深入了解ComfyUI ControlNet:Depth、OpenPose、Canny、Lineart、Softedge、Scribble、Seg等特性...
Updated: 3/20/2024
大家好!在本指南中,我们将深入探讨ControlNet在ComfyUI中的精彩世界。让我们一起探索它带来的优势以及如何为你的项目增添色彩!
我们将涵盖以下内容:
1. 什么是ControlNet?
2. ControlNet背后的技术原理
3. 如何使用ComfyUI ControlNet:基本步骤
- 3.1. 在ComfyUI中加载"Apply ControlNet"节点
- 3.2. "Apply ControlNet"节点的输入
- 3.3. "Apply ControlNet"节点的输出
- 3.4. 微调"Apply ControlNet"的参数
4. 如何使用ComfyUI ControlNet:高级特性 - 时间步关键帧
5. 各种ControlNet/T2IAdaptor模型:详细概述
- 5.1. ControlNet Openpose
- 5.2. ControlNet Tile
- 5.3. ControlNet Canny
- 5.4. ControlNet Depth
- 5.5. ControlNet Lineart
- 5.6. ControlNet Scribbles
- 5.7. ControlNet Segmentation
- 5.8. ControlNet Shuffle
- 5.9. ControlNet Inpainting
- 5.10. ControlNet MLSD
- 5.11. ControlNet Normalmaps
- 5.12. ControlNet Soft Edge
- 5.13. ControlNet IP2P (Instruct Pix2Pix)
- 5.14. T2I Adapter
- 5.15. 其他流行的ControlNet:QRCode Monster和IP-Adapter
6. 如何使用多个ControlNet
7. 立即体验ComfyUI ControlNet!
🌟🌟🌟 ComfyUI在线体验 - 立即体验ControlNet工作流 🌟🌟🌟
如果你有兴趣探索ControlNet工作流,请使用以下ComfyUI网页。它配备了所有基本的自定义节点和模型,无需手动设置即可实现无缝创作。立即开始动手体验ControlNet的功能,或继续阅读本教程以了解如何有效使用ControlNet。
更多高级和付费版ComfyUI工作流,请访问我们的 🌟ComfyUI工作流列表🌟
1. 什么是ControlNet?
ControlNet是一项变革性技术,显著增强了文本到图像扩散模型的能力,实现了前所未有的图像生成空间控制。作为一个神经网络架构,ControlNet可以与规模庞大的预训练模型(如Stable Diffusion)无缝集成。它利用了这些在数十亿张图像上训练的模型 将空间条件引入图像创建过程。这些条件的范围很广,从边缘和人体姿势到深度和分割图,使用户能够以单纯文本提示无法实现的方式引导图像生成。
