EchoMimic | Audiogesteuerte Portraitanimationen
EchoMimic ist ein Tool, das es Ihnen ermöglicht, realistische sprechende Köpfe und Körpergesten zu erstellen, die nahtlos mit dem bereitgestellten Audio synchronisiert sind. Durch den Einsatz fortschrittlicher KI-Techniken analysiert EchoMimic das Audioeingangssignal und erzeugt lebensechte Gesichtsausdrücke, Lippenbewegungen und Körpersprache, die perfekt zu den gesprochenen Worten und Emotionen passen. Mit EchoMimic können Sie Ihre Charaktere zum Leben erwecken und animierte Inhalte erstellen, die Ihr Publikum fesseln.ComfyUI EchoMimic Arbeitsablauf
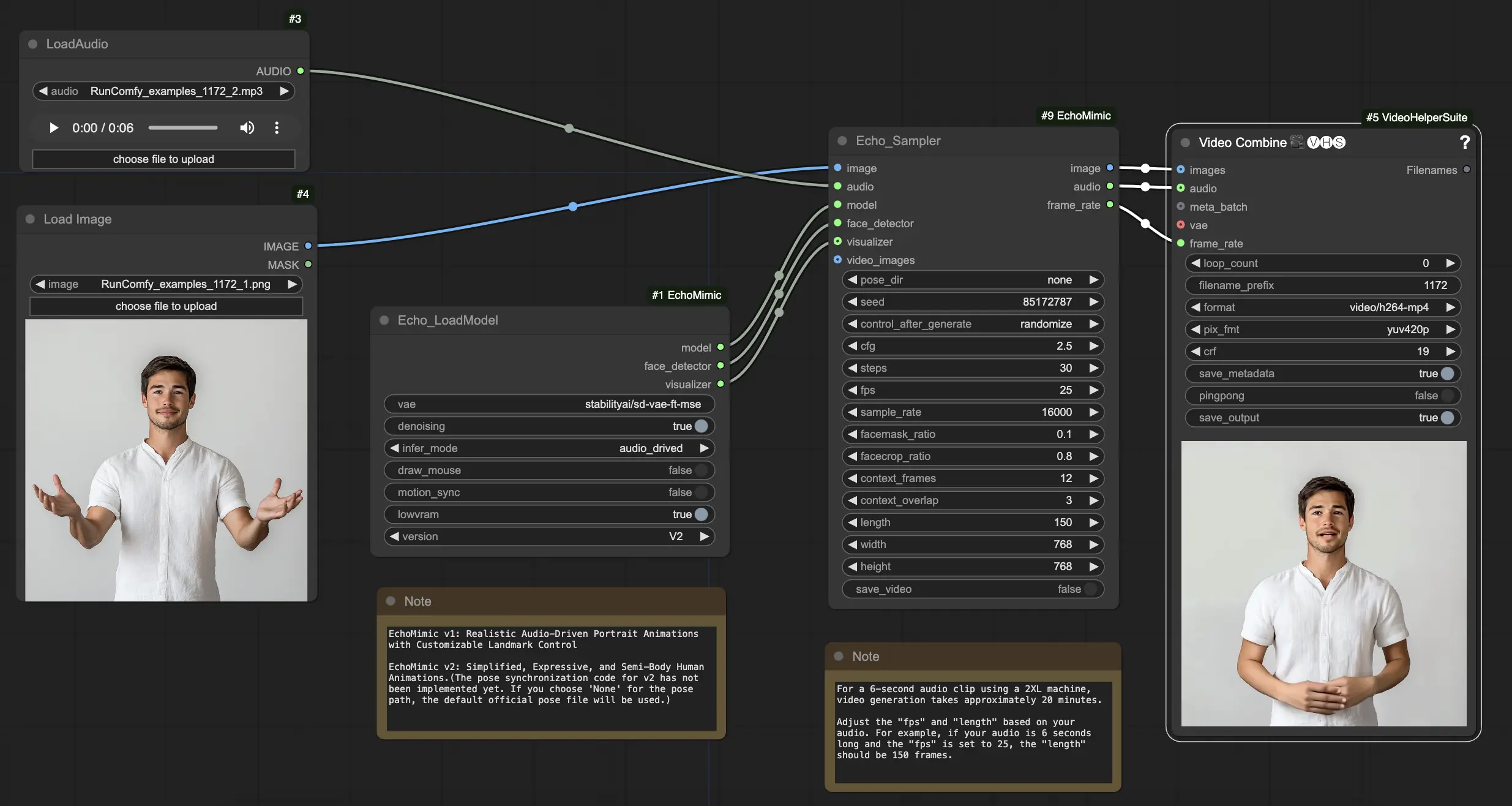
- Voll funktionsfähige Workflows
- Keine fehlenden Nodes oder Modelle
- Keine manuelle Einrichtung erforderlich
- Beeindruckende Visualisierungen
ComfyUI EchoMimic Beispiele
ComfyUI EchoMimic Beschreibung
EchoMimic ist ein Tool zur Erzeugung lebensechter, audiogesteuerter Portraitanimationen. Es nutzt Deep-Learning-Techniken, um das Eingangs-Audio zu analysieren und entsprechende Gesichtsausdrücke, Lippenbewegungen und Kopfgesten zu erzeugen, die eng mit dem emotionalen und phonetischen Inhalt der Sprache übereinstimmen.
