

IDM-VTON, short for "Improving Diffusion Models for Authentic Virtual Try-on in the Wild," is an innovative diffusion model that allows you to realistically try on garments virtually using just a few inputs. What sets IDM-VTON apart is its ability to preserve the unique details and identity of the garments while generating virtual try-on results that look incredibly authentic.
1. Understanding IDM-VTON#
At its core, IDM-VTON is a diffusion model that's been specifically engineered for virtual try-on. To use it, you simply need a representation of a person and a garment you want to try on. IDM-VTON then works its magic, rendering a result that looks like the person is actually wearing the garment. It achieves a level of garment fidelity and authenticity that surpasses previous diffusion-based virtual try-on methods.
2. The Inner Workings of IDM-VTON#
So, how does IDM-VTON pull off such realistic virtual try-on? The secret lies in its two main modules that work together to encode the semantics of the garment input:
- The first is an image prompt adapter, or IP-Adapter for short. This clever component extracts the high-level semantics of the garment - essentially, the key characteristics that define its appearance. It then fuses this information into the cross-attention layer of the main UNet diffusion model.
- The second module is a parallel UNet called GarmentNet. Its job is to encode the low-level features of the garment - the nitty-gritty details that make it unique. These features are then fused into the self-attention layer of the main UNet.
But that's not all! IDM-VTON also makes use of detailed textual prompts for both the garment and the person inputs. These prompts provide additional context that enhances the authenticity of the final virtual try-on result.
3. Putting IDM-VTON to Work in ComfyUI#
3.1 The Star of the Show: The IDM-VTON Node#
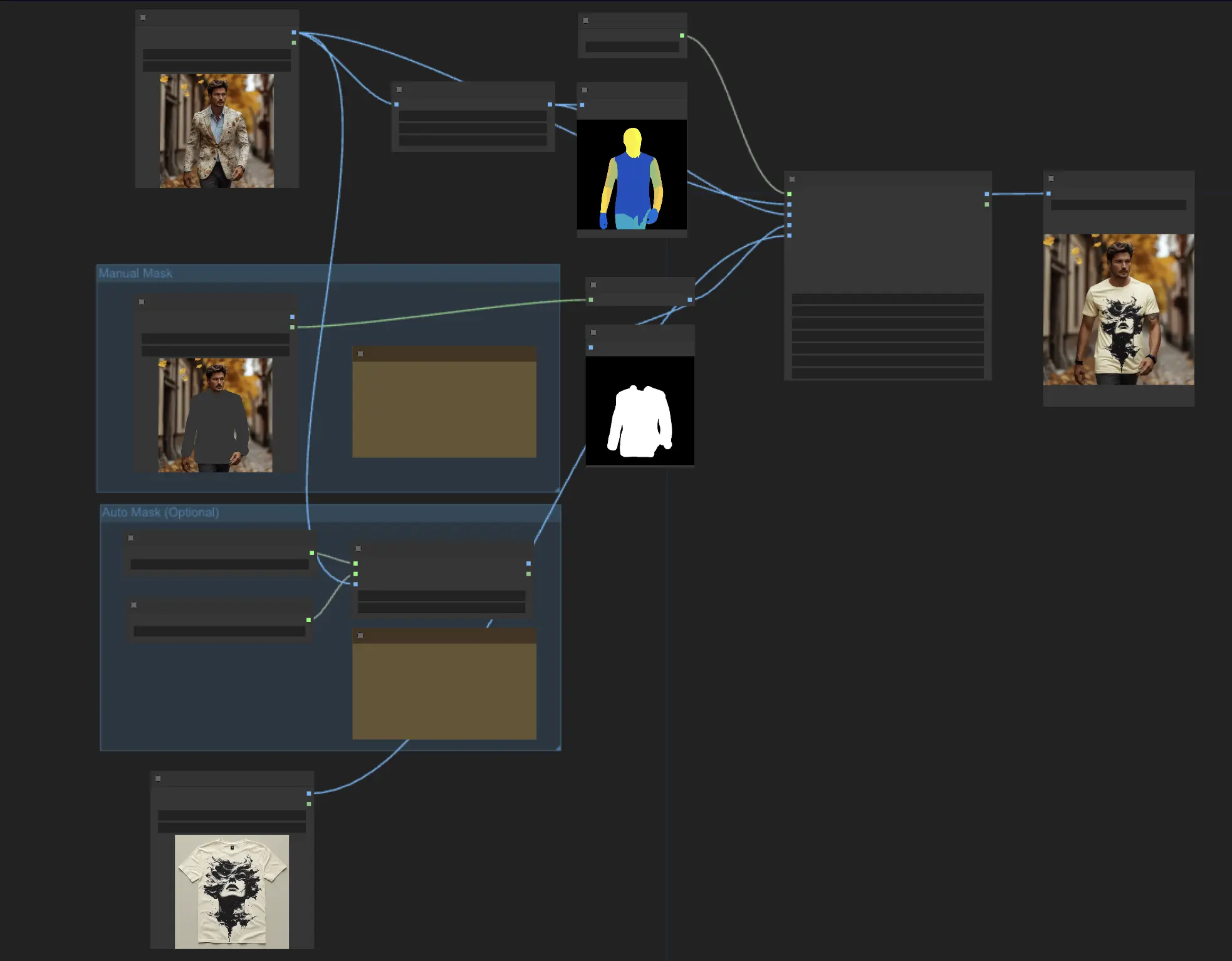
In ComfyUI, the "IDM-VTON" node is the powerhouse that runs the IDM-VTON diffusion model and generates the virtual try-on output.
For the IDM-VTON node to work its magic, it needs a few key inputs:
- Pipeline: This is the loaded IDM-VTON diffusion pipeline that powers the whole virtual try-on process.
- Human Input: An image of the person who will be virtually trying on the garment.
- Pose Input: A preprocessed DensePose representation of the human input, which helps IDM-VTON understand the person's pose and body shape.
- Mask Input: A binary mask that indicates which parts of the human input are clothing. This mask needs to be converted into an appropriate format.
- Garment Input: An image of the garment to be virtually tried on.
3.2 Getting Everything Ready#
To get the IDM-VTON node up and running, there are a few preparation steps:
- Loading the Human Image: A LoadImage node is used to load the image of the person. <img src="https://cdn.runcomfy.net/workflow_assets/1135/readme01.webp" alt="IDM-VTON" width="500" />
- Generating the Pose Image: The human image is passed through a DensePosePreprocessor node, which computes the DensePose representation that IDM-VTON needs. <img src="https://cdn.runcomfy.net/workflow_assets/1135/readme02.webp" alt="IDM-VTON" width="500" />
- Obtaining the Mask Image: There are two ways to get the clothing mask: <img src="https://cdn.runcomfy.net/workflow_assets/1135/readme03.webp" alt="IDM-VTON" width="500" />
a. Manual Masking (Recommended)
- Right-click on the loaded human image and choose "Open in Mask Editor."
- In the mask editor UI, manually mask the clothing regions.
b. Automatic Masking
- Use a GroundingDinoSAMSegment node to automatically segment the clothing.
- Prompt the node with a text description of the garment (like "t-shirt").
Whichever method you choose, the obtained mask needs to be converted to an image using a MaskToImage node, which is then connected to the "Mask Image" input of the IDM-VTON node.
- Loading the Garment Image: It is used to load the image of the garment.
For a deeper dive into the IDM-VTON model, don't miss the original paper, "Improving Diffusion Models for Authentic Virtual Try-on in the Wild". And if you're interested in using IDM-VTON in ComfyUI, be sure to check out the dedicated nodes here. Huge thanks to the researchers and developers behind these incredible resources.
