Vid2Vid 第 1 部分 | 组合与遮罩
ComfyUI Vid2Vid 提供了两种不同的工作流程来创建高质量、专业的动画:Vid2Vid 第 1 部分,通过专注于原始视频的组合和遮罩来增强您的创意;Vid2Vid 第 2 部分,利用 SDXL Style Transfer 将视频的风格转变为您想要的美学风格。本页面专门介绍 Vid2Vid 第 1 部分。ComfyUI Vid2Vid 工作流程

- 完全可操作的工作流
- 没有缺失的节点或模型
- 无需手动设置
- 具有惊艳的视觉效果
ComfyUI Vid2Vid 示例
ComfyUI Vid2Vid 描述
ComfyUI Vid2Vid 工作流程,由 创建,介绍了两种不同的工作流程,以实现高质量、专业的动画。
- 第一个 ComfyUI 工作流程:ComfyUI Vid2Vid 第 1 部分 | 组合与遮罩
- 第二个工作流程:
ComfyUI Vid2Vid 第 1 部分 | 组合与遮罩
这个工作流程通过专注于原始视频的组合和遮罩来增强创意。
步骤 1: 模型加载器 | ComfyUI Vid2Vid 工作流程第 1 部分
选择适合您的动画的模型。这包括选择 checkpoint 模型、VAE (Variational Autoencoder) 模型和 LoRA (Low-Rank Adaptation) 模型。这些模型对于定义动画的能力和风格至关重要。
