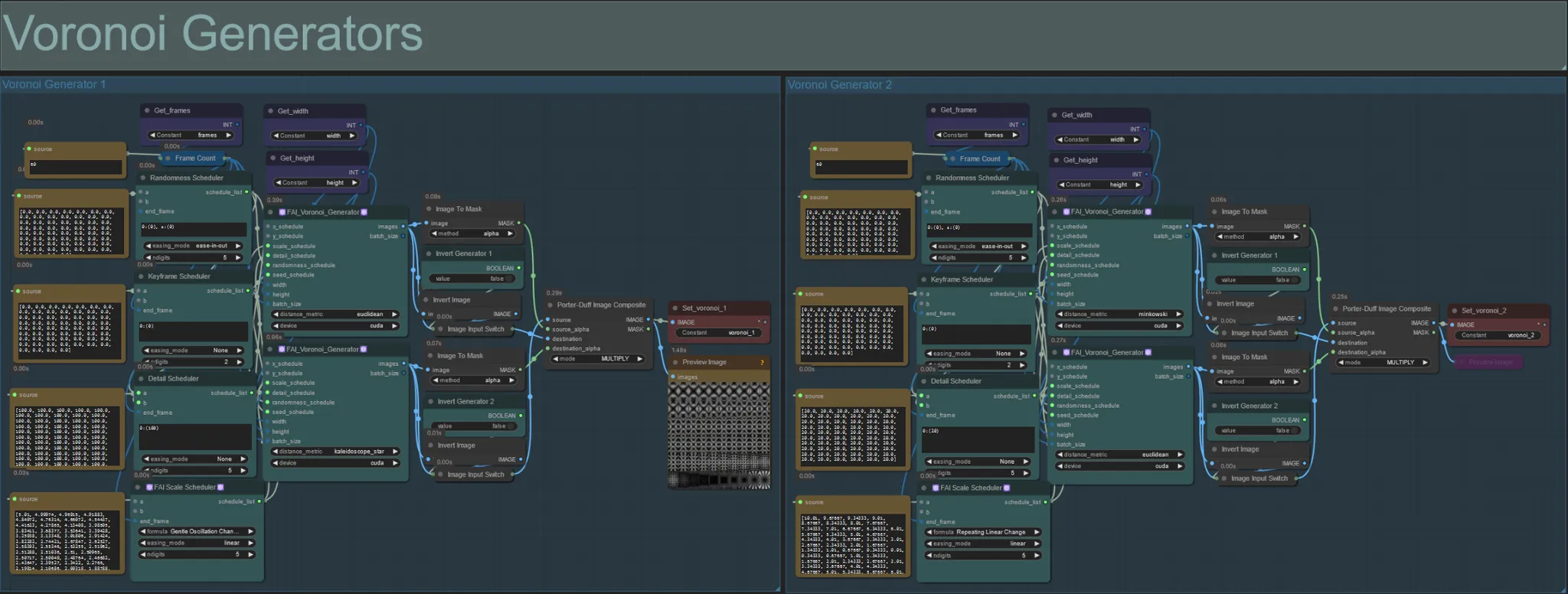
- Esta seção gera padrões de ruído Voronoi usando dois nós customizados FAI_Voronoi_Generator por grupo que são compostos juntos usando um Multiply.
- Você pode aumentar os valores do Randomness Scheduler nos parênteses de 0 para quebrar padrões simétricos no resultado final.
- Aumente o valor do Detail Scheduler nos parênteses para aumentar a contagem de detalhes nos padrões de ruído de saída. Valores mais baixos resultam em menor diferenciação de ruído.
- Altere os parâmetros "formula" no nó FAI Scale Scheduler para ter um grande impacto no movimento do padrão de ruído final.
- Você também pode mudar a função "distance_metric" nos próprios nós FAI_Voronoi_Generator para afetar grandemente os padrões e formas geradas do ruído resultante.
Máscaras de Áudio
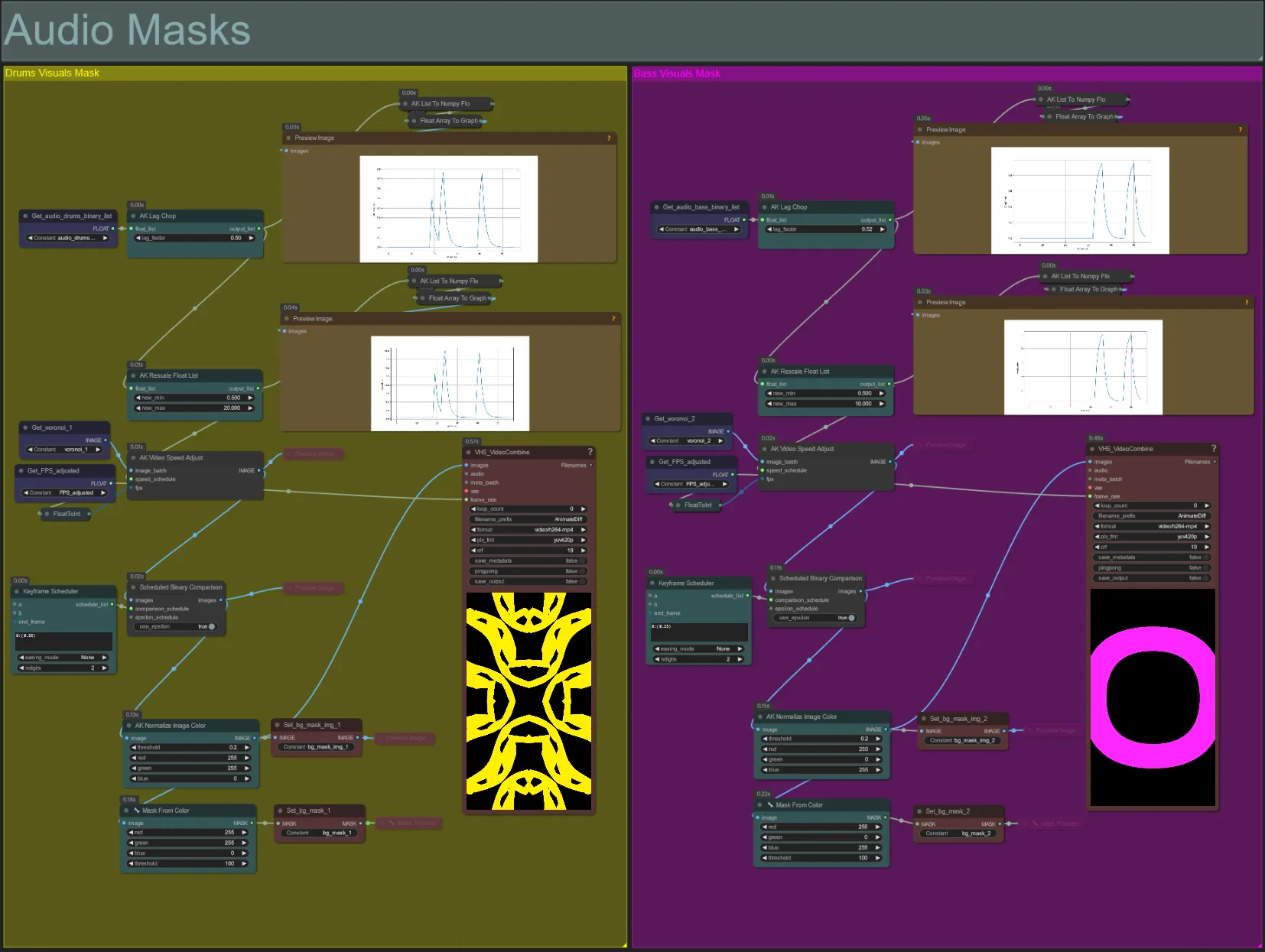
- Esta seção é usada para converter os lotes de imagem de ruído Voronoi em máscaras coloridas a serem compostas com o sujeito, bem como sincronizar seus movimentos com a batida de qualquer um dos stems de baixo ou bateria. Essas máscaras são essenciais para criar efeitos audioreativos.
