SDXL Turbo | Быстрое преобразование текста в изображение
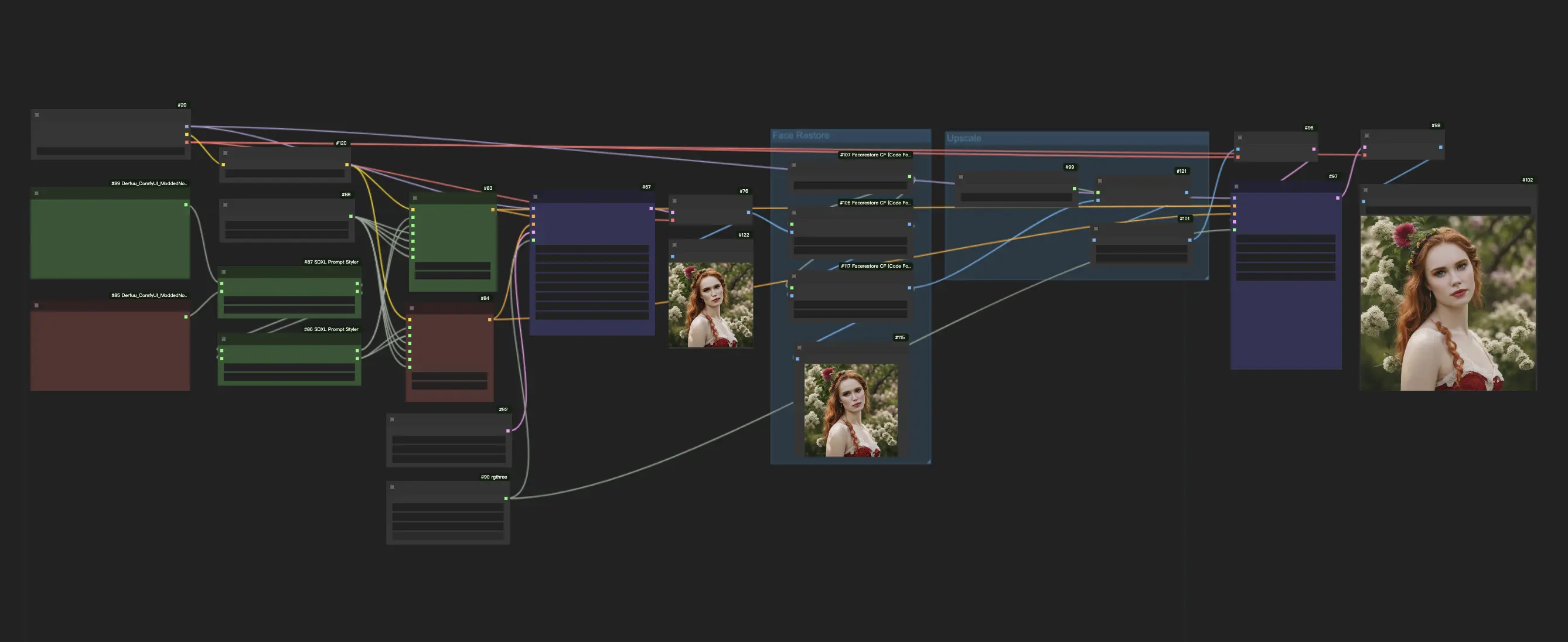
Этот рабочий процесс ComfyUI использует модель SDXL Turbo для быстрого генерации изображений из текста, требуя всего 1-4 шага. Для повышения стабильности и получения лучших результатов он также интегрирует модель восстановления лица и модель повышения разрешения.ComfyUI SDXL Turbo Рабочий процесс
- Полностью функциональные рабочие процессы
- Нет недостающих узлов или моделей
- Не требуется ручная настройка
- Отличается потрясающей визуализацией
ComfyUI SDXL Turbo Примеры

ComfyUI SDXL Turbo Описание
1. Рабочий процесс ComfyUI SDXL Turbo
SDXL Turbo синтезирует выходные изображения за один шаг и генерирует выходные данные "текст в изображение" в реальном времени. Качество SDXL Turbo относительно хорошее, хотя оно может не всегда быть стабильным. Для улучшения результатов рекомендуется включить модель восстановления лица и модель повышения разрешения для тех, кто стремится к более высокому качеству.
2. Обзор SDXL Turbo
SDXL Turbo - это генеративная модель "текст в изображение", которая эффективно преобразует текстовые подсказки в фотореалистичные изображения всего за одну оценку сети. Используя технику под названием Adversarial Diffusion Distillation (ADD), разработанную Stability AI, она значительно сокращает процесс синтеза изображений до 1-4 шагов, что значительно меньше по сравнению с традиционными 50 шагами, требуемыми ранее. Эта модель, являющаяся усовершенствованием SDXL 1.0, использует ADD для объединения дистилляции оценок с противоборствующей потерей, оптимизируя использование существующих моделей диффузии изображений для получения более высокого качества с меньшим числом шагов выборки. Введение этой техники дистилляции не только сохраняет качество изображений, но и значительно сокращает вычислительные усилия, необходимые для генерации изображений.
3. Ограничения SDXL Turbo
Несмотря на свои передовые возможности, SDXL Turbo имеет определенные ограничения. Он генерирует изображения с фиксированным разрешением 512x512 пикселей и может испытывать трудности с отображением читаемого текста, точным изображением лиц и людей, а также с достижением идеального фотореализма. Эти ограничения подчеркивают, что модель предназначена для исследований и изучения, а не для фактического или точного представления реальных объектов.





