




Stability AI has unveiled Stable Diffusion 3.5 (SD3.5), an open-source multimodal generative AI model that includes several variants such as Stable Diffusion 3.5 (SD3.5) Large, Stable Diffusion 3.5 (SD3.5) Large Turbo, and Stable Diffusion 3.5 (SD3.5) Medium. These models are highly customizable, capable of running on consumer hardware. The SD3.5 Large and Large Turbo models are immediately available, while the Medium version will be released on October 29, 2024.
1. How Stable Diffusion 3.5 (SD3.5) Works#
At a technical level, Stable Diffusion 3.5 (SD3.5) takes a text prompt as input, encodes it into a latent space using transformer-based text encoders, and then decodes that latent representation into an output image using a diffusion-based decoder. The transformer text encoders, such as the CLIP (Contrastive Language-Image Pre-training) model, map the input prompt into a semantically meaningful compressed representation in the latent space. This latent code is then iteratively denoised by the diffusion decoder over multiple timesteps to generate the final image output. The diffusion process involves gradually removing noise from a initially noisy latent representation, conditioned on the text embedding, until a clean image emerges.
The different model sizes in Stable Diffusion 3.5 (SD3.5) (Large, Medium) refer to the number of trainable parameters - 8 billion for the Large model and 2.5 billion for Medium. More parameters generally allow the model to capture more knowledge and nuance from its training data. The Turbo models are distilled versions that sacrifice some quality for much faster inference speeds. Distillation involves training a smaller "student" model to mimic the outputs of a larger "teacher" model, aiming to retain most of the capability in a more efficient architecture.
2. Strengths of the Stable Diffusion 3.5 (SD3.5) Models#
2.1. Customizability#
The Stable Diffusion 3.5 (SD3.5) models are designed to be easily fine-tuned and built upon for specific applications. Query-Key Normalization was integrated into the transformer blocks to stabilize training and simplify further development. This technique normalizes the attention scores in the transformer layers, which can make the model more robust and easier to adapt to new datasets via transfer learning.
2.2. Diversity of Outputs#
Stable Diffusion 3.5 (SD3.5) aims to generate images representative of the world's diversity without the need for extensive prompting. It can depict people with varying skin tones, features, and aesthetics. This is likely due to the model being trained on a large and diverse dataset of images from across the internet.
2.3. Broad Range of Styles#
The Stable Diffusion 3.5 (SD3.5) models are capable of generating images in a wide variety of styles including 3D renders, photorealism, paintings, line art, anime, and more. This versatility makes them suitable for many use cases. The style diversity emerges from the diffusion model's ability to capture many different visual patterns and aesthetics in its latent space.
2.4. Strong Prompt Adherence#
Especially for the Stable Diffusion 3.5 (SD3.5) Large model, SD3.5 does well at generating images that align with the semantic meaning of the input text prompts. It ranks highly compared to other models on prompt matching metrics. This ability to accurately translate text into images is powered by the transformer text encoder's language understanding capabilities.
3. Limitations and Drawbacks of the Stable Diffusion 3.5 (SD3.5) Models#
3.1. Struggles with Anatomy and Object Interactions#
Like most text-to-image models, Stable Diffusion 3.5 (SD3.5) still has difficulty rendering realistic human anatomy, especially hands, feet, and faces in complex poses. Interactions between objects and hands are often distorted. This is likely due to the challenge of learning all the nuances of 3D spatial relationships and physics from 2D images alone.
3.2. Limited Resolution#
The Stable Diffusion 3.5 (SD3.5) Large model is ideal for 1 megapixel images (1024x1024), while the Medium tops out around 2 megapixels. Generating coherent images at higher resolutions is challenging for SD3.5. This limitation stems from the computational and memory constraints of the diffusion architecture.
3.3. Occasional Glitches and Hallucinations#
Due to the Stable Diffusion 3.5 (SD3.5) models allowing for broad diversity of outputs from the same prompt with different random seeds, there can be some unpredictability. Prompts lacking specificity may lead to glitchy or unexpected elements appearing. This is an inherent property of the diffusion sampling process, which involves randomness.
3.4. Falls Short of Absolute Cutting-Edge#
According to some early tests, in terms of image quality and coherence, Stable Diffusion 3.5 (SD3.5) does not currently match the performance of state-of-the-art text-to-image models like Midjourney. And early comparisons between Stable Diffusion 3.5 (SD3.5) and FLUX.1 reveal that each model excels in different areas. While FLUX.1 seems to have an advantage in producing photorealistic images, SD3.5 Large has greater proficiency in generating anime-style artwork without requiring additional fine-tuning or modifications.