- Aumente o "lag_factor" no nó AK Lag Chop para aumentar o quão "pontiagudos" os gráficos de amplitude final serão. Isso fará com que o movimento do ruído de saída acelere e desacelere mais subitamente, enquanto um lag_factor mais baixo resultará em uma desaceleração mais gradual do movimento após cada batida. Isso é usado para evitar que a animação da máscara de ruído pareça muito "saltitante" e rígida.
- O AK Rescale Float List é usado para remapear os valores de amplitude normalizados de 0-1 para new_min e new_max. Um valor de 1.0 representa velocidade de reprodução de 30FPS da animação de ruído, enquanto 0.5 representa 15FPS, 2.0 representa 60FPS, etc. Ajuste este valor para mudar o quão lentamente o padrão de ruído audioreativo anima fora da batida (amplitude 0.0), e quão rápido ele se move na batida (amplitude 1.0).
- O Keyframe Scheduler tem um grande efeito na aparência da máscara. Ele cria uma lista de valores float para especificar o limite de valores de brilho de pixel a serem usados para as imagens de entrada de ruído, o que resultará em parte do ruído sendo cortado e transformado na máscara final. Reduza este valor para reter mais do ruído de entrada e aumente para reter menos do ruído.
Dilate Masks
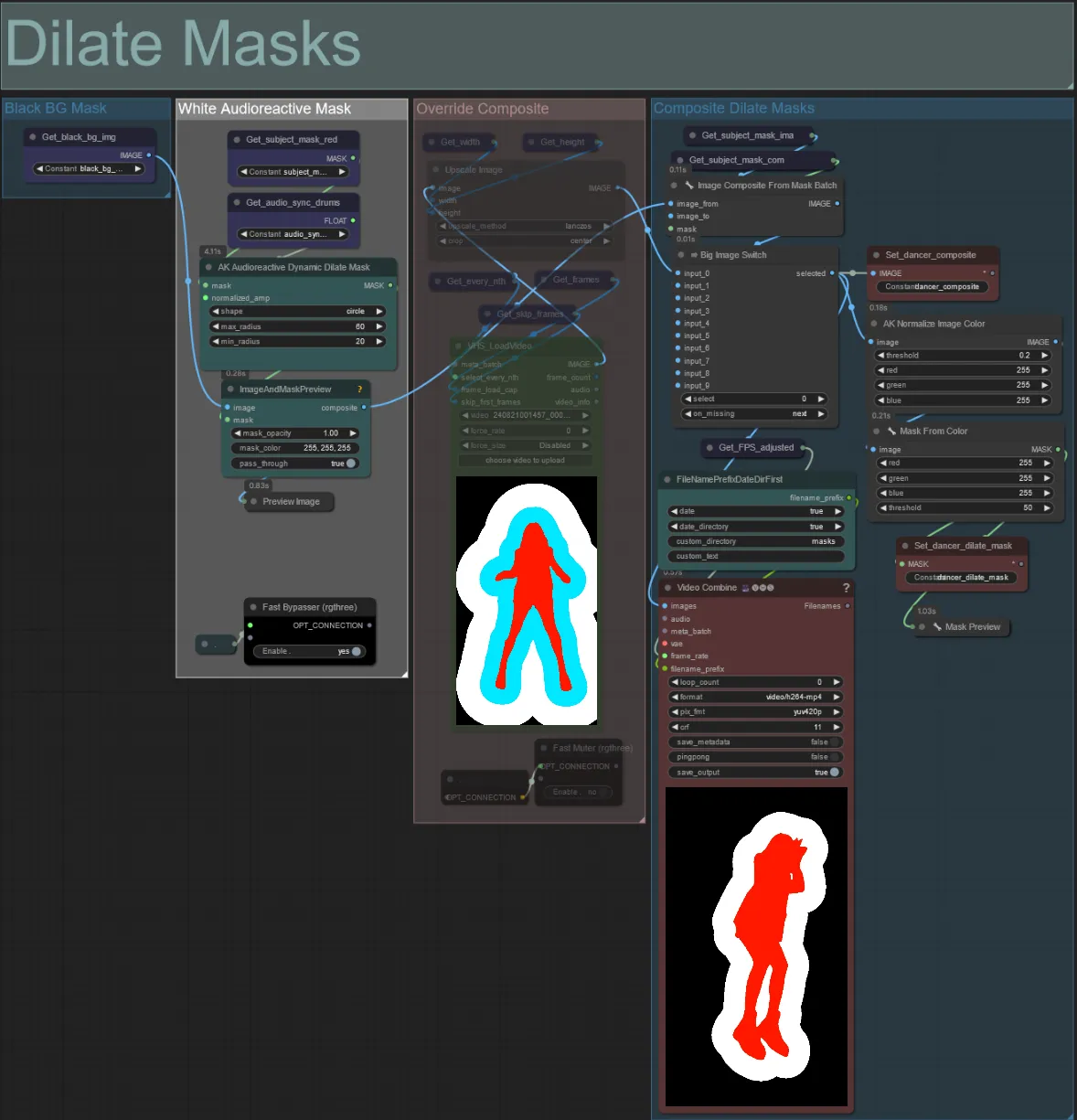
- Cada grupo colorido corresponde à cor da máscara de dilatação que será gerada por ele.