2. ControlNet背后的技术原理
ControlNet的精妙之处在于其独特的方法。首先,它固定原始模型的参数,确保基础训练保持不变。随后,ControlNet引入了一个编码层的克隆模型用于训练,采用"零卷积"。这些特殊设计的卷积层以零权重开始,小心地集成新的空间条件。这种方法可以防止任何干扰噪声的介入,在保持模型原有能力的同时,启动新的学习轨迹。
3. 如何使用ComfyUI ControlNet:基本步骤
传统的stable diffusion模型使用文本提示作为条件机制来引导图像生成,使输出与文本提示的细节保持一致。ControlNet在这个过程中引入了一种额外的条件形式,增强了根据文本和视觉输入更精确地控制生成图像的能力。
3.1. 在ComfyUI中加载"Apply ControlNet"节点
这一步将ControlNet集成到你的ComfyUI工作流中,使其能够在图像生成过程中应用额外的条件。它为将视觉引导与文本提示相结合奠定了基础。
3.2. "Apply ControlNet"节点的输入
正面和负面条件:这些输入对于定义期望的结果和要避免的方面至关重要。它们应分别链接到"正面提示"和"负面提示",与过程的文本条件部分保持一致。
ControlNet模型:此输入应连接到"Load ControlNet Model"节点的输出。这一步至关重要,用于选择并将ControlNet或T2IAdaptor模型纳入你的工作流,从而确保扩散模型受益于所选模型提供的特定指导。每个模型,无论是ControlNet还是T2IAdaptor,都经过严格训练,以根据特定数据类型或风格偏好影响图像生成过程。考虑到许多T2IAdaptor模型的功能与ControlNet模型非常相似,我们后续讨论的重点将主要放在ControlNet模型上。但为了完整性,我们也会重点介绍一些更受欢迎的T2IAdaptor。
预处理器:"image"输入必须连接到"ControlNet Preprocessor"节点,这对于使你的图像适应所使用的ControlNet模型的特定需求至关重要。使用针对所选ControlNet模型定制的正确预处理器至关重要。此步骤可确保原始图像经过必要的修改—例如格式、大小、颜色的调整,或特定滤镜的应用—以优化它用于ControlNet的指导。经过这个预处理阶段后,原始图像被修改后的版本所取代,ControlNet随后将其应用。这个过程可确保你的输入图像为ControlNet过程做好了精确准备。
3.3. "Apply ControlNet"节点的输出
