
1. O que é Omost?
Omost, abreviação de "Sua imagem está quase pronta!", é um projeto inovador que converte as capacidades de codificação dos Modelos de Linguagem de Grande Escala (LLM) em geração de imagens, ou mais precisamente, em capacidades de composição de imagens. O nome "Omost" tem um duplo significado: implica que toda vez que você usa o Omost, sua imagem está quase completa, e também significa "omni" (multimodal) e "most" (aproveitar ao máximo).
Omost fornece modelos LLM pré-treinados que geram código para compor conteúdo visual de imagens usando o agente virtual Canvas do Omost. Este Canvas pode então ser renderizado por implementações específicas de geradores de imagens para criar as imagens finais. O Omost é projetado para simplificar e aprimorar o processo de geração de imagens, tornando-o acessível e eficiente para artistas de IA.
2. Como o Omost Funciona
2.1. Canvas e Descrições
Omost usa um Canvas virtual onde elementos da imagem são descritos e posicionados. O Canvas é dividido em uma grade de 9x9=81 posições, permitindo colocação precisa dos elementos. Essas posições são refinadas em caixas delimitadoras, proporcionando 729 locais diferentes possíveis para cada elemento. Esta abordagem estruturada garante que os elementos sejam colocados de maneira precisa e consistente.
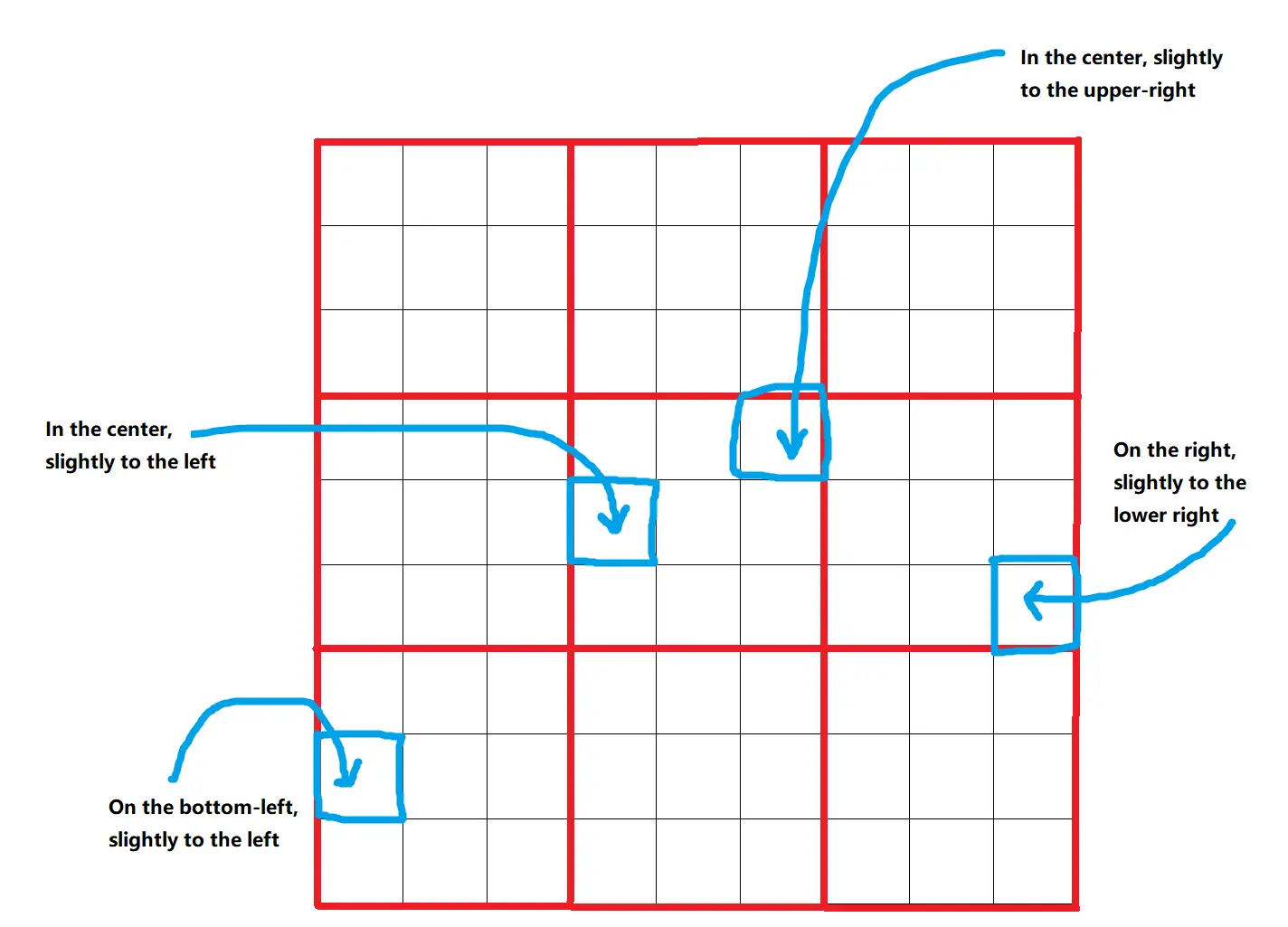
2.2. Profundidade e Cor
Elementos no Canvas recebem um parâmetro distance_to_viewer, que ajuda a classificá-los em camadas do fundo para o primeiro plano. Este parâmetro atua como um indicador de profundidade relativa, garantindo que elementos mais próximos apareçam na frente dos que estão mais distantes. Além disso, o parâmetro HTML_web_color_name fornece uma representação de cor grosseira para a renderização inicial, que pode ser refinada usando modelos de difusão. Esta cor inicial ajuda a visualizar a composição antes do ajuste fino.