- Você pode definir o raio mínimo e máximo da máscara de dilatação, bem como a forma usando o seguinte nó:
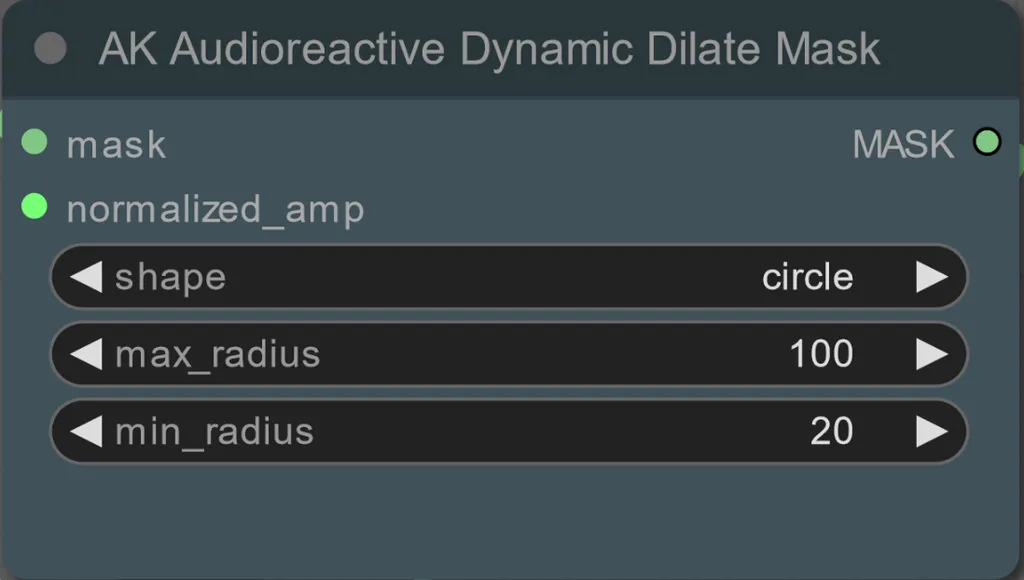
- shape: "circle" é o mais preciso, mas leva mais tempo para gerar. Defina isso quando estiver pronto para realizar a renderização final. "square" é rápido de calcular, mas menos preciso, melhor para testar o workflow e decidir sobre imagens do IP adapter.
- max_radius: O raio da máscara em pixels quando o valor da amplitude é máximo (1.0).
- min_radius: O raio da máscara em pixels quando o valor da amplitude é mínimo (0.0).
- Se você já tiver um vídeo de máscara composto gerado, pode desmutar o grupo "Override Composite Mask" e carregá-lo. Recomenda-se ignorar os grupos de máscara de dilatação se estiver substituindo para economizar tempo de processamento.
Máscara de Ruído Latente
