AnimateDiff + ControlNet | Стиль керамического искусства
Этот рабочий процесс в ComfyUI использует AnimateDiff и ControlNet с акцентом на глубину, а также другие, такие как Lora, чтобы искусно преобразовать видео в стиль керамического искусства. Это позволяет оригинальному содержанию приобрести уникальный художественный стиль, эффективно поднимая его до уровня шедевров керамического искусства.ComfyUI Vid2Vid (Art) Рабочий процесс
- Полностью функциональные рабочие процессы
- Нет недостающих узлов или моделей
- Не требуется ручная настройка
- Отличается потрясающей визуализацией
ComfyUI Vid2Vid (Art) Примеры
ComfyUI Vid2Vid (Art) Описание
1. Рабочий процесс ComfyUI: AnimateDiff + ControlNet | Стиль керамического искусства
Этот рабочий процесс использует AnimateDiff, ControlNet с акцентом на глубину и конкретные Lora, чтобы искусно преобразовать видео в стиль керамического искусства. Вам рекомендуется использовать различные подсказки, чтобы достичь различных художественных стилей, воплощая ваши идеи в реальность.
2. Как использовать AnimateDiff
AnimateDiff предназначен для анимации статических изображений и текстовых подсказок в динамические видео, используя модели Stable Diffusion и специализированный модуль движения. Он автоматизирует процесс анимации, предсказывая плавные переходы между кадрами, делая его доступным для пользователей без навыков программирования.
2.1 Модули движения AnimateDiff
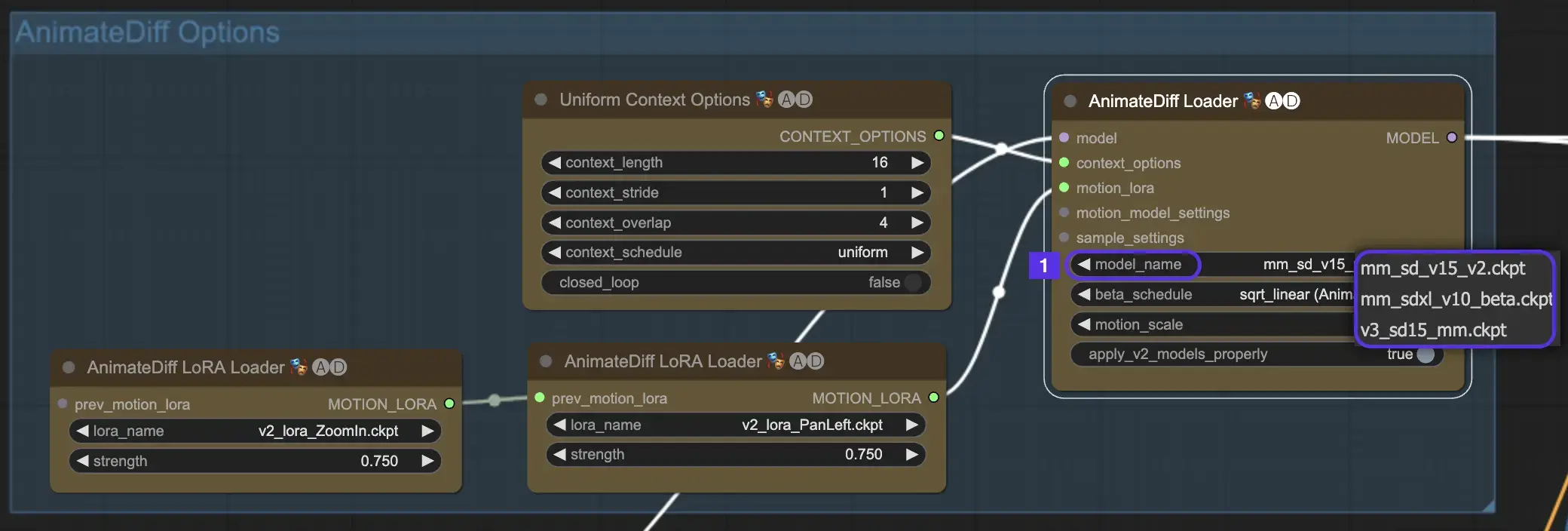
Для начала выберите желаемый модуль движения AnimateDiff из выпадающего списка model_name:
- Используйте v3_sd15_mm.ckpt для AnimateDiff V3
- Используйте mm_sd_v15_v2.ckpt для AnimateDiff V2
- Используйте mm_sdxl_v10_beta.ckpt для AnimateDiff SDXL
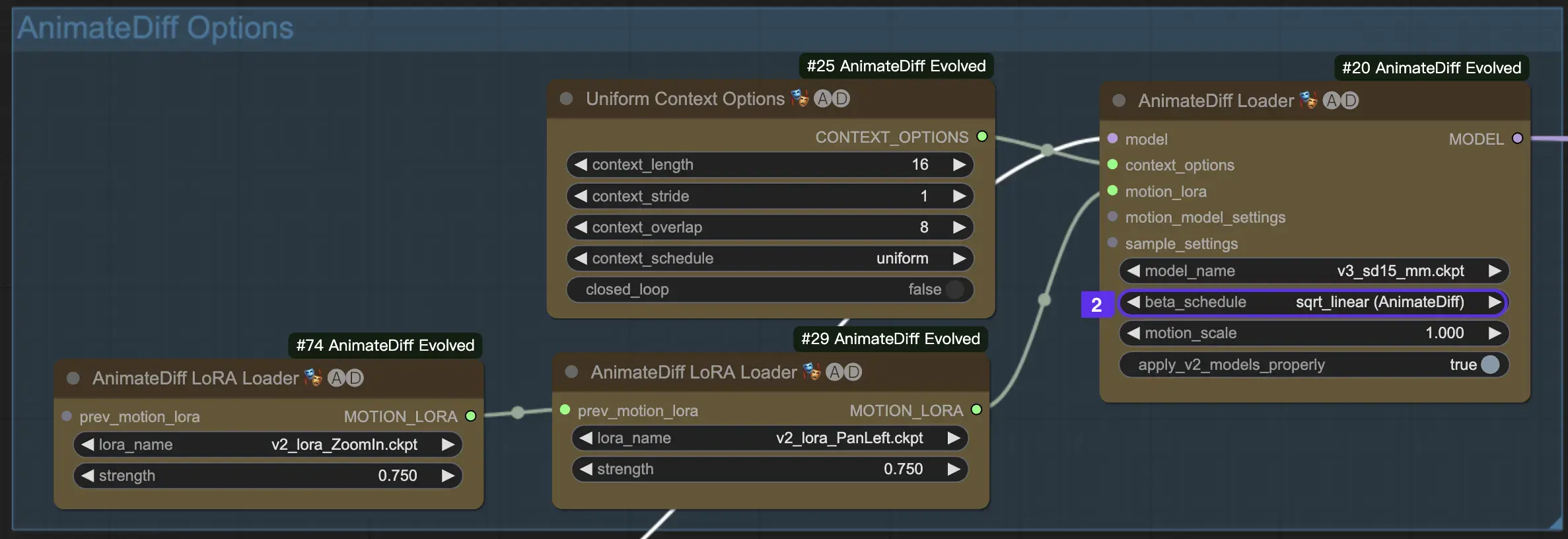
2.2 Beta Schedule
Beta Schedule в AnimateDiff имеет решающее значение для настройки процесса уменьшения шума во время создания анимации.
Для версий V3 и V2 AnimateDiff рекомендуется настройка sqrt_linear, хотя эксперименты с настройкой linear могут дать уникальные эффекты.
Для AnimateDiff SDXL рекомендуется настройка linear (AnimateDiff-SDXL).
