Hallo2 | 唇同步肖像动画
Hallo2是一个先进的AI模型,可以根据音频输入生成高质量的唇同步肖像动画。通过使用扩散模型、音频编码和人脸检测等技术,Hallo2能够创建4K动画,精确同步嘴部动作和表情。无缝集成在ComfyUI框架中,Hallo2使用户能够创建逼真的唇同步肖像动画。ComfyUI Hallo2 Lip-Sync 工作流程
想要运行这个工作流吗?
- 完全可操作的工作流
- 没有缺失的节点或模型
- 无需手动设置
- 具有惊艳的视觉效果
ComfyUI Hallo2 Lip-Sync 示例
ComfyUI Hallo2 Lip-Sync 描述
Hallo2技术由复旦大学和百度公司的崔佳豪、李辉、姚尧、朱昊、商涵林、程开辉、周航、朱思宇和王井东开发。更多信息,请访问。ComfyUI_Hallo2节点和工作流程由smthemex开发。更多详情,请访问。所有贡献归功于他们。
1. 关于Hallo2
Hallo2是一个用于生成高质量、长时长、4K分辨率音频驱动肖像动画视频的前沿模型。它在原有Hallo模型的基础上进行了几项关键改进:
- 支持生成更长的视频,最长可达数十分钟甚至数小时
- 生成4K分辨率的视频
- 除了音频外,还允许使用文本提示控制表情和姿态
Hallo2通过使用高级技术,如数据增强,以保持长时间的一致性,向量量化潜在代码以实现4K分辨率,以及改进的去噪过程,由音频和文本共同指导实现这一目标。
2. Hallo2的技术特征
Hallo2结合了几种先进的AI模型和技术来创建高质量的肖像视频:
- 扩散模型:这是生成视频帧的核心"引擎"。它从随机噪声开始,逐渐精炼至匹配所需输出,由音频和文本提示引导。
- 3D U-Net:这是一种神经网络,在扩散过程中充当"雕刻师"。它查看当前的噪声帧、音频和文本指令,并建议如何更改噪声,使其更像最终的肖像。
- 音频编码器:Hallo2使用一个名为Wav2Vec2的模型作为其"耳朵"来理解音频,将原始波形转换为捕捉语调、速度和语音内容的紧凑表示。
- 人脸检测器:为了帮助其专注于面部动画,Hallo2使用人脸检测模型自动定位参考图像中的肖像面部。然后它知道在哪里应用唇部和表情动作。
- 图像压缩器:为了高效处理高分辨率的4K图像,Hallo2使用一种特殊类型的自动编码器模型(VQ-VAE)将它们压缩成更小的"潜在"表示,然后在最后解码回4K。这就像JPEG在缩小图像文件大小的同时保持质量一样。