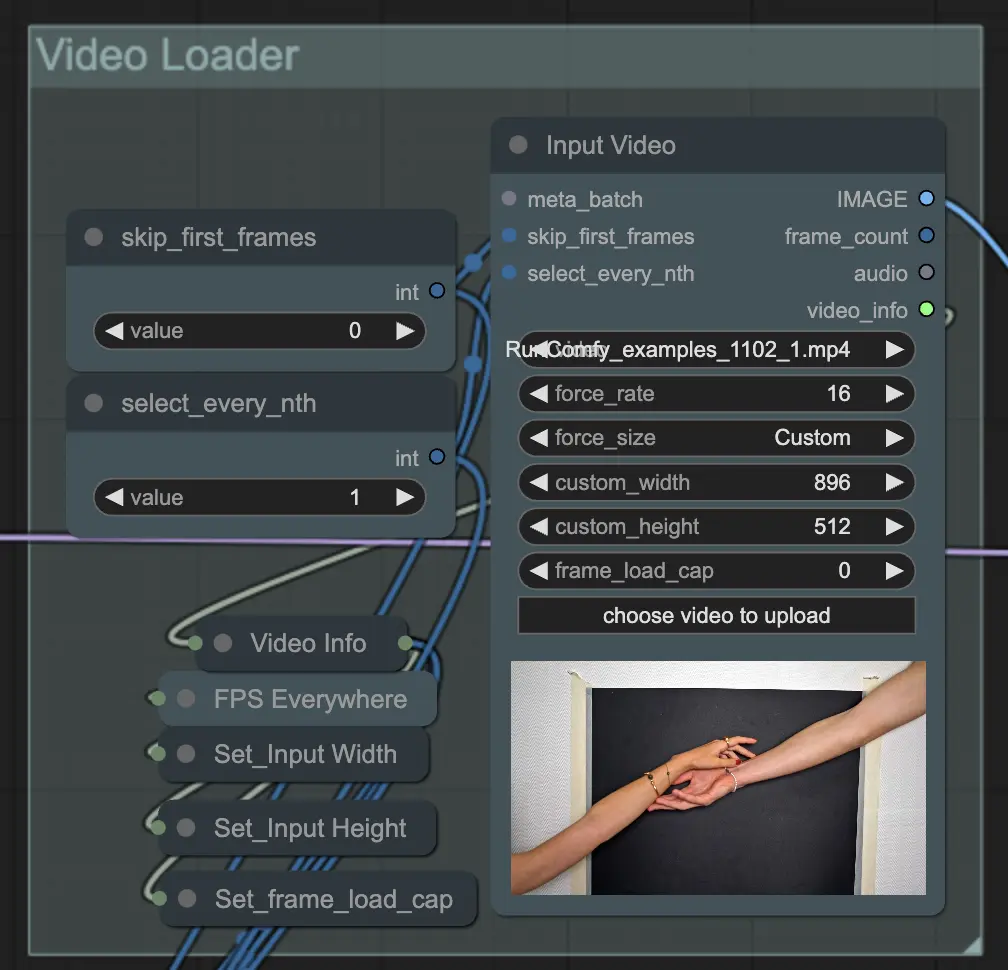
步骤 2: 视频加载器 | ComfyUI Vid2Vid 工作流程第 1 部分
输入视频节点负责导入将用于动画的视频文件。该节点读取视频并将其转换为单个帧,然后在后续步骤中处理。这允许详细的逐帧编辑和增强。
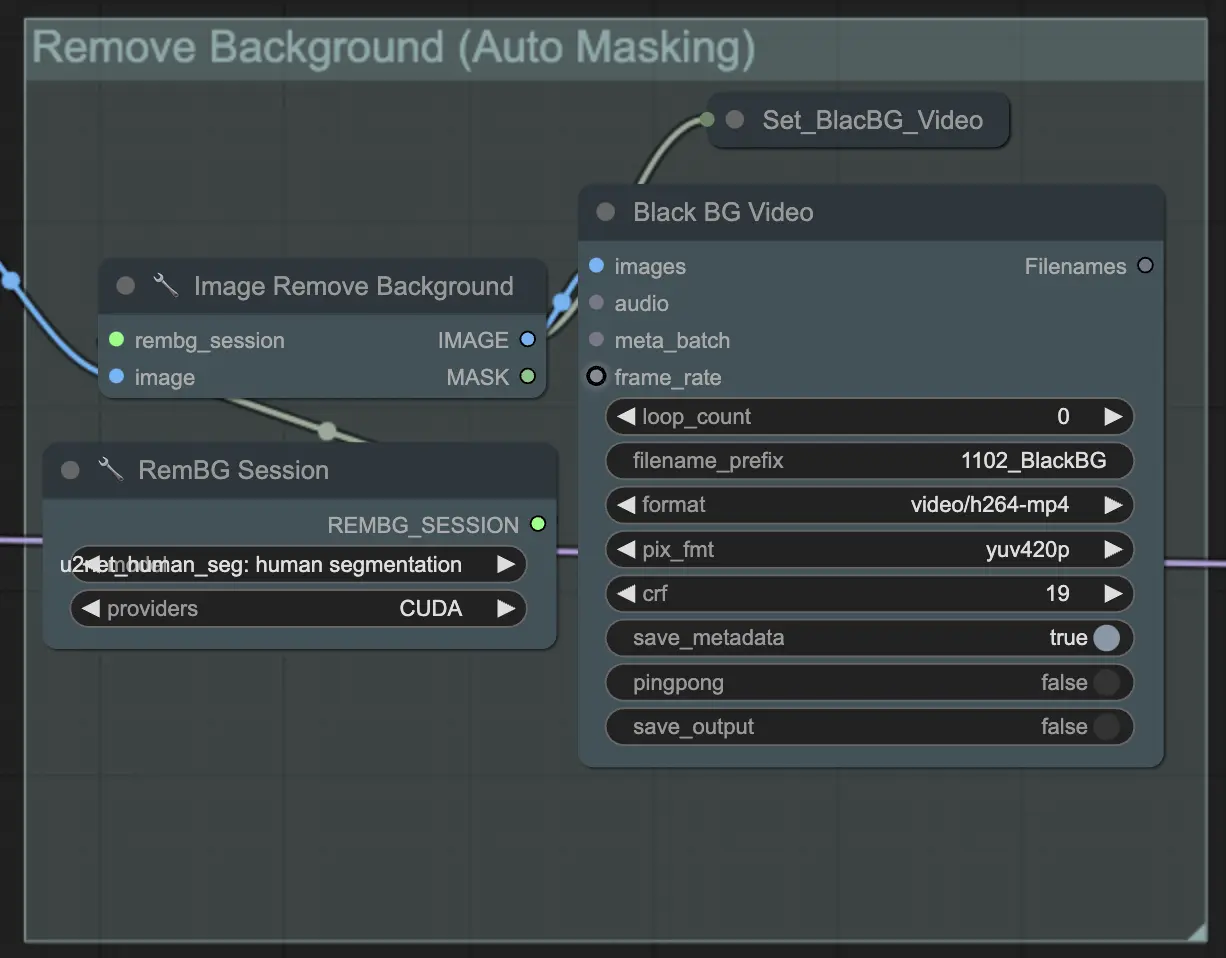
步骤 3: 移除背景(自动遮罩)| ComfyUI Vid2Vid 工作流程第 1 部分
**移除背景(自动遮罩)**使用自动遮罩技术将主体从背景中分离出来。这涉及检测和分离前景主体与背景的模型,创建二元遮罩。这一步对于确保主体可以独立于背景进行操作至关重要。
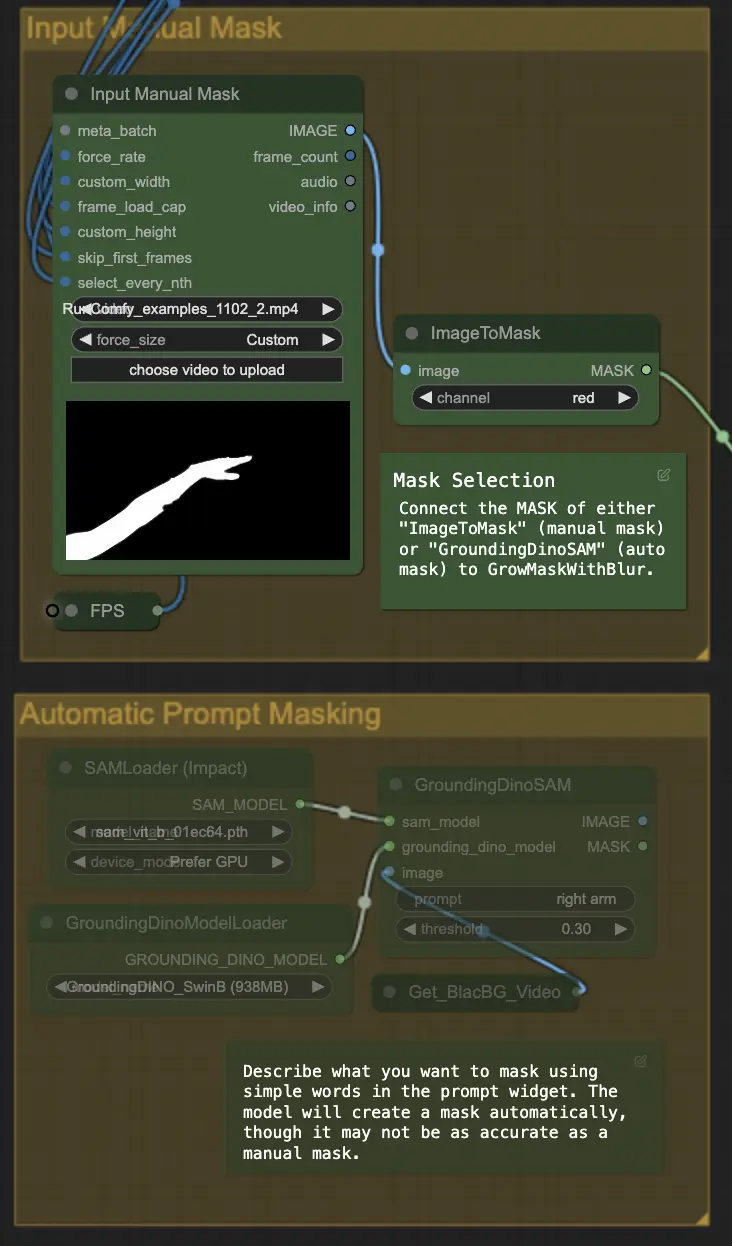