"Apply ControlNet"节点生成两个关键输出:正面和负面条件。这些输出融入了ControlNet和视觉引导的细微影响,在控制ComfyUI中的扩散模型行为方面发挥了关键作用。此后,你面临一个选择:进入KSampler进行采样阶段以进一步完善生成的图像,或者,对于那些追求在创作中实现更高层次的细节和自定义的人来说,继续叠加额外的ControlNet。这种集成更多ControlNet的高级技术允许更细粒度地操纵图像属性,为旨在实现无与伦比的精确度和控制的创作者提供了增强的工具包。
3.4. 微调"Apply ControlNet"的参数
strength:此参数决定了ControlNet对ComfyUI生成图像的影响强度。1.0意味着完全强度,即ControlNet的引导将对扩散模型的输出产生最大影响。相反,0.0表示没有影响,基本上禁用了ControlNet对图像生成过程的影响。
start_percent:此参数指定ControlNet开始影响生成的起始点,以扩散过程的百分比表示。例如,设置20%的起始百分比意味着ControlNet的引导将从扩散过程的20%开始影响图像生成。
end_percent:类似于"Start Percent","End Percent"参数定义ControlNet的影响停止的点。例如,80%的结束百分比意味着ControlNet的引导在扩散过程完成80%时停止影响图像生成,最后阶段不受影响。
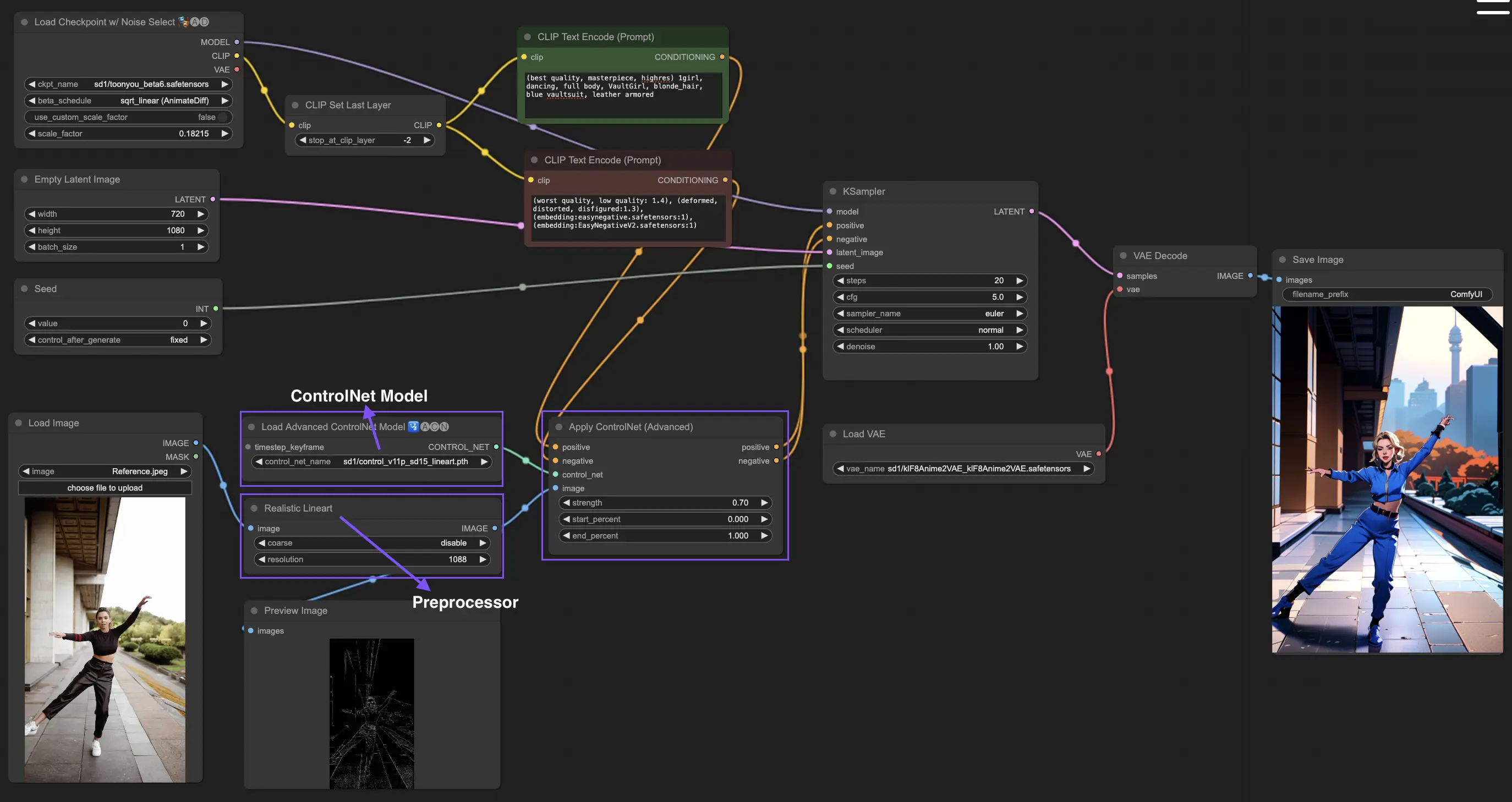
4. 如何使用ComfyUI ControlNet:高级特性 - 时间步关键帧
ControlNet中的时间步关键帧在AI生成内容的行为控制方面提供了复杂的控制,特别是在时间和进展至关重要的情况下,如动画或不断发展的视觉效果。以下是关键参数的详细分解,以帮助你有效且直观地使用它们:
prev_timestep_kf:可以将prev_timestep_kf视为与序列中之前的关键帧连接。通过连接关键帧,你可以创建一个平滑过渡或分镜板,引导AI逐步完成生成过程,确保每个阶段都合乎逻辑地流入下一个阶段。
cn_weights:cn_weights有助于通过在生成过程的不同阶段调整ControlNet内的特定特征来微调输出。
latent_keyframe:latent_keyframe允许你在生成过程的特定阶段调整AI模型的每个部分对最终结果的影响强度。例如,如果你要生成一个图像,其中前景在过程演变中应变得更加细节化,你可以在后面的关键帧中增加负责前景细节的模型方面(潜在因素)的强度。相反,如果某些特征应随时间逐渐淡入背景,你可以在后续关键帧中降低它们的强度。这种控制级别在创建动态、不断发展的视觉效果或精确时间和进展至关重要的项目中特别有用。
mask_optional:使用注意力遮罩作为聚光灯,将ControlNet的影响集中在图像的特定区域。无论是突出场景中的角色还是强调背景元素,这些遮罩可以统一应用,也可以改变强度,精确地将AI的注意力引导到你想要的地方。
start_percent:start_percent标记你的关键帧开始发挥作用的时间点,以整个生成过程的百分比来衡量。设置这个就像安排演员在舞台上的登场时间,确保他们在表演中恰到好处地出现。