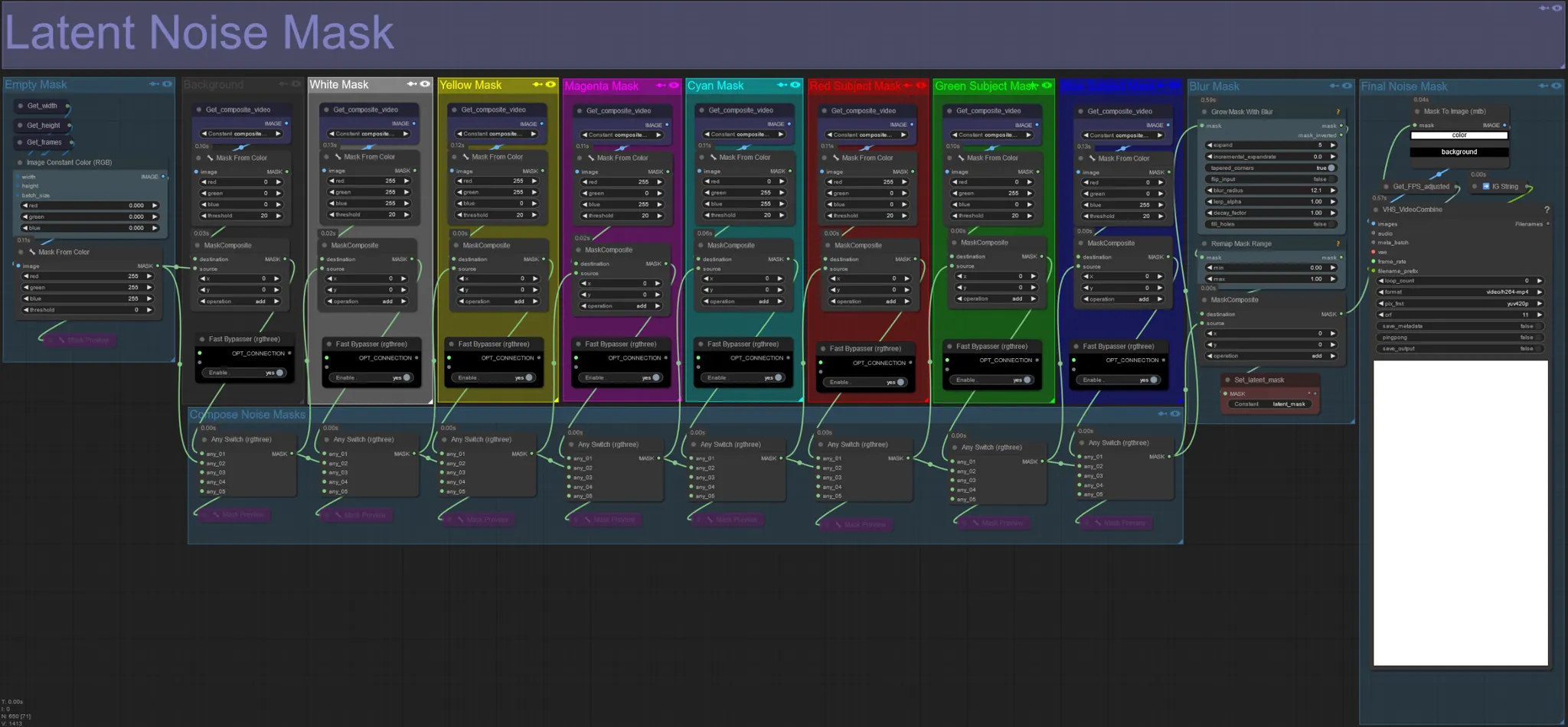
- Use máscaras de ruído latente para controlar quais máscaras são realmente difusas (sonhadas) pelo ksampler. Ignore o grupo correspondente à máscara colorida que você não deseja que seja difusa (ou seja, deseja ter elementos do vídeo original aparecendo).
- Deixar todos os grupos de máscara habilitados resulta em uma máscara de ruído final branca (tudo será difuso).
- Exemplo: Ignore o grupo Red Subject Mask clicando no nó Fast Bypasser para que seu dançarino ou sujeito apareça no resultado final.
Original Input Video:

Ignorando os Grupos de Máscara Vermelho e Amarelo:

Máscara Composta
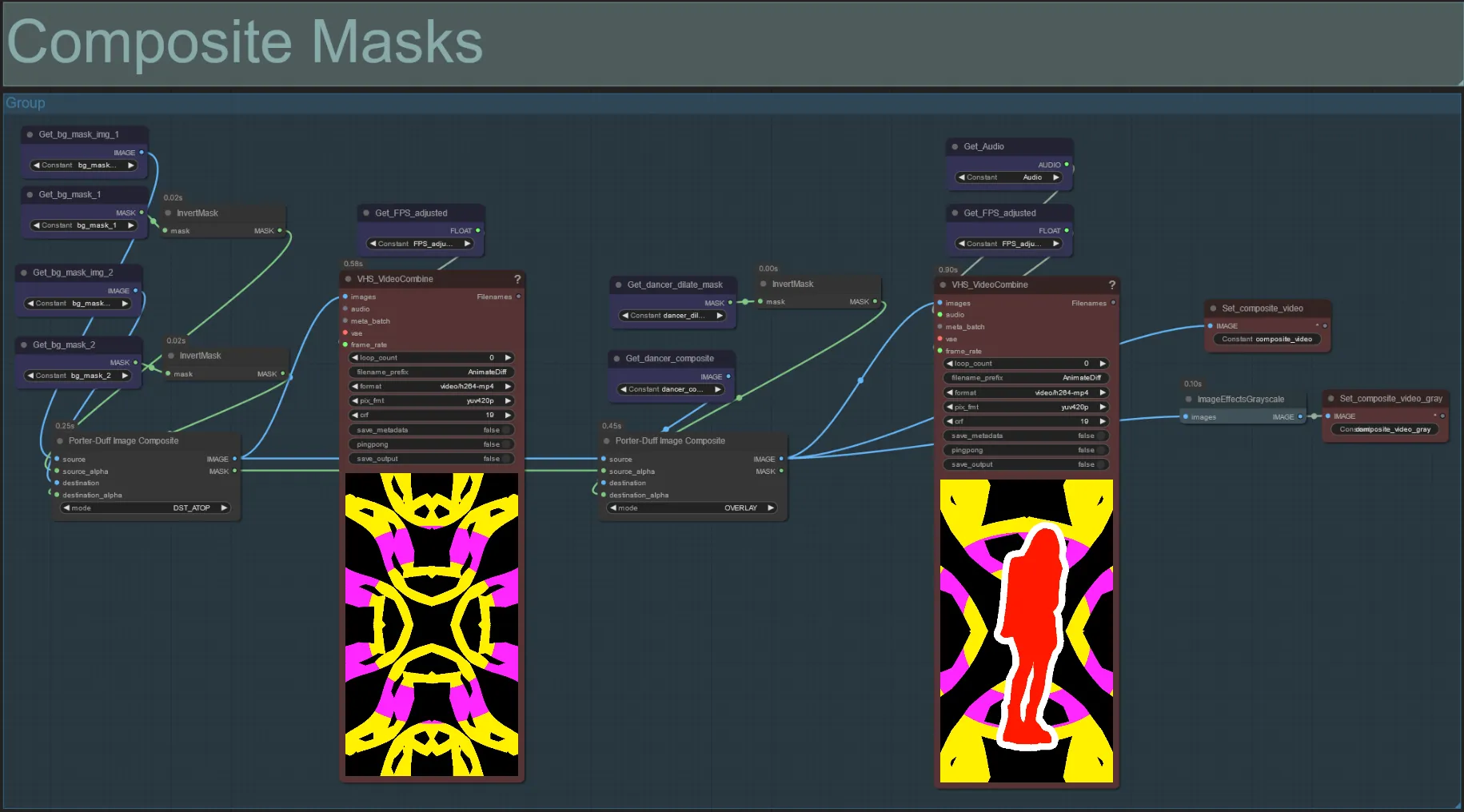
- Esta seção cria a composição final das máscaras de ruído Voronoi com a máscara do sujeito (e máscara de dilatação audioreativa, se habilitada).