步骤 4: 遮罩特定区域(手动遮罩或自动遮罩)| ComfyUI Vid2Vid 工作流程第 1 部分
这一步允许对上一步创建的遮罩进行精细调整。您可以使用其他软件手动遮罩特定区域,或依赖 ComfyUI 的 'Segment Anything' 自动遮罩功能。
- 手动遮罩: 这需要在 ComfyUI 外部使用其他软件进行精确控制。
- 自动遮罩: 使用自动遮罩功能,您可以在提示小部件中用简单的文字描述您想要遮罩的内容。模型将自动创建遮罩,尽管它可能不如手动遮罩准确。
默认版本使用手动遮罩。如果您想尝试自动遮罩,请绕过手动遮罩组并启用自动遮罩组。此外,将 'GroundingDinoSAM'(自动遮罩)的 MASK 连接到 'GrowMaskWithBlur',而不是将 'ImageToMask'(手动遮罩)连接到 'GrowMaskWithBlur'。
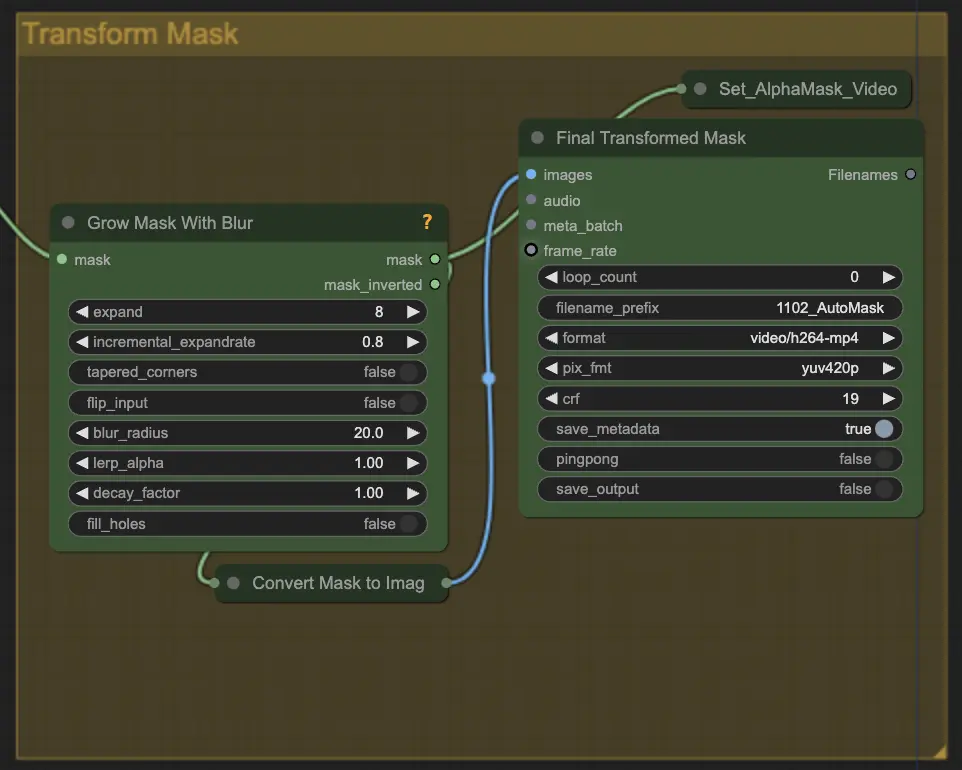
步骤 5: 转换遮罩 | ComfyUI Vid2Vid 工作流程第 1 部分
转换遮罩将遮罩转换为图像,并允许进行额外调整,如给原始遮罩添加模糊。这有助于软化边缘,使遮罩与图像的其余部分更自然地融合。
步骤 6: 输入提示 | ComfyUI Vid2Vid 工作流程第 1 部分