strength:strength提供对ControlNet整体影响的高级控制。
null_latent_kf_strength:对于在此场景(关键帧)中没有明确指示的任何演员(潜在因素),null_latent_kf_strength作为默认指令,告诉他们如何在背景中表现。它确保生成的任何部分都不会没有指导,即使在你没有具体提到的区域也能保持连贯的输出。
inherit_missing:激活inherit_missing允许你的当前关键帧采用其前身未指定的任何设置,就像弟弟妹妹继承衣服一样。它是一个有用的快捷方式,可以在不需要重复指令的情况下确保连续性和一致性。
guarantee_usage:guarantee_usage是你的保证,无论如何,当前关键帧在过程中都会有发挥作用的时刻,即使只是短暂的一瞬间。它确保你设置的每个关键帧都会产生影响,尊重你在引导AI创作过程中的详细规划。
时间步关键帧提供了精确引导AI创作过程所需的精度,使你能够完全按照自己的设想来编排视觉的演变,特别是在动画中,从开场到结尾。下面我们将更仔细地看时间步关键帧如何战略性地应用于管理动画的进展,确保从初始帧到最后一帧的无缝过渡,与你的艺术目标完美契合。
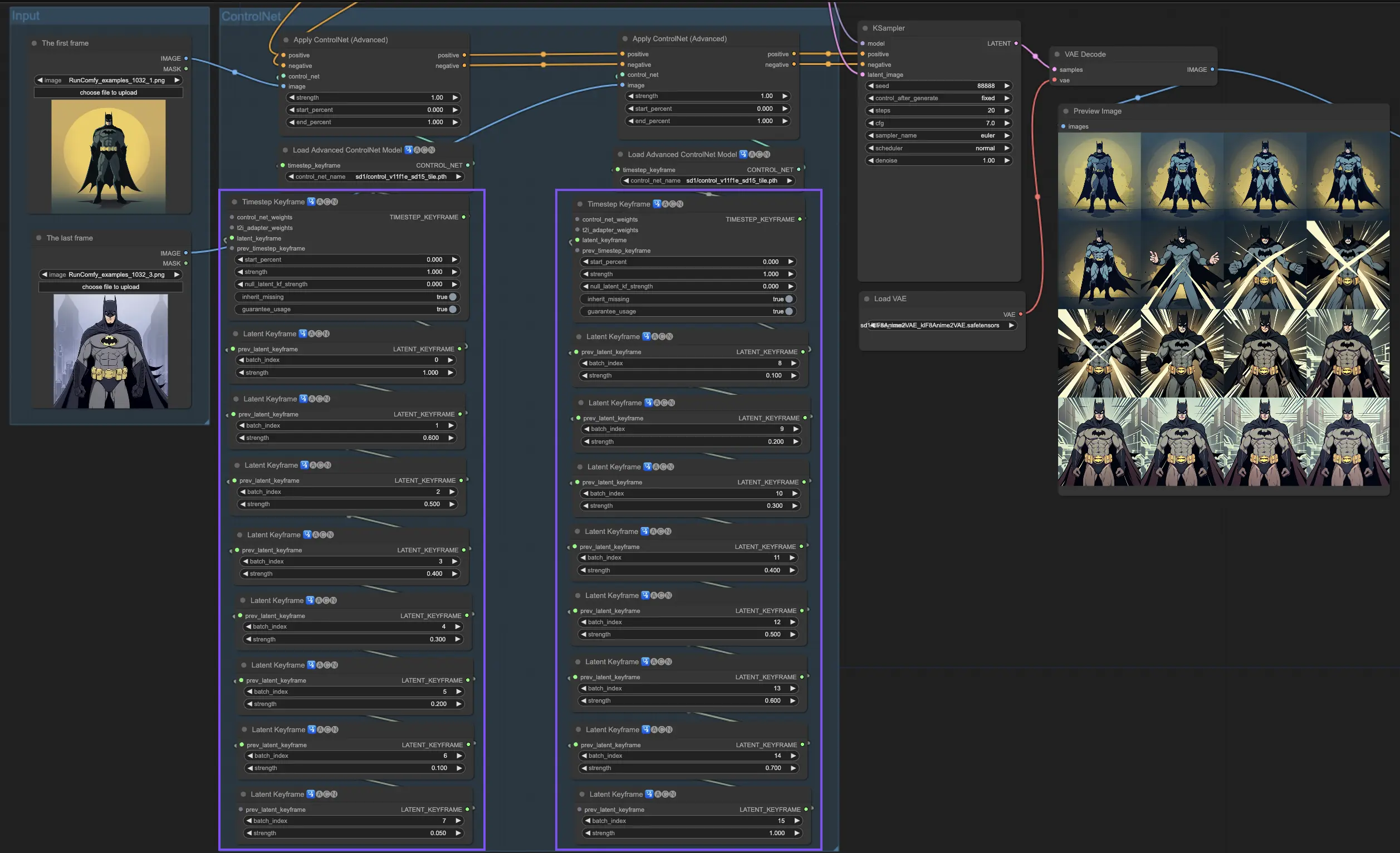
5. 各种ControlNet/T2IAdaptor模型:详细概述
鉴于许多T2IAdaptor模型的功能与ControlNet模型非常相似,我们后续讨论的重点将主要放在ControlNet模型上。但为了完整性,我们也会重点介绍一些更受欢迎的T2IAdaptor。
5.1. ComfyUI ControlNet Openpose
- Openpose (=Openpose body):ControlNet内的基础模型,识别眼睛、鼻子、脖子、肩膀、肘部、手腕、膝盖和脚踝等基本身体关键点。它非常适合基本的人体姿势复制。
- Openpose_face:通过添加面部关键点检测来扩展OpenPose模型,提供对面部表情和方向的更详细分析。这个ControlNet模型对于专注于面部表情的项目至关重要。
- Openpose_hand:增强OpenPose模型,能够捕捉手和手指的复杂细节,专注于详细的手势和位置。这一补充增强了OpenPose在ControlNet中的多功能性。
- Openpose_faceonly:一个专门用于面部细节的模型,省略身体关键点,专注于捕捉表情和面部方向。这个ControlNet内的模型专门关注面部特征。
- Openpose_full:OpenPose、OpenPose_face和OpenPose_hand模型的全面结合,提供对全身、面部和手部的完整检测,实现ControlNet内的完整人体姿势复制。
