
Ce guide Unsampling, écrit par Inner-Reflections, contribue grandement à explorer la méthode Unsampling pour atteindre un transfert de style vidéo dramatiquement cohérent.
1. Introduction : Contrôle du Bruit Latent avec Unsampling#
Le bruit latent est la base de tout ce que nous faisons avec Stable Diffusion. Il est étonnant de prendre du recul et de penser à ce que nous sommes capables d'accomplir avec cela. Cependant, en général, nous sommes forcés d'utiliser un nombre aléatoire pour générer le bruit. Et si nous pouvions le contrôler?
Je ne suis pas le premier à utiliser l'Unsampling. Il existe depuis très longtemps et a été utilisé de plusieurs manières différentes. Jusqu'à présent, cependant, je n'ai généralement pas été satisfait des résultats. J'ai passé plusieurs mois à trouver les meilleurs réglages et j'espère que vous apprécierez ce guide.
En utilisant le processus de sampling avec AnimateDiff/Hotshot, nous pouvons trouver du bruit qui représente notre vidéo originale et rend donc tout type de transfert de style plus facile. Il est particulièrement utile de garder Hotshot cohérent étant donné sa fenêtre de contexte de 8 images.
Ce processus d'unsampling convertit essentiellement notre vidéo d'entrée en bruit latent qui maintient le mouvement et la composition de l'original. Nous pouvons ensuite utiliser ce bruit représentatif comme point de départ pour le processus de diffusion plutôt que du bruit aléatoire. Cela permet à l'IA d'appliquer le style cible tout en gardant les choses cohérentes dans le temps.