Modelos
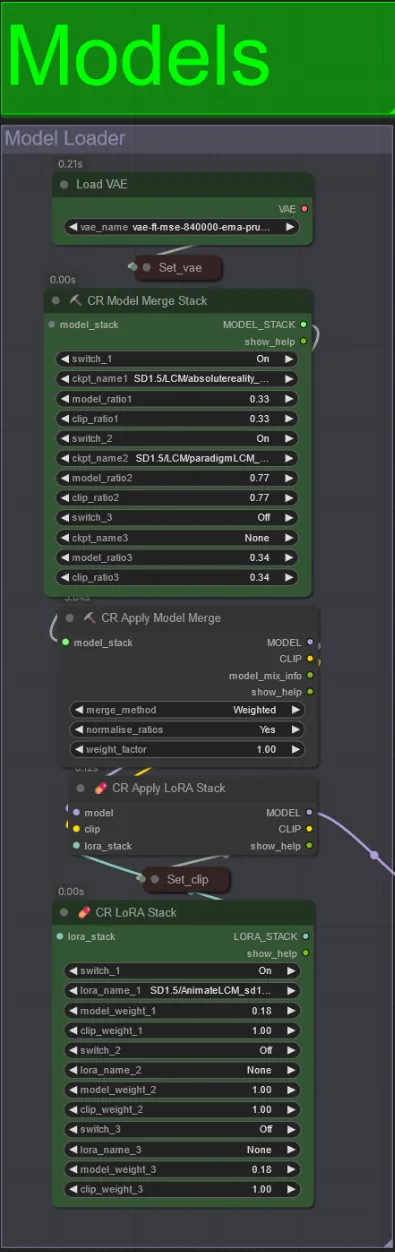
- Use um bom modelo LCM para o checkpoint. Eu recomendo ParadigmLCM por Machine Delusions.
- Você pode mesclar vários modelos juntos usando a pilha Model Merge para obter vários efeitos interessantes. Certifique-se de que os pesos somam 1.0 para os modelos habilitados.
- Você pode opcionalmente especificar o AnimateLCM_sd15_t2v_lora.safetensors com um peso baixo de 0.18 para aprimorar ainda mais o resultado final.
- Adicione quaisquer Loras adicionais ao modelo usando o Lora stacker abaixo do carregador de modelos.
AnimateDiff

- Você pode definir um Motion Lora diferente em vez do que eu usei (LiquidAF-0-1.safetensors)
- Aumente/diminua os floats Scale e Effect para aumentar/diminuir a quantidade de movimento na saída.
IP Adapters
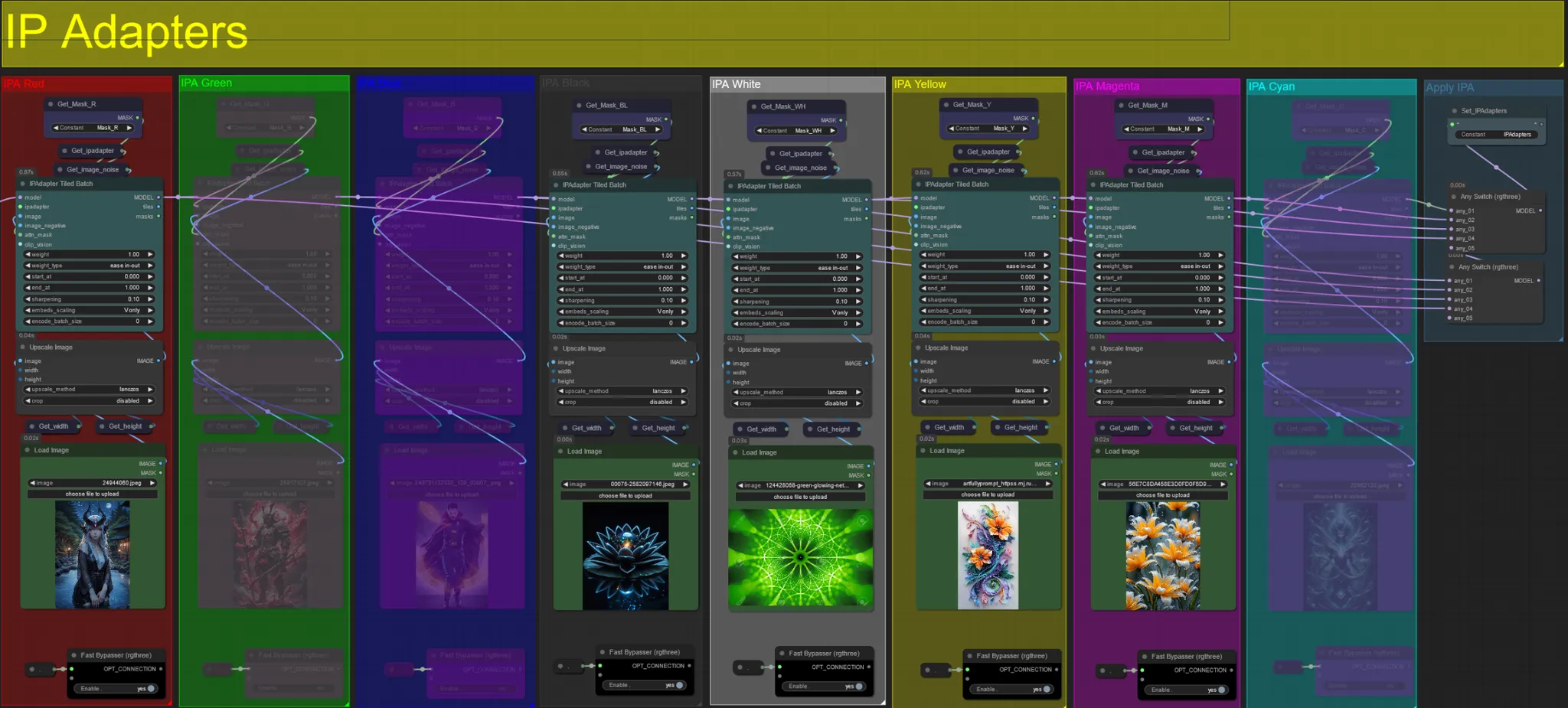
- Aqui você pode especificar as imagens de referência que serão usadas para renderizar os fundos para cada uma das máscaras de dilatação, bem como seu(s) sujeito(s) de vídeo.