输入文本提示以指导动画过程。提示可以描述主体的风格、外观或动作。这对于定义动画的创意方向至关重要,确保最终输出与设想的艺术风格相符。
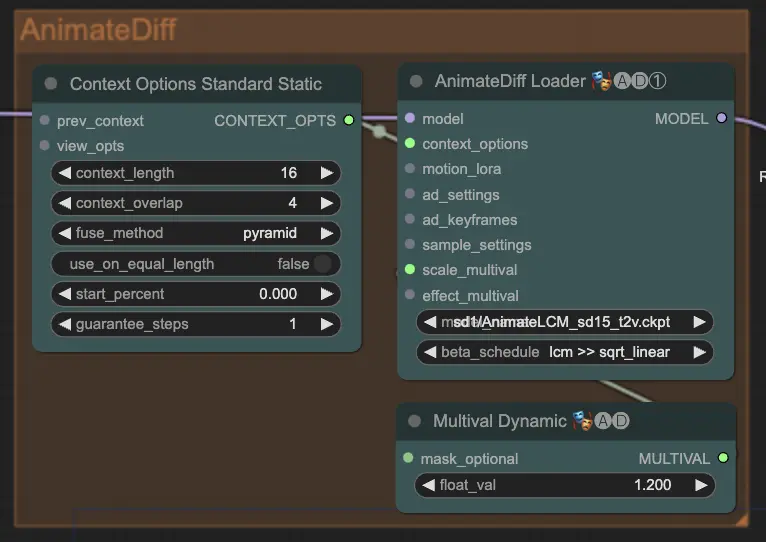
步骤 7: AnimateDiff | ComfyUI Vid2Vid 工作流程第 1 部分
AnimateDiff 节点通过识别连续帧之间的差异并逐步应用这些变化来创建流畅的动画。这有助于保持运动的连贯性,减少动画中突兀的变化,从而使其看起来更流畅和自然。
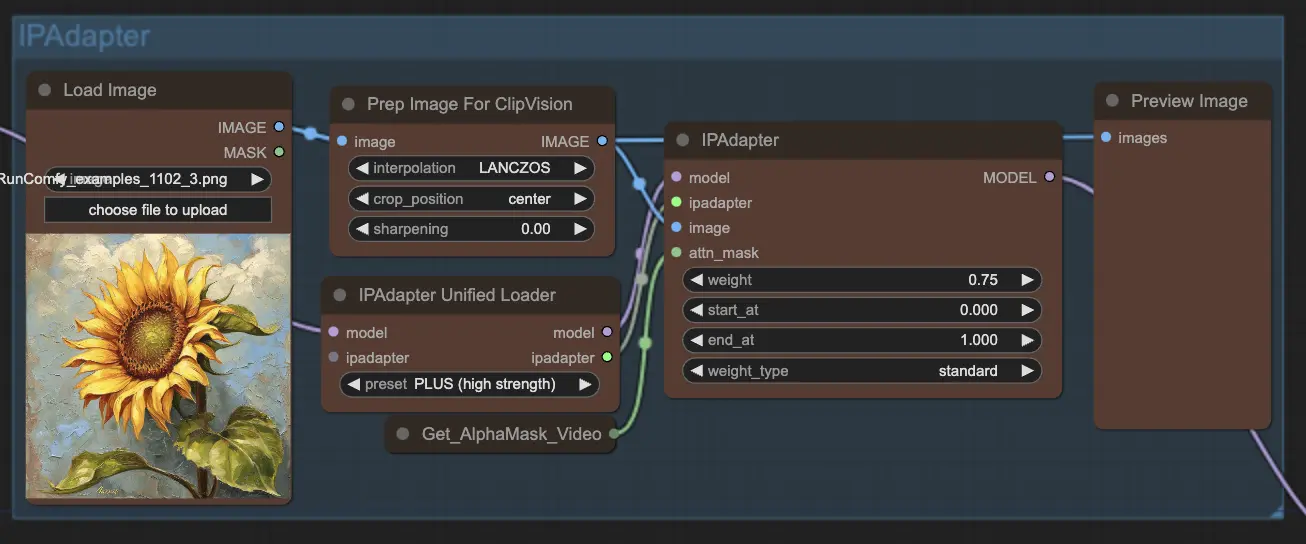
步骤 8: IPAdapter | ComfyUI Vid2Vid 工作流程第 1 部分