Ce guide suppose que vous avez installé AnimateDiff et/ou Hotshot. Si ce n'est pas déjà fait, les guides sont disponibles ici :
AnimateDiff : https://civitai.com/articles/2379
Hotshot XL guide : https://civitai.com/articles/2601/
Lien vers la ressource - Si vous voulez poster des vidéos sur Civitai en utilisant ce workflow. https://civitai.com/models/544534
2. Exigences Systémiques pour ce Workflow#
Un ordinateur Windows avec une carte graphique NVIDIA ayant au moins 12 Go de VRAM est recommandé. Sur la plateforme RunComfy, utilisez une machine Medium (16 Go de VRAM) ou de niveau supérieur. Ce processus ne nécessite pas plus de VRAM que les workflows standard d'AnimateDiff ou Hotshot, mais il prend presque deux fois plus de temps, car il exécute essentiellement le processus de diffusion deux fois—une fois pour l'upsampling et une fois pour le resampling avec le style cible.
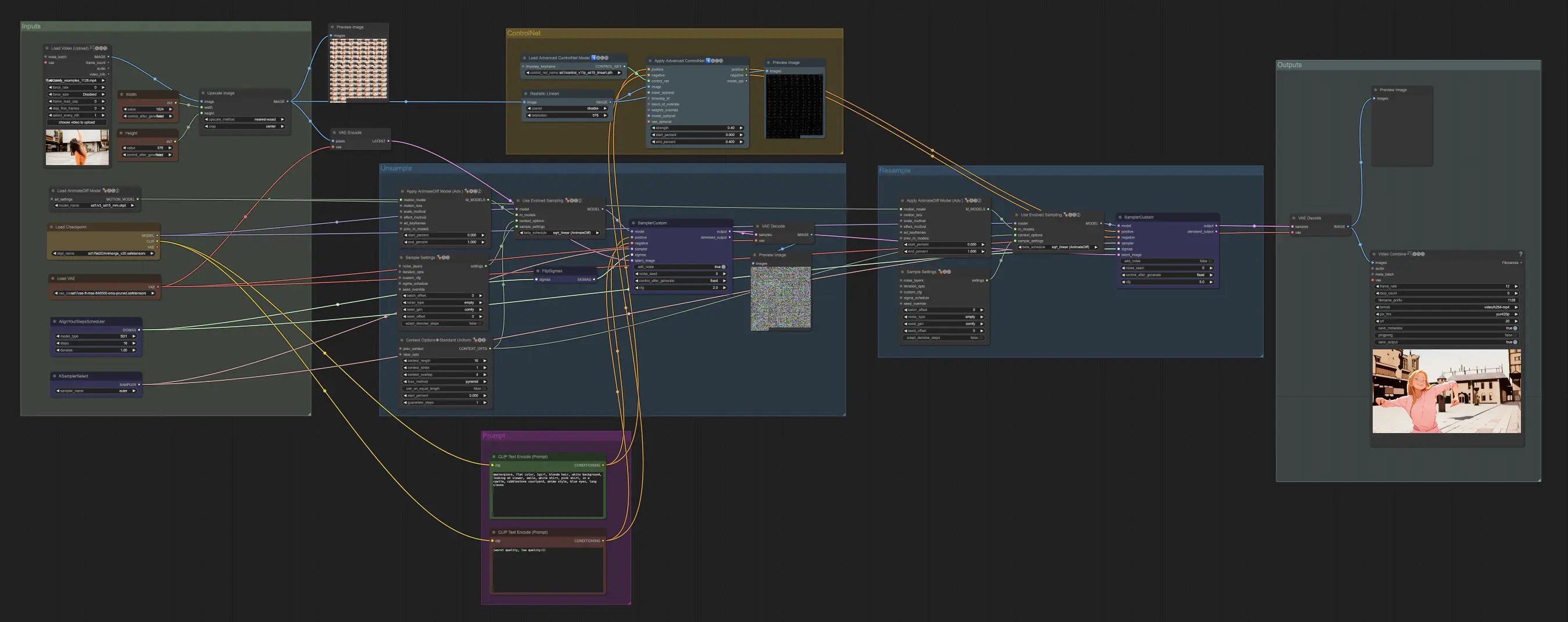
3. Explications des Nœuds et Guide des Réglages#
Nœud : Custom Sampler#
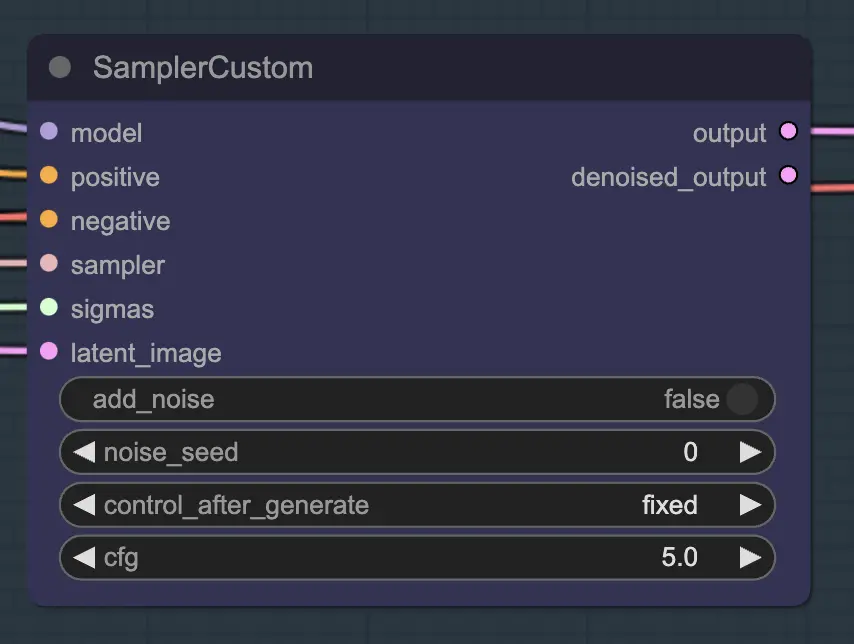
La partie principale de ceci est d'utiliser le Custom Sampler qui divise tous les réglages que vous voyez habituellement dans le KSampler régulier en morceaux :
Ceci est le nœud principal KSampler - pour l'unsampling, ajouter du bruit/seed n'a aucun effet (à ma connaissance). Le CFG est important - en général, plus le CFG est élevé à cette étape, plus la vidéo ressemblera à votre original. Un CFG plus élevé force l'unsampler à correspondre plus étroitement à l'entrée.
