LTX Video | Bild+Text zu Video
Lightricks hat LTX Video entwickelt, ein Videogenerierungsmodell, das diffusionsbasierte Techniken nutzt. Das Modell kann Videos aus Texteingaben oder einer Kombination aus Bild- und Texteingaben generieren. LTX Video gibt Videos in einer Auflösung von 768x512 und einer Bildrate von 24 FPS aus. Das LTX-Modell wurde mit einem vielfältigen Datensatz trainiert, um abwechslungsreiche Videoinhalte zu erzeugen. Entdecken Sie die Techniken hinter dem LTX-Modell und verwenden Sie es in ComfyUI.ComfyUI LTX Video Arbeitsablauf
- Voll funktionsfähige Workflows
- Keine fehlenden Nodes oder Modelle
- Keine manuelle Einrichtung erforderlich
- Beeindruckende Visualisierungen
ComfyUI LTX Video Beispiele
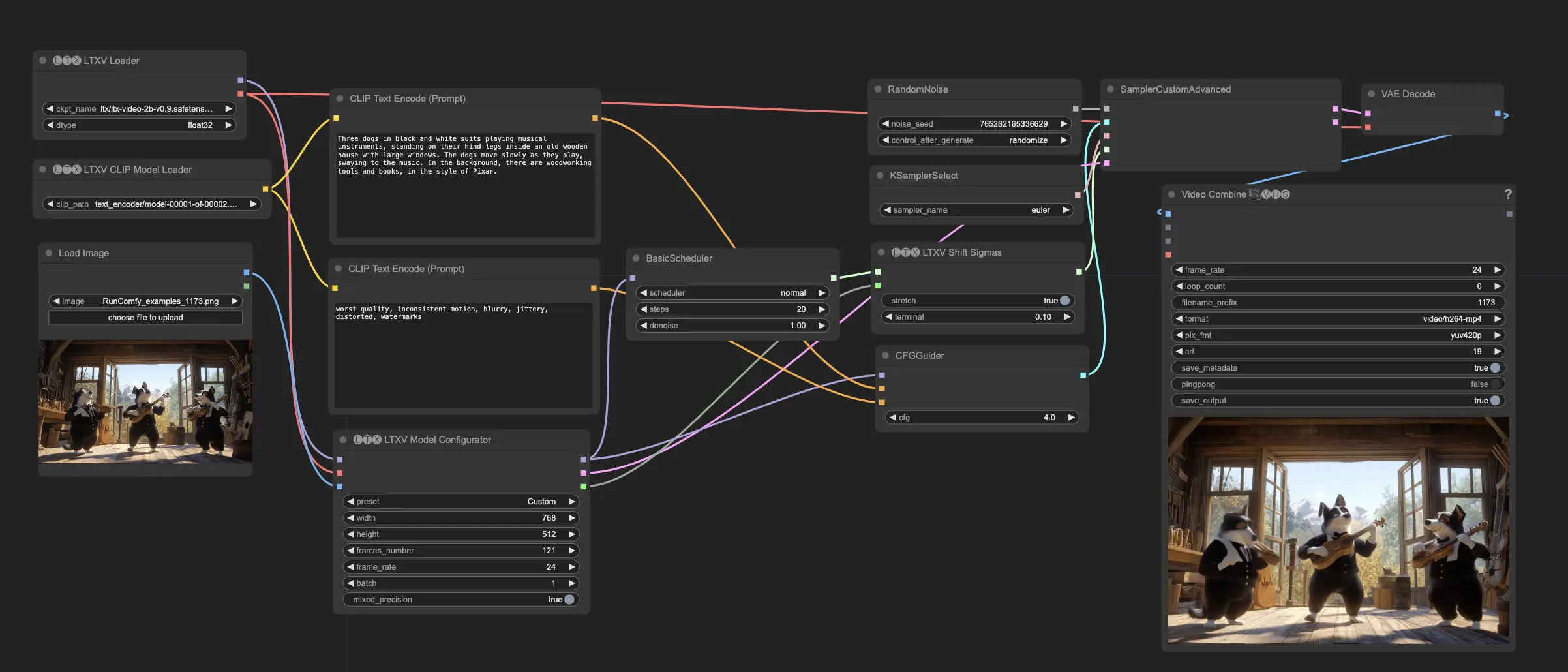
ComfyUI LTX Video Beschreibung
LTX Video ist ein diffusionsbasiertes Videogenerierungsmodell, das von Lightricks entwickelt wurde. Es ist in der Lage, Videos entweder aus Texteingaben (Text-zu-Video) oder einer Kombination aus Bild- und Texteingaben (Bild+Text-zu-Video) zu generieren. LTX Video produziert 24 Bilder pro Sekunde (FPS) Videos in einer Auflösung von 768x512 schneller, als sie angesehen werden können. Das Modell wurde mit einem groß angelegten Datensatz mit vielfältigen Videos trainiert, was es ihm ermöglicht, realistische und abwechslungsreiche Videoinhalte in hoher Auflösung zu generieren.