EchoMimic V2 wurde von einem Forscherteam der Terminal Technology Abteilung bei Alipay, Ant Group, darunter Rang Meng, Xingyu Zhang, Yuming Li und Chenguang Ma, entwickelt. Für detaillierte Informationen besuchen Sie bitte /. Der ComfyUI_EchoMimic-Knoten wurde von / entwickelt. Alle Anerkennung gebührt ihrem bedeutenden Beitrag.
EchoMimic V1 und V2
- EchoMimic V1: Realistische audiogesteuerte Portraitanimationen mit anpassbarer Landmarkenkontrolle
- EchoMimic V2: Vereinfachte, ausdrucksstarke und halb-körperliche Mensch-Animationen
Der Hauptunterschied besteht darin, dass EchoMimic V2 darauf abzielt, auffällige Halb-Körper-Mensch-Animationen zu erreichen, während unnötige Steuerungsbedingungen im Vergleich zu EchoMimic V1 vereinfacht werden. EchoMimic V2 verwendet eine neuartige Audio-Pose-Dynamik-Harmonisierung, um Gesichtsausdrücke und Körpergesten zu verbessern.
Stärken und Schwächen von EchoMimic V2
Stärken:
- EchoMimic V2 erzeugt hochrealistische und ausdrucksstarke Portraitanimationen, die durch Audio gesteuert werden
- EchoMimic V2 erweitert die Animation auf den Oberkörper, nicht nur auf den Kopfbereich
- EchoMimic V2 reduziert die Bedingungskomplexität und erhält gleichzeitig die Animationsqualität im Vergleich zu EchoMimic V1
- EchoMimic V2 integriert nahtlos Headshot-Daten zur Verbesserung von Gesichtsausdrücken
Schwächen:
- EchoMimic V2 erfordert eine Audioquelle, die dem Portrait für beste Ergebnisse entspricht
- EchoMimic V2 fehlt derzeit der Code zur Posesynchronisation, es wird eine Standard-Pose-Datei verwendet
- Das Erzeugen längerer hochwertiger Animationen mit EchoMimic V2 kann rechnerisch intensiv sein
- EchoMimic V2 funktioniert am besten mit zugeschnittenen Portraitbildern anstelle von Ganzkörperaufnahmen
Wie man den ComfyUI EchoMimic Workflow verwendet
Im "Echo_LoadModel"-Knoten haben Sie die Option, zwischen EchoMimic v1 und EchoMimic v2 zu wählen:
- EchoMimic v1: Diese Version konzentriert sich auf die Erzeugung realistischer audiogesteuerter Portraitanimationen mit der Möglichkeit, Landmarkenkontrollen anzupassen. Sie eignet sich gut zur Erstellung lebensechter Gesichtsanimationen, die eng mit dem Eingangs-Audio übereinstimmen.
- EchoMimic v2: Diese Version zielt darauf ab, den Animationsprozess zu vereinfachen und gleichzeitig ausdrucksstarke und halb-körperliche Mensch-Animationen zu liefern. Sie erweitert die Animation über den Gesichtbereich hinaus, um Bewegungen des Oberkörpers einzuschließen. Bitte beachten Sie jedoch, dass die Posesynchronisationsfunktion für v2 im aktuellen ComfyUI-Workflow noch nicht implementiert ist. Wenn Sie 'None' für den Pose-Pfad auswählen, wird stattdessen die Standard-Offizielle-Pose-Datei verwendet.