Nœud : KSampler Select#
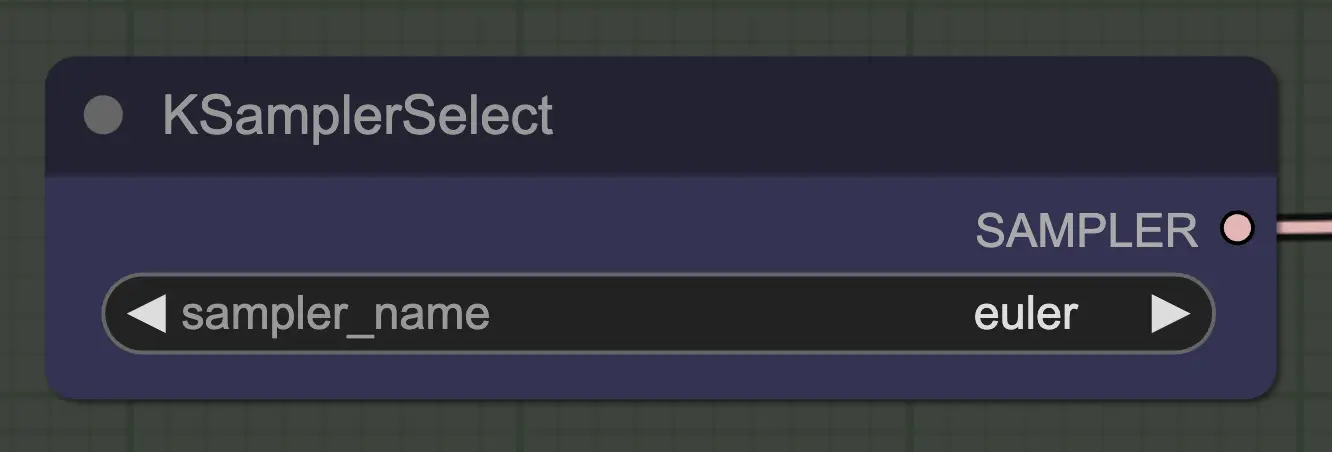
La chose la plus importante est d'utiliser un sampler qui converge! C'est pourquoi nous utilisons euler plutôt que euler a car ce dernier résulte en plus de randomisation/instabilité. Les samplers ancestraux qui ajoutent du bruit à chaque étape empêchent l'unsampling de converger proprement. Si vous voulez en savoir plus sur ce sujet, j'ai toujours trouvé cet article utile. @spacepxl sur reddit suggère que DPM++ 2M Karras est peut-être le sampler le plus précis selon le cas d'utilisation.
Nœud : Align Your Step Scheduler#