- A cor de cada grupo representa a máscara que ele mira:
Vermelho, Verde, Azul:
- Imagens de referência de máscara de sujeito.
Preto:
- Imagem de máscara de fundo, carregue uma imagem de referência para o fundo.
Branco:
- Imagens de referência de máscara de dilatação, carregue uma imagem de referência para cada máscara de dilatação de cor em uso.
Amarelo, Magenta
- Imagens de referência de máscara de ruído Voronoi.
ControlNet
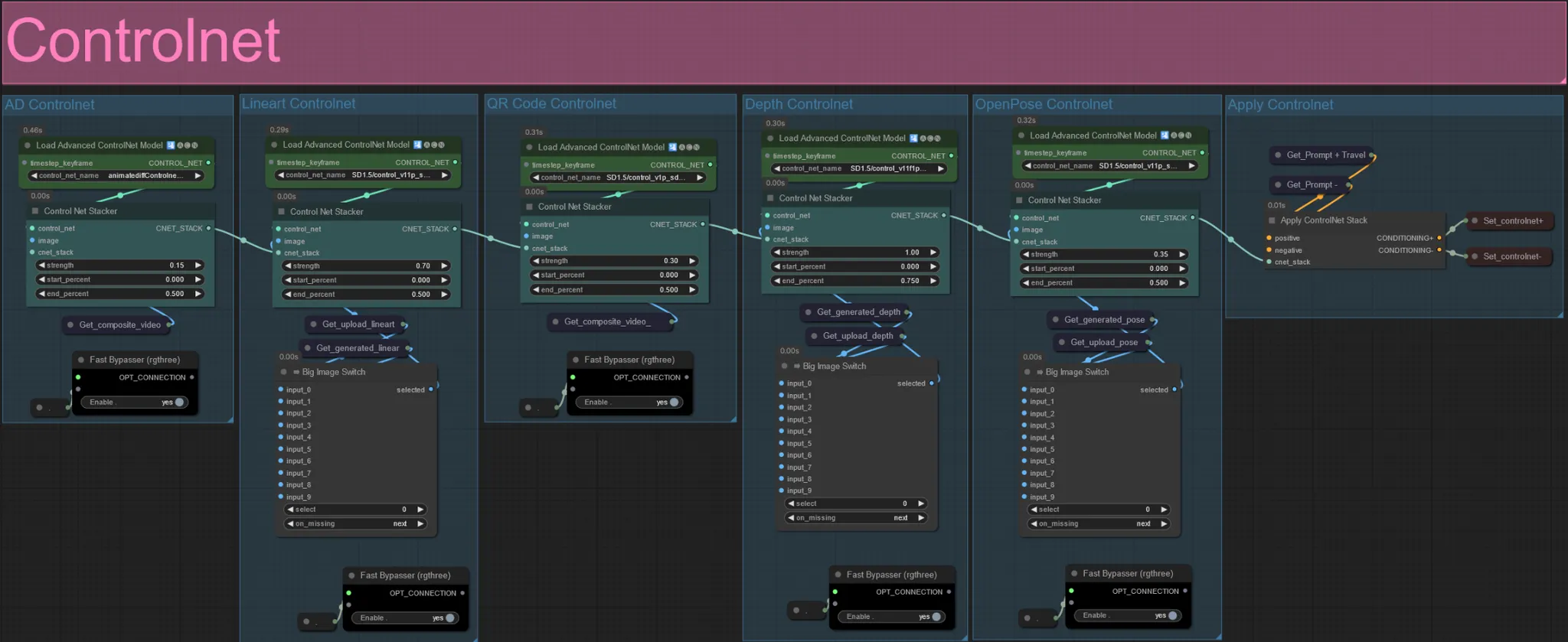
- Este workflow faz uso de 5 controlnets diferentes, incluindo AD, Lineart, QR Code, Depth e OpenPose.