Hier ist eine Schritt-für-Schritt-Anleitung zur Verwendung des bereitgestellten ComfyUI-Workflows:
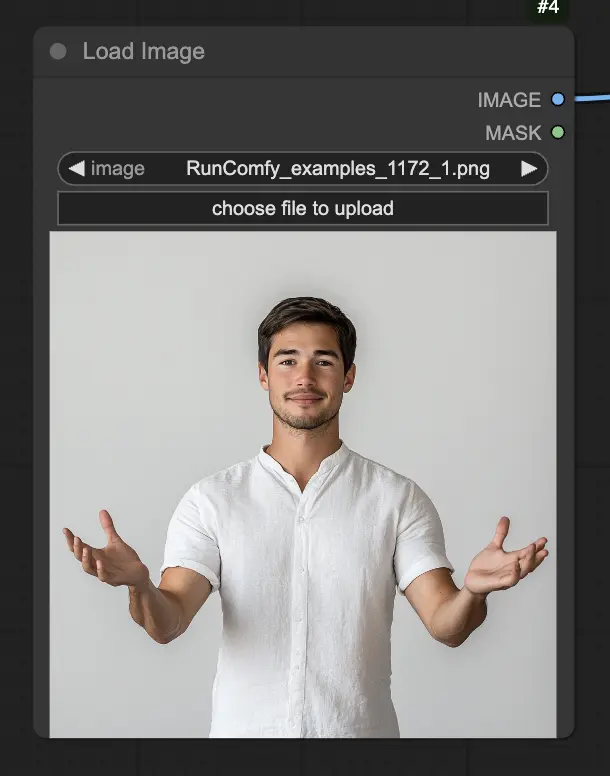
Schritt 1. Laden Sie Ihr Portraitbild über den LoadImage-Knoten. Dies sollte eine Nahaufnahme des Kopfes und der Schultern des Subjekts sein.
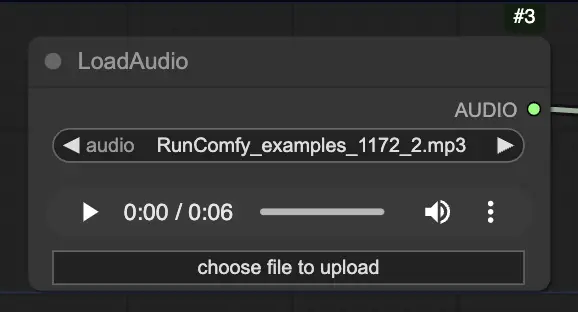
Schritt 2. Laden Sie Ihre Audiodatei über den LoadAudio-Knoten. Die Sprache im Audio sollte der Identität des Portraitsubjekts entsprechen.
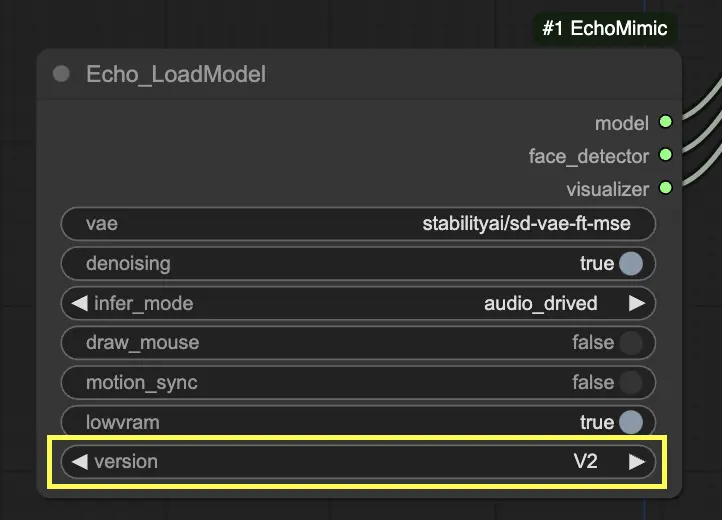
Schritt 3. Verwenden Sie den Echo_LoadModel-Knoten, um das EchoMimic-Modell zu laden. Wichtige Einstellungen:
- Wählen Sie die Version (V1 oder V2).
- Wählen Sie den Inferenzmodus, z.B. audiogesteuerter Modus.
