EchoMimic | 音频驱动的人像动画
EchoMimic 是一个工具,可以让您创建与提供的音频无缝同步的逼真说话头像和身体动作。通过利用先进的 AI 技术,EchoMimic 分析音频输入并生成与所说的词语和情感完美匹配的逼真面部表情、唇部动作和身体语言。使用 EchoMimic,您可以赋予您的角色生命,并创建吸引观众的动画内容。ComfyUI EchoMimic 工作流程
想要运行这个工作流吗?
- 完全可操作的工作流
- 没有缺失的节点或模型
- 无需手动设置
- 具有惊艳的视觉效果
ComfyUI EchoMimic 示例
ComfyUI EchoMimic 描述
EchoMimic 是一个用于生成栩栩如生的音频驱动的人像动画的工具。它利用深度学习技术分析输入音频,并生成与语音的情感和语音内容紧密匹配的相应面部表情、唇部动作和头部手势。
EchoMimic V2 由来自支付宝蚂蚁集团终端技术部门的研究团队开发,包括 Rang Meng、Xingyu Zhang、Yuming Li 和 Chenguang Ma。有关详细信息,请访问 /。ComfyUI_EchoMimic 节点由 / 开发。所有荣誉归功于他们的重大贡献。
EchoMimic V1 和 V2
- EchoMimic V1: 具有可定制标志控制的逼真音频驱动的人像动画
- EchoMimic V2: 简化、富有表现力和半身人类动画
关键区别在于 EchoMimic V2 旨在实现令人惊叹的半身人类动画,同时简化了相较于 EchoMimic V1 不必要的控制条件。EchoMimic V2 使用了一种新颖的音频姿态动态协调策略来增强面部表情和身体动作。
EchoMimic V2 的优点和缺点
优点:
- EchoMimic V2 生成由音频驱动的高度逼真和富有表现力的人像动画
- EchoMimic V2 将动画扩展至上半身,而不仅仅是头部区域
- EchoMimic V2 在保持动画质量的同时减少了条件复杂性,相较于 EchoMimic V1
- EchoMimic V2 无缝结合头部数据以增强面部表情
缺点:
- EchoMimic V2 需要与人像匹配的音频源以获得最佳效果
- EchoMimic V2 目前缺乏姿态同步代码,使用默认姿态文件
- 使用 EchoMimic V2 生成更长的高质量动画可能计算密集
- EchoMimic V2 最适合裁剪的人像图像而不是全身照片
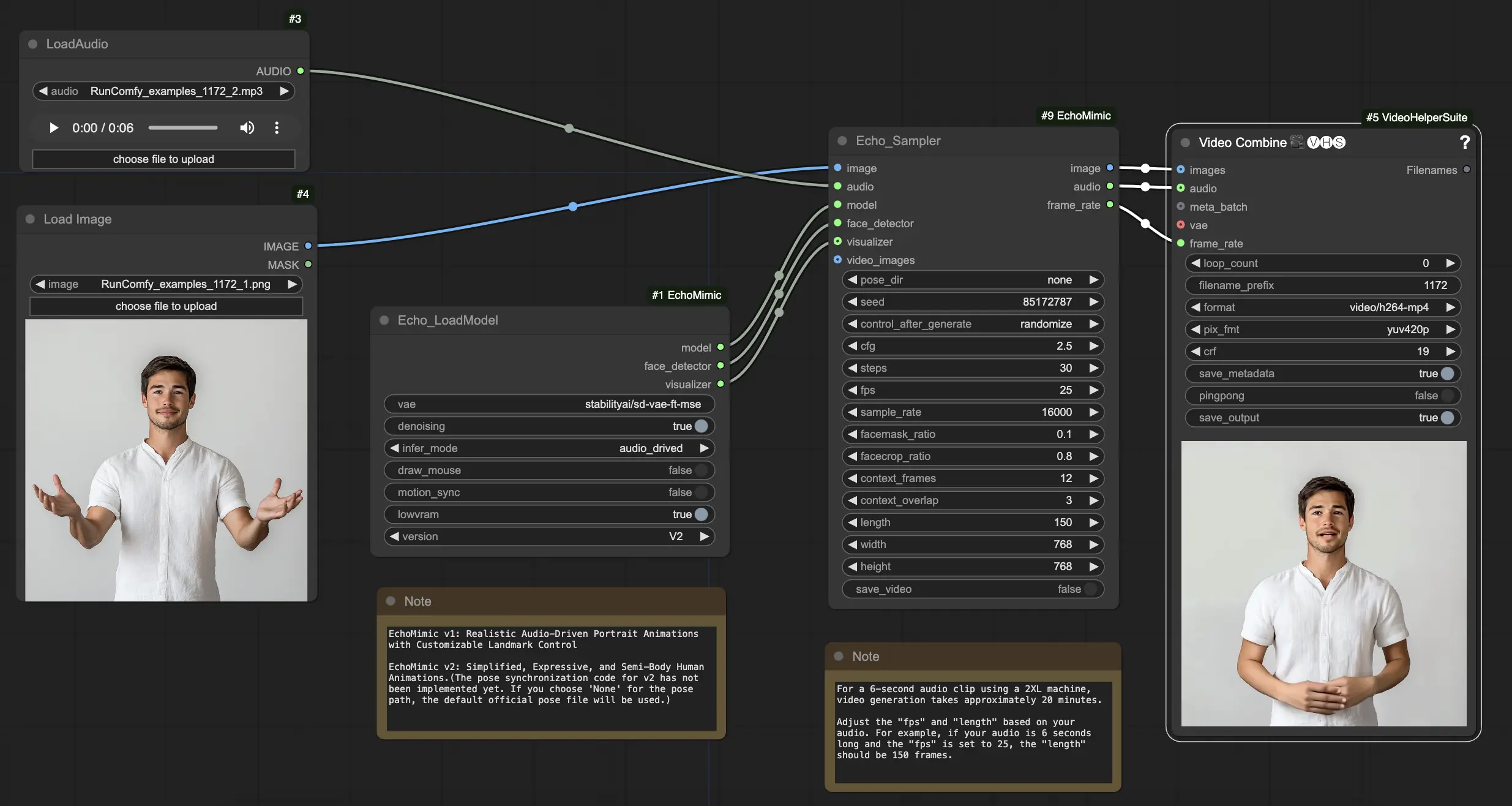
如何使用 ComfyUI EchoMimic 工作流
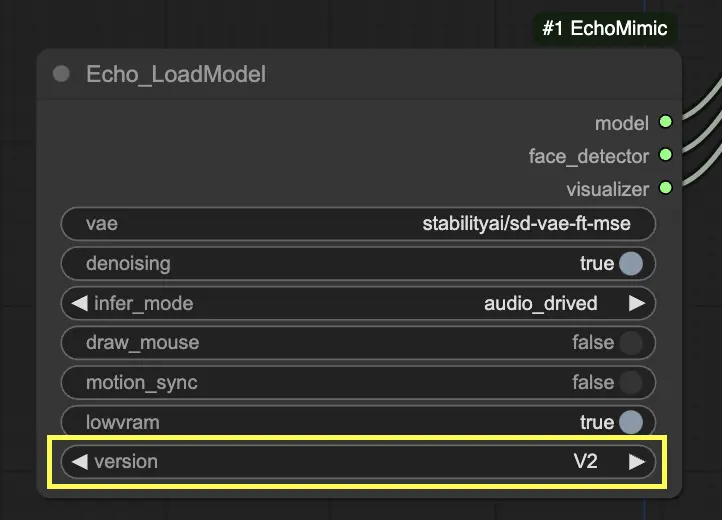
在 "Echo_LoadModel" 节点中,您可以选择 EchoMimic v1 和 EchoMimic v2:
- EchoMimic v1: 这个版本专注于生成具有可定制标志控制的逼真音频驱动的人像动画。它非常适合创建与输入音频紧密匹配的逼真面部动画。
- EchoMimic v2: 这个版本旨在简化动画过程,同时提供富有表现力和半身人类动画。它将动画扩展至面部区域之外,包括上半身动作。然而,请注意 v2 的姿态同步功能尚未在当前版本的 ComfyUI 工作流中实现。如果您选择 'None' 作为姿态路径,将使用默认官方姿态文件。
以下是使用提供的 ComfyUI 工作流的分步指南:
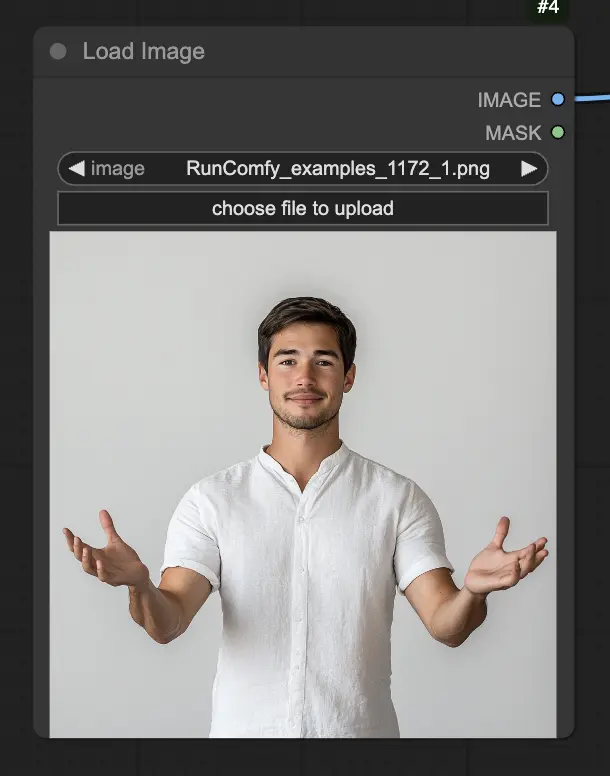
步骤 1. 使用 LoadImage 节点加载人像图像。这应该是主体头部和肩部的特写镜头。
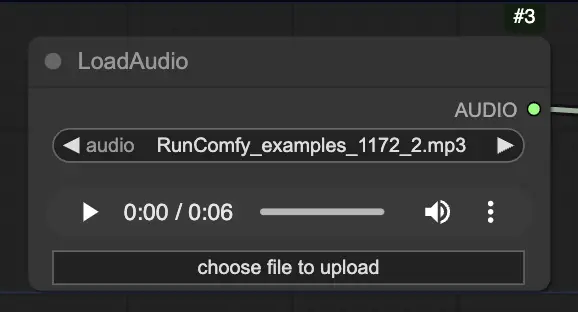
步骤 2. 使用 LoadAudio 节点加载音频文件。音频中的语音应与人像主体的身份匹配。
步骤 3. 使用 Echo_LoadModel 节点加载 EchoMimic 模型。关键设置:
- 选择版本(V1 或 V2)。
- 选择推理模式,例如音频驱动模式。
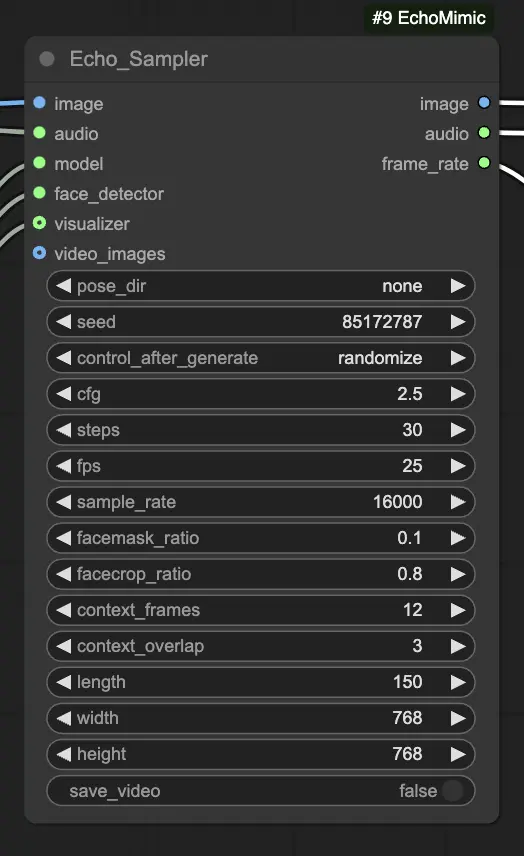
步骤 4. 将图像、音频和加载的模型连接到 Echo_Sampler 节点。关键设置:
- pose_dir: 用于姿态驱动动画模式的姿态序列文件的目录路径。如果设置为 "none",则不使用姿态序列。
- seed: 用于在运行中生成一致结果的随机种子。应为 0 到 MAX_SEED 之间的整数。
- cfg: 无分类器指导比例,控制音频条件的强度。较高的值会导致更明显的音频驱动动作。默认值为 2.5,可以在 0.0 到 10.0 之间。
- steps: 生成每帧的扩散步骤数量。较高的值会产生更流畅的动画,但生成时间更长。默认值为 30,可以在 1 到 100 之间。
- fps: 输出视频的帧率,以每秒帧数为单位。默认值为 25,可以在 5 到 100 之间。
- sample_rate: 输入音频的采样率,单位为 Hz。默认值为 16000,可以在 8000 到 48000 之间,以 1000 为增量。
- facemask_ratio: 面部遮罩区域与完整图像区域的比例。它控制围绕面部的动画区域大小。默认值为 0.1,可以在 0.0 到 1.0 之间。
- facecrop_ratio: 面部裁剪区域与完整图像区域的比例。它决定图像中面部区域的大小。默认值为 0.8,可以在 0.0 到 1.0 之间。
- context_frames: 用作生成每帧的上下文的过去和未来帧的数量。默认值为 12,可以在 0 到 50 之间。
- context_overlap: 相邻上下文窗口之间的重叠帧数。默认值为 3,可以在 0 到 10 之间。
- length: 输出视频的长度,以帧为单位。应根据输入音频的持续时间和 fps 设置。例如,如果您的音频长 6 秒,fps 设置为 25,长度应为 150 帧。长度可以在 50 到 5000 帧之间。
- width: 输出视频帧的宽度,以像素为单位。默认值为 512,可以在 128 到 1024 之间,以 64 为增量。
- height: 输出视频帧的高度,以像素为单位。默认值为 512,可以在 128 到 1024 之间,以 64 为增量。
请注意,视频生成可能需要一些时间。例如,使用 RunComfy 上的 2XL 机器从 6 秒音频片段创建视频大约需要 20 分钟。