- Todas as entradas para os controlnets são geradas automaticamente
- Você pode optar por substituir o vídeo de entrada para os controlnets de Lineart, Depth e Openpose, se desejado, desmutando os grupos "Override " como visto abaixo:
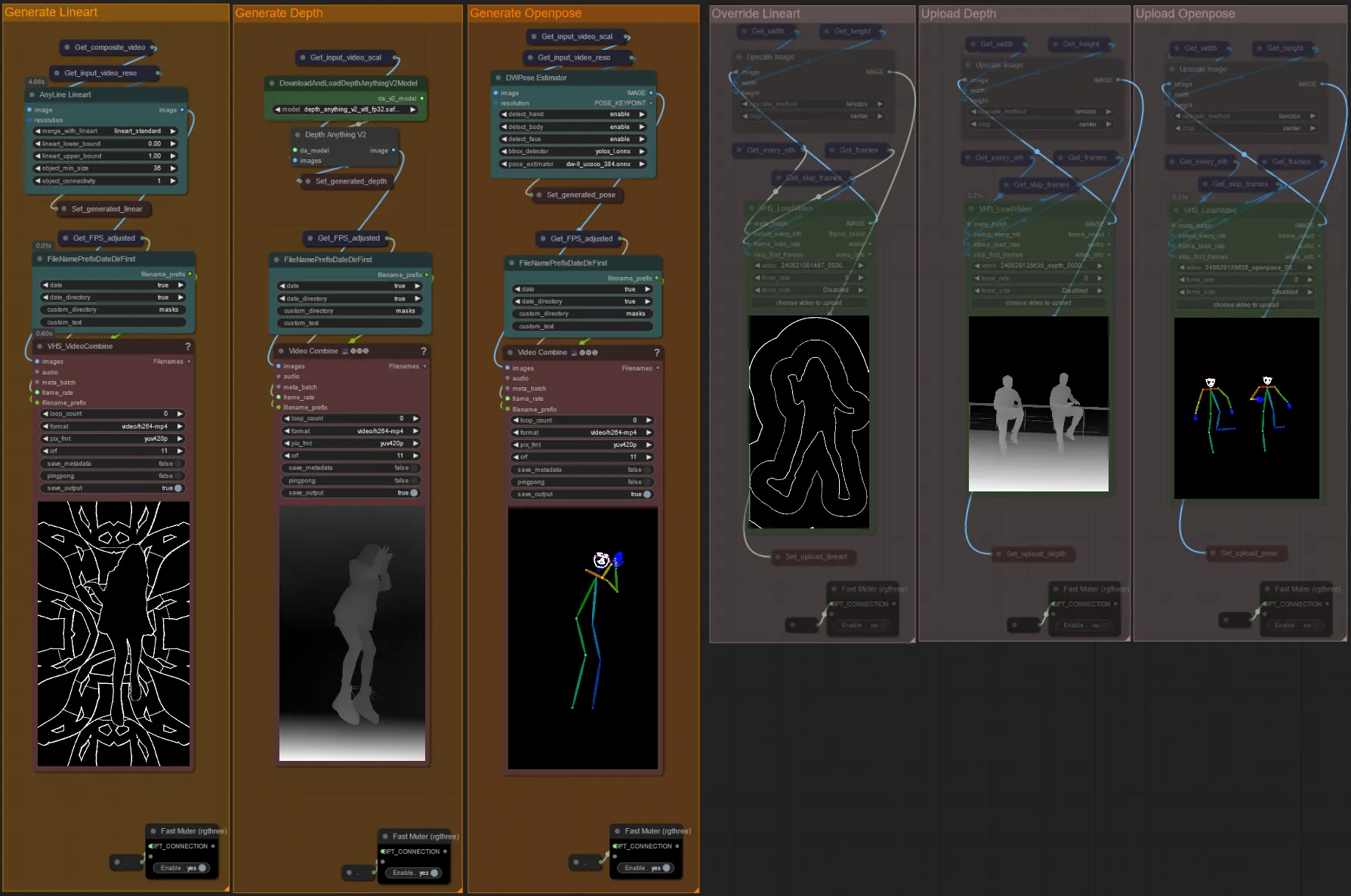
- Recomenda-se também mutar os grupos "Generate" se estiver substituindo para economizar tempo de processamento.
Dica:
- Ignore o Ksampler e inicie uma renderização com seu vídeo de entrada completo. Depois que todos os vídeos de pré-processamento forem gerados, salve-os e carregue-os nos respectivos substitutos. A partir de agora, ao testar o workflow, você não terá que esperar que cada vídeo de pré-processamento seja gerado individualmente.
Sampler
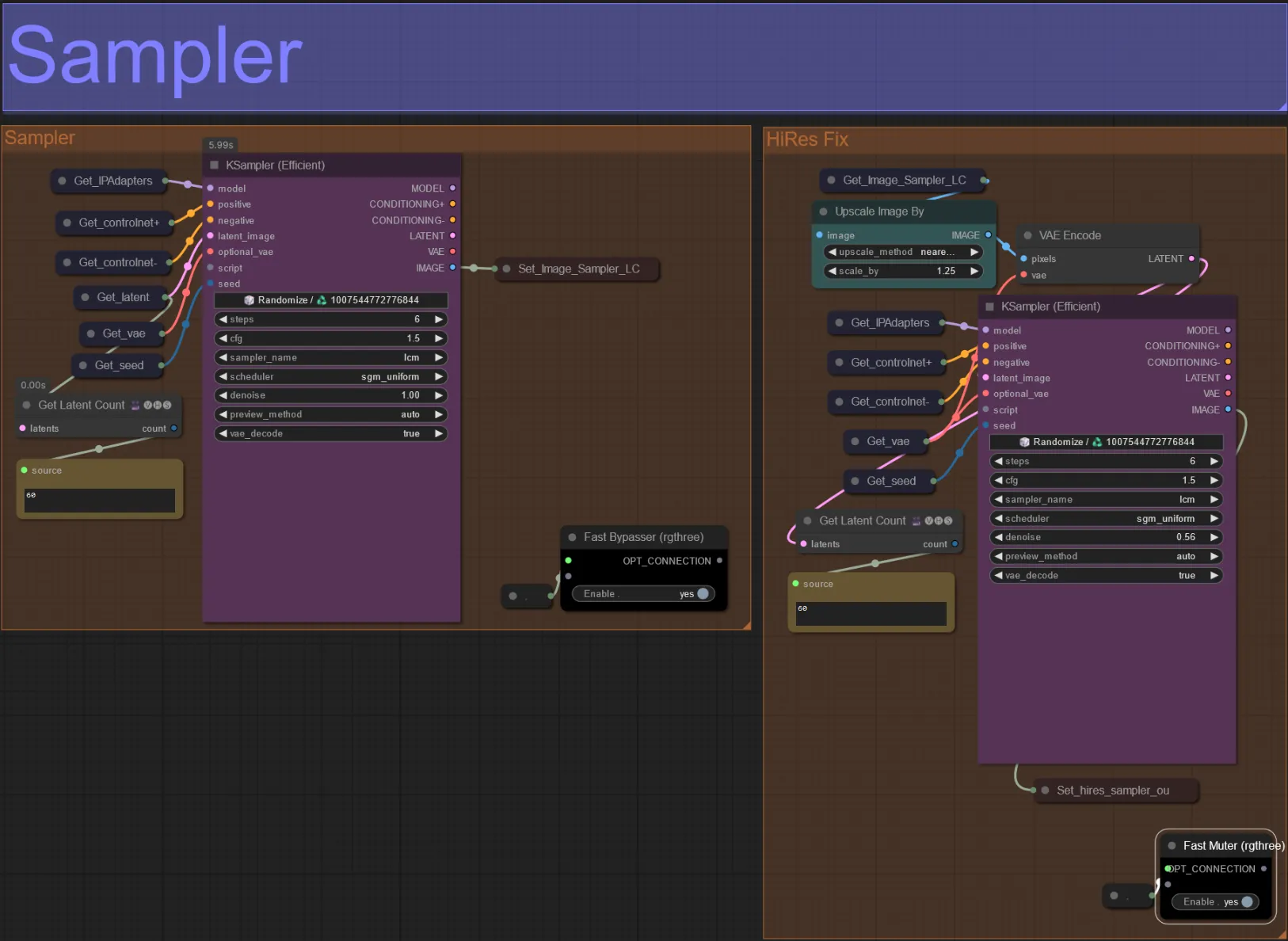
- Por padrão, o grupo HiRes Fix sampler será mutado para economizar tempo de processamento ao testar
- Recomendo ignorar o grupo Sampler também ao tentar experimentar configurações de máscara de dilatação para economizar tempo.