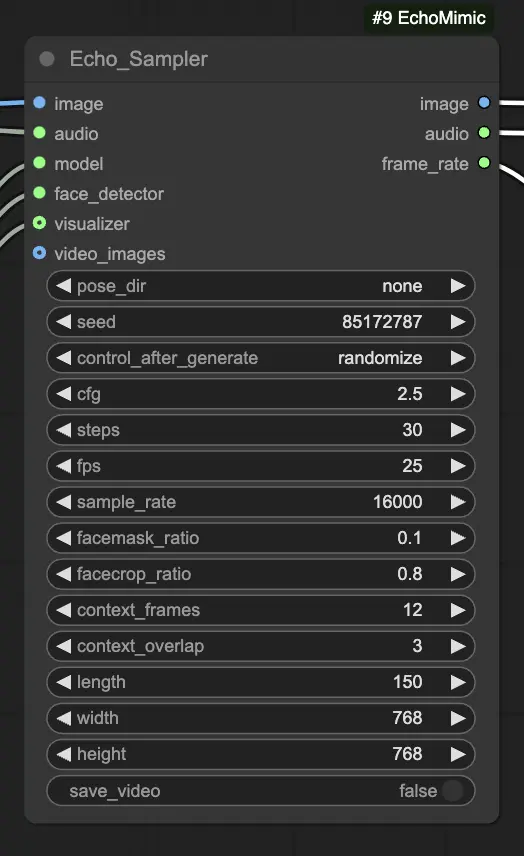
Schritt 4. Verbinden Sie das Bild, das Audio und das geladene Modell mit dem Echo_Sampler-Knoten. Wichtige Einstellungen:
- pose_dir: Der Verzeichnispfad für die Pose-Sequenz-Dateien, die in pose-gesteuerten Animationsmodi verwendet werden. Wenn "none" gesetzt ist, wird keine Pose-Sequenz verwendet.
- seed: Der Zufallswert zur Erzeugung konsistenter Ergebnisse über mehrere Durchläufe. Es sollte eine Ganzzahl zwischen 0 und MAX_SEED sein.
- cfg: Die Skala der klassifizierungsfreien Führung, die die Stärke der Audio-Konditionierung steuert. Höhere Werte führen zu ausgeprägteren audiogesteuerten Bewegungen. Der Standardwert ist 2,5 und kann von 0,0 bis 10,0 reichen.
- steps: Die Anzahl der Diffusionsschritte zur Erzeugung jedes Frames. Höhere Werte erzeugen glattere Animationen, benötigen aber länger zur Erzeugung. Der Standard ist 30 und kann von 1 bis 100 reichen.
- fps: Die Bildrate des Ausgabevideos in Bildern pro Sekunde. Der Standard ist 25 und kann von 5 bis 100 reichen.
- sample_rate: Die Abtastrate des Eingangs-Audios in Hz. Der Standard ist 16000 und kann von 8000 bis 48000 in Schritten von 1000 reichen.
- facemask_ratio: Das Verhältnis der Gesichtsmaske zur Gesamtbildfläche. Es steuert die Größe des Bereichs um das Gesicht, der animiert wird. Der Standard ist 0,1 und kann von 0,0 bis 1,0 reichen.
- facecrop_ratio: Das Verhältnis der Gesichtsausschnittsfläche zur Gesamtbildfläche. Es bestimmt, wie viel des Bildes dem Gesichtsbereich gewidmet wird. Der Standard ist 0,8 und kann von 0,0 bis 1,0 reichen.
- context_frames: Die Anzahl der vergangenen und zukünftigen Frames, die als Kontext für die Erzeugung jedes Frames verwendet werden. Der Standard ist 12 und kann von 0 bis 50 reichen.
- context_overlap: Die Anzahl der überlappenden Frames zwischen angrenzenden Kontextfenstern. Der Standard ist 3 und kann von 0 bis 10 reichen.
- length: Die Länge des Ausgabevideos in Frames. Sie sollte auf der Dauer Ihres Eingangs-Audios und der fps-Einstellung basieren. Zum Beispiel, wenn Ihr Audio 6 Sekunden lang ist und die fps auf 25 eingestellt ist, sollte die Länge 150 Frames betragen. Die Länge kann von 50 bis 5000 Frames reichen.
- width: Die Breite der Ausgabevideo-Frames in Pixeln. Der Standard ist 512 und kann in Schritten von 64 von 128 bis 1024 reichen.
- height: Die Höhe der Ausgabevideo-Frames in Pixeln. Der Standard ist 512 und kann in Schritten von 64 von 128 bis 1024 reichen.
Bitte beachten Sie, dass die Videogenerierung einige Zeit in Anspruch nehmen kann. Zum Beispiel dauert es etwa 20 Minuten, um mit einer 2XL-Maschine auf RunComfy ein Video aus einem 6-sekündigen Audioclip zu erstellen.