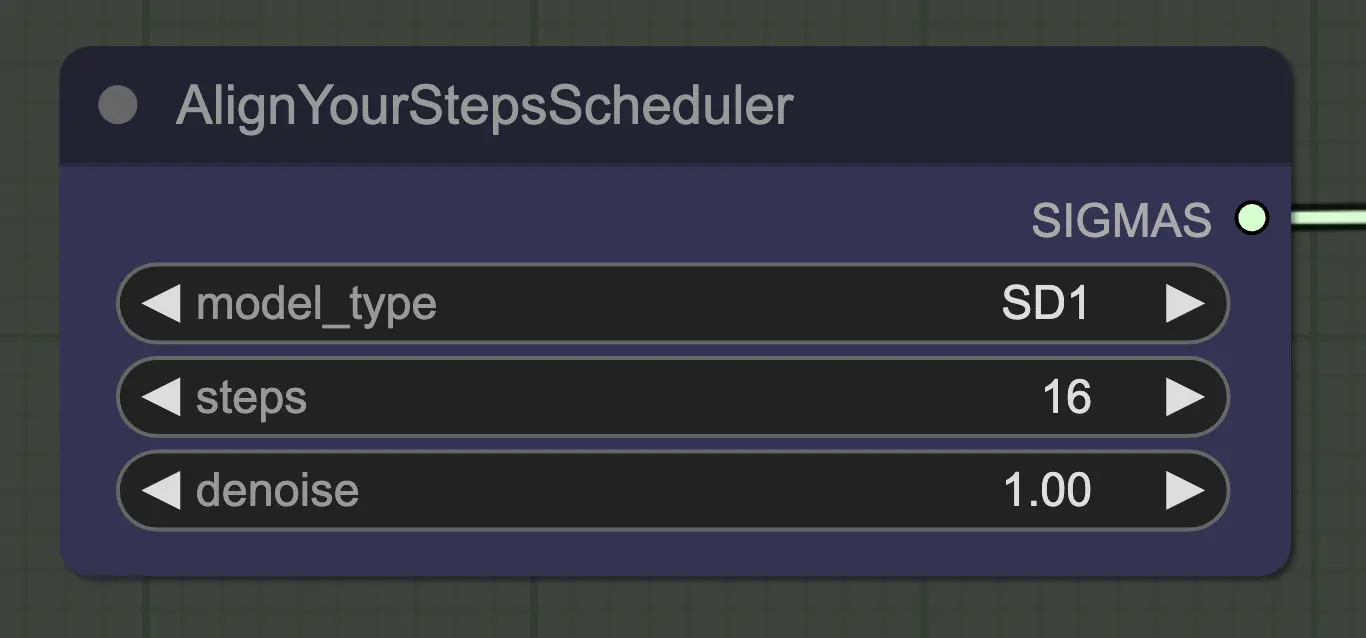
Tout scheduler fonctionnera bien ici - Align Your Steps (AYS) obtient cependant de bons résultats avec 16 étapes, donc j'ai opté pour cela pour réduire le temps de calcul. Plus d'étapes convergeront plus complètement mais avec des rendements décroissants.
Nœud : Flip Sigma#
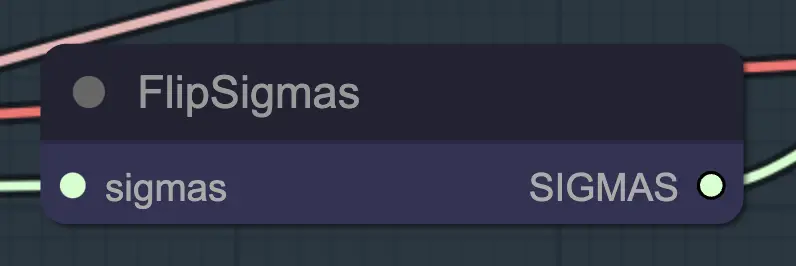
Flip Sigma est le nœud magique qui fait se produire l'unsampling! En inversant le programme sigma, nous renversons le processus de diffusion pour passer d'une image d'entrée propre à un bruit représentatif.