- 增强技巧:为了在长视频中保持质量,Hallo2在使用之前对先前生成的帧应用一些聪明的"数据增强"。这些包括偶尔擦除随机补丁或添加细微噪声。这有助于防止可能积累并破坏一致性的复合错误。
总之 - Hallo2接收音频和肖像图像,有一个AI "代理"来雕刻视频帧以匹配它们,同时保持原始肖像的真实性,并使用一些额外的技巧来保持一切同步和连贯,即使在长视频中。这些部分在一个多步骤的管道中协同工作,产生你所看到的令人印象深刻的结果。
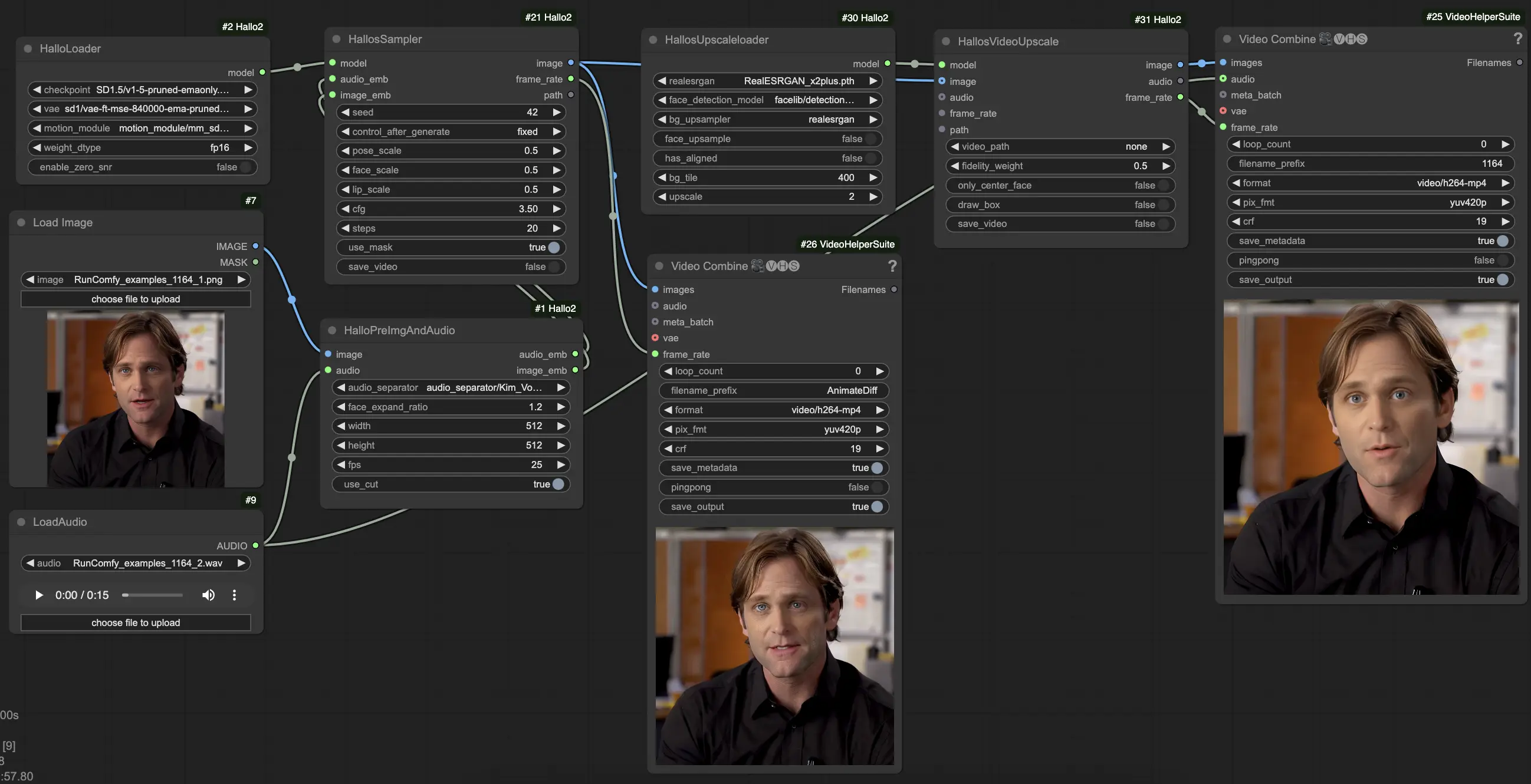
3. 如何使用ComfyUI Hallo2工作流程
Hallo2已通过几个专用节点集成到ComfyUI中。使用方法如下:
- 使用
LoadImage节点加载您的参考肖像图像。这应该是一个清晰的正面肖像。(提示:您的参考肖像框架和照明越好,结果就越好。避免侧面轮廓、遮挡、繁忙的背景等。) - 使用
LoadAudio节点加载您的驱动音频。它应符合您希望肖像表现的情绪。 - 将图像和音频连接到
HalloPreImgAndAudio节点。这会将图像和音频预处理为嵌入。关键参数:audio_separator:用于将语音与背景噪声分离的模型。通常保持默认值。face_expand_ratio:扩展检测到的面部区域的比例。较高的值包括更多的头发/背景。width/height:生成分辨率。较高的值较慢但更详细。512-1024平方是一个不错的平衡。fps:目标视频FPS。25是一个不错的默认值。
- 使用
HalloLoader节点加载核心Hallo2模型。指向您的Hallo2检查点、VAE和运动模块文件。 - 将预处理的图像和音频嵌入以及加载的模型连接到
HalloSampler节点。这执行实际的视频生成。关键参数:seed:决定细节的随机种子。如果您不喜欢第一个结果,请更改它。pose_scale/face_scale/lip_scale:姿态、面部表情和唇部动作强度的缩放比例。1.0 = 全强度,0.0 = 冻结。cfg:无分类指导缩放。较高 = 更紧随条件但多样性较少。steps:去噪步骤的数量。更多步骤 = 更好的质量但较慢。
- 此时,您可以查看生成的视频。要通过超分辨率进一步提高质量,请在链的末端添加
HallosUpscaleloader和HallosVideoUpscale节点。放大加载器读取预训练的放大模型,而放大器节点实际上执行到4K的放大。