IPAdapter 节点调整输入图像以匹配所需的输出风格或特征。这包括颜色化和风格转移等任务,确保动画的每一帧都保持一致的外观和感觉。
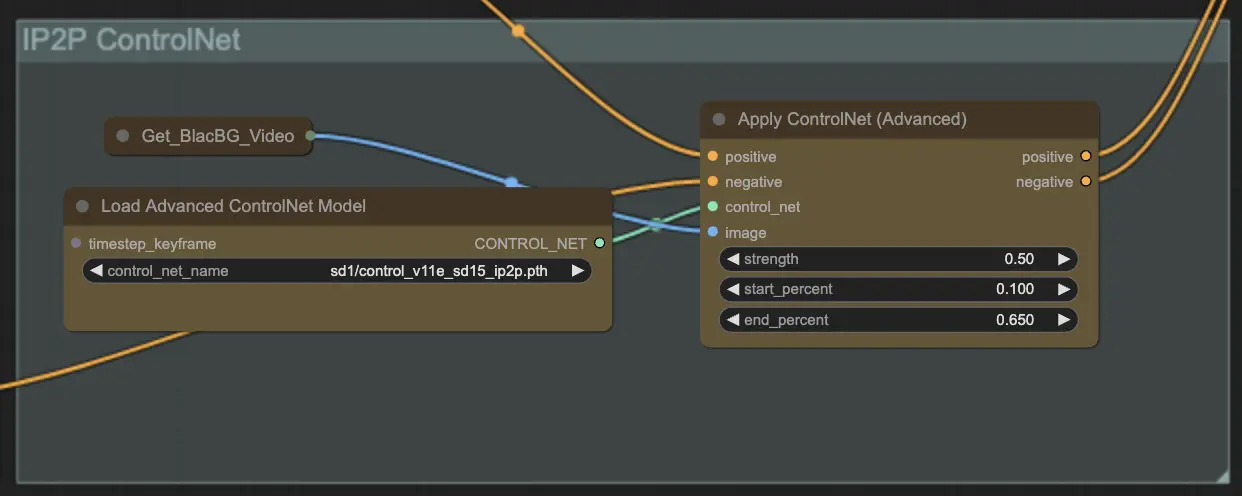
步骤 9: ControlNet | ComfyUI Vid2Vid 工作流程第 1 部分
使用 ControlNet - v1.1 - Instruct Pix2Pix Version 模型 通过使其能够处理额外的输入条件(例如边缘图、分割图)来增强扩散模型。它通过控制这些预训练模型的任务特定条件,以端到端的方式促进文本到图像生成,即使在较小的数据集上也能进行稳健的学习。
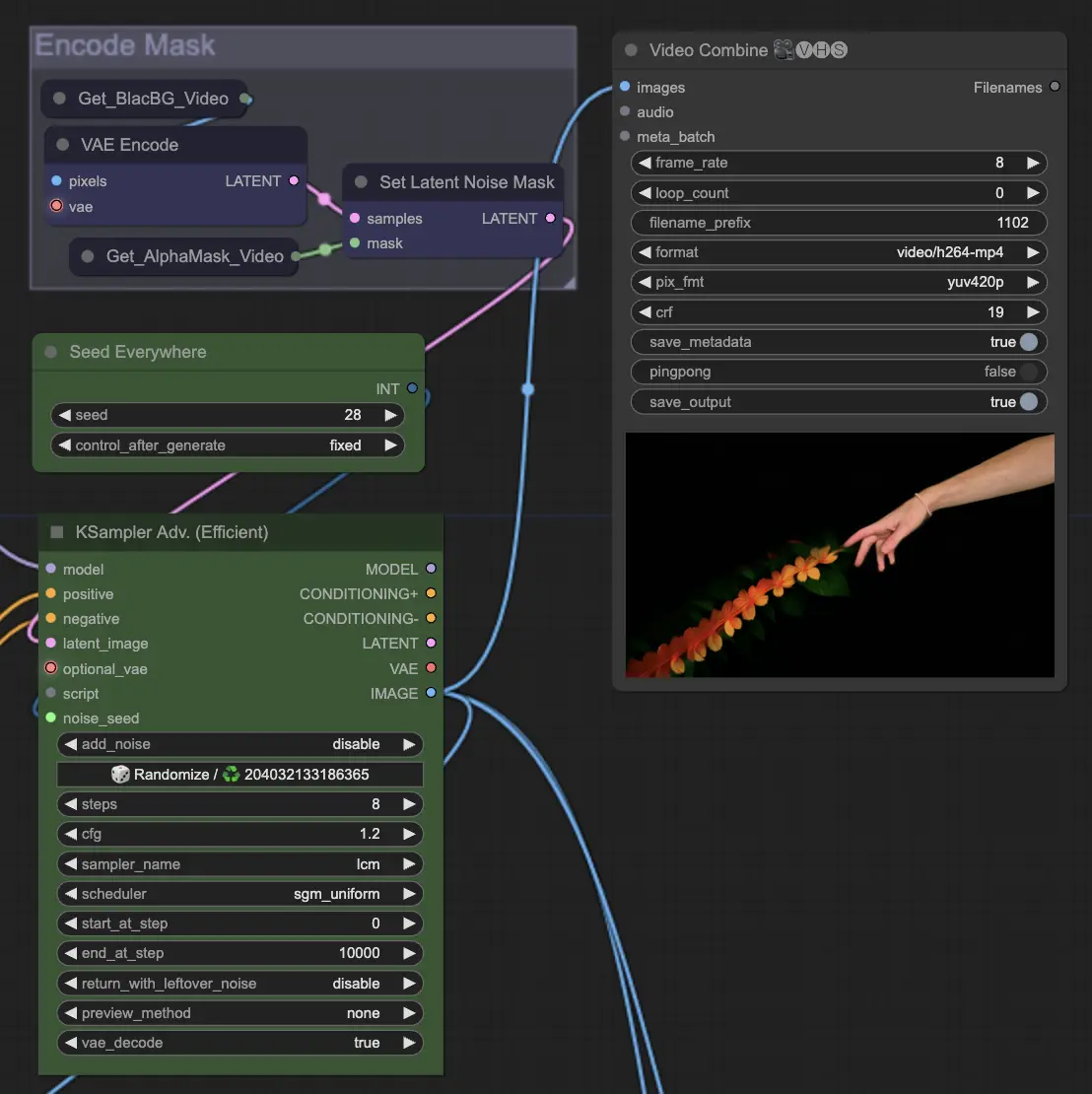