- DW_Openpose_full:OpenPose_full模型的增强版,结合了额外的改进,实现更详细和准确的姿势检测。这个版本代表了ControlNet框架内姿势检测准确性的巅峰。
预处理器:Openpose或DWpose
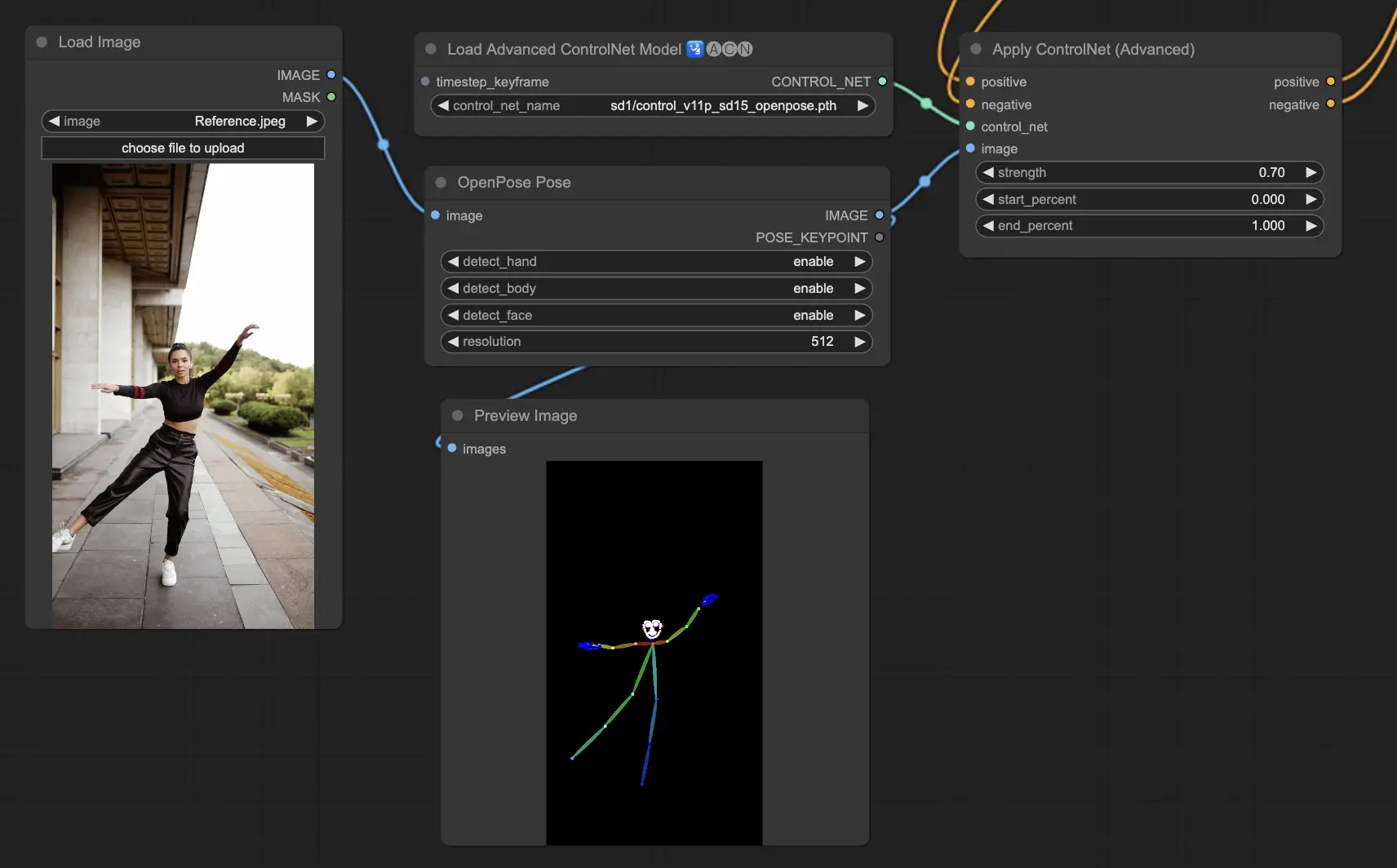
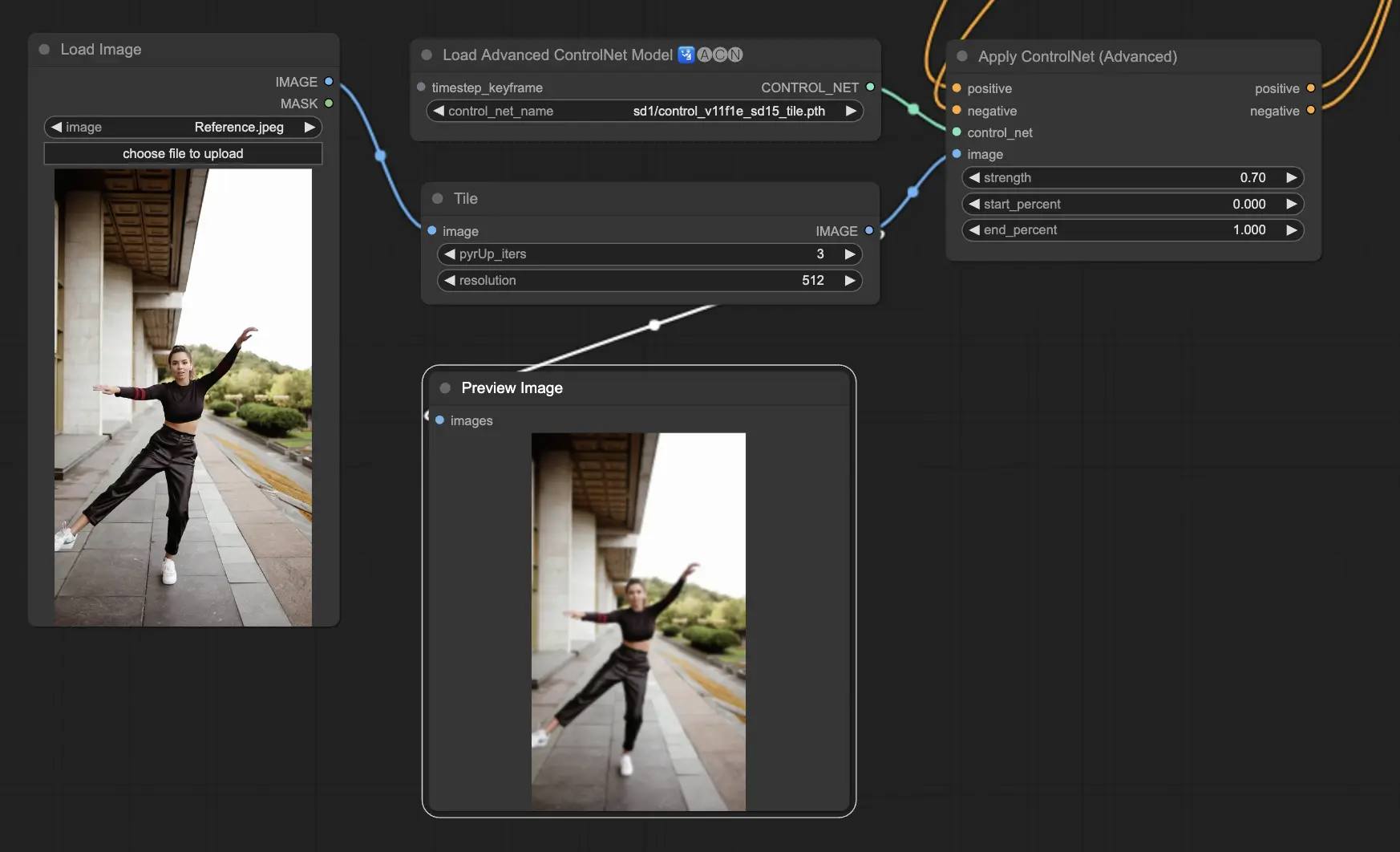
5.2. ComfyUI ControlNet Tile
Tile Resample模型用于图像的细节增强。它特别适合与上采样器结合使用,以提高图像分辨率的同时添加更精细的细节,通常用于锐化和丰富图像内的纹理和元素。
预处理器:Tile
5.3. ComfyUI ControlNet Canny
Canny模型应用Canny边缘检测算法,这是一个多阶段过程,用于检测图像中的各种边缘。这个模型有利于在简化视觉组成的同时保留图像的结构方面,使其适用于程式化艺术或进一步图像处理前的预处理。
预处理器:Canny
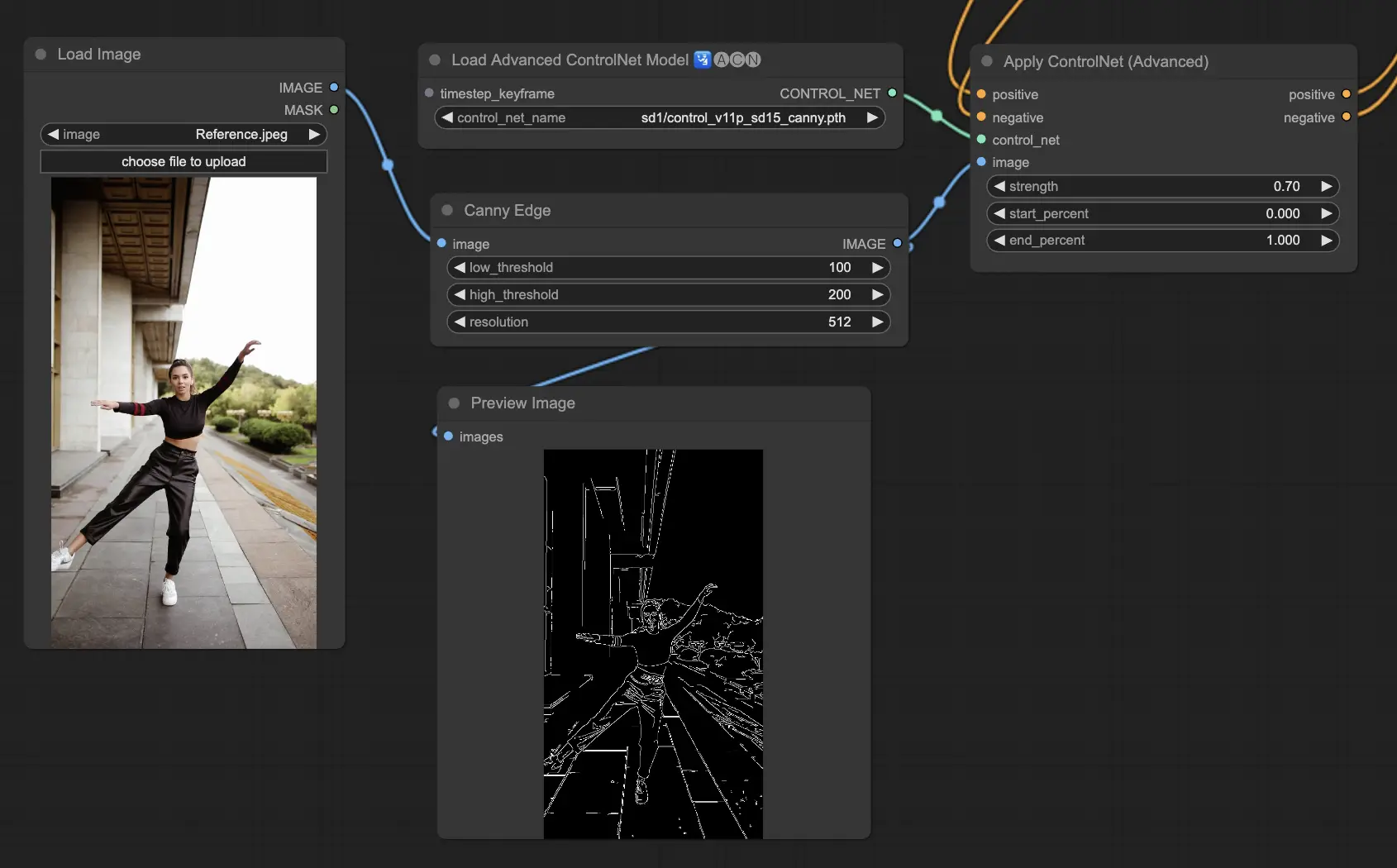
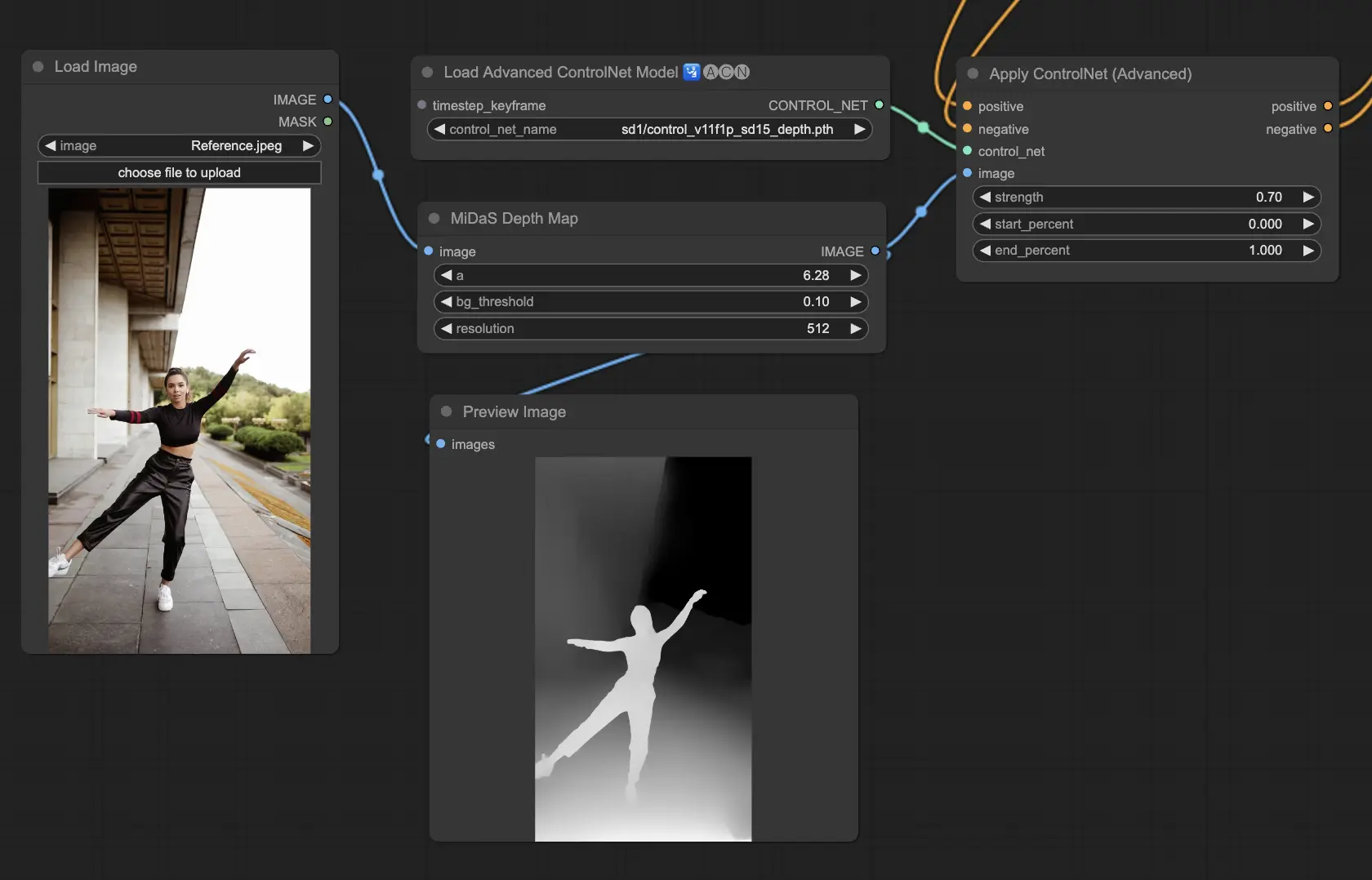
5.4. ComfyUI ControlNet Depth
Depth模型从2D图像推断深度信息,将感知距离转化为灰度深度图。每个变体在细节捕捉和背景强调之间提供不同的平衡:
- Depth Midas:提供经典的深度估计,在细节和背景渲染之间取得平衡。
- Depth Leres:侧重于增强细节,倾向于包含更多背景元素。
- Depth Leres++:为深度信息提供高级别的细节,非常适合复杂场景。
- Zoe:在细节层次方面在Midas和Leres模型之间取得平衡。
- Depth Anything:一种新的、改进的深度估计模型,专为各种场景而设计。
- Depth Hand Refiner:专门设计用于改善深度图中的手部细节,适用于手部定位至关重要的场景。
预处理器:Depth_Midas、Depth_Leres、Depth_Zoe、Depth_Anything、MeshGraphormer_Hand_Refiner。这个模型非常稳健,可以在渲染引擎生成的真实深度图上工作。
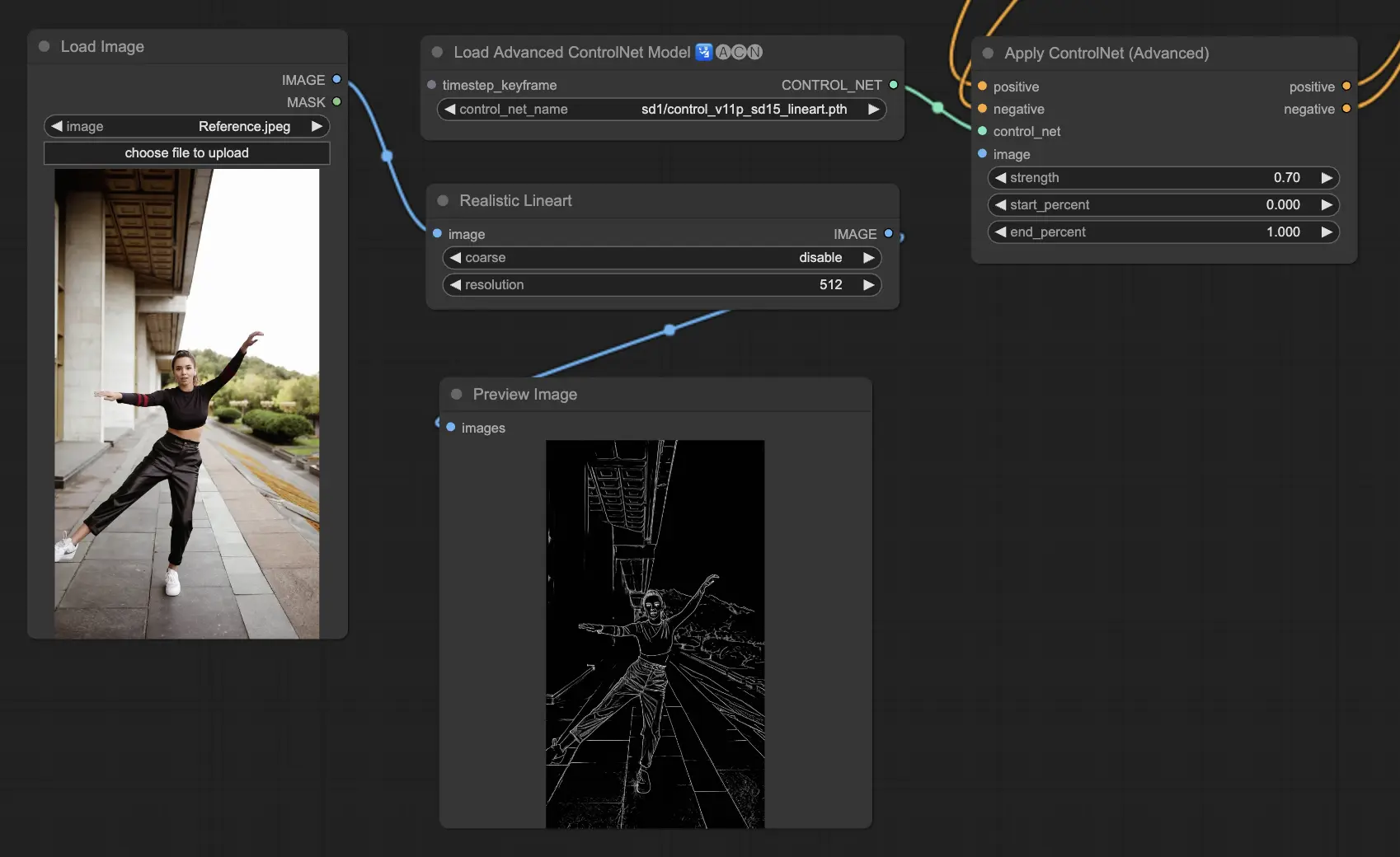
5.5. ComfyUI ControlNet Lineart
Lineart模型将图像转换为程式化的线条绘图,可用于艺术渲染或作为进一步创作工作的基础:
- Lineart:这个标准模型将图像转换为程式化的线条绘图,为各种艺术或创意项目提供通用的基础。
- Lineart anime:专注于生成动漫风格的线条绘图,以干净、精确的线条为特征,适合追求动漫美学的项目。
- Lineart realistic:生成具有更写实风格的线条绘图,以更多细节捕捉主体的本质,非常适合需要逼真表现的项目。
- Lineart coarse:生成更加鲜明的线条绘图,线条更粗重、更大胆,创造出引人注目的效果,特别适合大胆的艺术表达。