- Nas renderizações finais, você pode desmutar o grupo HiRes Fix, que irá aumentar a escala e adicionar detalhes ao resultado final.
Output
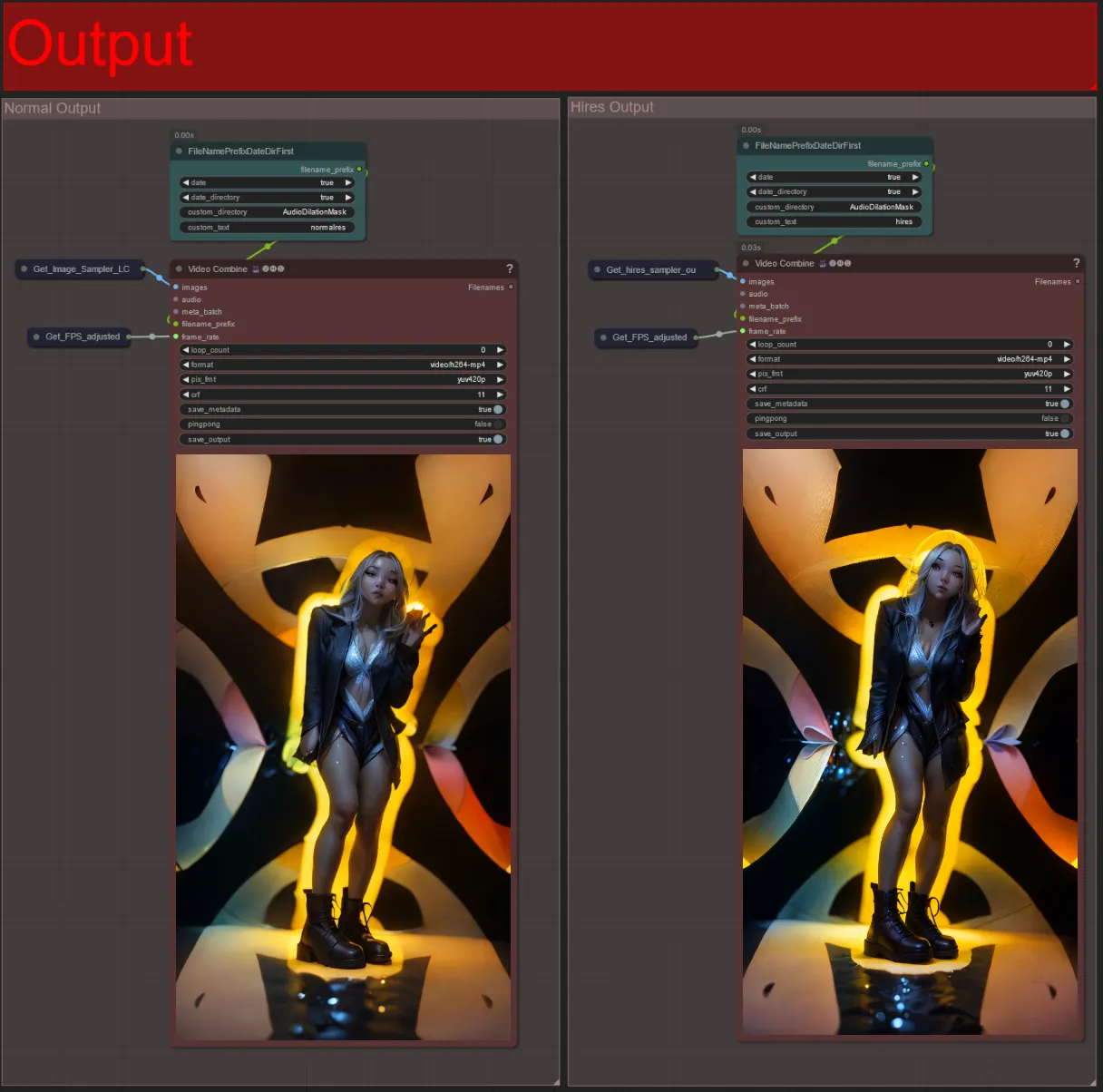
- Existem dois grupos de saída: o da esquerda é para saída de sampler padrão, e o da direita é para saída de sampler HiRes Fix.
- Você pode mudar onde os arquivos serão salvos mudando a string "custom_directory" nos nós "FileNamePrefixDateDirFirst". Por padrão, este nó salvará os vídeos de saída em um diretório com carimbo de data/hora no diretório "output" do ComfyUI
- por exemplo,
…/ComfyUI/output/240812/<custom_directory>/<my_video>.mp4
- por exemplo,
Criar um vídeo audioreativo pode adicionar energia pulsante e imersiva ao seu sujeito, com cada quadro respondendo à batida em tempo real. Então, mergulhe no mundo da arte audioreativa e aproveite as transformações guiadas pelo ritmo!
Sobre o Autor
Akatz AI:
- Website:
Contatos:
- Email: akatzfey@sendysoftware.com