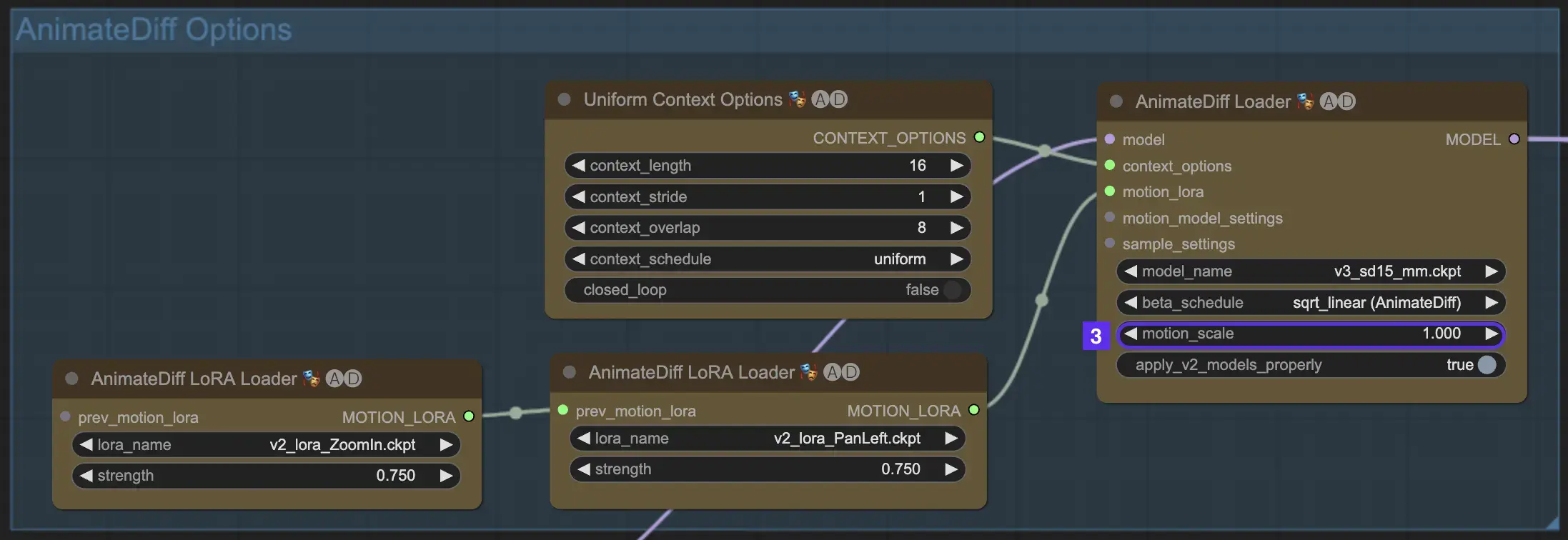
2.3 Масштаб движения
Функция Масштаб движения в AnimateDiff позволяет регулировать интенсивность движения в ваших анимациях. Масштаб движения меньше 1 приводит к более тонким движениям, тогда как масштаб больше 1 усиливает движение.
2.4 Длина контекста
Единая длина контекста в AnimateDiff важна для обеспечения плавных переходов между сценами, определяемыми вашим Batch Size. Она действует как экспертный редактор, плавно соединяя сцены для непрерывного повествования. Установка более длинной единой длины контекста обеспечивает более плавные переходы, в то время как более короткая длина предлагает более быстрые, более отчетливые изменения сцен, полезные для определенных эффектов. Стандартная единая длина контекста установлена на 16.
