Hunyuan Video | Text zu Video
Hunyuan Video ist ein Open-Source-Video-Grundlagenmodell, das von Tencent entwickelt wurde. Es bietet eine Videoerzeugungsleistung, die mit führenden Closed-Source-Modellen vergleichbar ist, wenn nicht sogar besser. Durch den Einsatz fortschrittlicher Techniken wie Datenkuratierung, gemeinsames Bild-Video-Training und eine optimierte Infrastruktur ermöglicht Hunyuan Video eine qualitativ hochwertige, großflächige Videoerzeugung.ComfyUI Hunyuan Video Arbeitsablauf
- Voll funktionsfähige Workflows
- Keine fehlenden Nodes oder Modelle
- Keine manuelle Einrichtung erforderlich
- Beeindruckende Visualisierungen
ComfyUI Hunyuan Video Beispiele
ComfyUI Hunyuan Video Beschreibung
ist ein innovatives Open-Source-Video-Grundlagenmodell, das eine Leistung in der Videoerzeugung bietet, die mit, wenn nicht sogar besser als die der besten Closed-Source-Modelle vergleichbar ist, entwickelt von Tencent, einem führenden Technologieunternehmen. Hunyuan Video nutzt modernste Technologien für das Modelllernen, wie Datenkuratierung, gemeinsames Bild-Video-Modelltraining und eine effiziente Infrastruktur für großflächiges Modelltraining und Inferenz. Hunyuan Video verfügt über das größte Open-Source-Video-Generativmodell mit über 13 Milliarden Parametern.
Zu den wichtigsten Merkmalen von Hunyuan Video gehören
- Hunyuan Video bietet eine einheitliche Architektur zur Erzeugung von sowohl Bildern als auch Videos. Es verwendet ein spezielles Transformer-Modell-Design namens "Dual-stream to Single-stream". Das bedeutet, dass das Modell die Video- und Textinformationen zunächst separat verarbeitet und sie dann kombiniert, um das endgültige Ergebnis zu erstellen. Dies hilft dem Modell, die Beziehung zwischen den visuellen Elementen und der Textbeschreibung besser zu verstehen.
- Der Textencoder in Hunyuan Video basiert auf einem Multimodalen Großen Sprachmodell (MLLM). Im Vergleich zu anderen beliebten Textencodern wie CLIP und T5-XXL ist MLLM besser darin, den Text mit den Bildern abzugleichen. Es kann auch detailliertere Beschreibungen und Begründungen über den Inhalt liefern. Dies hilft Hunyuan Video, Videos zu erzeugen, die genauer mit dem eingegebenen Text übereinstimmen.
- Um effizient hochauflösende Videos und Videos mit hoher Bildfrequenz zu verarbeiten, verwendet Hunyuan Video einen 3D-Variational Autoencoder (VAE) mit CausalConv3D. Diese Komponente komprimiert die Videos und Bilder in eine kleinere Darstellung, den sogenannten latenten Raum. Indem es in diesem komprimierten Raum arbeitet, kann Hunyuan Video Videos in ihrer ursprünglichen Auflösung und Bildfrequenz trainieren und erzeugen, ohne zu viele Rechenressourcen zu verbrauchen.
- Hunyuan Video enthält ein Modell zur Neuschreibung von Eingaben, das den eingegebenen Text des Benutzers automatisch an die Vorlieben des Modells anpassen kann. Es gibt zwei Modi: Normal und Master. Der Normal-Modus konzentriert sich darauf, das Verständnis des Modells für die Anweisungen des Benutzers zu verbessern, während der Master-Modus darauf abzielt, Videos mit höherer visueller Qualität zu erstellen. Der Master-Modus kann jedoch manchmal bestimmte Details im Text zugunsten einer besseren Videoqualität übersehen.
Verwenden Sie Hunyuan Video in ComfyUI
Diese Knoten und zugehörige Workflows wurden von Kijai entwickelt. Wir geben Kijai alle gebührende Anerkennung für diese innovative Arbeit. Auf der RunComfy-Plattform präsentieren wir einfach seine Beiträge an die Gemeinschaft.
