EchoMimic | Animações de Retratos Guiadas por Áudio
EchoMimic é uma ferramenta que permite criar cabeças falantes realistas e gestos corporais que se sincronizam perfeitamente com o áudio fornecido. Ao aproveitar técnicas avançadas de IA, o EchoMimic analisa o áudio de entrada e gera expressões faciais, movimentos labiais e linguagem corporal realistas que combinam perfeitamente com as palavras faladas e emoções. Com o EchoMimic, você pode dar vida aos seus personagens e criar conteúdo animado que cativa seu público.ComfyUI EchoMimic Fluxo de Trabalho
- Fluxos de trabalho totalmente operacionais
- Sem nós ou modelos ausentes
- Nenhuma configuração manual necessária
- Apresenta visuais impressionantes
ComfyUI EchoMimic Exemplos
ComfyUI EchoMimic Descrição
EchoMimic é uma ferramenta para gerar animações de retratos guiadas por áudio incrivelmente realistas. Utiliza técnicas de aprendizado profundo para analisar o áudio de entrada e gerar expressões faciais, movimentos labiais e gestos da cabeça correspondentes que combinam de perto com o conteúdo emocional e fonético do discurso.
EchoMimic V2 foi desenvolvido por uma equipe de pesquisadores do Departamento de Tecnologia Terminal da Alipay, Ant Group, incluindo Rang Meng, Xingyu Zhang, Yuming Li e Chenguang Ma. Para informações detalhadas, por favor visite /. O nó ComfyUI_EchoMimic foi desenvolvido por /. Todo o crédito vai para a significativa contribuição deles.
EchoMimic V1 e V2
- EchoMimic V1: Animações de Retratos Guiadas por Áudio Realistas com Controle de Marco Personalizável
- EchoMimic V2: Animações Humanas Semi-Corpo Expressivas e Simplificadas
A principal diferença é que o EchoMimic V2 visa alcançar uma animação humana meio corpo impressionante enquanto simplifica condições de controle desnecessárias em comparação com o EchoMimic V1. EchoMimic V2 utiliza uma estratégia inovadora de Harmonização Dinâmica Áudio-Postura para aprimorar expressões faciais e gestos corporais.