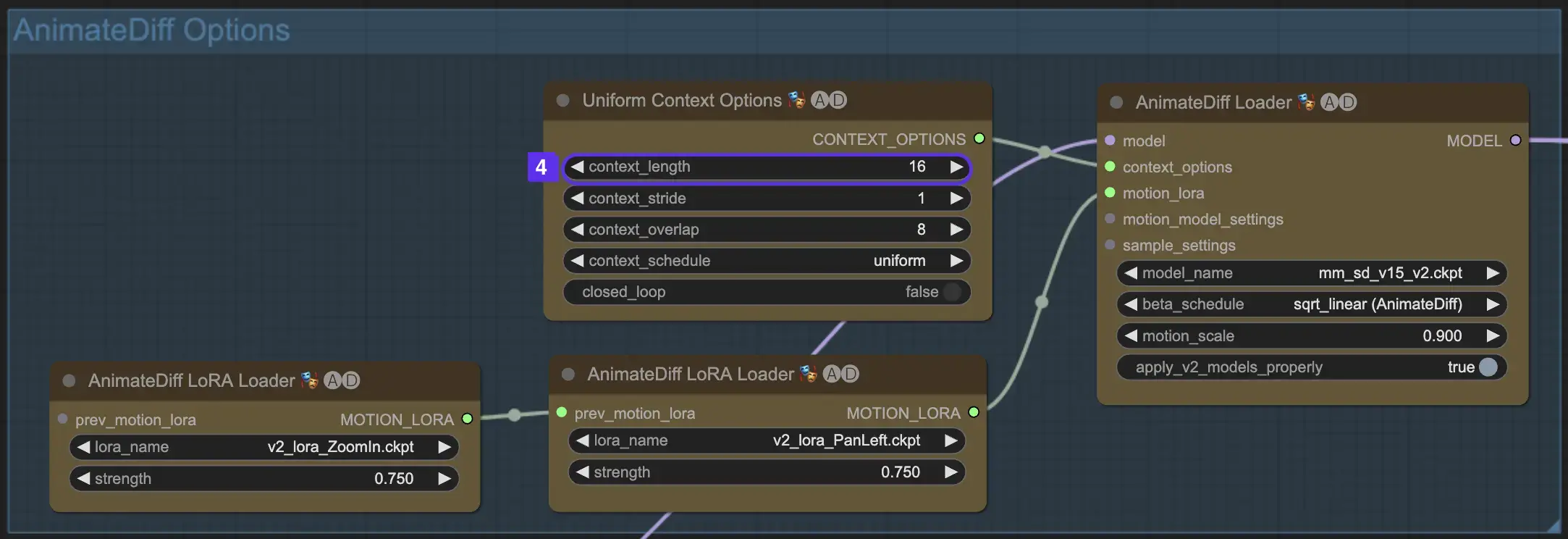
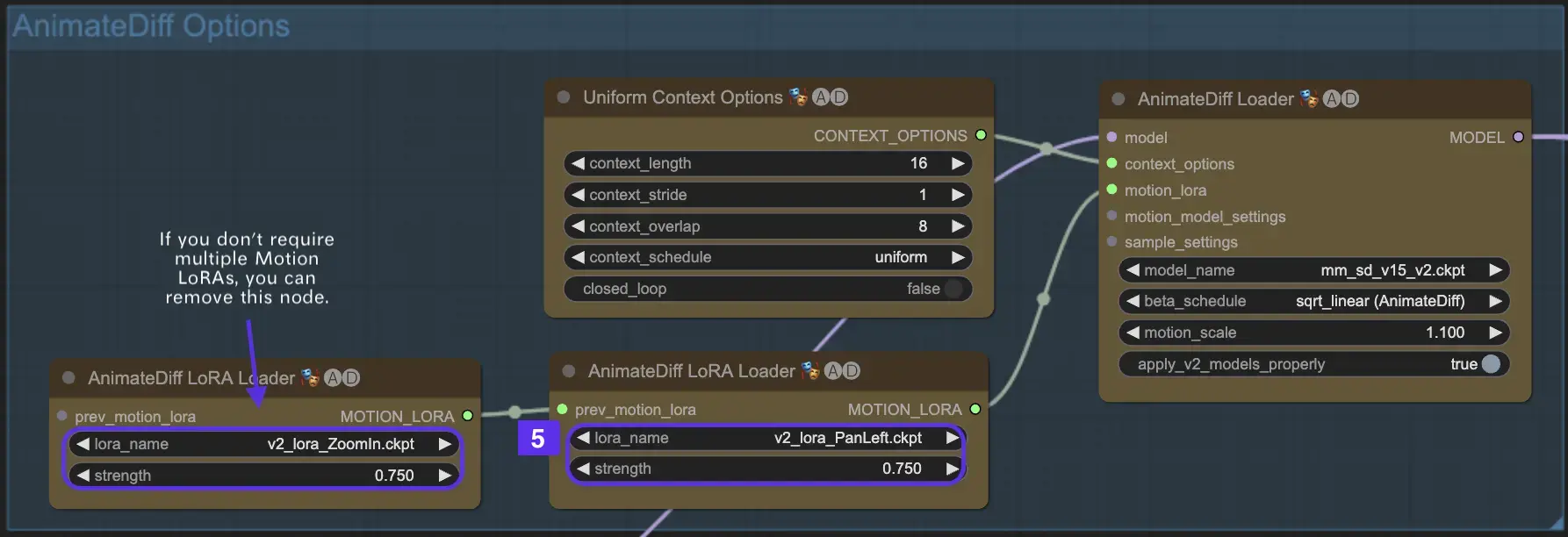
2.5 Использование Motion LoRA для улучшенной динамики камеры (специфично для AnimateDiff v2)
Motion LoRAs, совместимые только с AnimateDiff v2, вводят дополнительный уровень динамического движения камеры. Достижение оптимального баланса с весом LoRA, обычно около 0.75, обеспечивает плавное движение камеры без искажений фона.
Кроме того, связывание различных моделей Motion LoRA позволяет создавать сложные динамики камеры. Это позволяет создателям экспериментировать и находить идеальное сочетание для своей анимации, поднимая ее до кинематографического уровня.
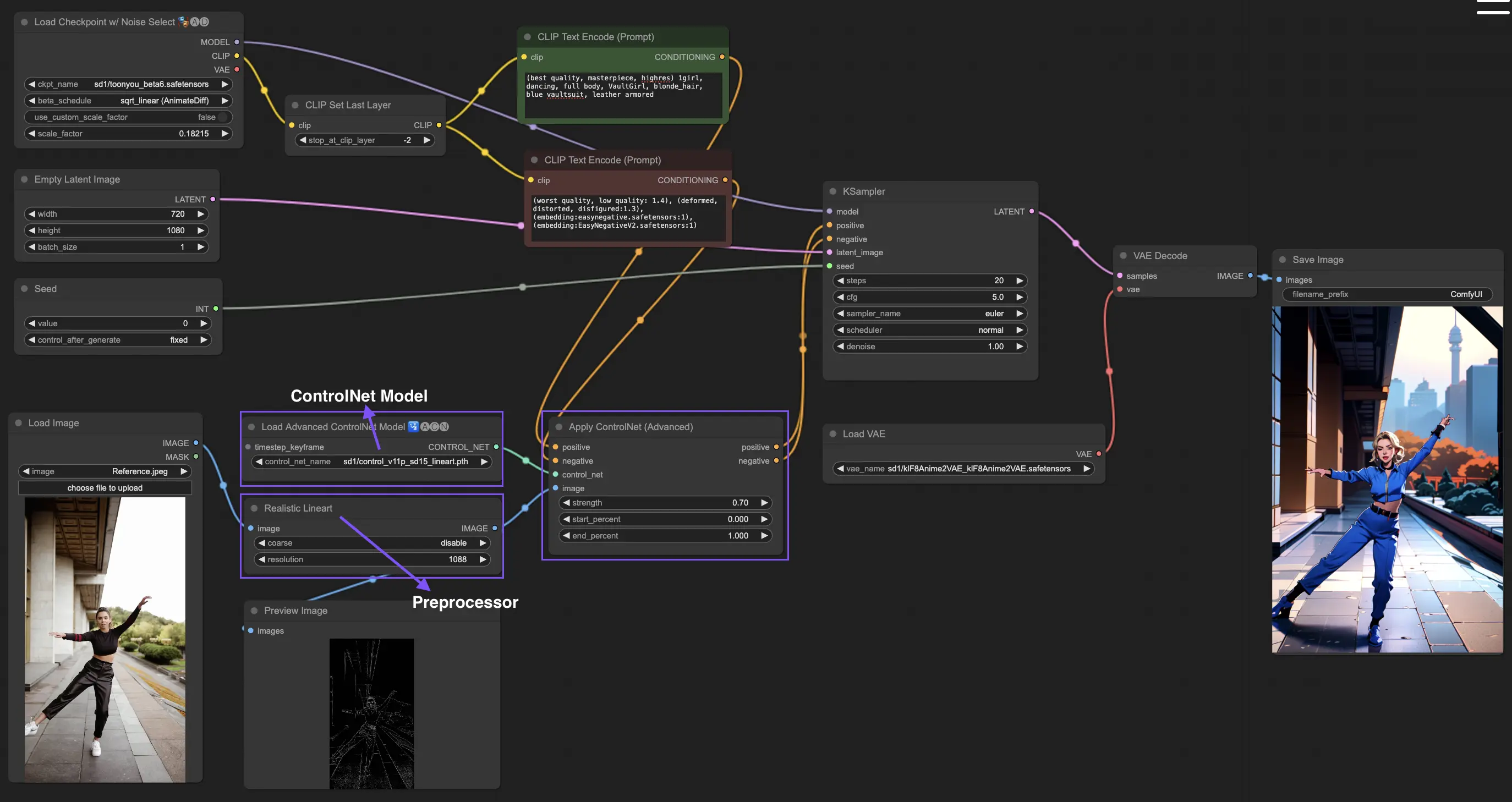
3. Как использовать ControlNet