Nœud : Prompt#
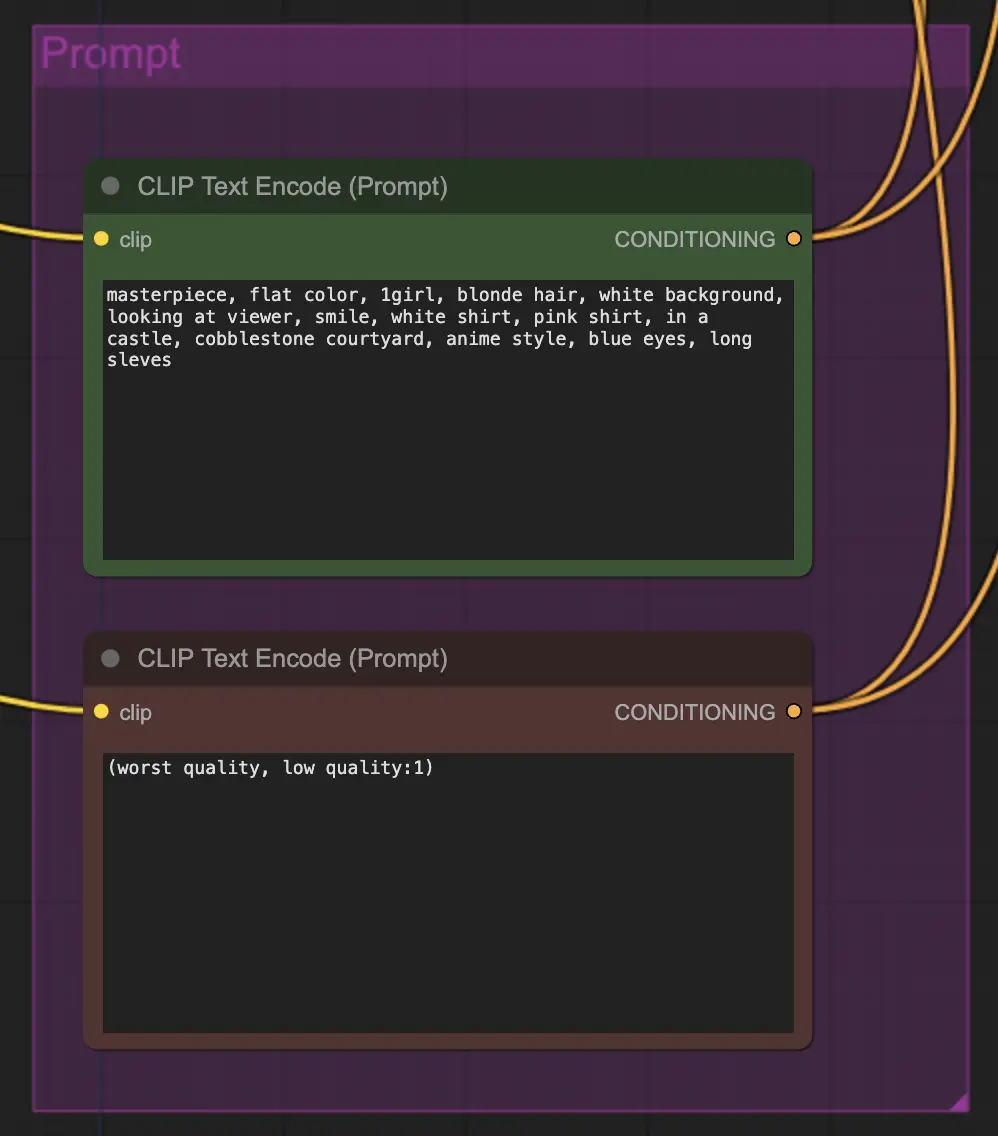
Le prompt est très important dans cette méthode pour une raison quelconque. Un bon prompt peut vraiment améliorer la cohérence de la vidéo, surtout plus vous voulez pousser la transformation. Pour cet exemple, j'ai alimenté le même conditionnement à la fois à l'unsampler et au resampler. Cela semble bien fonctionner en général - rien ne vous empêche cependant de mettre un conditionnement vide dans l'unsampler - je trouve que cela aide à améliorer le transfert de style, peut-être avec une légère perte de cohérence.