LTX Video Model und ComfyUI-LTXVideo Nodes wurden von Lightricks entwickelt. Alle Anerkennung gebührt ihrer Arbeit bei der Erstellung von LTX Video. Für weitere Informationen über LTX Video und die Projekte von Lightricks besuchen Sie bitte ihr GitHub-Repository unter https://github.com/Lightricks/LTX-Video oder ihre Website unter https://www.lightricks.com/ltxv.
Techniken hinter dem LTX-Modell
LTX Video nutzt einen diffusionsbasierten Ansatz zur Videogenerierung. Diffusionsmodelle arbeiten, indem sie ein verrauschtes Eingangssignal über mehrere Zeitschritte hinweg schrittweise entrauschen, um das endgültige Ergebnis zu erzeugen. Im Fall von LTX Video nimmt das Modell eine verrauschte latente Darstellung als Eingabe und entrauscht diese iterativ, um eine Sequenz von Videobildern zu erzeugen. Der Entrauschungsprozess wird durch die bereitgestellten Text- oder Bild+Text-Eingaben geleitet, die den Inhalt und Stil des generierten Videos steuern.
Die wichtigsten Techniken, die von LTX Video verwendet werden, umfassen:
- Diffusionsbasierte Videogenerierung: Durch den Einsatz von Diffusionsmodellen kann LTX Video qualitativ hochwertige Videos mit realistischen Bewegungen und Konsistenz über die Frames hinweg erzeugen.
- Text-zu-Video-Synthese: LTX Video kann Videos ausschließlich basierend auf textuellen Beschreibungen generieren, was es den Nutzern ermöglicht, benutzerdefinierte Videos von Grund auf mithilfe natürlicher Spracheingaben zu erstellen.
- Bild+Text-zu-Video-Synthese: LTX Video unterstützt auch die Generierung von Videos durch die Kombination eines Anfangsbildes mit einer Texteingabe. Dies ermöglicht es den Nutzern, einen Ausgangspunkt für das Video zu liefern und dessen Inhalt und Stil mit Text zu leiten.
Verwendung des LTX Video Workflows in ComfyUI
- Vorbereitung der Eingabe:
- Der Standard-Workflow ist die Bild + Text-zu-Video-Generierung. Geben Sie ein Anfangsbild zusammen mit einer Texteingabe an. Das Bild dient als Ausgangspunkt, und das Modell wird ein Video basierend auf dem Bild und dem begleitenden Text generieren. Beachten Sie, dass dieses Modell lange, beschreibende Eingaben erfordert; wenn die Eingabe zu kurz ist, leidet die Qualität erheblich.
- Konfiguration der Modellparameter:
- Stellen Sie die gewünschte Auflösung und die Anzahl der Frames für den generierten Inhalt ein. Die Auflösung sollte durch 32 teilbar sein, und die Anzahl der Frames sollte durch 8 + 1 teilbar sein (z.B. 257 Frames). LTX funktioniert am besten mit Auflösungen unter 720x1280 Pixel und weniger als 257 Frames.
- Passen Sie andere Parameter wie die Diffusionsschritte, den Rauschplan und die Führungsskala nach Ihren Anforderungen an. Diese Parameter steuern die Qualität und Vielfalt des generierten Outputs.
- Inhalt generieren:
- Der Output wird die angegebene Auflösung und Anzahl von Frames haben und mit der bereitgestellten Eingabe übereinstimmen.
Einschränkungen des LTX-Modells
- LTX Video ist nicht dazu gedacht oder in der Lage, faktische Informationen bereitzustellen.
- Als statistisches Modell könnte LTX Video vorhandene gesellschaftliche Vorurteile, die in den Trainingsdaten vorhanden sind, verstärken.
- Die generierten Videos stimmen möglicherweise nicht perfekt mit den bereitgestellten Eingaben überein.
- Die Qualität der Befolgung von Eingaben hängt stark vom verwendeten Eingabestil ab.
Lizenz
Bitte verwenden Sie das Modell für Zwecke, die unter der erlaubt sind.