ControlNet улучшает генерацию изображений, вводя точный пространственный контроль в модели text-to-image, позволяя пользователям манипулировать изображениями сложными способами, выходящими за рамки простых текстовых подсказок, используя обширные библиотеки моделей, таких как Stable Diffusion, для сложных задач, таких как рисование, картирование и сегментация визуалов.
Ниже приведен самый простой рабочий процесс с использованием ControlNet.
3.1 Загрузка узла "Apply ControlNet"
Начните создание изображения, загрузив узел "Apply ControlNet" в ComfyUI, создавая основу для комбинирования визуальных и текстовых элементов в вашем дизайне.
3.2 Входы узла "Apply ControlNet"
Используйте Positive и Negative Conditioning для формирования вашего изображения, выберите модель ControlNet для определения стильных черт и выполните предварительную обработку вашего изображения, чтобы оно соответствовало требованиям модели ControlNet, делая его готовым к преобразованию.
3.3 Выходы узла "Apply ControlNet"
Выходы узла направляют модель диффузии, предлагая выбор между дальнейшим уточнением изображения или добавлением большего количества ControlNet для улучшенной детализации и настройки на основе взаимодействия ControlNet с вашими творческими входами.
3.4 Настройка "Apply ControlNet" для лучших результатов
Контролируйте влияние ControlNet на ваше изображение с помощью настроек, таких как Determining Strength, Adjusting Start Percent и Setting End Percent, чтобы точно настроить процесс создания и конечный результат изображения.
Для получения более подробной информации, пожалуйста, ознакомьтесь с
Этот рабочий процесс вдохновлен с некоторыми модификациями. Для получения дополнительной информации, пожалуйста, посетите его канал на YouTube.