Pontos Fortes e Fracos do EchoMimic V2
Pontos Fortes:
- EchoMimic V2 gera animações de retratos altamente realistas e expressivas guiadas por áudio
- EchoMimic V2 estende a animação para a parte superior do corpo, não apenas para a região da cabeça
- EchoMimic V2 reduz a complexidade das condições enquanto mantém a qualidade da animação em comparação com o EchoMimic V1
- EchoMimic V2 incorpora perfeitamente dados de headshot para aprimorar expressões faciais
Pontos Fracos:
- EchoMimic V2 requer uma fonte de áudio correspondente ao retrato para melhores resultados
- EchoMimic V2 atualmente carece de código de sincronização de postura, usando um arquivo de postura padrão
- Gerar animações de longa duração e alta qualidade com EchoMimic V2 pode ser computacionalmente intensivo
- EchoMimic V2 funciona melhor em imagens de retratos cortadas em vez de fotos de corpo inteiro
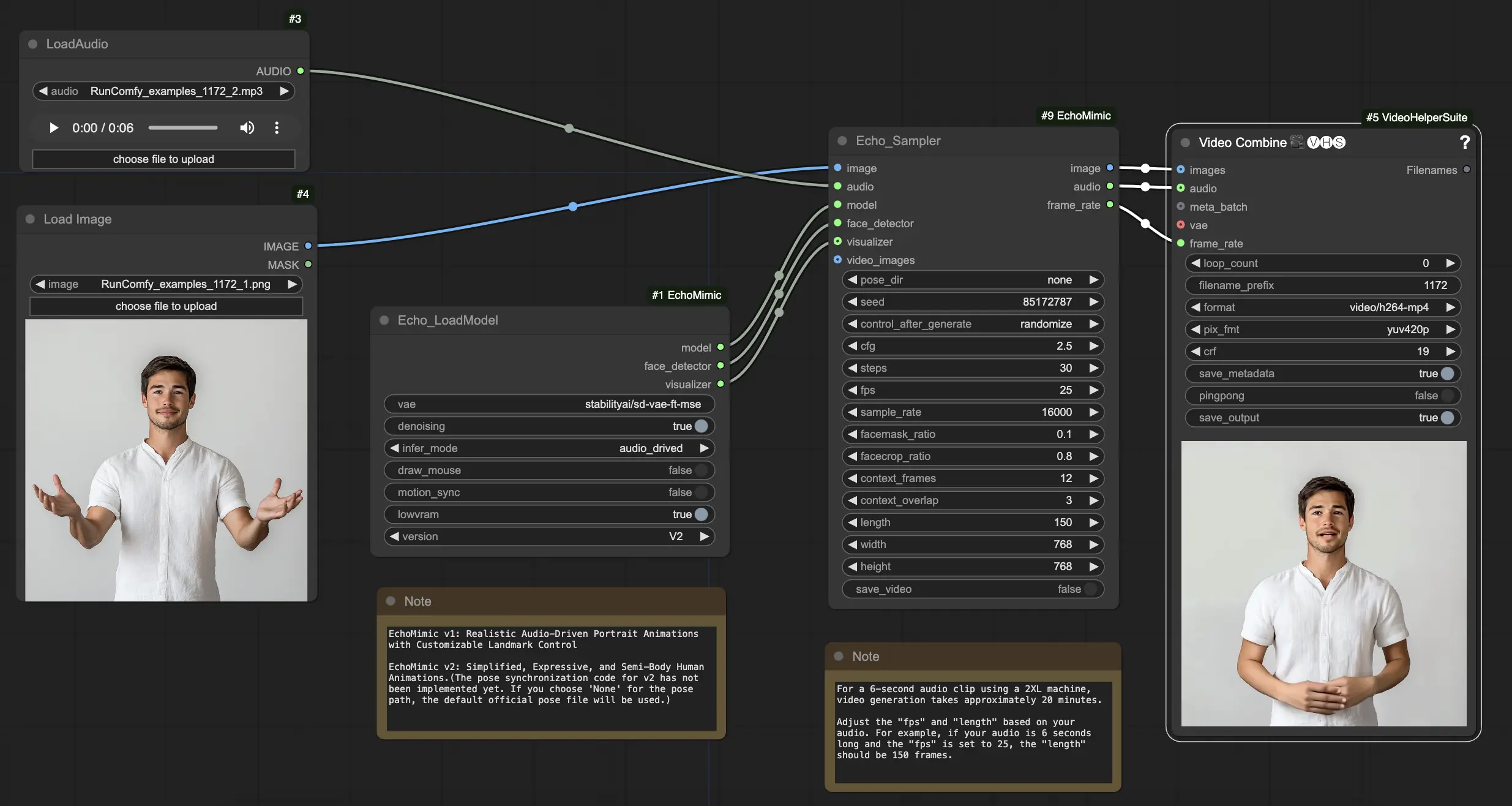
Como Usar o Workflow ComfyUI EchoMimic
No nó "Echo_LoadModel", você tem a opção de selecionar entre EchoMimic v1 e EchoMimic v2:
- EchoMimic v1: Esta versão foca em gerar animações de retratos guiadas por áudio realistas com a capacidade de personalizar o controle de marcos. É bem adequado para criar animações faciais realistas que combinam de perto com o áudio de entrada.
- EchoMimic v2: Esta versão visa simplificar o processo de animação enquanto entrega animações humanas expressivas e semi-corpo. Estende a animação além apenas da região facial para incluir movimentos da parte superior do corpo. No entanto, por favor, note que o recurso de sincronização de postura para v2 ainda não está implementado na versão atual do workflow ComfyUI. Se você selecionar 'None' para o caminho da postura, o arquivo de postura oficial padrão será usado.