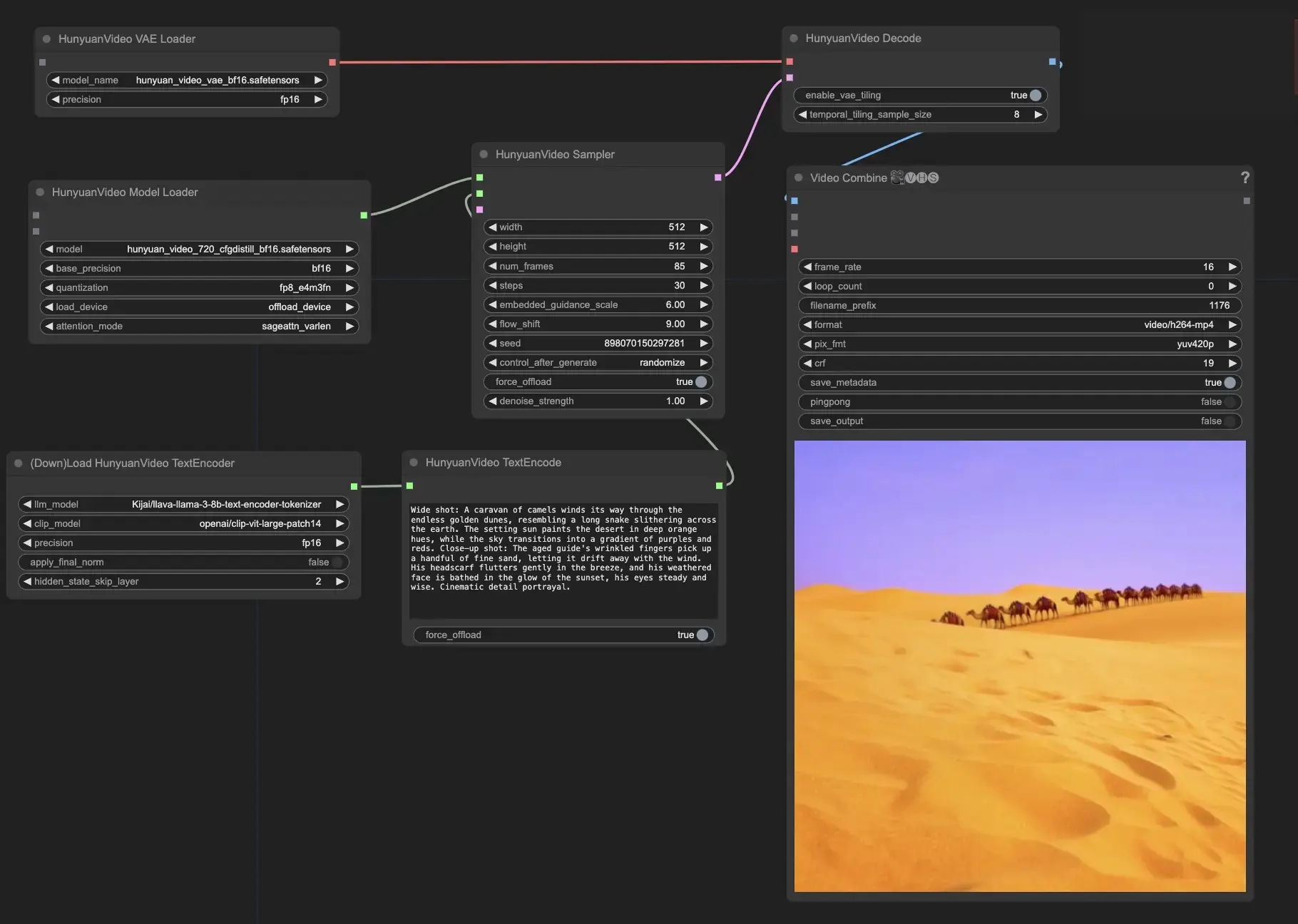
- Geben Sie Ihre Texteingabe ein: Im HunyuanVideoTextEncode-Knoten geben Sie Ihre gewünschte Texteingabe im Feld "prompt" ein. finden Sie einige Beispiele für Eingabeaufforderungen zu Ihrer Orientierung.
- Konfigurieren Sie die Videoausgabe-Einstellungen im HunyuanVideoSampler-Knoten:
- Stellen Sie die "width" und "height" auf Ihre bevorzugte Auflösung ein
- Setzen Sie die "num_frames" auf die gewünschte Videolänge in Frames
- "steps" kontrolliert die Anzahl der Entstörungs-/Abtastschritte (Standard: 30)
- "embedded_guidance_scale" bestimmt die Stärke der Eingabeaufforderung (Standard: 6.0)
- "flow_shift" beeinflusst die Videolänge (größere Werte führen zu kürzeren Videos, Standard: 9.0)