预处理器可以从图像生成详细或粗略的线条(Lineart和Lineart_Coarse)
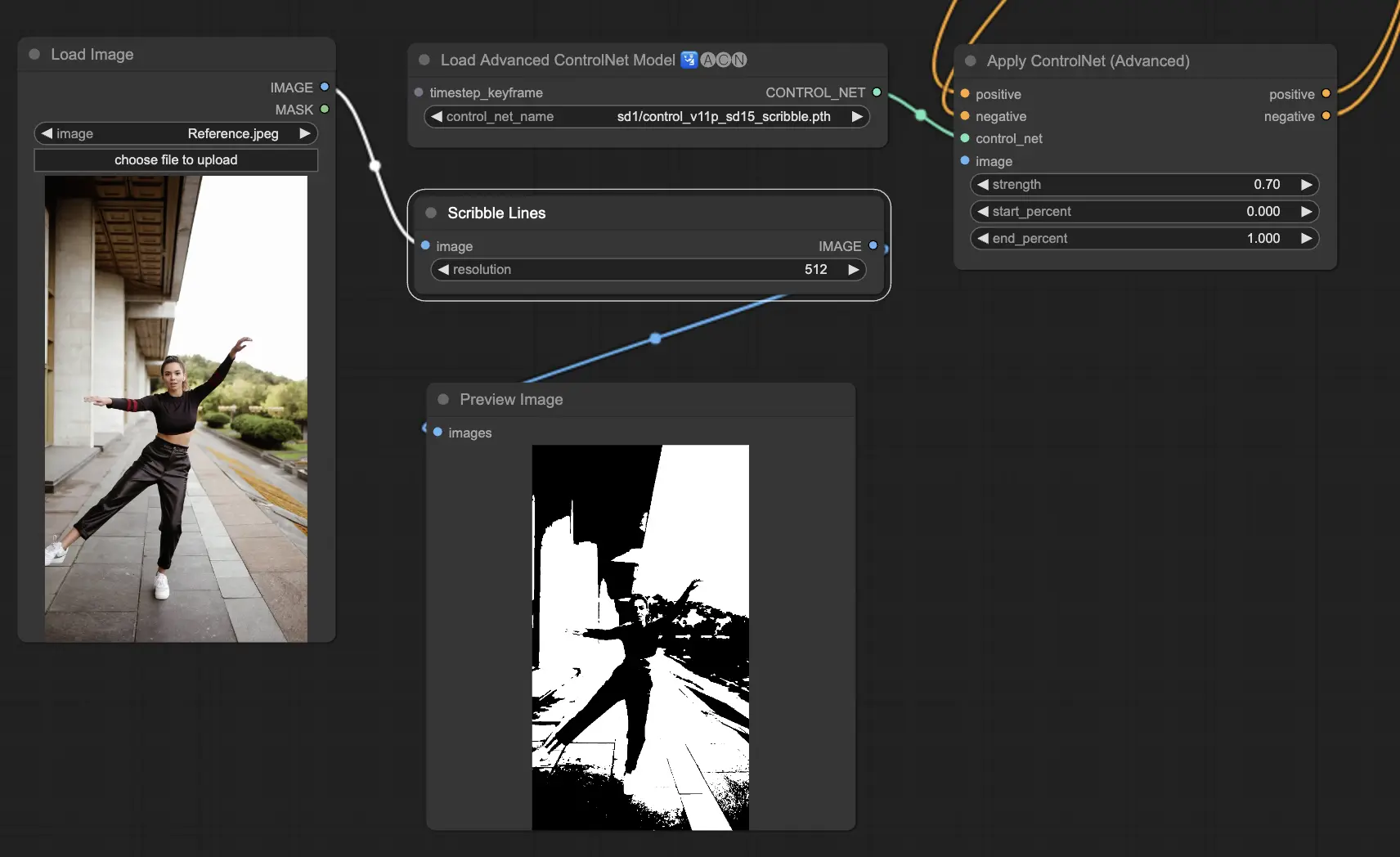
5.6. ComfyUI ControlNet Scribbles
Scribble模型旨在将图像转换为类似涂鸦的外观,模拟手绘草图的外观。它们特别适用于艺术重塑或作为更大设计工作流程中的初步步骤:
- Scribble:旨在将图像转换为详细的艺术作品,模拟手绘涂鸦或草图。
- Scribble HED:利用整体嵌套边缘检测(HED)生成类似手绘草图的轮廓。建议用于图像的重新着色和重塑,为艺术作品添加独特的艺术风格。
- Scribble Pidinet:专注于检测像素差异,以生成更清晰的线条,减少细节,非常适合更抽象的表现。Scribble Pidinet非常适合追求清晰曲线和直线边缘的人,提供一种精致的外观,同时保留基本细节。
- Scribble xdog:采用扩展差分高斯(xDoG)方法进行边缘检测。这允许调整阈值设置以微调涂鸦效果,使用户能够控制艺术作品中的细节水平。xDoG非常通用,使用户能够在艺术创作中取得完美平衡。
预处理器:Scribble、Scribble_HED、Scribble_PIDI和Scribble_XDOG
5.7. ComfyUI ControlNet Segmentation
分割模型将图像像素分类为不同的对象类,每个类由特定颜色表示。这对于识别和操作图像中的单个元素非常有价值,例如将前景与背景分离,或区分对象以进行详细编辑。
- Seg:旨在通过颜色区分图像中的对象,有效地将这些区别转化为输出中的不同元素。例如,它可以分离房间布局中的家具,这使其对于需要精确控制图像构图和编辑的项目特别有价值。
- ufade20k:利用在ADE20K数据集上训练的UniFormer分割模型,能够以高精度区分广泛的对象类型。
- ofade20k:采用OneFormer分割模型,也在ADE20K上训练,以其独特的分割能力提供另一种对象区分方法。
- ofcoco:利用在COCO数据集上训练的OneFormer分割,针对COCO数据集参数内分类的对象图像进行定制,有助于精确的对象识别和操作。
可接受的预处理器:Sam、Seg_OFADE20K(Oneformer ADE20K)、Seg_UFADE20K(Uniformer ADE20K)、Seg_OFCOCO(Oneformer COCO)或手动创建的遮罩。
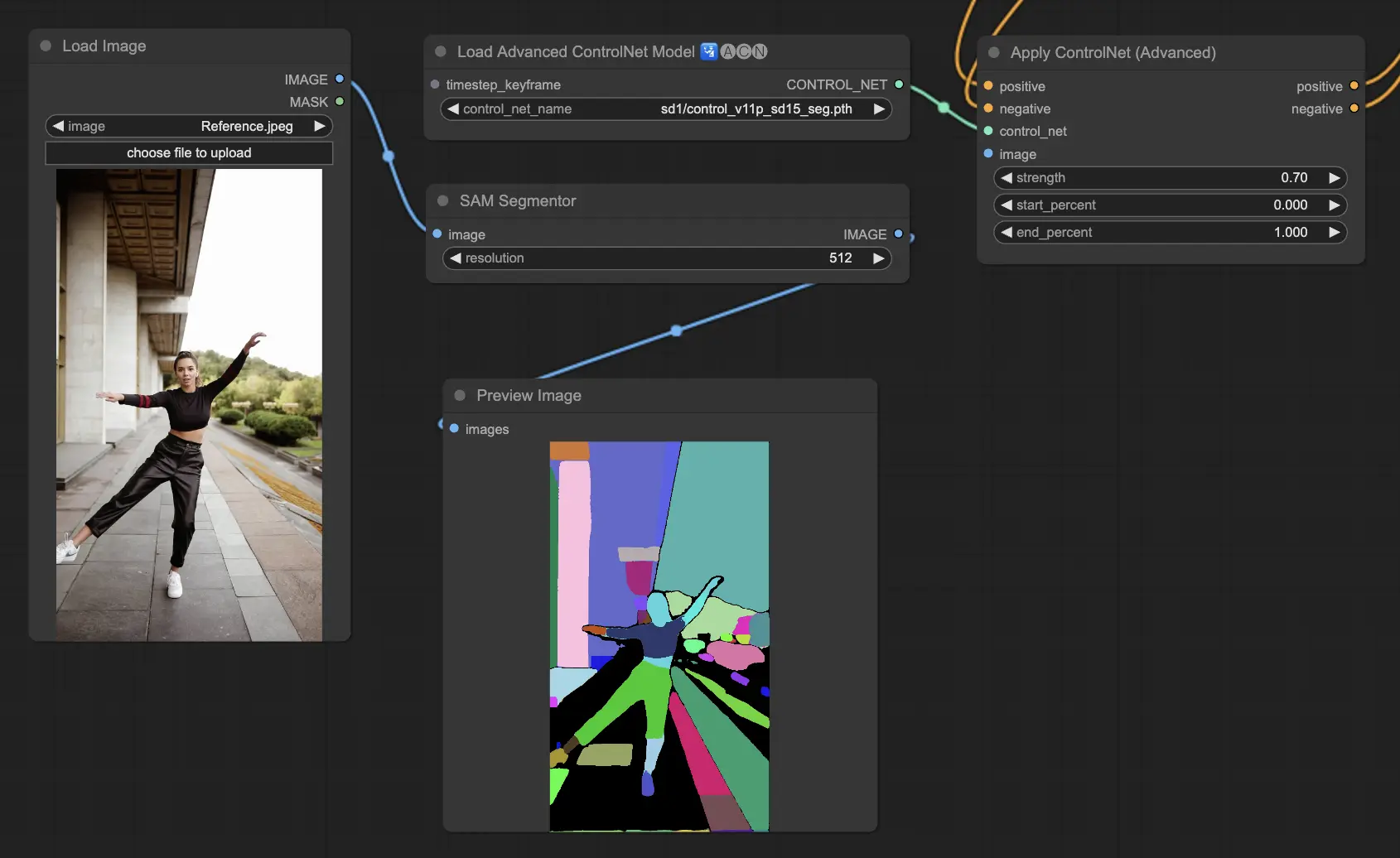
5.8. ComfyUI ControlNet Shuffle
Shuffle模型采用一种新颖的方法,通过随机化输入图像的属性,如配色方案或纹理,而不改变构图。这个模型在创意探索和生成同一图像的变体方面特别有效,保留了结构完整性,但改变了视觉美学。它的随机性意味着每个输出都是独特的,受生成过程中使用的种子值的影响。