Nœud : Resampling#
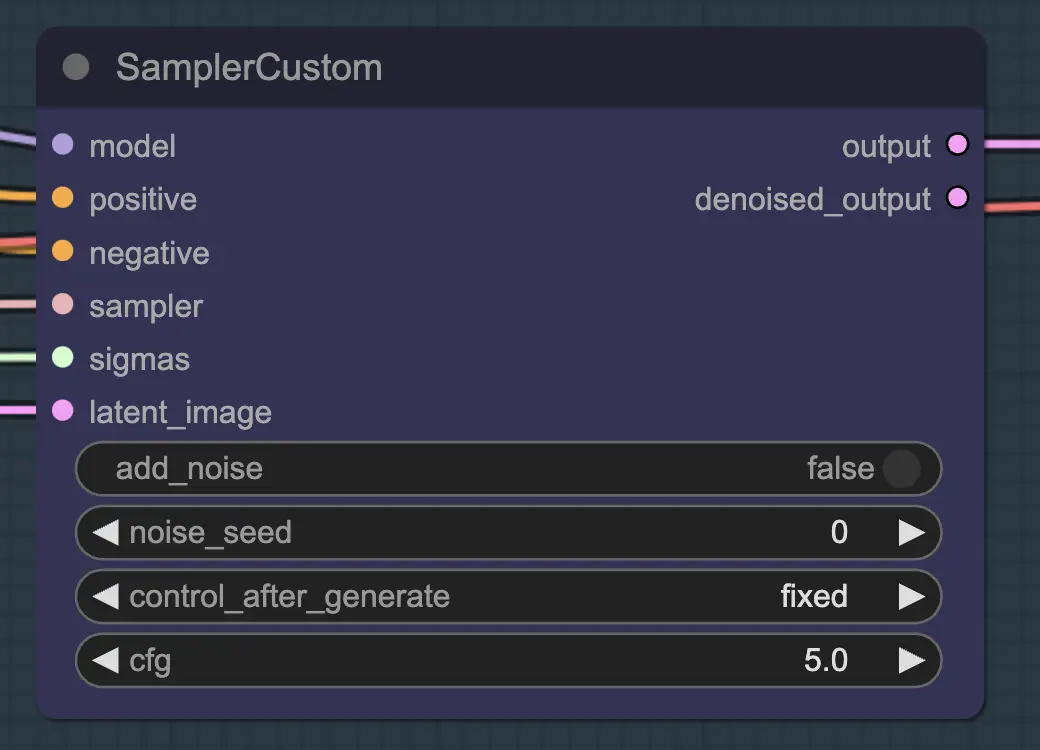
Pour le resampling, il est important de désactiver l'ajout de bruit (bien que le fait d'avoir du bruit vide dans les réglages de l'échantillonnage AnimateDiff ait le même effet - j'ai fait les deux pour mon workflow). Si vous ajoutez du bruit pendant le resampling, vous obtiendrez un résultat incohérent et bruyant, du moins avec les réglages par défaut. Sinon, je suggère de commencer avec un CFG assez bas combiné à des réglages ControlNet faibles car cela semble donner les résultats les plus cohérents tout en permettant au prompt d'influencer le style.
Autres Réglages#
Le reste de mes réglages sont des préférences personnelles. J'ai simplifié ce workflow autant que possible tout en incluant les composants et réglages clés.
4. Informations sur le Workflow#
Le workflow par défaut utilise le modèle SD1.5. Cependant, vous pouvez passer à SDXL en changeant simplement le checkpoint, VAE, modèle AnimateDiff, modèle ControlNet et modèle de programme d'étape à SDXL.
5. Notes/Problèmes Importants#
- Clignotement - Si vous regardez les latents décodés et prévisualisés créés par l'unsampling dans mes workflows, vous remarquerez certains avec des anomalies de couleur évidentes. La cause exacte n'est pas claire pour moi, et en général, elles n'affectent pas les résultats finaux. Ces anomalies sont particulièrement apparentes avec SDXL. Cependant, elles peuvent parfois causer des clignotements dans votre vidéo. La cause principale semble être liée aux ControlNets - donc réduire leur force peut aider. Changer le prompt ou même modifier légèrement le scheduler peut également faire une différence. Je rencontre encore ce problème de temps en temps - si vous avez une solution, faites-le moi savoir!
- DPM++ 2M peut parfois améliorer le clignotement.
6. Où Aller d'Ici?#
Cela ressemble à une toute nouvelle façon de contrôler la cohérence vidéo, donc il y a beaucoup à explorer. Si vous voulez mes suggestions :
- Essayez de combiner/masquer le bruit de plusieurs vidéos sources.
- Ajoutez IPAdapter pour une transformation cohérente des personnages.
À propos de l'Auteur#
Inner-Reflections
- https://x.com/InnerRefle11312
- https://civitai.com/user/Inner_Reflections_AI