步骤 10: 渲染 | ComfyUI Vid2Vid 工作流程第 1 部分
在 渲染 步骤中,处理后的帧被编译成最终的视频输出。这一步确保所有单独的帧无缝地组合成一个连贯的动画,准备导出和进一步使用。
步骤 11: 组合背景 | ComfyUI Vid2Vid 工作流程第 1 部分
这涉及将动画主体与背景进行合成。您可以为动画添加静态或动态背景,确保主体与新背景平滑融合,创建视觉上吸引人的最终产品。
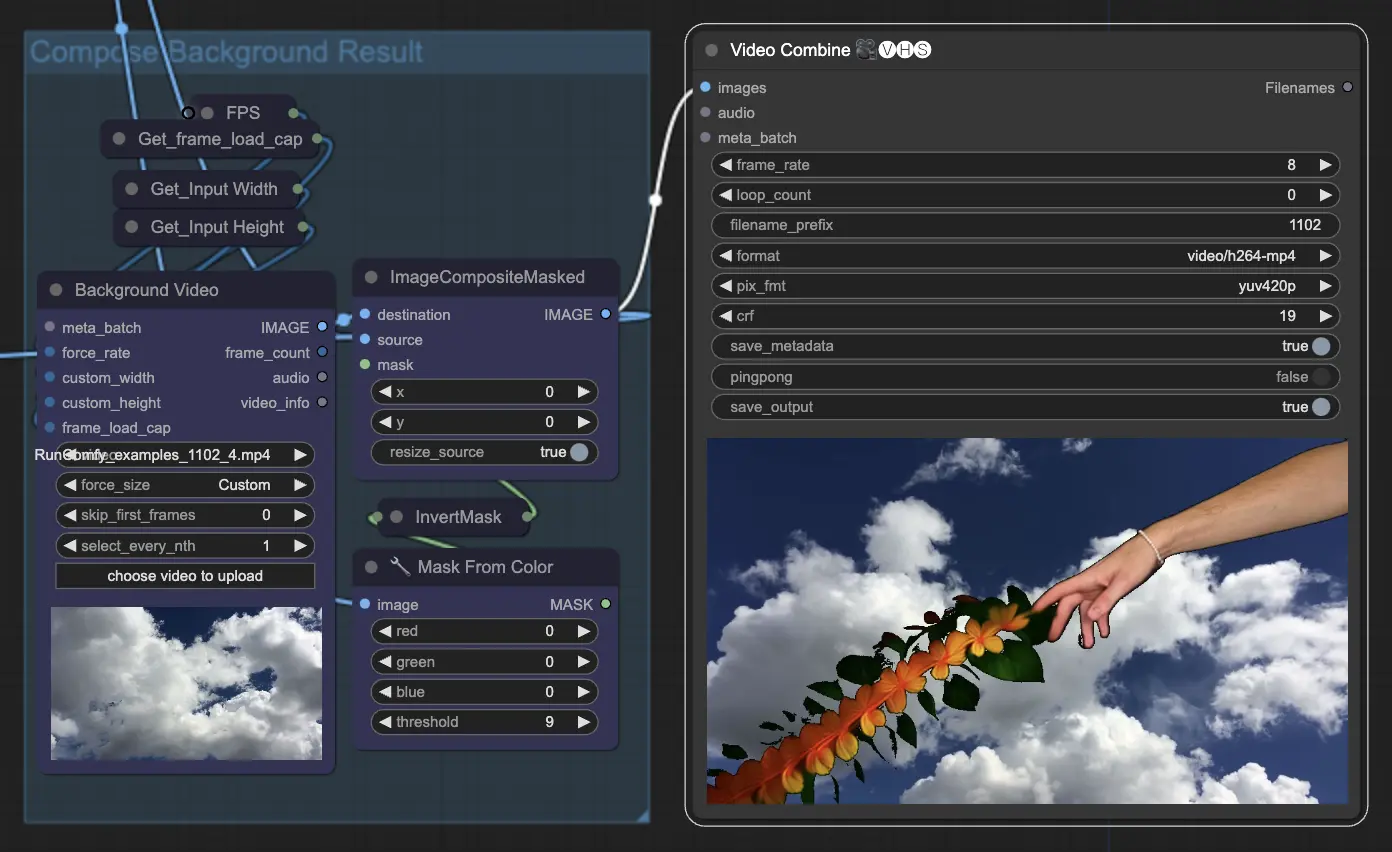
通过使用 ComfyUI Vid2Vid 工作流程第 1 部分,您可以创建复杂的动画,并精确控制从组合和遮罩到最终渲染的每一个方面。