预处理器:Shuffle
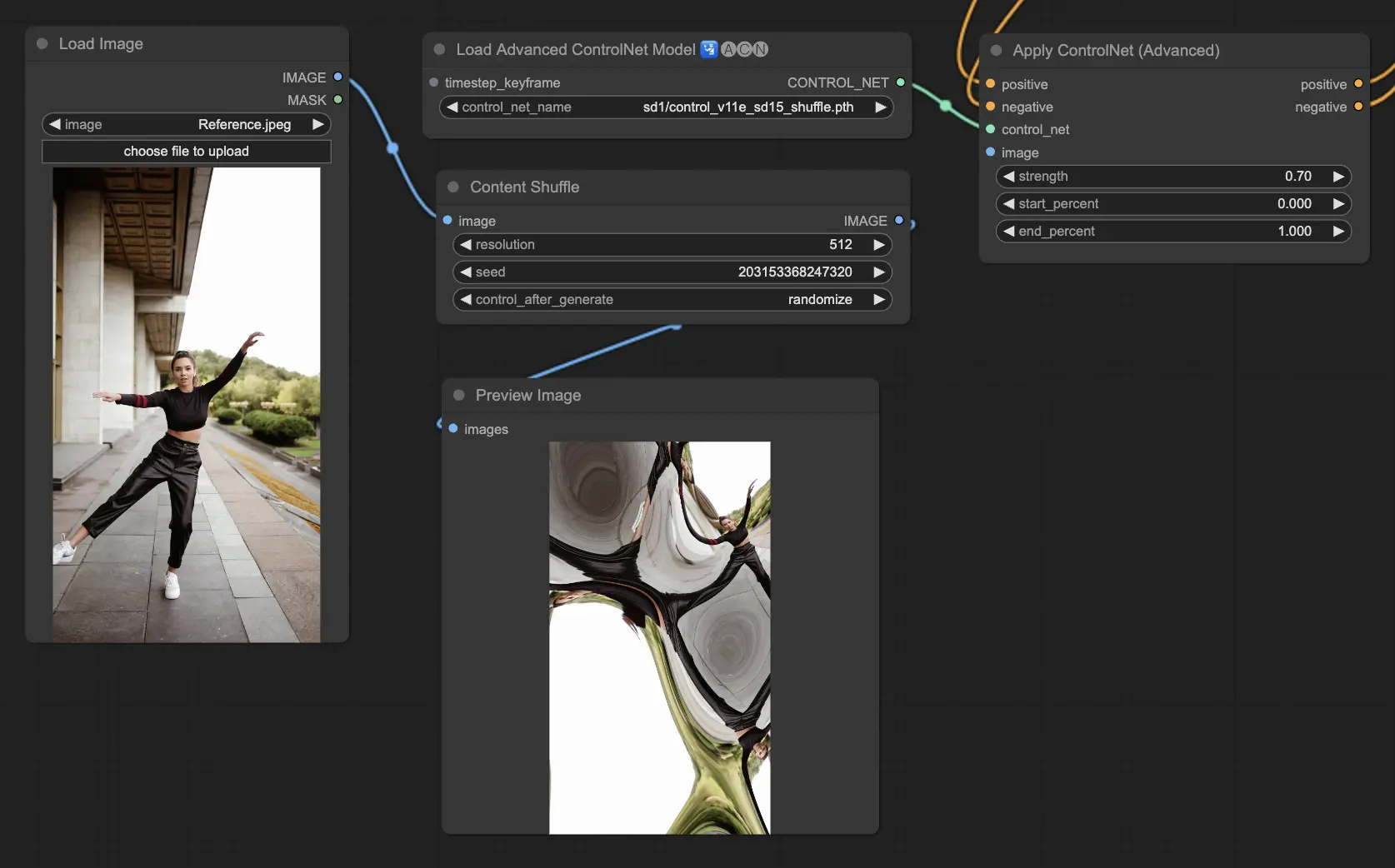
5.9. ComfyUI ControlNet Inpainting
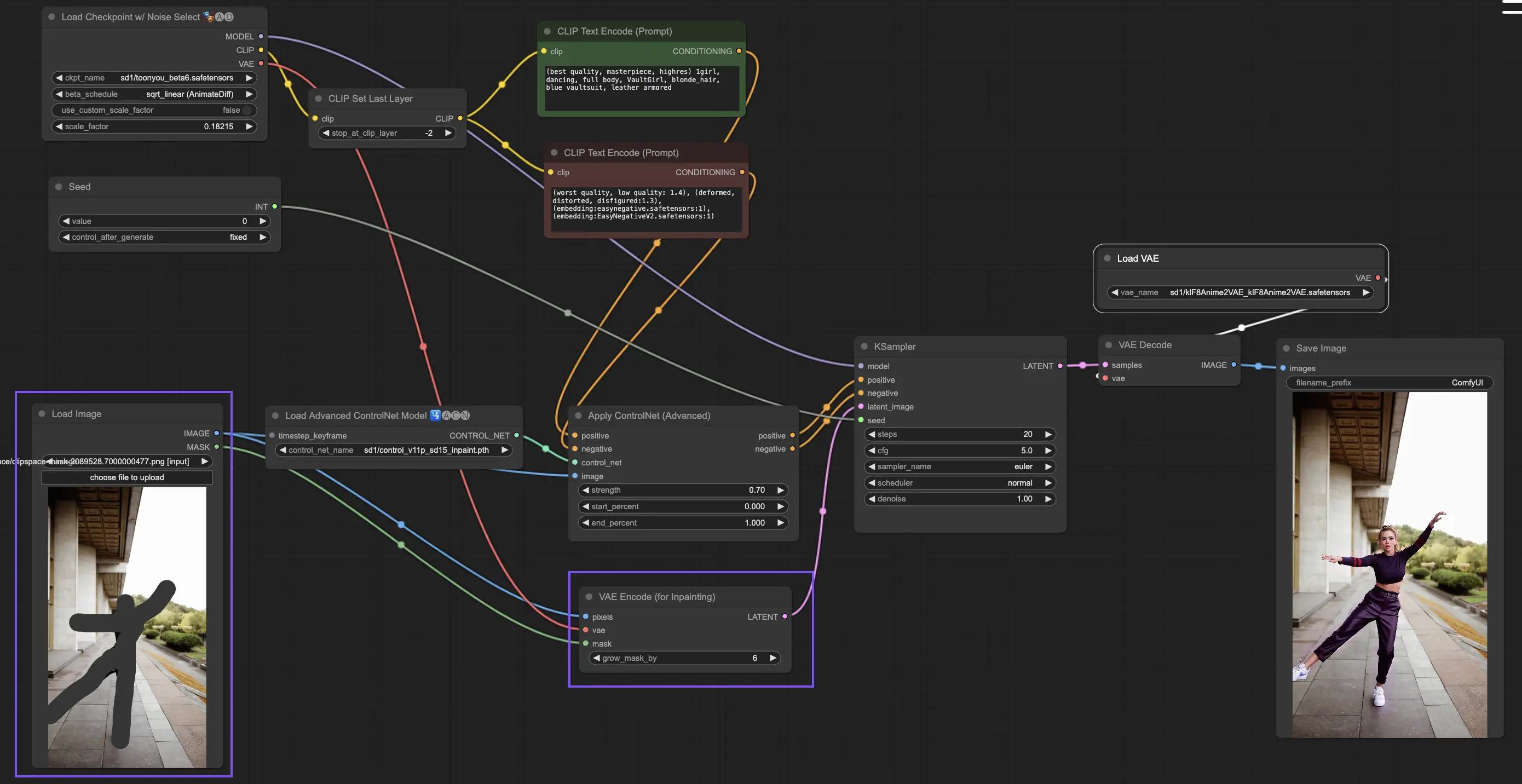
ControlNet内的Inpainting模型允许在图像的特定区域进行细化编辑,在保持整体连贯性的同时引入显著的变化或修正。
要使用ControlNet Inpainting,首先通过遮罩隔离要重新生成的区域。这可以通过右键单击所需的图像并选择"Open in MaskEditor"进行修改来实现。
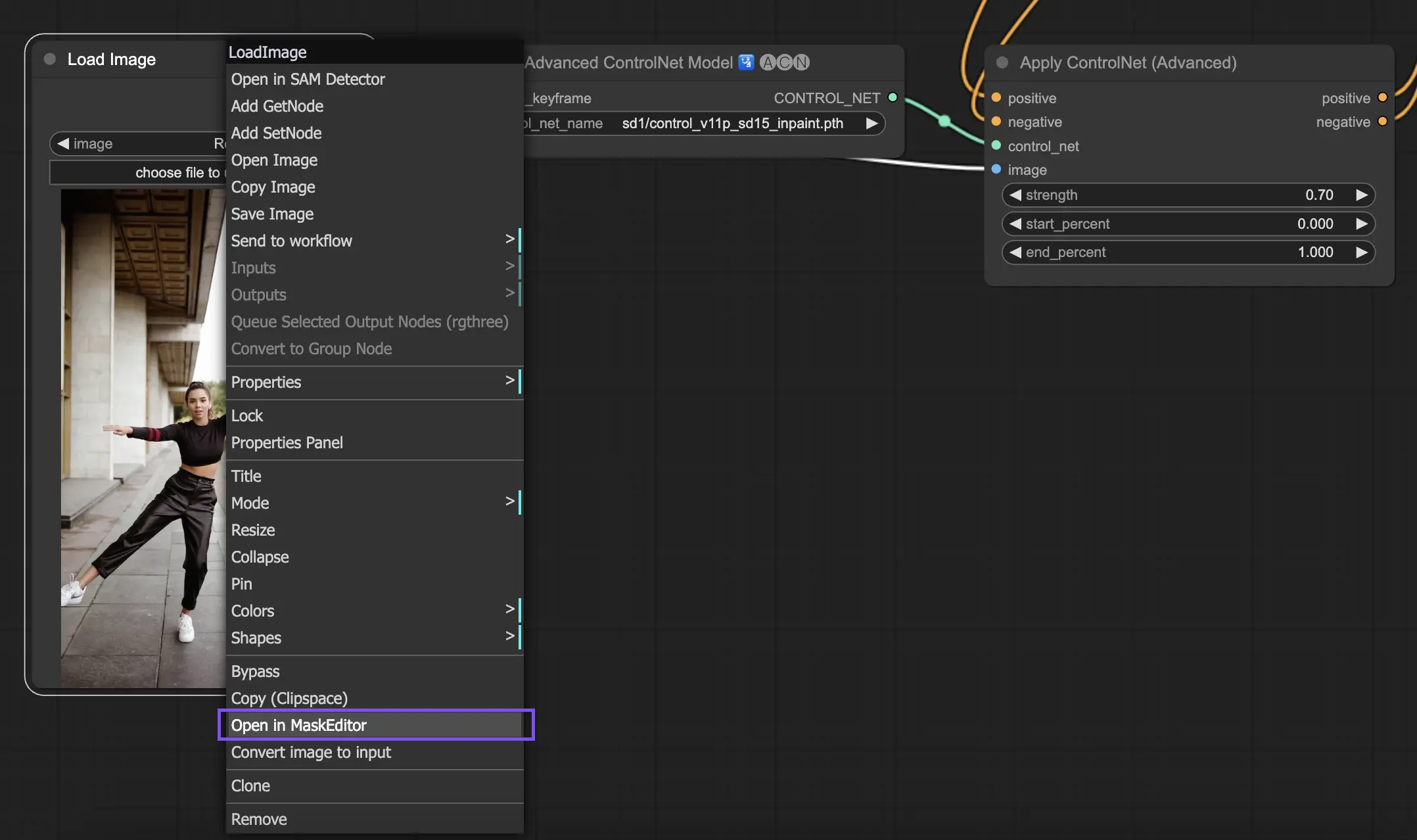
与ControlNet中的其他实现不同,Inpainting由于直接对图像进行修改而绕过了预处理器的需要。但是,将编辑后的图像转发到潜在空间via KSampler至关重要。这确保了扩散模型只专注于重新生成遮罩区域,保持未遮罩区域的完整性。
5.10. ComfyUI ControlNet MLSD
M-LSD(Mobile Line Segment Detection)专注于检测直线,非常适合具有强烈建筑元素、室内和几何形式的图像。它将场景简化为其结构本质,有助于涉及人造环境的创意项目。
预处理器:MLSD。
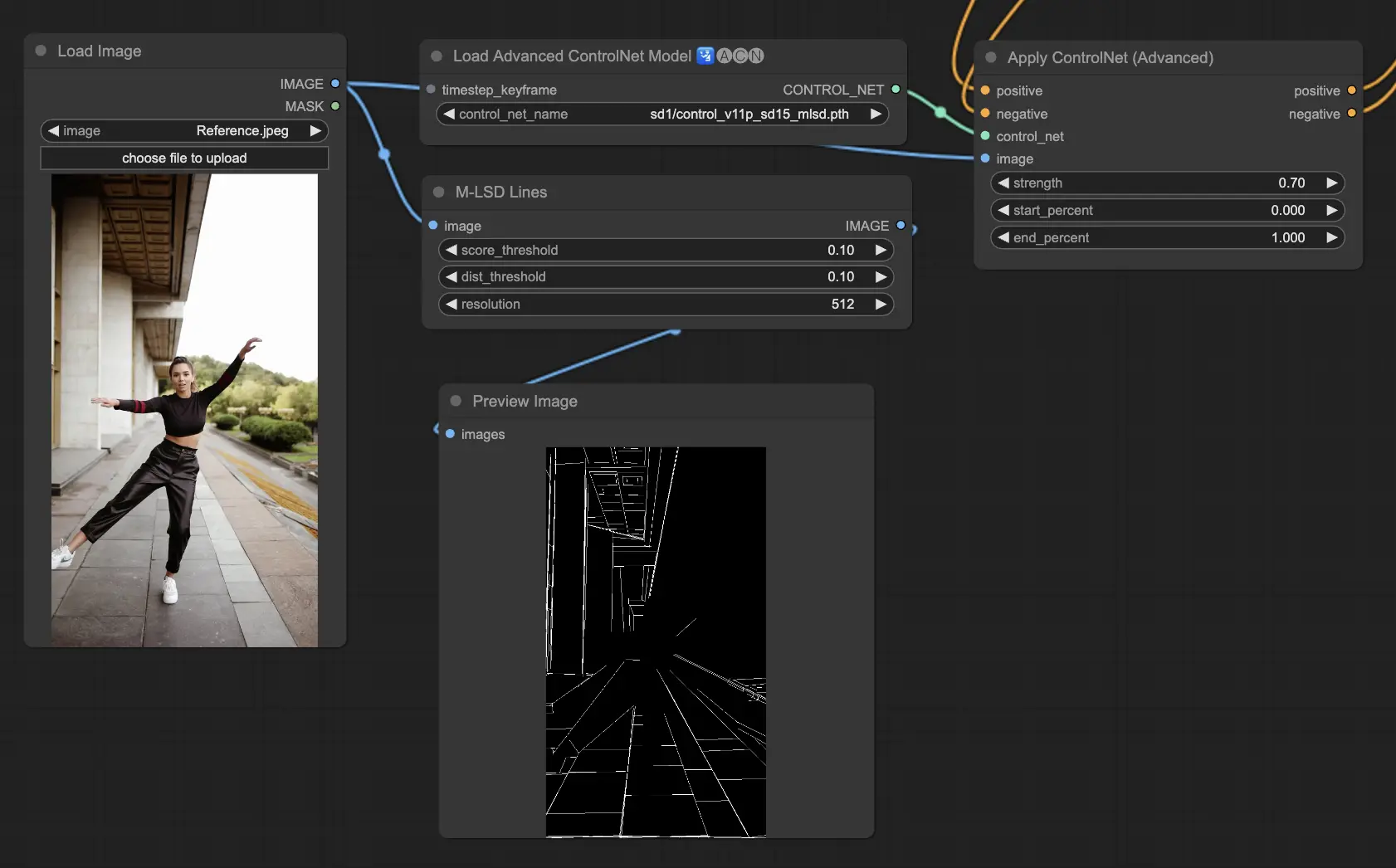
5.11. ComfyUI ControlNet Normalmaps
Normalmaps通过模拟视觉场景中表面的方向,而不是仅依赖颜色数据,来模拟复杂的光照和纹理效果。这对于3D建模和模拟任务至关重要。
- Normal Bae:这种方法通过利用法线不确定性方法生成法线贴图。它提供了一种创新的技术来描绘表面的方向,增强了基于场景的物理几何而不是传统的基于颜色的方法的光照效果模拟。
- Normal Midas:利用Midas模型生成的深度图,Normal Midas可以准确估计法线贴图。这种方法允许基于场景的深度信息对表面纹理和光照进行细微模拟,从而丰富3D模型的视觉复杂性。
预处理器:Normal BAE、Normal Midas
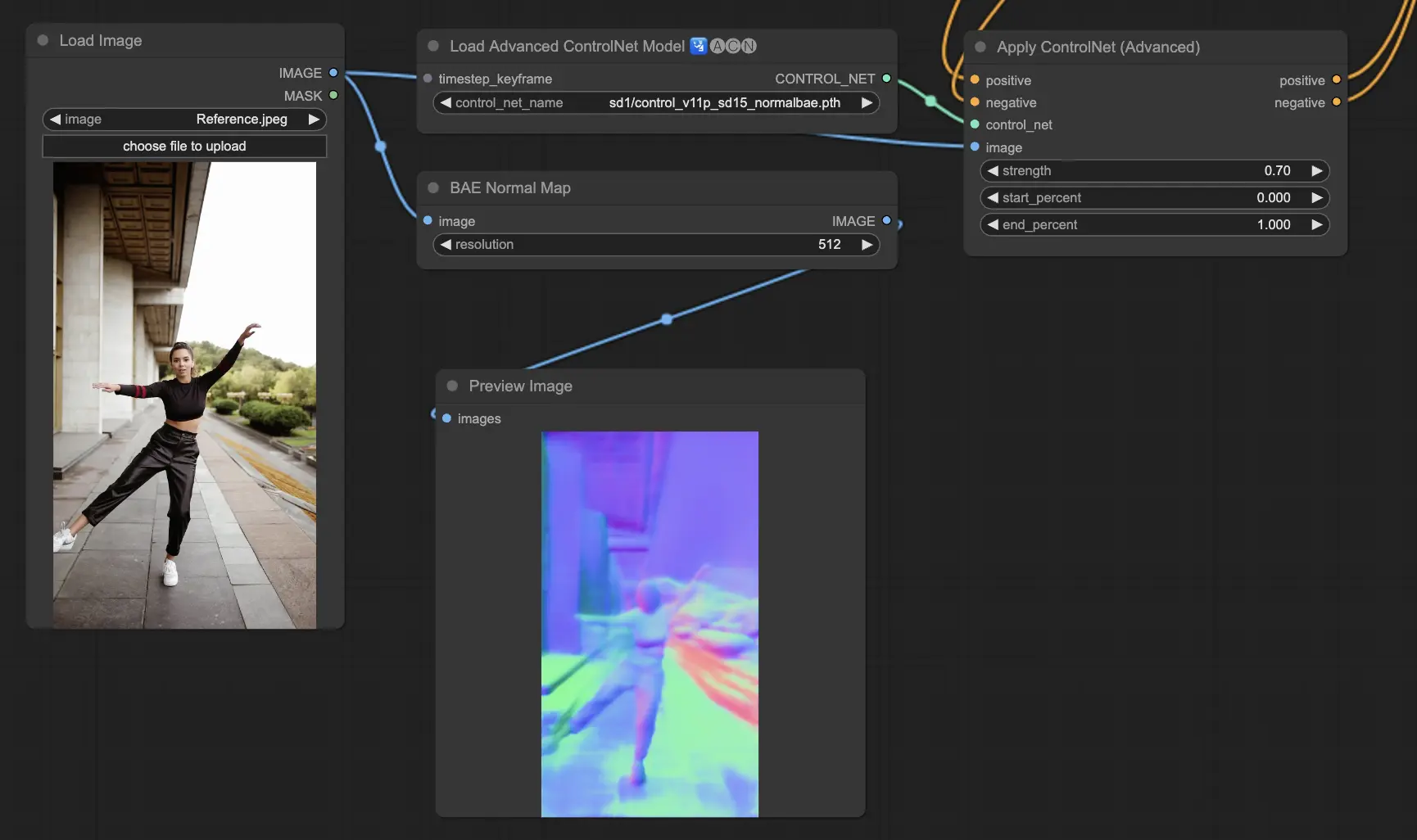
5.12. ComfyUI ControlNet Soft Edge
ControlNet Soft Edge旨在生成边缘更柔和的图像,侧重于细节控制和自然外观。它使用先进的神经网络技术进行精确的图像处理,提供更大的创作自由和无缝混合能力。
稳健性:SoftEdge_PIDI_safe > SoftEdge_HED_safe>> SoftEdge_PIDI > SoftEdge_HED
最大结果质量:SoftEdge_HED > SoftEdge_PIDI > SoftEdge_HED_safe > SoftEdge_PIDI_safe