2.3. Engenharia de Prompts
Omost usa sub-prompts, que são breves descrições autossuficientes de elementos, para gerar composições de imagens detalhadas e coerentes. Cada sub-prompt tem menos de 75 tokens e descreve um elemento de forma independente. Esses sub-prompts são mesclados em prompts completos para o LLM processar, garantindo que as imagens geradas sejam precisas e semanticamente ricas. Este método garante que a codificação de texto seja eficiente e evita erros de truncamento semântico.
2.4. Prompter Regional
Omost implementa técnicas avançadas de manipulação de atenção para lidar com prompts regionais, garantindo que cada parte da imagem seja gerada com precisão com base nas descrições fornecidas. Técnicas como a manipulação de pontuação de atenção garantem que as ativações dentro das áreas mascaradas sejam incentivadas, enquanto as de fora sejam desencorajadas. Este controle preciso sobre a atenção resulta em uma geração de imagens de alta qualidade e específica para a região.
3. Explicação Detalhada dos Nós do ComfyUI Omost
3.1. Nó Carregador de LLM do Omost
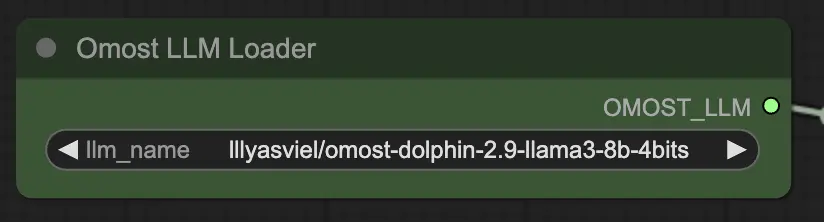
Parâmetros de entrada do Nó Carregador de LLM do Omost
llm_name: O nome do modelo LLM pré-treinado para carregar. Opções disponíveis incluem:lllyasviel/omost-phi-3-mini-128k-8bitslllyasviel/omost-llama-3-8b-4bitslllyasviel/omost-dolphin-2.9-llama3-8b-4bits
Este parâmetro especifica qual modelo carregar, cada um oferecendo diferentes capacidades e otimizações.
Parâmetros de saída do Nó Carregador de LLM do Omost
OMOST_LLM: O modelo LLM carregado.
Esta saída fornece o LLM carregado, pronto para gerar descrições e composições de imagens.
3.2. Nó de Chat de LLM do Omost
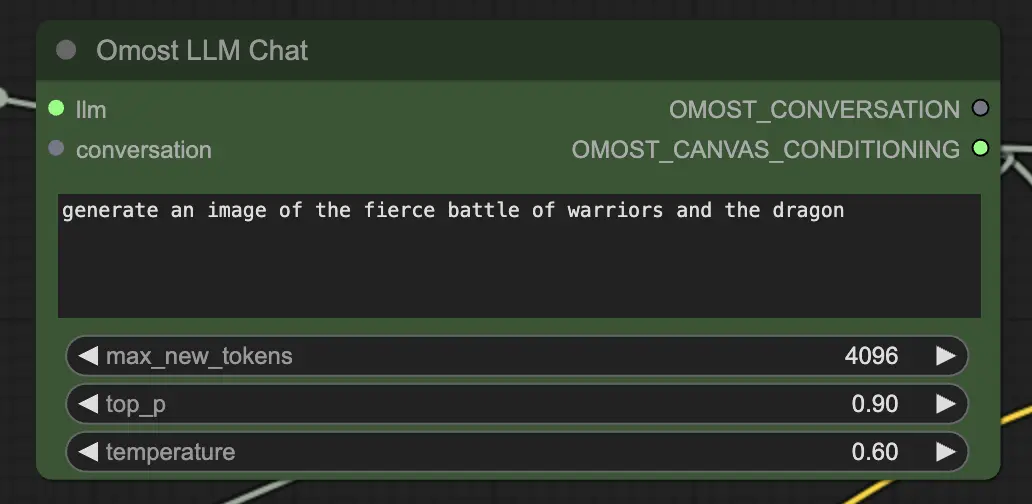
Parâmetros de entrada do Nó de Chat de LLM do Omost
llm: O modelo LLM carregado peloOmostLLMLoader.text: O prompt de texto para gerar uma imagem. Esta é a entrada principal onde você descreve a cena ou elementos que deseja gerar.max_new_tokens: Número máximo de novos tokens a serem gerados. Isso controla o comprimento do texto gerado, com um número maior permitindo descrições mais detalhadas.top_p: Controla a diversidade da saída gerada. Um valor mais próximo de 1.0 inclui mais possibilidades diversas, enquanto um valor mais baixo foca nos resultados mais prováveis.temperature: Controla a aleatoriedade da saída gerada. Valores mais altos resultam em saídas mais aleatórias, enquanto valores mais baixos tornam a saída mais determinística.conversation(Opcional): Contexto de conversa anterior. Isso permite que o modelo continue a partir de interações anteriores, mantendo o contexto e a coerência.