Aqui está um guia passo a passo sobre como usar o workflow ComfyUI fornecido:
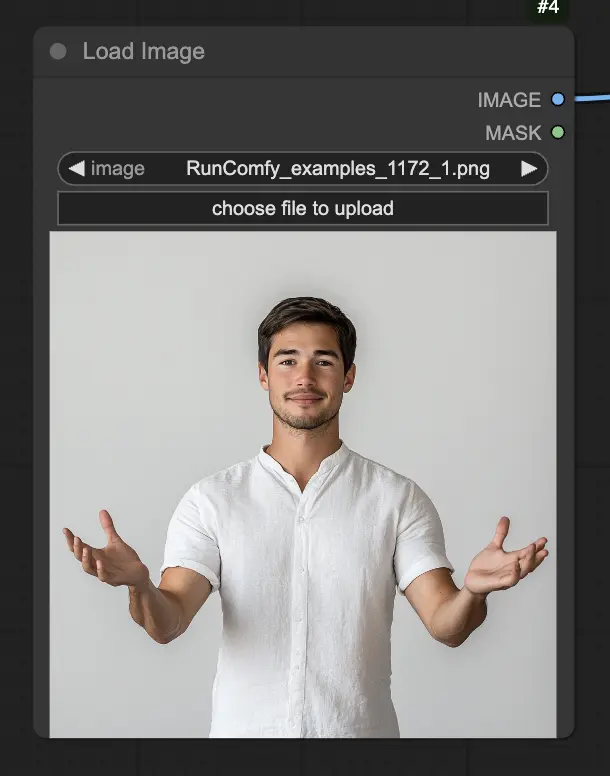
Passo 1. Carregue sua imagem de retrato usando o nó LoadImage. Esta deve ser uma foto em close do rosto e ombros do sujeito.
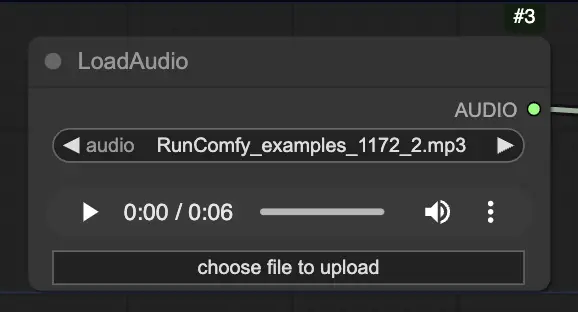
Passo 2. Carregue seu arquivo de áudio usando o nó LoadAudio. O discurso no áudio deve corresponder à identidade do sujeito do retrato.
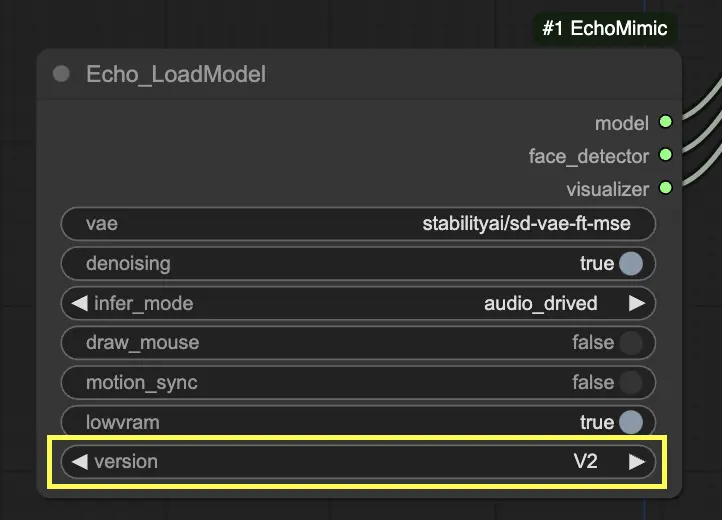
Passo 3. Use o nó Echo_LoadModel para carregar o modelo EchoMimic. Configurações principais:
- Escolha a versão (V1 ou V2).
- Selecione o modo de inferência, por exemplo, modo guiado por áudio.