4. Stable Diffusion 3.5 in ComfyUI#
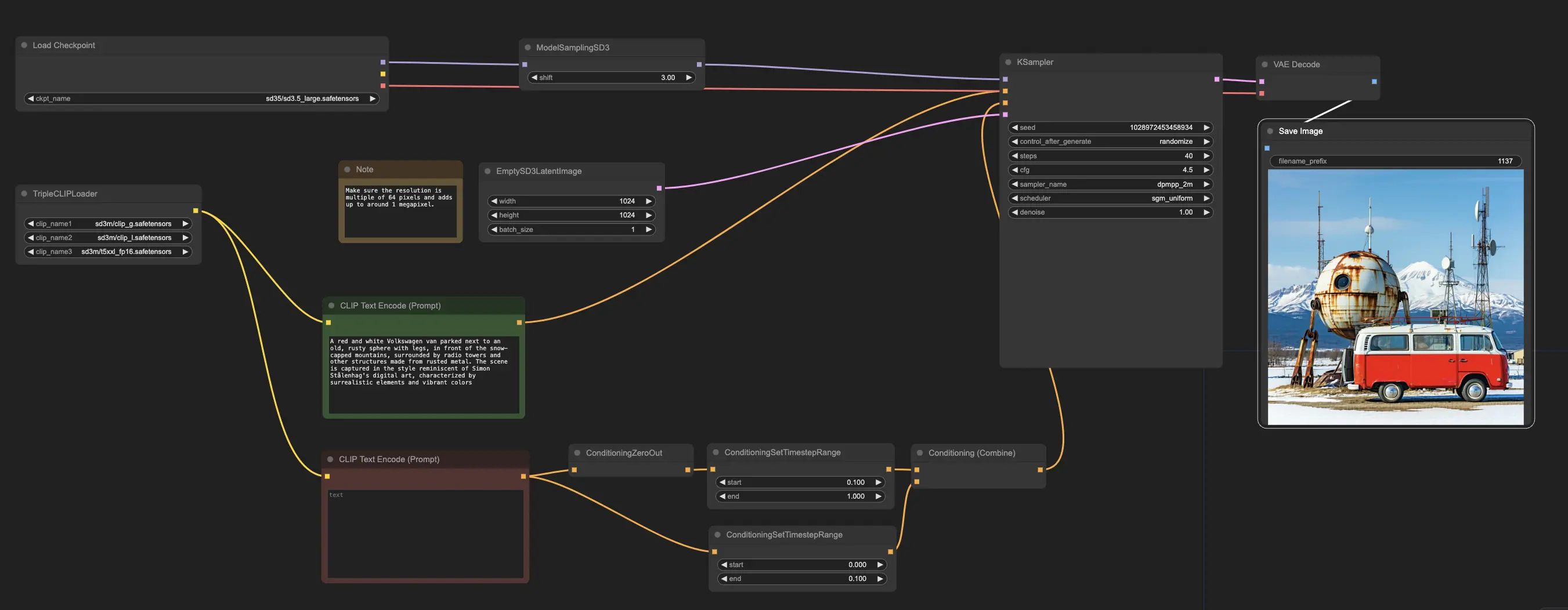
At RunComfy, we've made it easy for you to start using the Stable Diffusion 3.5 (SD3.5) models by preloading them for your convenience. You can jump right in and run inferences using the example workflow
The example workflow begins with the CheckpointLoaderSimple node, which loads the pre-trained Stable Diffusion 3.5 Large model. And to help translate your text prompts into a format the model can understand, the TripleCLIPLoader node is used to load the corresponding encoders. These encoders are crucial in guiding the image generation process based on the text you provide.
The EmptySD3LatentImage node then creates a blank canvas with the specified dimensions, typically 1024x1024 pixels, which serves as the starting point for the model to generate the image. The CLIPTextEncode nodes process the text prompts you provide, using the loaded encoders to create a set of instructions for the model to follow.
Before these instructions are sent to the model, they undergo further refinement through the ConditioningCombine, ConditioningZeroOut, and ConditioningSetTimestepRange nodes. These nodes remove the influence of any negative prompts, specify when the prompts should be applied during the generation process, and combine the instructions into a single, cohesive set.
Finally, you can fine-tune the image generation process using the ModelSamplingSD3 node, which allows you to adjust various settings such as the sampling mode, number of steps, and model output scale. Finally, the KSampler node gives you control over the number of steps, the strength of the instructions' influence (CFG scale), and the specific algorithm used for generation, enabling you to achieve the desired results.