Parâmetros de saída do Nó de Chat de LLM do Omost
OMOST_CONVERSATION: O histórico da conversa, incluindo a nova resposta. Isso ajuda a rastrear o diálogo e manter o contexto em várias interações.OMOST_CANVAS_CONDITIONING: Os parâmetros de condicionamento do Canvas gerado para renderização. Esses parâmetros definem como os elementos são colocados e descritos no Canvas.
3.3. Nó de Renderização de Condicionamento de Canvas do Omost
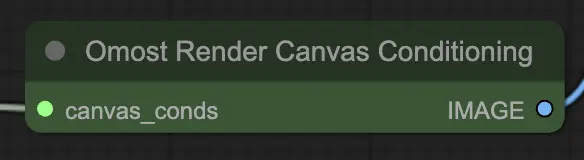
Parâmetros de entrada do Nó de Renderização de Condicionamento de Canvas do Omost
canvas_conds: Os parâmetros de condicionamento do Canvas. Esses parâmetros incluem descrições detalhadas e posições dos elementos no Canvas.
Parâmetros de saída do Nó de Renderização de Condicionamento de Canvas do Omost
IMAGE: A imagem renderizada com base no condicionamento do Canvas. Esta saída é a representação visual da cena descrita, gerada a partir dos parâmetros de condicionamento.
3.4. Nó de Condicionamento de Layout do Omost
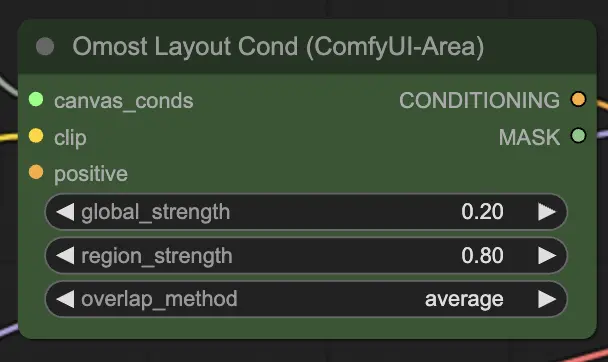
Parâmetros de entrada do Nó de Condicionamento de Layout do Omost
canvas_conds: Os parâmetros de condicionamento do Canvas.clip: O modelo CLIP para codificação de texto. Este modelo codifica as descrições de texto em vetores que podem ser usados pelo gerador de imagens.global_strength: A força do condicionamento global. Isso controla o quanto a descrição geral afeta a imagem.region_strength: A força do condicionamento regional. Isso controla o quanto as descrições regionais específicas afetam suas respectivas áreas.overlap_method: O método para lidar com áreas sobrepostas (por exemplo,overlay,average). Isso define como mesclar regiões sobrepostas na imagem.positive(Opcional): Condicionamento positivo adicional. Isso pode incluir prompts ou condições extras para aprimorar aspectos específicos da imagem.
Parâmetros de saída do Nó de Condicionamento de Layout do Omost
CONDITIONING: Os parâmetros de condicionamento para a geração de imagens. Esses parâmetros guiam o processo de geração de imagens, garantindo que a saída corresponda à cena descrita.MASK: A máscara usada para o condicionamento. Isso ajuda na depuração e na aplicação de condições adicionais a regiões específicas.
3.5. Nó de Carregamento de Condicionamento de Canvas do Omost
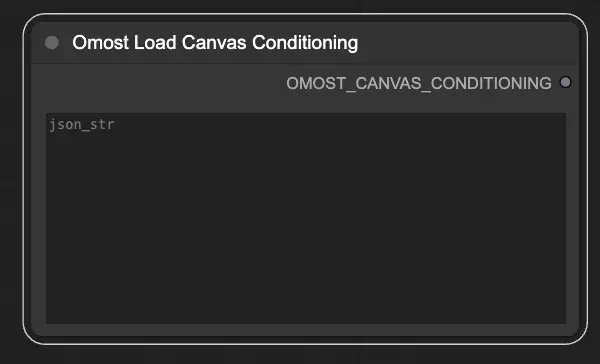
Parâmetros de entrada do Nó de Carregamento de Condicionamento de Canvas do Omost
json_str: A string JSON representando os parâmetros de condicionamento do Canvas. Isso permite carregar condições predefinidas de um arquivo JSON.
Parâmetros de saída do Nó de Carregamento de Condicionamento de Canvas do Omost
OMOST_CANVAS_CONDITIONING: Os parâmetros de condicionamento do Canvas carregados. Esses parâmetros inicializam o Canvas com condições específicas, pronto para a geração de imagens.