考虑到这种权衡,我们建议默认使用SoftEdge_PIDI。在大多数情况下,它的效果非常好。
预处理器:SoftEdge_PIDI、SoftEdge_PIDI_safe、SoftEdge_HED、SoftEdge_HED_safe。
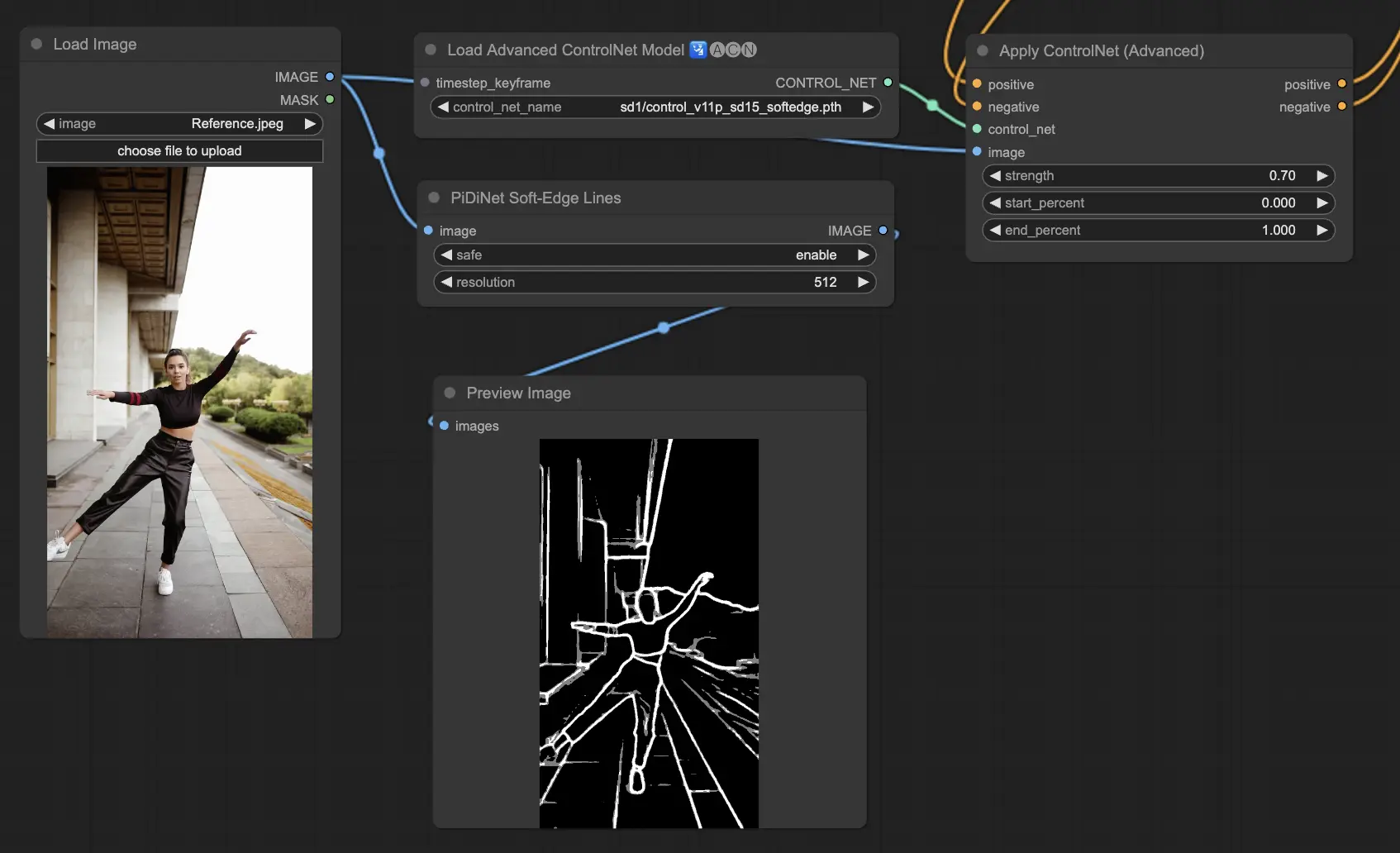
5.13. ComfyUI ControlNet IP2P (Instruct Pix2Pix)
ControlNet IP2P(Instruct Pix2Pix)模型在ControlNet框架内脱颖而出,成为一个独特的适应,专门利用Instruct Pix2Pix数据集进行图像转换。这个ControlNet变体的不同之处在于,在训练阶段平衡指令提示和描述提示。与官方的Instruct Pix2Pix不同,ControlNet IP2P采用这些提示类型的50/50混合,提高了其在生成预期结果方面的多功能性和有效性。
5.14. ComfyUI T2I Adapter
t2iadapter color:t2iadapter_color模型专门设计用于在使用文本到图像扩散模型时增强生成图像的色彩表现和准确性。通过专注于色彩适配,这个模型允许更准确和生动的色彩调色板,与文本提示中提供的描述紧密结合。它对于色彩保真度和特异性至关重要的项目特别有用,为生成的图像增添了新的现实主义和细节层次。
t2iadapter style:t2iadapter_style模型针对图像生成的风格化方面,使输出图像的艺术风格得以修改和控制。这个适配器允许用户引导文本到图像模型生成符合文本提示中描述的特定艺术风格或美学的图像。对于风格在图像中起关键作用的创意项目来说,它是一个宝贵的工具,提供了将传统艺术风格与现代AI能力无缝融合的方式。
5.15. 其他流行的ComfyUI ControlNet:QRCode Monster和IP-Adapter
对于这些部分,我们将专门撰写独立的文章进行全面介绍,考虑到我们希望分享的大量信息。
6. 如何使用多个ComfyUI ControlNet
ComfyUI中使用多个ControlNet涉及一个分层或链接ControlNet模型的过程,以通过对姿势、形状、风格和颜色等各个方面的更精确控制来细化图像生成。
因此,你可以通过应用一个ControlNet(例如OpenPose)并将其输出馈送到另一个ControlNet(例如Canny)来构建工作流。这种分层应用允许对图像进行详细定制,每个ControlNet应用其特定的转换或控制。这个过程允许对最终输出进行细化控制,整合由不同ControlNet引导的多个方面。
🌟🌟🌟 ComfyUI在线体验 - 立即体验ControlNet工作流 🌟🌟🌟
如果你有兴趣探索ControlNet工作流,请使用以下ComfyUI网页。它配备了所有基本的自定义节点和模型,无需手动设置即可实现无缝创作。立即获得实践经验,熟悉ControlNet的功能!