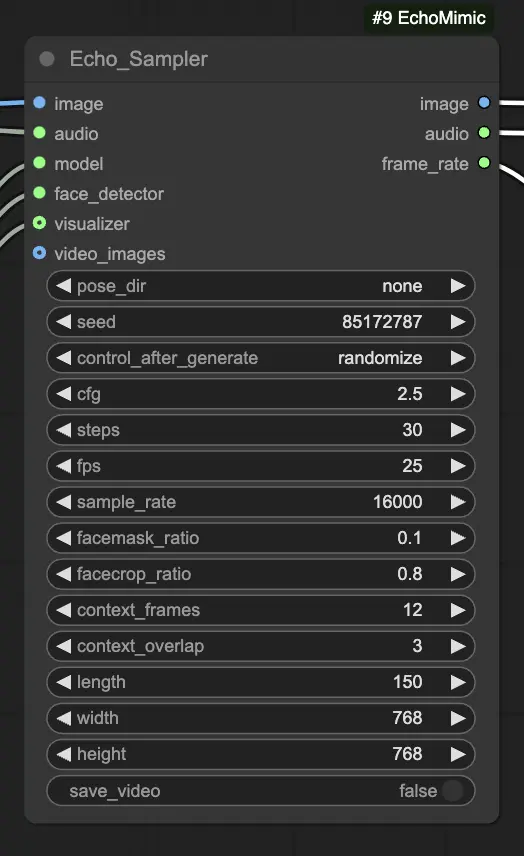
Passo 4. Conecte a imagem, o áudio e o modelo carregado ao nó Echo_Sampler. Configurações principais:
- pose_dir: O caminho do diretório para os arquivos de sequência de postura usados em modos de animação guiados por postura. Se configurado como "none", nenhuma sequência de postura será usada.
- seed: A semente aleatória para gerar resultados consistentes em execuções. Deve ser um número inteiro entre 0 e MAX_SEED.
- cfg: A escala de orientação livre de classificação, controlando a força do condicionamento de áudio. Valores mais altos resultam em movimentos guiados por áudio mais pronunciados. O valor padrão é 2.5, e pode variar de 0.0 a 10.0.
- steps: O número de passos de difusão para gerar cada quadro. Valores mais altos produzem animações mais suaves, mas demoram mais para gerar. O padrão é 30, e pode variar de 1 a 100.
- fps: A taxa de quadros do vídeo de saída em quadros por segundo. O padrão é 25, e pode variar de 5 a 100.
- sample_rate: A taxa de amostragem do áudio de entrada em Hz. O padrão é 16000, e pode variar de 8000 a 48000 em incrementos de 1000.
- facemask_ratio: A proporção da área da máscara facial em relação à área total da imagem. Controla o tamanho da região ao redor do rosto que é animada. O padrão é 0.1, e pode variar de 0.0 a 1.0.
- facecrop_ratio: A proporção da área de corte do rosto em relação à área total da imagem. Determina quanto da imagem é dedicada à região do rosto. O padrão é 0.8, e pode variar de 0.0 a 1.0.
- context_frames: O número de quadros passados e futuros a serem usados como contexto para gerar cada quadro. O padrão é 12, e pode variar de 0 a 50.
- context_overlap: O número de quadros sobrepostos entre janelas de contexto adjacentes. O padrão é 3, e pode variar de 0 a 10.
- length: O comprimento do vídeo de saída em quadros. Deve ser baseado na duração do seu áudio de entrada e na configuração de fps. Por exemplo, se seu áudio tiver 6 segundos de duração e o fps estiver configurado para 25, o comprimento deve ser de 150 quadros. O comprimento pode variar de 50 a 5000 quadros.
- width: A largura dos quadros do vídeo de saída em pixels. O padrão é 512, e pode variar de 128 a 1024 em incrementos de 64.
- height: A altura dos quadros do vídeo de saída em pixels. O padrão é 512, e pode variar de 128 a 1024 em incrementos de 64.
Por favor, note que a geração de vídeo pode levar algum tempo. Por exemplo, criar um vídeo a partir de um clipe de áudio de 6 segundos usando uma máquina 2XL no RunComfy leva cerca de 20 minutos.


